A guest article by Mike Walmsley, University of Oxford
The way we do science is changing; there’s exponentially more data every day but around the same number of scientists. The traditional approach of collecting data samples, looking through them, and drawing some conclusions about each one is often inadequate.
One solution is to deploy algorithms to process the data automatically. Another solution is to deploy more eyeballs: recruit members of the public to join in and help. I work on the intersection between the two – combining crowdsourcing and machine learning to do better science than with either alone.
In this article, I want to share how I’ve been using crowdsourcing and machine learning to investigate how galaxies evolve by classifying millions of galaxy images. Along the way, I’ll share some techniques we use to train CNNs that make predictions with uncertainty. I’ll also explain how to use those predictions to do active learning: labelling only the data which would best help you improve your models.
Better Telescopes, Bigger Problems
Ever since Edwin Hubble in the 1920’s, astronomers have looked up at galaxies and tried to classify them into different types – smooth galaxies, spiral galaxies, and so on. But the number of galaxies kept on climbing. About 20 years ago, a grad student named Kevin Schawinski sat at his desk with a pile of 900,000 galaxy pictures, put his head in his hands and thought – “there has to be a better way” than classifying every one himself. He wasn’t alone. To classify all 900,000 galaxies without sacrificing Kevin’s sanity, a team of scientists (including Kevin) built Galaxy Zoo.
Galaxy Zoo is a website that asks members of the public to classify galaxies for us. We show you a galaxy, and we ask simple questions about what you can see, like – is the galaxy smooth, or featured? As you answer, we lead you down a decision tree where the questions depend on how you’ve previously responded.
 |
| The Galaxy Zoo UI. Check it out, and join in with the science, here. |
Since launch, hundreds of thousands of volunteers have classified millions of galaxies – advancing our understanding of supermassive black holes, spiral arms, the births and deaths of stars, and much more. However, there’s a problem: humans don’t scale. Galaxy surveys keep getting bigger, but we will always have about the same number of volunteers. The latest space-based telescopes can image hundreds of millions of galaxies – far more than we could ever label with crowdsourcing alone.
To keep up, we used TensorFlow to build a galaxy classifier. Other researchers have used the responses we’ve collected to train convolutional neural networks (CNNs) – a type of deep learning model tailored for image recognition. However, traditional CNNs have a drawback; they don’t easily handle uncertainty.
Training a CNN to solve a regression problem by predicting a value for each label and minimising the mean squared error, as is common, implicitly assumes that all labels are equally uncertain – which is definitely not the case for Galaxy Zoo. Further, the CNN only gives a ‘best guess’ answer with no error bars – making it difficult to draw scientific conclusions.
In our paper, we use Bayesian CNNs for morphology classification. Bayesian CNNs provide two key improvements:
- They account for varying uncertainty when learning from volunteer responses.
- They predict full posteriors over the morphology of each galaxy.
Using our Bayesian CNN, we can learn from noisy labels and make reliable predictions (with error bars) for hundreds of millions of galaxies.
How Bayesian Convolutional Neural Networks Work
There are two key steps to creating our Bayesian CNNs.
1. Predict the parameters of a probability distribution, not the label itself
Training neural networks is much like any other fitting problem: you tweak the model to match the observations. If you are equally confident in all your collected labels, you can just minimise the difference (e.g. mean squared error) between your predictions and the observed values. However for Galaxy Zoo, many labels are more confident than others.
If I observe that, for some galaxy, 30% of volunteers say “bar”, my confidence in that 30% depends heavily on how many people replied – was it 4 or 40? Instead, we predict the probability that a typical volunteer will say “Bar”, and minimise how surprised we should be given the total number of volunteers who replied.
This way, our model understands that errors on galaxies where many volunteers replied are worse than errors on galaxies where few volunteers replied – letting it learn from every galaxy.
In our case, we can model our surprise with the Binomial distribution by recognising that k “Bar” responses from N volunteers is much like k successes from N independent trials.
loss = tf.reduce_mean(binomial_loss(labels, scalar_predictions))Where `binomial_loss` calculates the surprise (negative log likelihood) of the observed labels given our model predictions:  In TF, we can calculate this with:
In TF, we can calculate this with:
def binomial_loss(observations, est_prob_success):
one = tf.constant(1., dtype=tf.float32)
# to avoid calculating log 0
epsilon = tf.keras.backend.epsilon()
# multiplication in tf requires floats
k_successes = tf.cast(observations[:, 0], tf.float32)
n_trials = tf.cast(observations[:, 1], tf.float32)
# binomial negative log likelihood, dropping (fixed) combinatorial terms
return -( k_successes * tf.log(est_prob_success + epsilon) + (n_trials - k_successes) * tf.log(one - est_prob_success + epsilon )2. Use Dropout to Pretend to Train Many Networks
Our model now makes probabilistic predictions, but what if we had trained a different model? It would make slightly different probabilistic predictions. To be Bayesian, we need to marginalise over the possible models we might have trained. To do this, we use dropout.
At train time, dropout reduces overfitting by “approximately combining exponentially many different neural network architectures efficiently” (Srivastava 2014). This approximates the Bayesian approach of treating the network weights as random variables to be marginalised over. By also applying dropout at test time, we can exploit this idea of approximating many models to also make Bayesian predictions (Gal 2016).
Here’s a TF 2.0 example using the Subclassing API:
from tensorflow.keras import layers, Model
class SimpleClassifier(Model):
def __init__(self):
super(SimpleClassifier, self).__init__()
self.conv1 = layers.Conv2D(32, 3, activation='relu')
self.flatten = layers.Flatten()
self.d1 = layers.Dense(128, activation='relu')
self.dropout1 = layers.Dropout(rate=0.5)
self.d2 = layers.Dense(2, activation='softmax')
def call(self, x, training):
x = self.conv1(x)
x = self.flatten(x)
x = self.d1(x)
if training: # dropout typically applied only at train time
x = self.dropout1(x)
return self.d2(x)Switching on test-time dropout actually involves less code:
def call(self, x): # no ‘training’ argument required
x = self.conv1(x)
x = self.flatten(x)
x = self.d1(x)
x = self.dropout1(x) # dropout always on
return self.d2(x)Below, you can see our Bayesian CNN in action. Each row is a galaxy (shown to the left). In the central column, our CNN makes a single probabilistic prediction (the probability that a typical volunteer would answer “Bar”). We can interpret that as a posterior for the probability that k of N volunteers would say “Bar” – shown in black. On the right, we marginalise over many CNNs using dropout. Each CNN posterior (grey) is different, but we can marginalise over them to get the posterior over many CNNs (green) – our Bayesian posterior.
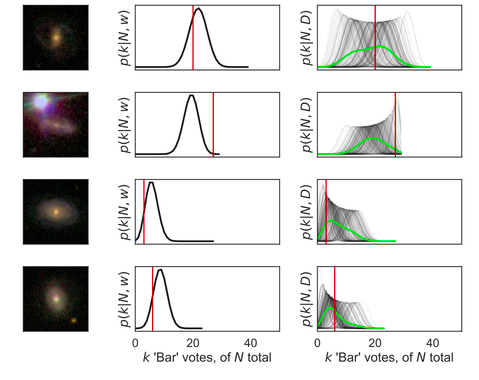 |
| Left: input images of galaxies, with or without a bar. Center: single probabilistic predictions (i.e. without dropout) for how many volunteers would say “Bar”. Right: many probabilistic predictions made with different dropout masks (grey), marginalised into our approximate Bayesian posterior (green). |
The Bayesian posterior does an excellent job at quantifying if each galaxy has a bar. Read more about it in the paper (and check out the code).
Active Learning
Modern surveys will image hundreds of millions of galaxies – more than we can show to volunteers. Given that, which galaxies should we classify with volunteers, and which by our Bayesian CNN?
Ideally we would only show volunteers the images that the model would find most informative. The model should be able to ask, “Hey, these galaxies would be really helpful to learn from; can you label them for me please?” Then the humans would label them and the model would retrain – this is active learning. In our experiments, applying active learning reduces the number of galaxies needed to reach a given performance level by up to 35-60%.
We can use our posteriors to work out which galaxies are most informative. Remember that we use dropout to approximate training many models (see above). We show in the paper that informative galaxies are galaxies where those models confidently disagree.
Why? We often hold our strongest opinions where we are least informed – and so do our CNN (Hendrycks 2016). Without a basis in evidence, different CNN will often disagree confidently. 
Formally, informative galaxies are galaxies where each model is confident (entropy H in the posterior from each model, p(votes|weights), is low) but the average prediction over all the models is uncertain (entropy across all averaged posteriors is high). This is only possible because we think about labels probabilistically and approximate training many models. For more, see Houlsby, N. (2014) and Gal 2017, or our code for an implementation.
What galaxies are informative? Exactly the galaxies you would intuitively expect.
- The model strongly prefers diverse featured galaxies over ellipticals (smooth ‘blobs’).
- For identifying bars, the model prefers galaxies which are better resolved (lower redshift).
This selection is completely automatic. Indeed, I didn’t realise the lower redshift preference until I looked at the images!
 |
| Our active learning system selects galaxies on the left (featured and diverse) over those on the right (smooth ‘blobs’). |
Active learning is picking galaxies to label right now on Galaxy Zoo – check it out here by selecting the ‘Enhanced’ workflow. I’m excited to see what science can be done as we move from classifying hundreds of thousands of galaxies to hundreds of millions.
If you’d like to know more or you have any questions, get in touch in the comments or on Twitter (@mike_w_ai, @chrislintott, @yaringal, @OATML_Oxford).
Cheers,
Mike
*Dropout is an imperfect approximation of a fully Bayesian approach that’s feasible for large vision models but may underestimate uncertainty. It’s possible to make better approximations, especially for small models. Check out this post by the Tensorflow Probability team showing how to do this for one-dimensional regression. Read More