Posted by Tony Mak, Software Engineer, Google Research and Simon Tong, Principal Engineer, Google Research, Brain Team
Despite the success and widespread adoption of smartphones, using them to compose longer pieces of text is still quite cumbersome. As one writes, grammatical errors can often creep into the text (especially undesirable in formal situations), and correcting these errors can be time consuming on a small display with limited controls.
To address some of these challenges, we are launching a grammar correction feature that is directly built into Gboard on Pixel 6 that works entirely on-device to preserve privacy, detecting and suggesting corrections for grammatical errors while the user is typing. Building such functionality required addressing a few key obstacles: memory size limitations, latency requirements, and handling partial sentences. Currently, the feature is capable of correcting English sentences (we plan to expand to more languages in the near future) and available on almost any app with Gboard1.
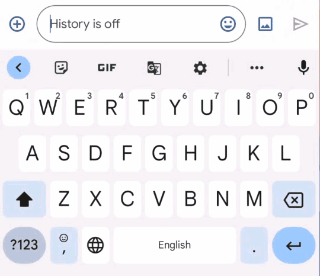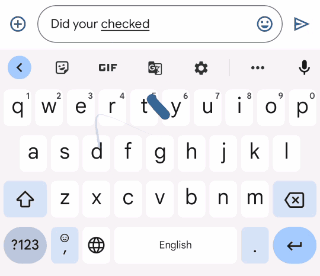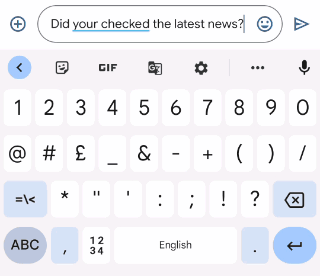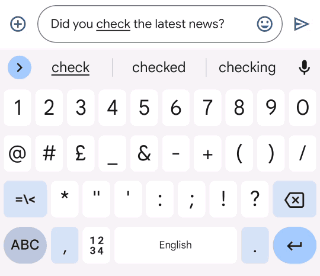 |
| Gboard suggests how to correct an ungrammatical sentence as the user types. |
Model Architecture
We trained a sequence-to-sequence neural network to take an input sentence (or a sentence prefix) and output the grammatically correct version — if the original text is already grammatically correct, the output of the model is identical to its input, indicating that no corrections are needed. The model uses a hybrid architecture that combines a Transformer encoder with an LSTM decoder, a combination that provides a good balance of quality and latency.
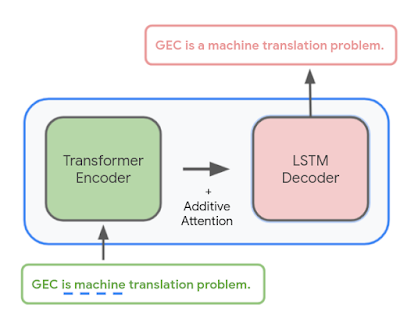 |
| Overview of the grammatical error correction (GEC) model architecture. |
Mobile devices are constrained by limited memory and computational power, which make it more difficult to build a high quality grammar checking system. There are a few techniques we use to build a small, efficient, and capable model.
- Shared embedding: Because the input and output of the model are structurally similar (e.g., both are text in the same language), we share some of the model weights between the Transformer encoder and the LSTM decoder, which reduces the model file size considerably without unduly affecting accuracy.
- Factorized embedding: The model splits a sentence into a sequence of predefined tokens. To achieve good quality, we find that it is important to use a large vocabulary of predefined tokens, however, this substantially increases the model size. A factorized embedding separates the size of the hidden layers from the size of the vocabulary embedding. This enables us to have a model with a large vocabulary without significantly increasing the number of total weights.
- Quantization: To reduce the model size further, we perform post-training quantization, which allows us to store each 32-bit floating point weight using only 8-bits. While this means that each weight is stored with lower fidelity, nevertheless, we find that the quality of the model is not materially affected.
By employing these techniques, the resulting model takes up only 20MB of storage and performs inference on 60 input characters under 22ms on the Google Pixel 6 CPU.
Training the Model
In order to train the model, we needed training data in the form of <original, corrected> text pairs.
One possible approach to generating a small on-device model would be to use the same training data as a large cloud-based grammar model. While this data produces a reasonably high quality on-device model, we found that using a technique called hard distillation to generate training data that is better-matched to the on-device domain yields even better quality results.
Hard distillation works as follows: We first collected hundreds of millions of English sentences from across the public web. We then used the large cloud-based grammar model to generate grammar corrections for those sentences. This training dataset of <original, corrected> sentence pairs is then used to train a smaller on-device model that can correct full sentences. We found that the on-device model built from this training dataset produces significantly higher quality suggestions than a similar-sized on-device model built on the original data used to train the cloud-based model.
Before training the model from this data, however, there is another issue to address. To enable the model to correct grammar as the user types (an important capability of mobile devices) it needs to be able to handle sentence prefixes. While this enables grammar correction when the user has only typed part of a sentence, this capability is particularly useful in messaging apps, where the user often omits the final period in a sentence and presses the send button as soon as they finish typing. If grammar correction is only triggered on complete sentences, it might miss many errors.
This raises the question of how to decide whether a given sentence prefix is grammatically correct. We used a heuristic to solve this — if a given sentence prefix can be completed to form a grammatically correct sentence, we then consider it grammatically correct. If not, it is assumed to be incorrect.
| What the user has typed so far | Suggested grammar correction | |
| She puts a lot | ||
| She puts a lot of | ||
| She puts a lot of effort | ||
| She puts a lot of effort yesterday | Replace “puts” with “put in”. |
| GEC on incomplete sentences. There is no correction for valid sentence prefixes. |
We created a second dataset suitable for training a large cloud-based model, but this time focusing on sentence prefixes. We generated the data using the aforementioned heuristic by taking the <original, corrected> sentence pairs from the cloud-based model’s training dataset and randomly sampling aligned prefixes from them.
For example, given the <original, corrected> sentence pair:
Original sentence: She puts a lot of effort yesterday afternoon.
Corrected sentence: She put in a lot of effort yesterday afternoon.
We might sample the following prefix pairs:
Original prefix: She puts
Corrected prefix: She put in
Original prefix: She puts a lot of effort yesterday
Corrected prefix: She put in a lot of effort yesterday
We then autocompleted each original prefix to a full sentence using a neural language model (similar in spirit to that used by SmartCompose). If a full-sentence grammar model finds no errors in the full sentence, then that means there is at least one possible way to complete this original prefix without making any grammatical errors, so we consider the original prefix to be correct and output <original prefix, original prefix> as a training example. Otherwise, we output <original prefix, corrected prefix>. We used this training data to train a large cloud-based model that can correct sentence prefixes, then used that model for hard distillation, generating new <original, corrected> sentence prefix pairs that are better-matched to the on-device domain.
Finally, we constructed the final training data for the on-device model by combining these new sentence prefix pairs with the full sentence pairs. The on-device model trained on this combined data is then capable of correcting both full sentences as well as sentence prefixes.
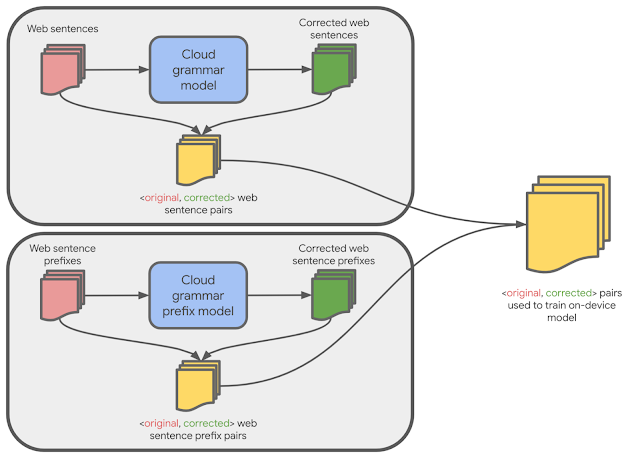 |
| Training data for the on-device model is generated from cloud-based models. |
Grammar Correction On-Device
Gboard sends a request to the on-device grammar model whenever the user has typed more than three words, whether the sentence is completed or not. To provide a quality user experience, we underline the grammar mistakes and provide replacement suggestions when the user interacts with them. However, the model outputs only corrected sentences, so those need to be transformed into replacement suggestions. To do this, we align the original sentence and the corrected sentence by minimizing the Levenshtein distance (i.e., the number of edits that are needed to transform the original sentence to the corrected sentence).
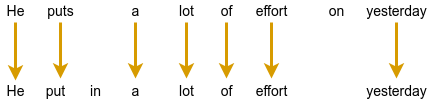 |
| Extracting edits by aligning the corrected sentence to the original sentence. |
Finally, we transform the insertion edits and deletion edits to be replacement edits. In the above example, we transform the suggested insertion of “in” to be an edit that suggests replacing “puts” with “put in”. And we similarly suggest replacing “effort on” with “effort”.
Conclusion
We have built a small high-quality grammar correction model by designing a compact model architecture and leveraging a cloud-based grammar system during training via hard distillation. This compact model enables users to correct their text entirely on their own device without ever needing to send their keystrokes to a remote server.
Acknowledgements
We gratefully acknowledge the key contributions of the other team members, including Abhanshu Sharma, Akshay Kannan, Bharath Mankalale, Chenxi Ni, Felix Stahlberg, Florian Hartmann, Jacek Jurewicz, Jayakumar Hoskere, Jenny Chin, Kohsuke Yatoh, Lukas Zilka, Martin Sundermeyer, Matt Sharifi, Max Gubin, Nick Pezzotti, Nithi Gupta, Olivia Graham, Qi Wang, Sam Jaffee, Sebastian Millius, Shankar Kumar, Sina Hassani, Vishal Kumawat, and Yuanbo Zhang, Yunpeng Li, Yuxin Dai. We would also like to thank Xu Liu and David Petrou for their support.
1The feature will eventually be available in all apps with Gboard, but is currently unavailable for those in WebView. ↩
