The largest AI models can require months to train on today’s computing platforms. That’s too slow for businesses.
AI, high performance computing and data analytics are growing in complexity with some models, like large language ones, reaching trillions of parameters.
The NVIDIA Hopper architecture is built from the ground up to accelerate these next-generation AI workloads with massive compute power and fast memory to handle growing networks and datasets.
Transformer Engine, part of the new Hopper architecture, will significantly speed up AI performance and capabilities, and help train large models within days or hours.
Training AI Models With Transformer Engine
Transformer models are the backbone of language models used widely today, such asBERT and GPT-3. Initially developed for natural language processing use cases, their versatility is increasingly being applied to computer vision, drug discovery and more.
However, model size continues to increase exponentially, now reaching trillions of parameters. This is causing training times to stretch into months due to huge amounts of computation, which is impractical for business needs.
Transformer Engine uses 16-bit floating-point precision and a newly added 8-bit floating-point data format combined with advanced software algorithms that will further speed up AI performance and capabilities.
AI training relies on floating-point numbers, which have fractional components, like 3.14. Introduced with the NVIDIA Ampere architecture, the TensorFloat32 (TF32) floating-point format is now the default 32-bit format in the TensorFlow and PyTorch frameworks.
Most AI floating-point math is done using 16-bit “half” precision (FP16), 32-bit “single” precision (FP32) and, for specialized operations, 64-bit “double” precision (FP64). By reducing the math to just eight bits, Transformer Engine makes it possible to train larger networks faster.
When coupled with other new features in the Hopper architecture — like the NVLink Switch system, which provides a direct high-speed interconnect between nodes — H100-accelerated server clusters will be able to train enormous networks that were nearly impossible to train at the speed necessary for enterprises.
Diving Deeper Into Transformer Engine
Transformer Engine uses software and custom NVIDIA Hopper Tensor Core technology designed to accelerate training for models built from the prevalent AI model building block, the transformer. These Tensor Cores can apply mixed FP8 and FP16 formats to dramatically accelerate AI calculations for transformers. Tensor Core operations in FP8 have twice the throughput of 16-bit operations.
The challenge for models is to intelligently manage the precision to maintain accuracy while gaining the performance of smaller, faster numerical formats. Transformer Engine enables this with custom, NVIDIA-tuned heuristics that dynamically choose between FP8 and FP16 calculations and automatically handle re-casting and scaling between these precisions in each layer.
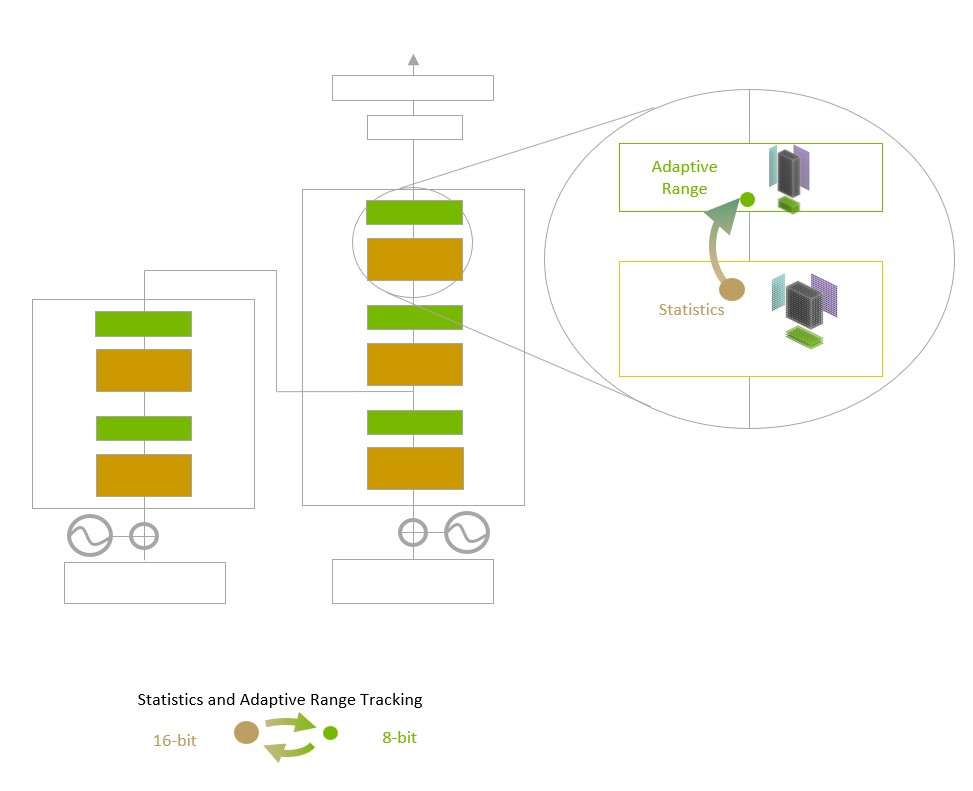
The NVIDIA Hopper architecture also advances fourth-generation Tensor Cores by tripling the floating-point operations per second compared with prior-generation TF32, FP64, FP16 and INT8 precisions. Combined with Transformer Engine and fourth-generation NVLink, Hopper Tensor Cores enable an order-of-magnitude speedup for HPC and AI workloads.
Revving Up Transformer Engine
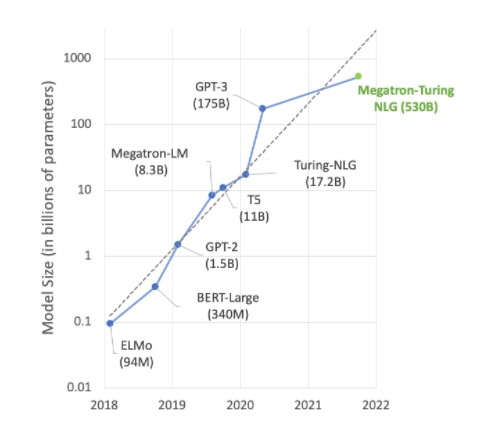
Much of the cutting-edge work in AI revolves around large language models like Megatron 530B. The chart below shows the growth of model size in recent years, a trend that is widely expected to continue. Many researchers are already working on trillion-plus parameter models for natural language understanding and other applications, showing an unrelenting appetite for AI compute power.
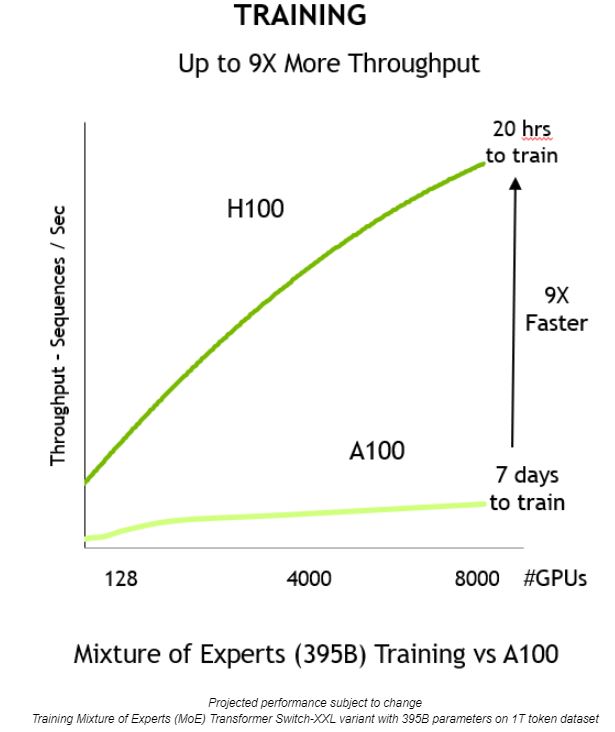
Meeting the demand of these growing models requires a combination of computational power and a ton of high-speed memory. The NVIDIA H100 Tensor Core GPU delivers on both fronts, with the speedups made possible by Transformer Engine to take AI training to the next level.
When combined, these innovations deliver higher throughput and a 9x reduction in time to train, from seven days to just 20 hours:
Transformer Engine can also be used for inference without any data format conversions. Previously, INT8 was the go-to precision for optimal inference performance. However, it requires that the trained networks be converted to INT8 as part of the optimization process, something the NVIDIA TensorRT inference optimizer makes easy.
Using models trained with FP8 will allow developers to skip this conversion step altogether and do inference operations using that same precision. And like INT8-formatted networks, deployments using Transformer Engine can run in a much smaller memory footprint.
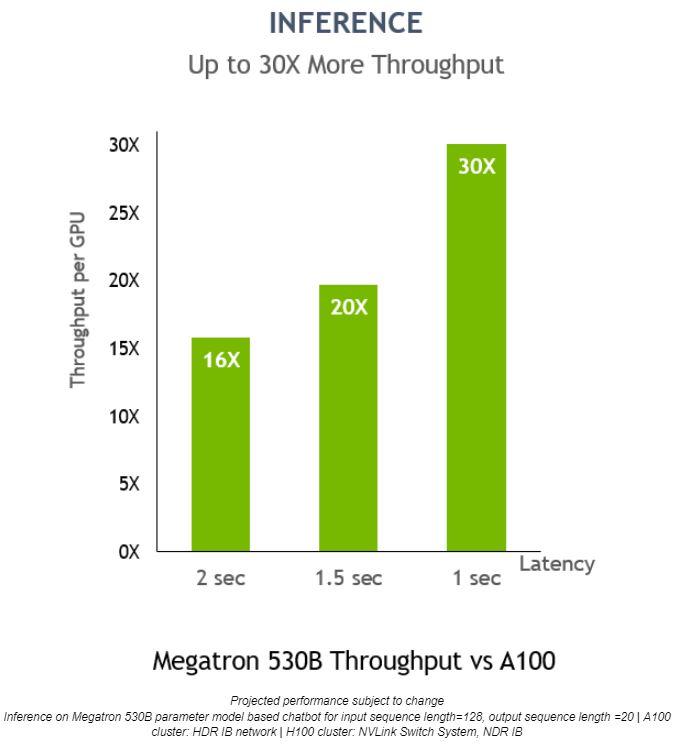
On Megatron 530B, NVIDIA H100 inference per-GPU throughput is up to 30x higher than NVIDIA A100, with a 1-second response latency, showcasing it as the optimal platform for AI deployments:
To learn more about NVIDIA H100 GPU and the Hopper architecture, watch the GTC 2022 keynote from Jensen Huang. Register for GTC 2022 for free to attend sessions with NVIDIA and industry leaders.”
The post H100 Transformer Engine Supercharges AI Training, Delivering Up to 6x Higher Performance Without Losing Accuracy appeared first on NVIDIA Blog.