Today, we’re excited to announce the availability of Llama 2 inference and fine-tuning support on AWS Trainium and AWS Inferentia instances in Amazon SageMaker JumpStart. Using AWS Trainium and Inferentia based instances, through SageMaker, can help users lower fine-tuning costs by up to 50%, and lower deployment costs by 4.7x, while lowering per token latency. Llama 2 is an auto-regressive generative text language model that uses an optimized transformer architecture. As a publicly available model, Llama 2 is designed for many NLP tasks such as text classification, sentiment analysis, language translation, language modeling, text generation, and dialogue systems. Fine-tuning and deploying LLMs, like Llama 2, can become costly or challenging to meet real time performance to deliver good customer experience. Trainium and AWS Inferentia, enabled by the AWS Neuron software development kit (SDK), offer a high-performance, and cost effective option for training and inference of Llama 2 models.
In this post, we demonstrate how to deploy and fine-tune Llama 2 on Trainium and AWS Inferentia instances in SageMaker JumpStart.
Solution overview
In this blog, we will walk through the following scenarios :
- Deploy Llama 2 on AWS Inferentia instances in both the Amazon SageMaker Studio UI, with a one-click deployment experience, and the SageMaker Python SDK.
- Fine-tune Llama 2 on Trainium instances in both the SageMaker Studio UI and the SageMaker Python SDK.
- Compare the performance of the fine-tuned Llama 2 model with that of pre-trained model to show the effectiveness of fine-tuning.
To get hands on, see the GitHub example notebook.
Deploy Llama 2 on AWS Inferentia instances using the SageMaker Studio UI and the Python SDK
In this section, we demonstrate how to deploy Llama 2 on AWS Inferentia instances using the SageMaker Studio UI for a one-click deployment and the Python SDK.
Discover the Llama 2 model on the SageMaker Studio UI
SageMaker JumpStart provides access to both publicly available and proprietary foundation models. Foundation models are onboarded and maintained from third-party and proprietary providers. As such, they are released under different licenses as designated by the model source. Be sure to review the license for any foundation model that you use. You are responsible for reviewing and complying with any applicable license terms and making sure they are acceptable for your use case before downloading or using the content.
You can access the Llama 2 foundation models through SageMaker JumpStart in the SageMaker Studio UI and the SageMaker Python SDK. In this section, we go over how to discover the models in SageMaker Studio.
SageMaker Studio is an integrated development environment (IDE) that provides a single web-based visual interface where you can access purpose-built tools to perform all machine learning (ML) development steps, from preparing data to building, training, and deploying your ML models. For more details on how to get started and set up SageMaker Studio, refer to Amazon SageMaker Studio.
After you’re in SageMaker Studio, you can access SageMaker JumpStart, which contains pre-trained models, notebooks, and prebuilt solutions, under Prebuilt and automated solutions. For more detailed information on how to access proprietary models, refer to Use proprietary foundation models from Amazon SageMaker JumpStart in Amazon SageMaker Studio.
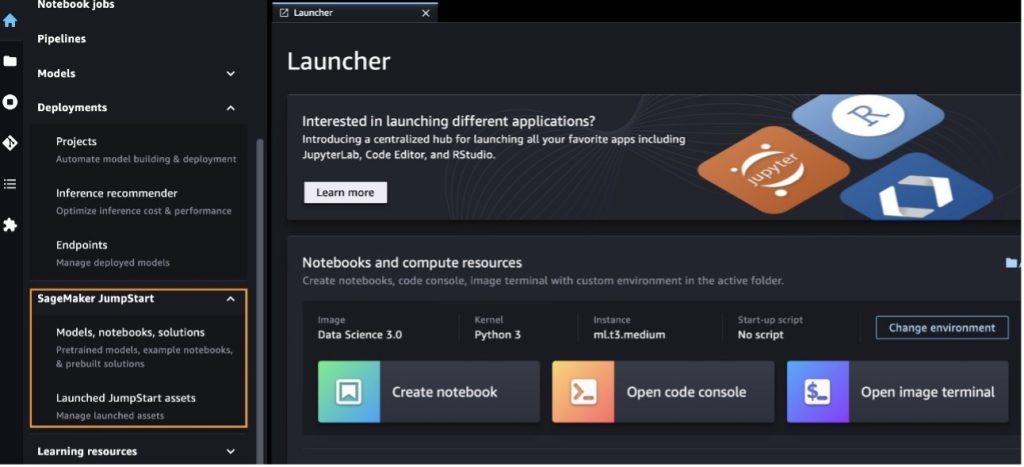
From the SageMaker JumpStart landing page, you can browse for solutions, models, notebooks, and other resources.
If you don’t see the Llama 2 models, update your SageMaker Studio version by shutting down and restarting. For more information about version updates, refer to Shut down and Update Studio Classic Apps.
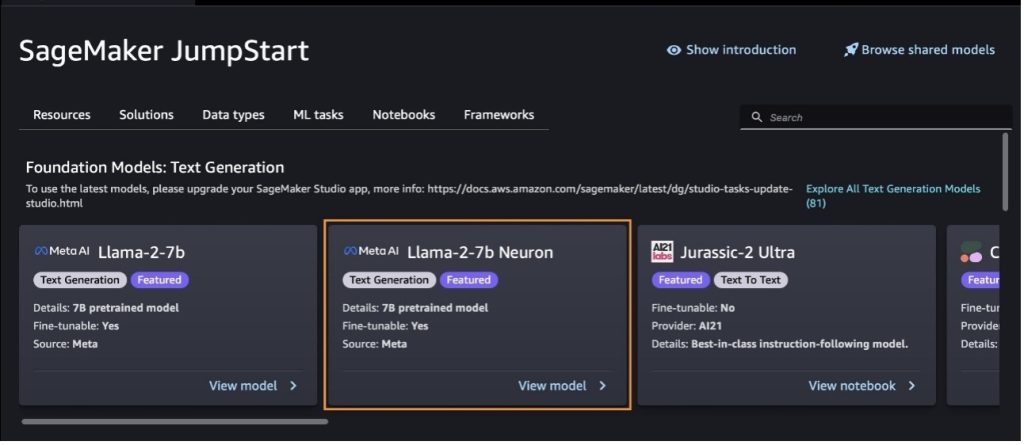
You can also find other model variants by choosing Explore All Text Generation Models or searching for llama or neuron in the search box. You will be able to view the Llama 2 Neuron models on this page.
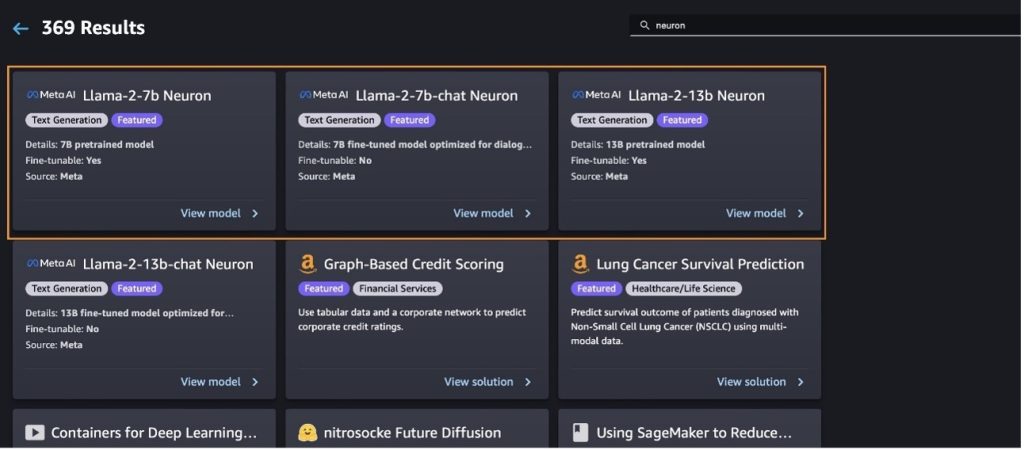
Deploy the Llama-2-13b model with SageMaker Jumpstart
You can choose the model card to view details about the model such as license, data used to train, and how to use it. You can also find two buttons, Deploy and Open notebook, which help you use the model using this no-code example.
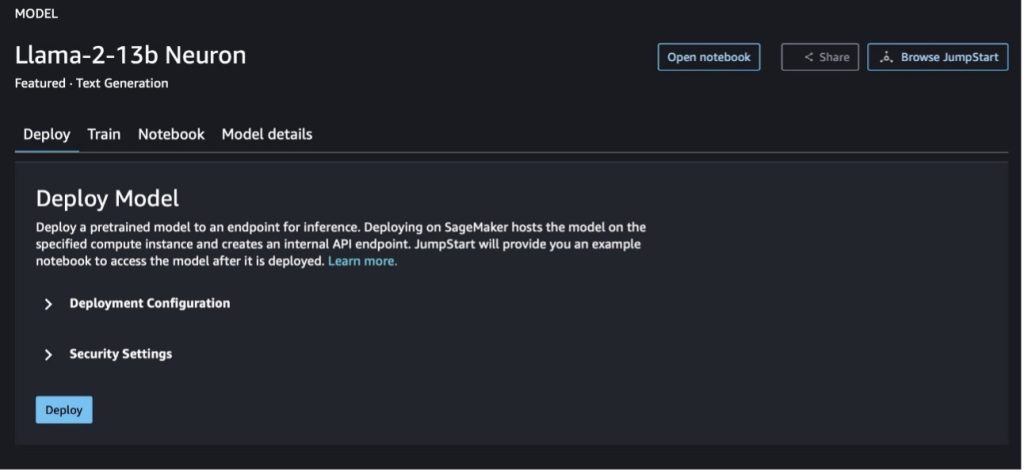
When you choose either button, a pop-up will show the End User License Agreement and Acceptable Use Policy (AUP) for you to acknowledge.
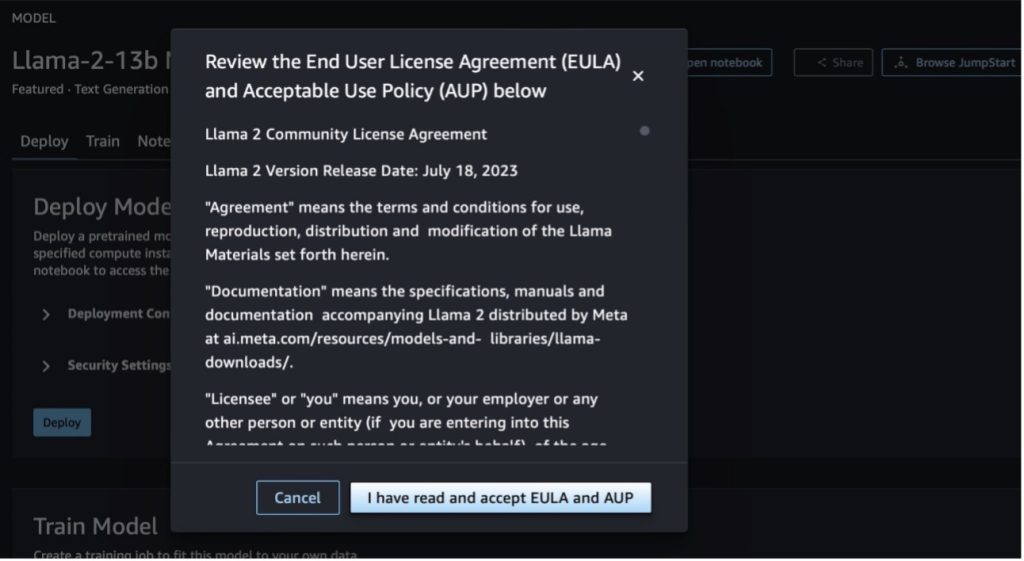
After you acknowledge the policies, you can deploy the endpoint of the model and use it via the steps in the next section.
Deploy the Llama 2 Neuron model via the Python SDK
When you choose Deploy and acknowledge the terms, model deployment will start. Alternatively, you can deploy through the example notebook by choosing Open notebook. The example notebook provides end-to-end guidance on how to deploy the model for inference and clean up resources.
To deploy or fine-tune a model on Trainium or AWS Inferentia instances, you first need to call PyTorch Neuron (torch-neuronx) to compile the model into a Neuron-specific graph, which will optimize it for Inferentia’s NeuronCores. Users can instruct the compiler to optimize for lowest latency or highest throughput, depending on the objectives of the application. In JumpStart, we pre-compiled the Neuron graphs for a variety of configurations, to allow users to sip compilation steps, enabling faster fine-tuning and deploying models.
Note that the Neuron pre-compiled graph is created based on a specific version of the Neuron Compiler version.
There are two ways to deploy LIama 2 on AWS Inferentia-based instances. The first method utilizes the pre-built configuration, and allows you to deploy the model in just two lines of code. In the second, you have greater control over the configuration. Let’s start with the first method, with the pre-built configuration, and use the pre-trained Llama 2 13B Neuron Model, as an example. The following code shows how to deploy Llama 13B with just two lines:
To perform inference on these models, you need to specify the argument accept_eula to be True as part of the model.deploy() call. Setting this argument to be true, acknowledges you have read and accepted the EULA of the model. The EULA can be found in the model card description or from the Meta website.
The default instance type for Llama 2 13B is ml.inf2.8xlarge. You can also try other supported models IDs:
meta-textgenerationneuron-llama-2-7bmeta-textgenerationneuron-llama-2-7b-f(chat model)meta-textgenerationneuron-llama-2-13b-f(chat model)
Alternatively, if you want have more control of the deployment configurations, such as context length, tensor parallel degree, and maximum rolling batch size, you can modify them via environmental variables, as demonstrated in this section. The underlying Deep Learning Container (DLC) of the deployment is the Large Model Inference (LMI) NeuronX DLC. The environmental variables are as follows:
- OPTION_N_POSITIONS – The maximum numbers of input and output tokens. For example, if you compile the model with
OPTION_N_POSITIONSas 512, then you can use an input token of 128 (input prompt size) with a maximum output token of 384 (the total of the input and output tokens has to be 512). For the maximum output token, any value below 384 is fine, but you can’t go beyond it (for example, input 256 and output 512). - OPTION_TENSOR_PARALLEL_DEGREE – The number of NeuronCores to load the model in AWS Inferentia instances.
- OPTION_MAX_ROLLING_BATCH_SIZE – The maximum batch size for concurrent requests.
- OPTION_DTYPE – The date type to load the model.
The compilation of Neuron graph depends on the context length (OPTION_N_POSITIONS), tensor parallel degree (OPTION_TENSOR_PARALLEL_DEGREE), maximum batch size (OPTION_MAX_ROLLING_BATCH_SIZE), and data type (OPTION_DTYPE) to load the model. SageMaker JumpStart has pre-compiled Neuron graphs for a variety of configurations for the preceding parameters to avoid runtime compilation. The configurations of pre-compiled graphs are listed in the following table. As long as the environmental variables fall into one of the following categories, compilation of Neuron graphs will be skipped.
| LIama-2 7B and LIama-2 7B Chat | ||||
| Instance type | OPTION_N_POSITIONS | OPTION_MAX_ROLLING_BATCH_SIZE | OPTION_TENSOR_PARALLEL_DEGREE | OPTION_DTYPE |
| ml.inf2.xlarge | 1024 | 1 | 2 | fp16 |
| ml.inf2.8xlarge | 2048 | 1 | 2 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 4 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 4 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 24 | fp16 |
| LIama-2 13B and LIama-2 13B Chat | ||||
| ml.inf2.8xlarge | 1024 | 1 | 2 | fp16 |
| ml.inf2.24xlarge | 2048 | 4 | 4 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 2048 | 4 | 4 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 24 | fp16 |
The following is an example of deploying Llama 2 13B and setting all the available configurations.
Now that we have deployed the Llama-2-13b model, we can run inference with it by invoking the endpoint. The following code snippet demonstrates using the supported inference parameters to control text generation:
- max_length – The model generates text until the output length (which includes the input context length) reaches
max_length. If specified, it must be a positive integer. - max_new_tokens – The model generates text until the output length (excluding the input context length) reaches
max_new_tokens. If specified, it must be a positive integer. - num_beams – This indicates the number of beams used in the greedy search. If specified, it must be an integer greater than or equal to
num_return_sequences. - no_repeat_ngram_size – The model ensures that a sequence of words of
no_repeat_ngram_sizeis not repeated in the output sequence. If specified, it must be a positive integer greater than 1. - temperature – This controls the randomness in the output. A higher temperature results in an output sequence with low-probability words; a lower temperature results in an output sequence with high-probability words. If
temperatureequals 0, it results in greedy decoding. If specified, it must be a positive float. - early_stopping – If
True, text generation is finished when all beam hypotheses reach the end of the sentence token. If specified, it must be Boolean. - do_sample – If
True, the model samples the next word as per the likelihood. If specified, it must be Boolean. - top_k – In each step of text generation, the model samples from only the
top_kmost likely words. If specified, it must be a positive integer. - top_p – In each step of text generation, the model samples from the smallest possible set of words with a cumulative probability of
top_p. If specified, it must be a float between 0–1. - stop – If specified, it must be a list of strings. Text generation stops if any one of the specified strings is generated.
The following code shows an example:
Output:
For more information on the parameters in the payload, refer to Detailed parameters.
You can also explore the implementation of the parameters in the notebook to add more information about the link of the notebook.
Fine-tune Llama 2 models on Trainium instances using the SageMaker Studio UI and SageMaker Python SDK
Generative AI foundation models have become a primary focus in ML and AI, however, their broad generalization can fall short in specific domains like healthcare or financial services, where unique datasets are involved. This limitation highlights the need to fine-tune these generative AI models with domain-specific data to enhance their performance in these specialized areas.
Now that we have deployed the pre-trained version of the Llama 2 model, let’s look at how we can fine-tune this to domain-specific data to increase the accuracy, improve the model in terms of prompt completions, and adapt the model to your specific business use case and data. You can fine-tune the models using either the SageMaker Studio UI or SageMaker Python SDK. We discuss both methods in this section.
Fine-tune the Llama-2-13b Neuron model with SageMaker Studio
In SageMaker Studio, navigate to the Llama-2-13b Neuron model. On the Deploy tab, you can point to the Amazon Simple Storage Service (Amazon S3) bucket containing the training and validation datasets for fine-tuning. In addition, you can configure deployment configuration, hyperparameters, and security settings for fine-tuning. Then choose Train to start the training job on a SageMaker ML instance.
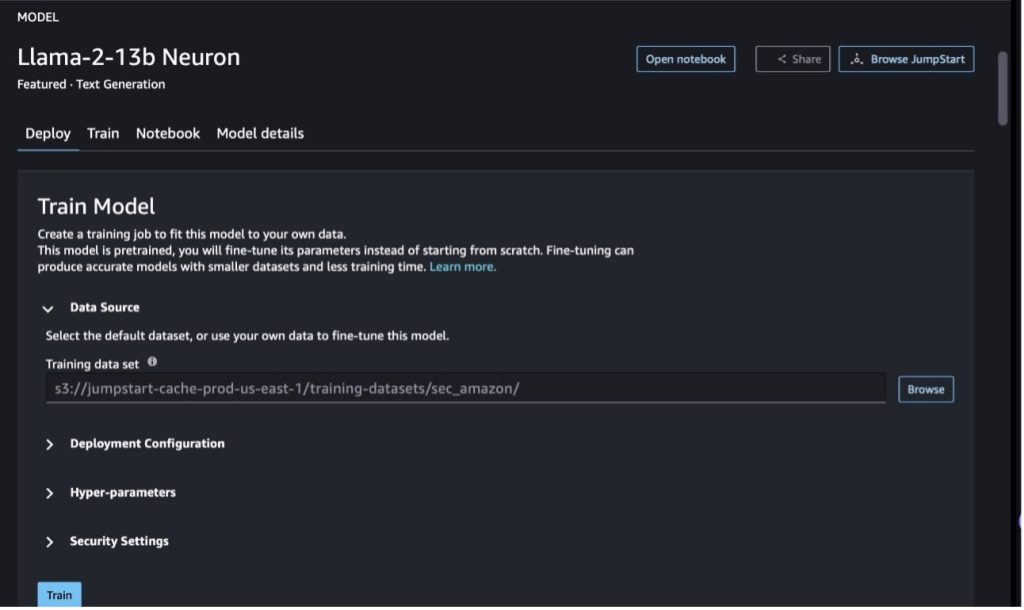
To use Llama 2 models, you need to accept the EULA and AUP. It will show up when you when you choose Train. Choose I have read and accept EULA and AUP to start the fine-tuning job.
You can view the status of your training job for the fine-tuned model under on the SageMaker console by choosing Training jobs in the navigation pane.
You can either fine-tune your Llama 2 Neuron model using this no-code example, or fine-tune via the Python SDK, as demonstrated in the next section.
Fine-tune the Llama-2-13b Neuron model via the SageMaker Python SDK
You can fine-tune on the dataset with the domain adaptation format or the instruction-based fine-tuning format. The following are the instructions for how the training data should be formatted before being sent into fine-tuning:
- Input – A
traindirectory containing either a JSON lines (.jsonl) or text (.txt) formatted file.- For the JSON lines (.jsonl) file, each line is a separate JSON object. Each JSON object should be structured as a key-value pair, where the key should be
text, and the value is the content of one training example. - The number of files under the train directory should equal to 1.
- For the JSON lines (.jsonl) file, each line is a separate JSON object. Each JSON object should be structured as a key-value pair, where the key should be
- Output – A trained model that can be deployed for inference.
In this example, we use a subset of the Dolly dataset in an instruction tuning format. The Dolly dataset contains approximately 15,000 instruction-following records for various categories, such as, question answering, summarization, and information extraction. It is available under the Apache 2.0 license. We use the information_extraction examples for fine-tuning.
- Load the Dolly dataset and split it into
train(for fine-tuning) andtest(for evaluation):
- Use a prompt template for preprocessing the data in an instruction format for the training job:
- Examine the hyperparameters and overwrite them for your own use case:
- Fine-tune the model and start a SageMaker training job. The fine-tuning scripts are based on the neuronx-nemo-megatron repository, which are modified versions of the packages NeMo and Apex that have been adapted for use with Neuron and EC2 Trn1 instances. The neuronx-nemo-megatron repository has 3D (data, tensor, and pipeline) parallelism to allow you to fine-tune LLMs in scale. The supported Trainium instances are ml.trn1.32xlarge and ml.trn1n.32xlarge.
- Finally, deploy the fine-tuned model in a SageMaker endpoint:
Compare responses between the pre-trained and fine-tuned Llama 2 Neuron models
Now that we have deployed the pre-trained version of the Llama-2-13b model and fine-tuned it, we can view some of the performance comparisons of the prompt completions from both models, as shown in the following table. We also offer an example to fine-tune Llama 2 on a SEC filing dataset in .txt format. For details, see the GitHub example notebook.
| Item | Inputs | Ground truth | Response from non-finetuned model | Response from fine-tuned model |
| 1 | Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.nn### Instruction:nExtract universities Moret studied at and his year of graduation for each, and put them in a bulleted list.nn### Input:nMoret was born in 1953 in Vevey Switzerland, and did his undergraduate studies at the École Polytechnique Fédérale de Lausanne (EPFL), graduating in 1975. He went on to graduate studies at the University of Tennessee, earning a Ph.D. in 1980. He then joined the faculty of the University of New Mexico, where he remained until 2006, when he moved to EPFL. He retired from EPFL in December 2016.nnIn 1996, Moret founded the ACM Journal of Experimental Algorithmics, and he remained editor in chief of the journal until 2003. In 2001, Moret founded the Workshop in Algorithms for Bioinformatics (WABI) and remains on the Steering Committee for the conference.nnIn 2018, Moret was elected as a Fellow of the International Society for Computational Biology, for his outstanding contributions to the fields of computational biology and bioinformatics.nn### Response:n | * École Polytechnique Fédérale de Lausanne (EPFL) (graduated 1975)n* University of Tennessee (graduated 1980) | Moret studied at the École Polytechnique Fédérale de Lausanne (EPFL) and the University of Tennessee, graduating in1975 and1980, respectively.nn### Hint:nn- Use the `split` function to split the input into a list of sentences.n- Use the `split` function to split each sentence into a list of words.n- Use the `split` function to split | – École Polytechnique Fédérale de Lausanne (EPFL),1975n- University of Tennessee,1980n- University of New Mexicon- École Polytechnique Fédérale de Lausanne (EPFL),2006nn<s> Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.n |
| 2 | Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.nn### Instruction:nFrom the passage identify the attributes of Dionysus. Display the results in a comma separated format.nn### Input:nDionysus (Διόνυσος, Diónusos)/Bacchus (Βάκχος, Bákkhos)nnGod of wine, fruitfulness, parties, festivals, madness, chaos, drunkenness, vegetation, ecstasy, and the theater. He is the twice-born son of Zeus and Semele, in that Zeus snatched him from his mother’s womb and stitched Dionysus into his own thigh and carried him until he was ready to be born. In art he is depicted as either an older bearded god (particularly before 430 BC) or an effeminate, long-haired youth (particularly after 430 BC). His attributes include the thyrsus, a drinking cup, the grape vine, and a crown of ivy. He is often in the company of his thiasos, a group of attendants including satyrs, maenads, and his old tutor Silenus. The consort of Dionysus was Ariadne. It was once held that Dionysius was a later addition to the Greek pantheon, but the discovery of Linear B tablets confirm his status as a deity from an early period. Bacchus was another name for him in Greek, and came into common usage among the Romans. His sacred animals include dolphins, serpents, tigers, and donkeys.nn### Response:n | the thyrsus, a drinking cup, the grape vine, a crown of ivy | Dionysus (Διόνυσος, Diónusos)nnGod of wine, fruitfulness, parties, festivals, madness, chaos, drunkenness, vegetation, ecstasy, and the theater. He is the twice-born son of Zeus and Semele, in that Zeus snatched him from his mother’s womb and stitched Dionysus into his own thigh | thyrsus, a drinking cup, the grape vine, a crown of ivynn<s> Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.nn### Instruction:nWhat is the difference between Parthian and Arsacid Empire?nn### Input:nThe Parthian Empire, also known as the Arsacid Empire was a |
| 3 | Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.nn### Instruction:nWhy does the capital of Uzbekistan contain the biggest Greek community?nn### Input:nThe Greeks in Uzbekistan number approximately 9,000. The community is made up of Greeks from Russia who were deported by force from that country to Uzbekistan in the 1940s, and political refugees from Greece. About 30,000 Greeks lived in the country before World War II and a further 11,000 arrived after the Greek Civil War and the defeat of Democratic Army of Greece. Their numbers have dwindled from a high of some 40,000 in the 1960s. The main reason is emigration to Greece after the end of the Cold War when laws allowed the return of all ethnic Greeks who had been exiled for political reasons after the Greek Civil War. The biggest Greek community in the country is in the capital city of Tashkent where most of the Greek political refugees were relocated by the Soviet authorities. In ancient times the south of the country was part of the Hellenistic Seleucid Kingdom but the few Greek communities there have since assimilated. The most important organization representing ethnic Greeks is the Greek Cultural Association of Tashkent. The activities of this organization include Greek language instruction (19 classes with a total of 571 students, classes for adults) and the teaching of Greek dances and music.nn### Response:n | Most of the Greek political refugees in Uzbekistan were relocated by the Soviet authorities to the capital city of Tashkent. | n“`nThe capital of Uzbekistan contains the biggest Greek community because the Greeks in Uzbekistan number approximately9,000. The community is made up of Greeks from Russia who were deported by force from that country to Uzbekistan in the1940s, and political refugees from Greece. About30,000 Greeks lived in the country before World War II and a further11,00 | The capital of Uzbekistan contains the biggest Greek community because that is where most of the Greek political refugees were relocated by the Soviet authorities after being deported from Greece.nn<s> Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.nn### Instruction:nWhat is the difference between Parthian and Arsacid Empire?nn### Input:n |
We can see that the responses from the fine-tuned model demonstrate a significant improvement in precision, relevance, and clarity compared to those from the pre-trained model. In some cases, using the pre-trained model for your use case might not be enough, so fine-tuning it using this technique will make the solution more personalized to your dataset.
Clean up
After you have completed your training job and don’t want to use the existing resources anymore, delete the resources using the following code:
Conclusion
The deployment and fine-tuning of Llama 2 Neuron models on SageMaker demonstrate a significant advancement in managing and optimizing large-scale generative AI models. These models, including variants like Llama-2-7b and Llama-2-13b, use Neuron for efficient training and inference on AWS Inferentia and Trainium based instances, enhancing their performance and scalability.
The ability to deploy these models through the SageMaker JumpStart UI and Python SDK offers flexibility and ease of use. The Neuron SDK, with its support for popular ML frameworks and high-performance capabilities, enables efficient handling of these large models.
Fine-tuning these models on domain-specific data is crucial for enhancing their relevance and accuracy in specialized fields. The process, which you can conduct through the SageMaker Studio UI or Python SDK, allows for customization to specific needs, leading to improved model performance in terms of prompt completions and response quality.
Comparatively, the pre-trained versions of these models, while powerful, may provide more generic or repetitive responses. Fine-tuning tailors the model to specific contexts, resulting in more accurate, relevant, and diverse responses. This customization is particularly evident when comparing responses from pre-trained and fine-tuned models, where the latter demonstrates a noticeable improvement in quality and specificity of output. In conclusion, the deployment and fine-tuning of Neuron Llama 2 models on SageMaker represent a robust framework for managing advanced AI models, offering significant improvements in performance and applicability, especially when tailored to specific domains or tasks.
Get started today by referencing sample SageMaker notebook.
For more information on deploying and fine-tuning pre-trained Llama 2 models on GPU-based instances, refer to Fine-tune Llama 2 for text generation on Amazon SageMaker JumpStart and Llama 2 foundation models from Meta are now available in Amazon SageMaker JumpStart.
The authors would like to acknowledge the technical contributions of Evan Kravitz, Christopher Whitten, Adam Kozdrowicz, Manan Shah, Jonathan Guinegagne and Mike James.
About the Authors
 Xin Huang is a Senior Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on developing scalable machine learning algorithms. His research interests are in the area of natural language processing, explainable deep learning on tabular data, and robust analysis of non-parametric space-time clustering. He has published many papers in ACL, ICDM, KDD conferences, and Royal Statistical Society: Series A.
Xin Huang is a Senior Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on developing scalable machine learning algorithms. His research interests are in the area of natural language processing, explainable deep learning on tabular data, and robust analysis of non-parametric space-time clustering. He has published many papers in ACL, ICDM, KDD conferences, and Royal Statistical Society: Series A.
 Nitin Eusebius is a Sr. Enterprise Solutions Architect at AWS, experienced in Software Engineering, Enterprise Architecture, and AI/ML. He is deeply passionate about exploring the possibilities of generative AI. He collaborates with customers to help them build well-architected applications on the AWS platform, and is dedicated to solving technology challenges and assisting with their cloud journey.
Nitin Eusebius is a Sr. Enterprise Solutions Architect at AWS, experienced in Software Engineering, Enterprise Architecture, and AI/ML. He is deeply passionate about exploring the possibilities of generative AI. He collaborates with customers to help them build well-architected applications on the AWS platform, and is dedicated to solving technology challenges and assisting with their cloud journey.
 Madhur Prashant works in the generative AI space at AWS. He is passionate about the intersection of human thinking and generative AI. His interests lie in generative AI, specifically building solutions that are helpful and harmless, and most of all optimal for customers. Outside of work, he loves doing yoga, hiking, spending time with his twin, and playing the guitar.
Madhur Prashant works in the generative AI space at AWS. He is passionate about the intersection of human thinking and generative AI. His interests lie in generative AI, specifically building solutions that are helpful and harmless, and most of all optimal for customers. Outside of work, he loves doing yoga, hiking, spending time with his twin, and playing the guitar.
 Dewan Choudhury is a Software Development Engineer with Amazon Web Services. He works on Amazon SageMaker’s algorithms and JumpStart offerings. Apart from building AI/ML infrastructures, he is also passionate about building scalable distributed systems.
Dewan Choudhury is a Software Development Engineer with Amazon Web Services. He works on Amazon SageMaker’s algorithms and JumpStart offerings. Apart from building AI/ML infrastructures, he is also passionate about building scalable distributed systems.
 Hao Zhou is a Research Scientist with Amazon SageMaker. Before that, he worked on developing machine learning methods for fraud detection for Amazon Fraud Detector. He is passionate about applying machine learning, optimization, and generative AI techniques to various real-world problems. He holds a PhD in Electrical Engineering from Northwestern University.
Hao Zhou is a Research Scientist with Amazon SageMaker. Before that, he worked on developing machine learning methods for fraud detection for Amazon Fraud Detector. He is passionate about applying machine learning, optimization, and generative AI techniques to various real-world problems. He holds a PhD in Electrical Engineering from Northwestern University.
 Qing Lan is a Software Development Engineer in AWS. He has been working on several challenging products in Amazon, including high performance ML inference solutions and high performance logging system. Qing’s team successfully launched the first Billion-parameter model in Amazon Advertising with very low latency required. Qing has in-depth knowledge on the infrastructure optimization and Deep Learning acceleration.
Qing Lan is a Software Development Engineer in AWS. He has been working on several challenging products in Amazon, including high performance ML inference solutions and high performance logging system. Qing’s team successfully launched the first Billion-parameter model in Amazon Advertising with very low latency required. Qing has in-depth knowledge on the infrastructure optimization and Deep Learning acceleration.
 Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker built-in algorithms and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.
Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker built-in algorithms and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.
 Dr. Li Zhang is a Principal Product Manager-Technical for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms, a service that helps data scientists and machine learning practitioners get started with training and deploying their models, and uses reinforcement learning with Amazon SageMaker. His past work as a principal research staff member and master inventor at IBM Research has won the test of time paper award at IEEE INFOCOM.
Dr. Li Zhang is a Principal Product Manager-Technical for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms, a service that helps data scientists and machine learning practitioners get started with training and deploying their models, and uses reinforcement learning with Amazon SageMaker. His past work as a principal research staff member and master inventor at IBM Research has won the test of time paper award at IEEE INFOCOM.
 Kamran Khan, Sr Technical Business Development Manager for AWS Inferentina/Trianium at AWS. He has over a decade of experience helping customers deploy and optimize deep learning training and inference workloads using AWS Inferentia and AWS Trainium.
Kamran Khan, Sr Technical Business Development Manager for AWS Inferentina/Trianium at AWS. He has over a decade of experience helping customers deploy and optimize deep learning training and inference workloads using AWS Inferentia and AWS Trainium.
 Joe Senerchia is a Senior Product Manager at AWS. He defines and builds Amazon EC2 instances for deep learning, artificial intelligence, and high-performance computing workloads.
Joe Senerchia is a Senior Product Manager at AWS. He defines and builds Amazon EC2 instances for deep learning, artificial intelligence, and high-performance computing workloads.