The increase in online social activities such as social networking or online gaming is often riddled with hostile or aggressive behavior that can lead to unsolicited manifestations of hate speech, cyberbullying, or harassment. For example, many online gaming communities offer voice chat functionality to facilitate communication among their users. Although voice chat often supports friendly banter and trash talking, it can also lead to problems such as hate speech, cyberbullying, harassment, and scams. Flagging harmful language helps organizations keep conversations civil and maintain a safe and inclusive online environment for users to create, share, and participate freely. Today, many companies rely solely on human moderators to review toxic content. However, scaling human moderators to meet these needs at a sufficient quality and speed is expensive. As a result, many organizations risk facing high user attrition rates, reputational damage, and regulatory fines. In addition, moderators are often psychologically impacted by reviewing the toxic content.
Amazon Transcribe is an automatic speech recognition (ASR) service that makes it easy for developers to add speech-to-text capability to their applications. Today, we are excited to announce Amazon Transcribe Toxicity Detection, a machine learning (ML)-powered capability that uses both audio and text-based cues to identify and classify voice-based toxic content across seven categories, including sexual harassment, hate speech, threats, abuse, profanity, insults, and graphic language. In addition to text, Toxicity Detection uses speech cues such as tones and pitch to hone in on toxic intent in speech.
This is an improvement from standard content moderation systems that are designed to focus only on specific terms, without accounting for intention. Most enterprises have an SLA of 7–15 days to review content reported by users because moderators must listen to lengthy audio files to evaluate if and when the conversation became toxic. With Amazon Transcribe Toxicity Detection, moderators only review the specific portion of the audio file flagged for toxic content (vs. the entire audio file). The content human moderators must review is reduced by 95%, enabling customers to reduce their SLA to just a few hours, as well as enable them to proactively moderate more content beyond just what’s flagged by the users. It will allow enterprises to automatically detect and moderate content at scale, provide a safe and inclusive online environment, and take action before it can cause user churn or reputational damage. The models used for toxic content detection are maintained by Amazon Transcribe and updated periodically to maintain accuracy and relevance.
In this post, you’ll learn how to:
- Identify harmful content in speech with Amazon Transcribe Toxicity Detection
- Use the Amazon Transcribe console for toxicity detection
- Create a transcription job with toxicity detection using the AWS Command Line Interface (AWS CLI) and Python SDK
- Use the Amazon Transcribe toxicity detection API response
Detect toxicity in audio chat with Amazon Transcribe Toxicity Detection
Amazon Transcribe now provides a simple, ML-based solution for flagging harmful language in spoken conversations. This feature is especially useful for social media, gaming, and general needs, eliminating the need for customers to provide their own data to train the ML model. Toxicity Detection classifies toxic audio content into the following seven categories and provides a confidence score (0–1) for each category:
- Profanity – Speech that contains words, phrases, or acronyms that are impolite, vulgar, or offensive.
- Hate speech – Speech that criticizes, insults, denounces, or dehumanizes a person or group on the basis of an identity (such as race, ethnicity, gender, religion, sexual orientation, ability, and national origin).
- Sexual – Speech that indicates sexual interest, activity, or arousal using direct or indirect references to body parts, physical traits, or sex.
- Insults – Speech that includes demeaning, humiliating, mocking, insulting, or belittling language. This type of language is also labeled as bullying.
- Violence or threat – Speech that includes threats seeking to inflict pain, injury, or hostility toward a person or group.
- Graphic – Speech that uses visually descriptive and unpleasantly vivid imagery. This type of language is often intentionally verbose to amplify a recipient’s discomfort.
- Harassment or abusive – Speech intended to affect the psychological well-being of the recipient, including demeaning and objectifying terms.
You can access Toxicity Detection either via the Amazon Transcribe console or by calling the APIs directly using the AWS CLI or the AWS SDKs. On the Amazon Transcribe console, you can upload the audio files you want to test for toxicity and get results in just a few clicks. Amazon Transcribe will identify and categorize toxic content, such as harassment, hate speech, sexual content, violence, insults, and profanity. Amazon Transcribe also provides a confidence score for each category, providing valuable insights into the content’s toxicity level. Toxicity Detection is currently available in the standard Amazon Transcribe API for batch processing and supports US English language.
Amazon Transcribe console walkthrough
To get started, sign in to the AWS Management Console and go to Amazon Transcribe. To create a new transcription job, you need to upload your recorded files into an Amazon Simple Storage Service (Amazon S3) bucket before they can be processed. On the audio settings page, as shown in the following screenshot, enable Toxicity detection and proceed to create the new job. Amazon Transcribe will process the transcription job in the background. As the job progresses, you can expect the status to change to COMPLETED when the process is finished.
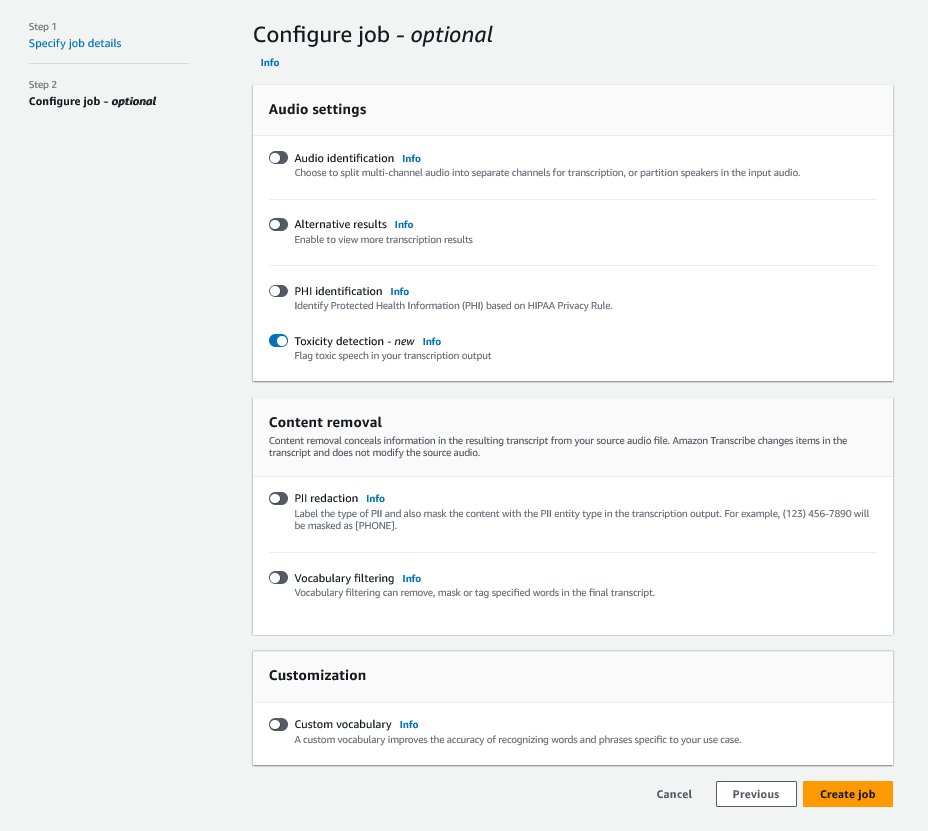
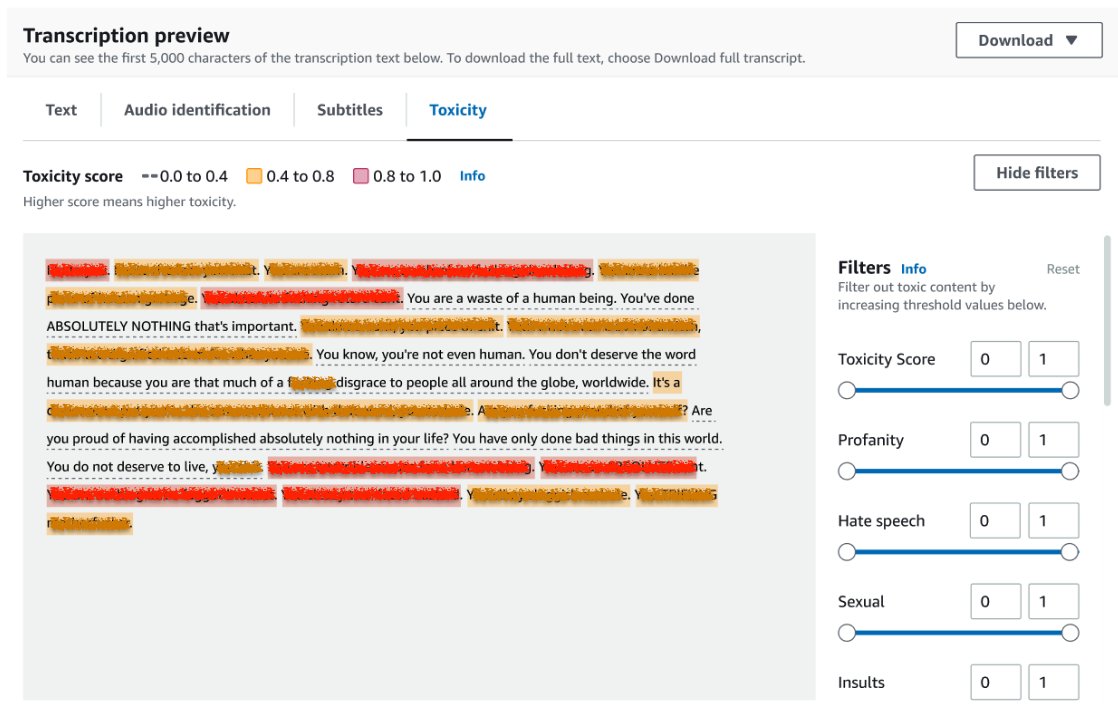
To review the results of a transcription job, choose the job from the job list to open it. Scroll down to the Transcription preview section to check results on the Toxicity tab. The UI shows color-coded transcription segments to indicate the level of toxicity, determined by the confidence score. To customize the display, you can use the toggle bars in the Filters pane. These bars allow you to adjust the thresholds and filter the toxicity categories accordingly.
The following screenshot has covered portions of the transcription text due to the presence of sensitive or toxic information.
Transcription API with a toxicity detection request
In this section, we guide you through creating a transcription job with toxicity detection using programming interfaces. If the audio file is not already in an S3 bucket, upload it to ensure access by Amazon Transcribe. Similar to creating a transcription job on the console, when invoking the job, you need to provide the following parameters:
- TranscriptionJobName – Specify a unique job name.
- MediaFileUri – Enter the URI location of the audio file on Amazon S3. Amazon Transcribe supports the following audio formats: MP3, MP4, WAV, FLAC, AMR, OGG, or WebM
- LanguageCode – Set to
en-US. As of this writing, Toxicity Detection only supports US English language. - ToxicityCategories – Pass the
ALLvalue to include all supported toxicity detection categories.
The following are examples of starting a transcription job with toxicity detection enabled using Python3:
You can invoke the same transcription job with toxicity detection using the following AWS CLI command:
Transcription API with toxicity detection response
The Amazon Transcribe toxicity detection JSON output will include the transcription results in the results field. Enabling toxicity detection adds an extra field called toxicityDetection under the results field. toxicityDetection includes a list of transcribed items with the following parameters:
- text – The raw transcribed text
- toxicity – A confidence score of detection (a value between 0–1)
- categories – A confidence score for each category of toxic speech
- start_time – The start position of detection in the audio file (seconds)
- end_time – The end position of detection in the audio file (seconds)
The following is a sample abbreviated toxicity detection response you can download from the console:
Summary
In this post, we provided an overview of the new Amazon Transcribe Toxicity Detection feature. We also described how you can parse the toxicity detection JSON output. For more information, check out the Amazon Transcribe console and try out the Transcription API with Toxicity Detection.
Amazon Transcribe Toxicity Detection is now available in the following AWS Regions: US East (Ohio), US East (N. Virginia), US West (Oregon), Asia Pacific (Sydney), Europe (Ireland), and Europe (London). To learn more, visit Amazon Transcribe.
Learn more about content moderation on AWS and our content moderation ML use cases. Take the first step towards streamlining your content moderation operations with AWS.
About the author
 Lana Zhang is a Senior Solutions Architect at AWS WWSO AI Services team, specializing in AI and ML for content moderation, computer vision, and natural language processing. With her expertise, she is dedicated to promoting AWS AI/ML solutions and assisting customers in transforming their business solutions across diverse industries, including social media, gaming, e-commerce, and advertising & marketing.
Lana Zhang is a Senior Solutions Architect at AWS WWSO AI Services team, specializing in AI and ML for content moderation, computer vision, and natural language processing. With her expertise, she is dedicated to promoting AWS AI/ML solutions and assisting customers in transforming their business solutions across diverse industries, including social media, gaming, e-commerce, and advertising & marketing.
 Sumit Kumar is a Sr Product Manager, Technical at AWS AI Language Services team. He has 10 years of product management experience across a variety of domains and is passionate about AI/ML. Outside of work, Sumit loves to travel and enjoys playing cricket and Lawn-Tennis.
Sumit Kumar is a Sr Product Manager, Technical at AWS AI Language Services team. He has 10 years of product management experience across a variety of domains and is passionate about AI/ML. Outside of work, Sumit loves to travel and enjoys playing cricket and Lawn-Tennis.