“85% of buyers trust online reviews as much as a personal recommendation” – Gartner
Consumers are increasingly engaging with businesses through digital surfaces and multiple touchpoints. Statistics show that the majority of shoppers use reviews to determine what products to buy and which services to use. As per Spiegel Research Centre, the purchase likelihood for a product with five reviews is 270% greater than the purchase likelihood of a product with no reviews. Reviews have the power to influence consumer decisions and strengthen brand value.
In this post, we use Amazon Comprehend to extract meaningful information from product reviews, analyze it to understand how users of different demographics are reacting to products, and discover aggregated information on user affinity towards a product. Amazon Comprehend is a fully managed and continuously trained natural language processing (NLP) service that can extract insight about content of a document or text.
Solution overview
Today, reviews can be provided by customers in various ways, such as star ratings, free text or natural language, or social media shares. Free text or natural language reviews help build trust, as it’s an independent opinion from consumers. It’s often used by product teams to interact with customers through review channels. It’s a proven fact that when customers feel heard, their feeling about the brand improves. Whereas it’s comparatively easier to analyze star ratings or social media shares, natural language or free text reviews pose multiple challenges, like identifying keywords or phrases, topics or concepts, and sentiment or entity-level sentiments. The challenge is mainly due to the variability of length in written text and plausible presence of both signals and noise. Furthermore, the information can either be very clear and explicit (for example, with keywords and key phrases) or unclear and implicit (abstract topics and concepts). Even more challenging is understanding different types of sentiments and relating them to appropriate products and services. Nevertheless, it’s highly critical to understand this information and textual signals in order to provide a frictionless customer experience.
In this post, we use a publicly available NLP – fast.ai dataset to analyze the product reviews provided by customers. We start by using an unsupervised machine learning (ML) technique known as topic modeling. This a popular unsupervised technique that discovers abstract topics that can occur in a text review collection. Topic modeling is a clustering problem that is unsupervised, meaning that the models have no knowledge on possible target variables (such as topics in a review). The topics are represented as clusters. Often, the number of clusters in a corpus of documents is decided with the help of domain experts or by using some standard statistical analysis. The model outputs generally have three components: numbered clusters (topic 0, topic 1, and so on), keywords associated to each cluster, and representative clusters for each document (or review in our case). By its inherent nature, topic models don’t generate human-readable labels for the clusters or topics, which is a common misconception. Something to note about topic modeling in general is that it’s a mixed membership model— every document in the model may have a resemblance to every topic. The topic model learns in an iterative Bayesian process to determine the probability that each document is associated with a given theme or topic. The model output depends on selecting the number of topics optimally. A small number of topics can result in the topics being too broad, and a larger number of topics may result in redundant topics or topics with similarity. There are a number of ways to evaluate topic models:
- Human judgment – Observation-based, interpretation-based
- Quantitative metrics – Perplexity, coherence calculations
- Mixed approach – A combination of judgment-based and quantitative approaches
Perplexity is calculated by splitting a dataset into two parts—a training set and a test set. Likelihood is usually calculated as a logarithm, so this metric is sometimes referred to as the held-out log-likelihood. Perplexity is a predictive metric. It assesses a topic model’s ability to predict a test set after having been trained on a training set. One of the shortcomings of perplexity is that it doesn’t capture context, meaning that it doesn’t capture the relationship between words in a topic or topics in a document. However, the idea of semantic context is important for human understanding. Measures such as the conditional likelihood of the co- occurrence of words in a topic can be helpful. These approaches are collectively referred to as coherence. For this post, we focus on the human judgment (observation-based) approach, namely observing the top n words in a topic.
The solution consists of the following high-level steps:
- Set up an Amazon SageMaker notebook instance.
- Create a notebook.
- Perform exploratory data analysis.
- Run your Amazon Comprehend topic modeling job.
- Generate topics and understand sentiment.
- Use Amazon QuickSight to visualize data and generate reports.
You can use this solution in any AWS Region, but you need to make sure that the Amazon Comprehend APIs and SageMaker are in the same Region. For this post, we use the Region US East (N. Virginia).
Set up your SageMaker notebook instance
You can interact with Amazon Comprehend via the AWS Management Console, AWS Command Line Interface (AWS CLI), or Amazon Comprehend API. For more information, refer to Getting started with Amazon Comprehend. We use a SageMaker notebook and Python (Boto3) code throughout this post to interact with the Amazon Comprehend APIs.
- On the Amazon SageMaker console, under Notebook in the navigation pane, choose
Notebook instances. - Choose Create notebook instance.

- Specify a notebook instance name and set the instance type as ml.r5.2xlarge.
- Leave the rest of the default settings.
- Create an AWS Identity and Access Management (IAM) role with
AmazonSageMakerFullAccessand access to any necessary Amazon Simple Storage Service (Amazon S3) buckets and Amazon Comprehend APIs. - Choose Create notebook instance.
After a few minutes, your notebook instance is ready. - To access Amazon Comprehend from the notebook instance, you need to attach the
ComprehendFullAccesspolicy to your IAM role.
For a security overview of Amazon Comprehend, refer to Security in Amazon Comprehend.
Create a notebook
After you open the notebook instance that you provisioned, on the Jupyter console, choose New and then Python 3 (Data Science). Alternatively, you can access the sample code file in the GitHub repo. You can upload the file to the notebook instance to run it directly or clone it.
The GitHub repo contains three notebooks:
data_processing.ipynbmodel_training.ipynbtopic_mapping_sentiment_generation.ipynb
Perform exploratory data analysis
We use the first notebook (data_processing.ipynb) to explore and process the data. We start by simply loading the data from an S3 bucket into a DataFrame.
# Bucket containing the data
BUCKET = 'clothing-shoe-jewel-tm-blog'
# Item ratings and metadata
S3_DATA_FILE = 'Clothing_Shoes_and_Jewelry.json.gz' # Zip
S3_META_FILE = 'meta_Clothing_Shoes_and_Jewelry.json.gz' # Zip
S3_DATA = 's3://' + BUCKET + '/' + S3_DATA_FILE
S3_META = 's3://' + BUCKET + '/' + S3_META_FILE
# Transformed review, input for Comprehend
LOCAL_TRANSFORMED_REVIEW = os.path.join('data', 'TransformedReviews.txt')
S3_OUT = 's3://' + BUCKET + '/out/' + 'TransformedReviews.txt'
# Final dataframe where topics and sentiments are going to be joined
S3_FEEDBACK_TOPICS = 's3://' + BUCKET + '/out/' + 'FinalDataframe.csv'
def convert_json_to_df(path):
"""Reads a subset of a json file in a given path in chunks, combines, and returns
"""
# Creating chunks from 500k data points each of chunk size 10k
chunks = pd.read_json(path, orient='records',
lines=True,
nrows=500000,
chunksize=10000,
compression='gzip')
# Creating a single dataframe from all the chunks
load_df = pd.DataFrame()
for chunk in chunks:
load_df = pd.concat([load_df, chunk], axis=0)
return load_df
# Review data
original_df = convert_json_to_df(S3_DATA)
# Metadata
original_meta = convert_json_to_df(S3_META)In the following section, we perform exploratory data analysis (EDA) to understand the data. We start by exploring the shape of the data and metadata. For authenticity, we use verified reviews only.
# Shape of reviews and metadata
print('Shape of review data: ', original_df.shape)
print('Shape of metadata: ', original_meta.shape)
# We are interested in verified reviews only
# Also checking the amount of missing values in the review data
print('Frequency of verified/non verified review data: ', original_df['verified'].value_counts())
print('Frequency of missing values in review data: ', original_df.isna().sum())We further explore the count of each category, and see if any duplicate data is present.
# Count of each categories for EDA.
print('Frequncy of different item categories in metadata: ', original_meta['category'].value_counts())
# Checking null values for metadata
print('Frequency of missing values in metadata: ', original_meta.isna().sum())
# Checking if there are duplicated data. There are indeed duplicated data in the dataframe.
print('Duplicate items in metadata: ', original_meta[original_meta['asin'].duplicated()])When we’re satisfied with the results, we move to the next step of preprocessing the data. Amazon Comprehend recommends providing at least 1,000 documents in each topic modeling job, with each document at least three sentences long. Documents must be in UTF-8 formatted text files. In the following step, we make sure that data is in the recommended UTF-8 format and each input is no more than 5,000 bytes in size.
def clean_text(df):
"""Preprocessing review text.
The text becomes Comprehend compatible as a result.
This is the most important preprocessing step.
"""
# Encode and decode reviews
df['reviewText'] = df['reviewText'].str.encode("utf-8", "ignore")
df['reviewText'] = df['reviewText'].str.decode('ascii')
# Replacing characters with whitespace
df['reviewText'] = df['reviewText'].replace(r'r+|n+|t+|u2028',' ', regex=True)
# Replacing punctuations
df['reviewText'] = df['reviewText'].str.replace('[^ws]','', regex=True)
# Lowercasing reviews
df['reviewText'] = df['reviewText'].str.lower()
return df
def prepare_input_data(df):
"""Encoding and getting reviews in byte size.
Review gets encoded to utf-8 format and getting the size of the reviews in bytes.
Comprehend requires each review input to be no more than 5000 Bytes
"""
df['review_size'] = df['reviewText'].apply(lambda x:len(x.encode('utf-8')))
df = df[(df['review_size'] > 0) & (df['review_size'] < 5000)]
df = df.drop(columns=['review_size'])
return df
# Only data points with a verified review will be selected and the review must not be missing
filter = (original_df['verified'] == True) & (~original_df['reviewText'].isna())
filtered_df = original_df[filter]
# Only a subset of fields are selected in this experiment.
filtered_df = filtered_df[['asin', 'reviewText', 'summary', 'unixReviewTime', 'overall', 'reviewerID']]
# Just in case, once again, dropping data points with missing review text
filtered_df = filtered_df.dropna(subset=['reviewText'])
print('Shape of review data: ', filtered_df.shape)
# Dropping duplicate items from metadata
original_meta = original_meta.drop_duplicates(subset=['asin'])
# Only a subset of fields are selected in this experiment.
original_meta = original_meta[['asin', 'category', 'title', 'description', 'brand', 'main_cat']]
# Clean reviews using text cleaning pipeline
df = clean_text(filtered_df)
# Dataframe where Comprehend outputs (topics and sentiments) will be added
df = prepare_input_data(df)We then save the data to Amazon S3 and also keep a local copy in the notebook instance.
# Saving dataframe on S3 df.to_csv(S3_FEEDBACK_TOPICS, index=False)
# Reviews are transformed per Comprehend guideline- one review per line
# The txt file will be used as input for Comprehend
# We first save the input file locally
with open(LOCAL_TRANSFORMED_REVIEW, "w") as outfile:
outfile.write("n".join(df['reviewText'].tolist()))
# Transferring the transformed review (input to Comprehend) to S3
!aws s3 mv {LOCAL_TRANSFORMED_REVIEW} {S3_OUT}
This completes our data processing phase.
Run an Amazon Comprehend topic modeling job
We then move to the next phase, where we use the preprocessed data to run a topic modeling job using Amazon Comprehend. At this stage, you can either use the second notebook (model_training.ipynb) or use the Amazon Comprehend console to run the topic modeling job. For instructions on using the console, refer to Running analysis jobs using the console. If you’re using the notebook, you can start by creating an Amazon Comprehend client using Boto3, as shown in the following example.
# Client and session information
session = boto3.Session()
s3 = boto3.resource('s3')
# Account id. Required downstream.
account_id = boto3.client('sts').get_caller_identity().get('Account')
# Initializing Comprehend client
comprehend = boto3.client(service_name='comprehend',
region_name=session.region_name)You can submit your documents for topic modeling in two ways: one document per file, or one document per line.
We start with 5 topics (k-number), and use one document per line. There is no single best way as a standard practice to select k or the number of topics. You may try out different values of k, and select the one that has the largest likelihood.
# Number of topics set to 5 after having a human-in-the-loop
# This needs to be fully aligned with topicMaps dictionary in the third script
NUMBER_OF_TOPICS = 5
# Input file format of one review per line
input_doc_format = "ONE_DOC_PER_LINE"
# Role arn (Hard coded, masked)
data_access_role_arn = "arn:aws:iam::XXXXXXXXXXXX:role/service-role/AmazonSageMaker-ExecutionRole-XXXXXXXXXXXXXXX"Our Amazon Comprehend topic modeling job requires you to pass an InputDataConfig dictionary object with S3, InputFormat, and DocumentReadAction as required parameters. Similarly, you need to provide the OutputDataConfig object with S3 and DataAccessRoleArn as required parameters. For more information, refer to the Boto3 documentation for start_topics_detection_job.
# Constants for S3 bucket and input data file
BUCKET = 'clothing-shoe-jewel-tm-blog'
input_s3_url = 's3://' + BUCKET + '/out/' + 'TransformedReviews.txt'
output_s3_url = 's3://' + BUCKET + '/out/' + 'output/'
# Final dataframe where we will join Comprehend outputs later
S3_FEEDBACK_TOPICS = 's3://' + BUCKET + '/out/' + 'FinalDataframe.csv'
# Local copy of Comprehend output
LOCAL_COMPREHEND_OUTPUT_DIR = os.path.join('comprehend_out', '')
LOCAL_COMPREHEND_OUTPUT_FILE = os.path.join(LOCAL_COMPREHEND_OUTPUT_DIR, 'output.tar.gz')
INPUT_CONFIG={
# The S3 URI where Comprehend input is placed.
'S3Uri': input_s3_url,
# Document format
'InputFormat': input_doc_format,
}
OUTPUT_CONFIG={
# The S3 URI where Comprehend output is placed.
'S3Uri': output_s3_url,
}You can then start an asynchronous topic detection job by passing the number of topics, input configuration object, output configuration object, and an IAM role, as shown in the following example.
# Reading the Comprehend input file just to double check if number of reviews
# and the number of lines in the input file have an exact match.
obj = s3.Object(input_s3_url)
comprehend_input = obj.get()['Body'].read().decode('utf-8')
comprehend_input_lines = len(comprehend_input.split('n'))
# Reviews where Comprehend outputs will be merged
df = pd.read_csv(S3_FEEDBACK_TOPICS)
review_df_length = df.shape[0]
# The two lengths must be equal
assert comprehend_input_lines == review_df_length
# Start Comprehend topic modelling job.
# Specifies the number of topics, input and output config and IAM role ARN
# that grants Amazon Comprehend read access to data.
start_topics_detection_job_result = comprehend.start_topics_detection_job(
NumberOfTopics=NUMBER_OF_TOPICS,
InputDataConfig=INPUT_CONFIG,
OutputDataConfig=OUTPUT_CONFIG,
DataAccessRoleArn=data_access_role_arn)
print('start_topics_detection_job_result: ' + json.dumps(start_topics_detection_job_result))
# Job ID is required downstream for extracting the Comprehend results
job_id = start_topics_detection_job_result["JobId"]
print('job_id: ', job_id)You can track the current status of the job by calling the DescribeTopicDetectionJob operation. The status of the job can be one of the following:
- SUBMITTED – The job has been received and is queued for processing
- IN_PROGRESS – Amazon Comprehend is processing the job
- COMPLETED – The job was successfully completed and the output is available
- FAILED – The job didn’t complete
# Topic detection takes a while to complete.
# We can track the current status by calling Use the DescribeTopicDetectionJob operation.
# Keeping track if Comprehend has finished its job
description = comprehend.describe_topics_detection_job(JobId=job_id)
topic_detection_job_status = description['TopicsDetectionJobProperties']["JobStatus"]
print(topic_detection_job_status)
while topic_detection_job_status not in ["COMPLETED", "FAILED"]:
time.sleep(120)
topic_detection_job_status = comprehend.describe_topics_detection_job(JobId=job_id)['TopicsDetectionJobProperties']["JobStatus"]
print(topic_detection_job_status)
topic_detection_job_status = comprehend.describe_topics_detection_job(JobId=job_id)['TopicsDetectionJobProperties']["JobStatus"]
print(topic_detection_job_status)When the job is successfully complete, it returns a compressed archive containing two files: topic-terms.csv and doc-topics.csv. The first output file, topic-terms.csv, is a list of topics in the collection. For each topic, the list includes, by default, the top terms by topic according to their weight. The second file, doc-topics.csv, lists the documents associated with a topic and the proportion of the document that is concerned with the topic. Because we specified ONE_DOC_PER_LINE earlier in the input_doc_format variable, the document is identified by the file name and the 0-indexed line number within the file. For more information on topic modeling, refer to Topic modeling.
The outputs of Amazon Comprehend are copied locally for our next steps.
# Bucket prefix where model artifacts are stored
prefix = f'{account_id}-TOPICS-{job_id}'
# Model artifact zipped file
artifact_file = 'output.tar.gz'
# Location on S3 where model artifacts are stored
target = f's3://{BUCKET}/out/output/{prefix}/{artifact_file}'
# Copy Comprehend output from S3 to local notebook instance
! aws s3 cp {target} ./comprehend-out/
# Unzip the Comprehend output file.
# Two files are now saved locally-
# (1) comprehend-out/doc-topics.csv and
# (2) comprehend-out/topic-terms.csv
comprehend_tars = tarfile.open(LOCAL_COMPREHEND_OUTPUT_FILE)
comprehend_tars.extractall(LOCAL_COMPREHEND_OUTPUT_DIR)
comprehend_tars.close()Because the number of topics is much less than the vocabulary associated with the document collection, the topic space representation can be viewed as a dimensionality reduction process as well. You may use this topic space representation of documents to perform clustering. On the other hand, you can analyze the frequency of words in each cluster to determine topic associated with each cluster. For this post, we don’t perform any other techniques like clustering.
Generate topics and understand sentiment
We use the third notebook (topic_mapping_sentiment_generation.ipynb) to find how users of different demographics are reacting to products, and also analyze aggregated information on user affinity towards a particular product.
We can combine the outputs from the previous notebook to get topics and associated terms for each topic. However, the topics are numbered and may lack explainability. Therefore, we prefer to use a human-in-the-loop with enough domain knowledge and subject matter expertise to name the topics by looking at their associated terms. This process can be considered as a mapping from topic numbers to topic names. However, it’s noteworthy that the individual list of terms for the topics can be mutually inclusive and therefore may create multiple mappings. The human-in-the-loop should formalize the mappings based on the context of the use case. Otherwise, the downstream performance may be impacted.
We start by declaring the variables. For each review, there can be multiple topics. We count their frequency and select a maximum of three most frequent topics. These topics are reported as the representative topics of a review. First, we define a variable TOP_TOPICS to hold the maximum number of representative topics. Second, we define and set values to the language_code variable to support the required language parameter of Amazon Comprehend. Finally, we create topicMaps, which is a dictionary that maps topic numbers to topic names.
# boto3 session to access service
session = boto3.Session()
comprehend = boto3.client( 'comprehend',
region_name=session.region_name)
# S3 bucket
BUCKET = 'clothing-shoe-jewel-tm-blog'
# Local copy of doc-topic file
DOC_TOPIC_FILE = os.path.join('comprehend-out', 'doc-topics.csv')
# Final dataframe where we will join Comprehend outputs later
S3_FEEDBACK_TOPICS = 's3://' + BUCKET + '/out/' + 'FinalDataframe.csv'
# Final output
S3_FINAL_OUTPUT = 's3://' + BUCKET + '/out/' + 'reviewTopicsSentiments.csv'
# Top 3 topics per product will be aggregated
TOP_TOPICS = 3
# Working on English language only.
language_code = 'en'
# Topic names for 5 topics created by human-in-the-loop or SME feed
topicMaps = {
0: 'Product comfortability',
1: 'Product Quality and Price',
2: 'Product Size',
3: 'Product Color',
4: 'Product Return',
}
Next, we use the topic-terms.csv file generated by Amazon Comprehend to connect the unique terms associated with each topic. Then, by applying the mapping dictionary on this topic-term association, we connect the unique terms to the topic names.
# Loading documents and topics assigned to each of them by Comprehend
docTopics = pd.read_csv(DOC_TOPIC_FILE)
docTopics.head()
# Creating a field with doc number.
# This doc number is the line number of the input file to Comprehend.
docTopics['doc'] = docTopics['docname'].str.split(':').str[1]
docTopics['doc'] = docTopics['doc'].astype(int)
docTopics.head()
# Load topics and associated terms
topicTerms = pd.read_csv(DOC_TOPIC_FILE)
# Consolidate terms for each topic
aggregatedTerms = topicTerms.groupby('topic')['term'].aggregate(lambda term: term.unique().tolist()).reset_index()
# Sneak peek
aggregatedTerms.head(10)This mapping improves the readability and explainability of the topics generated by Amazon Comprehend, as we can see in the following DataFrame.

Furthermore, we join the topic number, terms, and names to the initial input data, as shown in the following steps.
This returns topic terms and names corresponding to each review. The topic numbers and terms are joined with each review and then further joined back to the original DataFrame we saved in the first notebook.
# Load final dataframe where Comprehend results will be merged to
feedbackTopics = pd.read_csv(S3_FEEDBACK_TOPICS)
# Joining topic numbers to main data
# The index of feedbackTopics is referring to doc field of docTopics dataframe
feedbackTopics = pd.merge(feedbackTopics,
docTopics,
left_index=True,
right_on='doc',
how='left')
# Reviews will now have topic numbers, associated terms and topics names
feedbackTopics = feedbackTopics.merge(aggregatedTerms,
on='topic',
how='left')
feedbackTopics.head()We generate sentiment for the review text using detect_sentiment. It inspects text and returns an inference of the prevailing sentiment (POSITIVE, NEUTRAL, MIXED, or NEGATIVE).
def detect_sentiment(text, language_code):
"""Detects sentiment for a given text and language
"""
comprehend_json_out = comprehend.detect_sentiment(Text=text, LanguageCode=language_code)
return comprehend_json_out
# Comprehend output for sentiment in raw json
feedbackTopics['comprehend_sentiment_json_out'] = feedbackTopics['reviewText'].apply(lambda x: detect_sentiment(x, language_code))
# Extracting the exact sentiment from raw Comprehend Json
feedbackTopics['sentiment'] = feedbackTopics['comprehend_sentiment_json_out'].apply(lambda x: x['Sentiment'])
# Sneak peek
feedbackTopics.head(2)Both topics and sentiments are tightly coupled with reviews. Because we will be aggregating topics and sentiments at product level, we need to create a composite key by combining the topics and sentiments generated by Amazon Comprehend.
# Creating a composite key of topic name and sentiment.
# This is because we are counting frequency of this combination.
feedbackTopics['TopicSentiment'] = feedbackTopics['TopicNames'] + '_' + feedbackTopics['sentiment']Afterwards, we aggregate at product level and count the composite keys for each product.
This final step helps us better understand the granularity of the reviews per product and categorizing it per topic in an aggregated manner. For instance, we can consider the values shown for topicDF DataFrame. For the first product, of all the reviews for it, overall the customers had a positive experience on product return, size, and comfort. For the second product, the customers had mostly a mixed-to-positive experience on product return and a positive experience on product size.
# Create product id group
asinWiseDF = feedbackTopics.groupby('asin')
# Each product now has a list of topics and sentiment combo (topics can appear multiple times)
topicDF = asinWiseDF['TopicSentiment'].apply(lambda x:list(x)).reset_index()
# Count appreances of topics-sentiment combo for product
topicDF['TopTopics'] = topicDF['TopicSentiment'].apply(Counter)
# Sorting topics-sentiment combo based on their appearance
topicDF['TopTopics'] = topicDF['TopTopics'].apply(lambda x: sorted(x, key=x.get, reverse=True))
# Select Top k topics-sentiment combo for each product/review
topicDF['TopTopics'] = topicDF['TopTopics'].apply(lambda x: x[:TOP_TOPICS])
# Sneak peek
topicDF.head()
Our final DataFrame consists of this topic information and sentiment information joined back to the final DataFrame named feedbackTopics that we saved on Amazon S3 in our first notebook.
# Adding the topic-sentiment combo back to product metadata
finalDF = S3_FEEDBACK_TOPICS.merge(topicDF, on='asin', how='left')
# Only selecting a subset of fields
finalDF = finalDF[['asin', 'TopTopics', 'category', 'title']]
# Saving the final output locally
finalDF.to_csv(S3_FINAL_OUTPUT, index=False)Use Amazon QuickSight to visualize the data
You can use QuickSight to visualize the data and generate reports. QuickSight is a business intelligence (BI) service that you can use to consume data from many different sources and build intelligent dashboards. In this example, we generate a QuickSight analysis using the final dataset we produced, as shown in the following example visualizations.
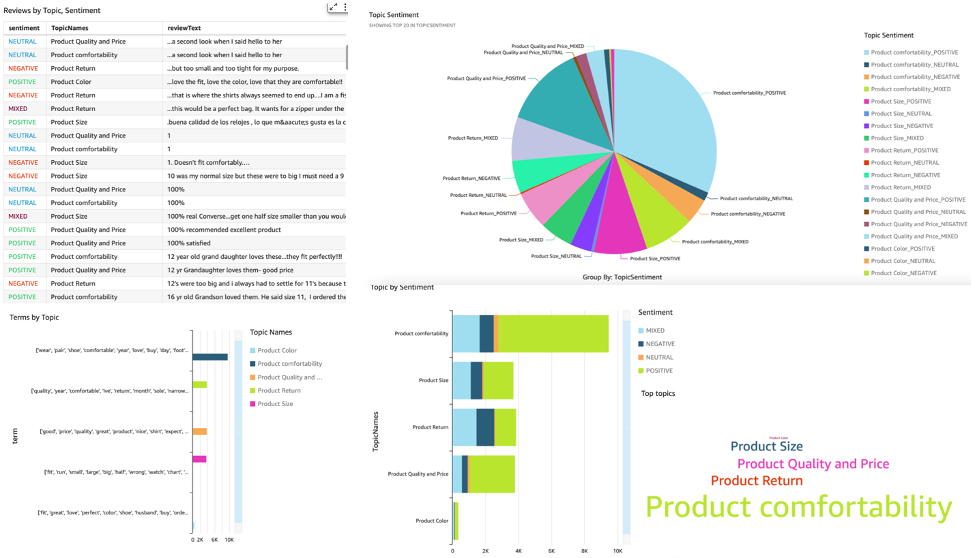
To learn more about Amazon QuickSight, refer to Getting started with Amazon Quicksight.
Cleanup
At the end, we need to shut down the notebook instance we have used in this experiment from AWS Console.
Conclusion
In this post, we demonstrated how to use Amazon Comprehend to analyze product reviews and find the top topics using topic modeling as a technique. Topic modeling enables you to look through multiple topics and organize, understand, and summarize them at scale. You can quickly and easily discover hidden patterns that are present across the data, and then use that insight to make data-driven decisions. You can use topic modeling to solve numerous business problems, such as automatically tagging customer support tickets, routing conversations to the right teams based on topic, detecting the urgency of support tickets, getting better insights from conversations, creating data-driven plans, creating problem-focused content, improving sales strategy, and identifying customer issues and frictions.
These are just a few examples, but you can think of many more business problems that you face in your organization on a daily basis, and how you can use topic modeling with other ML techniques to solve those.
About the Authors
 Gurpreet is a Data Scientist with AWS Professional Services based out of Canada. She is passionate about helping customers innovate with Machine Learning and Artificial Intelligence technologies to tap business value and insights from data. In her spare time, she enjoys hiking outdoors and reading books.i
Gurpreet is a Data Scientist with AWS Professional Services based out of Canada. She is passionate about helping customers innovate with Machine Learning and Artificial Intelligence technologies to tap business value and insights from data. In her spare time, she enjoys hiking outdoors and reading books.i
 Rushdi Shams is a Data Scientist with AWS Professional Services, Canada. He builds machine learning products for AWS customers. He loves to read and write science fictions.
Rushdi Shams is a Data Scientist with AWS Professional Services, Canada. He builds machine learning products for AWS customers. He loves to read and write science fictions.
 Wrick Talukdar is a Senior Architect with Amazon Comprehend Service team. He works with AWS customers to help them adopt machine learning on a large scale. Outside of work, he enjoys reading and photography.
Wrick Talukdar is a Senior Architect with Amazon Comprehend Service team. He works with AWS customers to help them adopt machine learning on a large scale. Outside of work, he enjoys reading and photography.