Posted by Ivan Grishchenko, Valentin Bazarevsky and Na Li, Google Research
Today we’re excited to launch MediaPipe‘s BlazePose in our new pose-detection API. BlazePose is a high-fidelity body pose model designed specifically to support challenging domains like yoga, fitness and dance. It can detect 33 keypoints, extending the 17 keypoint topology of the original PoseNet model we launched a couple of years ago. These additional keypoints provide vital information about face, hands, and feet location with scale and rotation. Together with our face and hand models they can be used to unlock various domain-specific applications like gesture control or sign language without special hardware. With today’s release we enable developers to use the same models on the web that are powering MLKit Pose and MediaPipe Python unlocking the same great performance across all devices.
The new TensorFlow.js pose-detection API supports two runtimes: TensorFlow.js and MediaPipe. TensorFlow.js provides the flexibility and wider adoption of JavaScript, optimized for several backends including WebGL (GPU), WASM (CPU), and Node. MediaPipe capitalizes on WASM with GPU accelerated processing and provides faster out-of-the-box inference speed. The MediaPipe runtime currently lacks Node and iOS Safari support, but we’ll be adding the support soon.
 |
| BlazePose can track 33 keypoints across a variety complex poses in real-time. |
Installation
To use BlazePose with the new pose-detection API, you have to first decide whether to use the TensorFlow.js runtime or MediaPipe runtime. To understand the advantages of each runtime, check the performance and loading times section later in this document for further details.
For each runtime, you can use either script tag or NPM for installation.
Using TensorFlow.js runtime:
- Through script tag:
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-core"></script>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-converter"></script>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-backend-webgl"></script>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow-models/pose-detection"></script> - Through NPM:
yarn add @tensorflow/tfjs-core, @tensorflow/tfjs-converter
yarn add @tensorflow/tfjs-backend-webgl
yarn add @tensorflow-models/pose-detection
Using MediaPipe runtime:
- Through script tag:
<script src="https://cdn.jsdelivr.net/npm/@mediapipe/pose"></script>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow-models/pose-detection"></script> - Through NPM:
yarn add @mediapipe/pose
yarn add @tensorflow-models/pose-detection
Try it yourself!
Once the package is installed, you only need to follow the few steps below to start using it. There are three variants of the model: lite, full, and heavy. The model accuracy increases from lite to heavy, while the inference speed decreases and memory footprint increases. The heavy variant is intended for applications that require high accuracy, while the lite variant is intended for latency-critical applications. The full variant is a balanced option, which is also the default option here.
Using TensorFlow.js runtime:
// Import TFJS runtime with side effects.
import '@tensorflow/tfjs-backend-webgl';
import * as poseDetection from '@tensorflow-models/pose-detection';
// Create a detector.
const detector = await poseDetection.createDetector(poseDetection.SupportedModels.BlazePose, {runtime: 'tfjs'});Using MediaPipe runtime:
// Import MediaPipe runtime with side effects.
import '@mediapipe/pose';
import * as poseDetection from '@tensorflow-models/pose-detection';
// Create a detector.
const detector = await poseDetection.createDetector(poseDetection.SupportedModels.BlazePose, {runtime: 'mediapipe'});You can also choose the lite or the heavy variant by setting the modelType field, as shown below:
// Create a detector.
const detector = await poseDetection.createDetector(poseDetection.SupportedModels.BlazePose, {runtime, modelType:'lite'});// Pass in a video stream to the model to detect poses.
const video = document.getElementById('video');
const poses = await detector.estimatePoses(video);Each pose contains 33 keypoints, with absolute x, y coordinates, confidence score and name:
console.log(poses[0].keypoints);
// Outputs:
// [
// {x: 230, y: 220, score: 0.9, name: "nose"},
// {x: 212, y: 190, score: 0.8, name: "left_eye_inner"},
// ...
// ]Refer to our ReadMe (TFJS runtime, MediaPipe runtime) for more details about the API.
As you begin to play and develop with BlazePose, we would appreciate your feedback and contributions. If you make something using this model, tag it with #MadeWithTFJS on social media so we can find your work, as we would love to see what you create.
Model deep dive
BlazePose provides real-time human body pose perception in the browser, working up to 4 meters from the camera.
We trained BlazePose specifically for highly demanded single-person use cases like yoga, fitness, and dance which require precise tracking of challenging postures, enabling the overlay of digital content and information on top of the physical world in augmented reality, gesture control, and quantifying physical exercises.
For pose estimation, we utilize our proven two-step detector-tracker ML pipeline. Using a detector, this pipeline first locates the pose region-of-interest (ROI) within the frame. The tracker subsequently predicts all 33 pose keypoints from this ROI. Note that for video use cases, the detector is run only on the first frame. For subsequent frames we derive the ROI from the previous frame’s pose keypoints as discussed below.
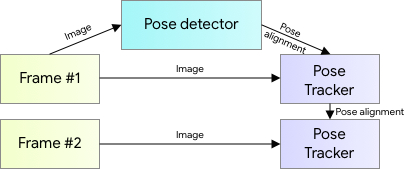 |
| BlazePose architecture. |
BlazePose’s topology contains 33 points extending 17 points by COCO with additional points on palms and feet to provide lacking scale and orientation information for limbs, which is vital for practical applications like fitness, yoga and dance.
Since the BlazePose CVPR’2020 release, MediaPipe has been constantly improving the models’ quality to remain state-of-the-art on the web / edge for single person pose tracking. Besides running through the TensorFlow.js pose-detection API, BlazePose is also available on Android, iOS and Python via MediaPipe and ML Kit. For detailed information, read the Google AI Blog post and the model card.
BlazePose Browser Performance
TensorFlow.js continuously seeks opportunities to bring the latest and fastest runtime for browsers. To achieve the best performance for this BlazePose model, in addition to the TensorFlow.js runtime (w/ WebGL backend) we further integrated with the MediaPipe runtime via the MediaPipe JavaScript Solutions. The MediaPipe runtime leverages WASM to utilize state-of-the-art pipeline acceleration available across platforms, which also powers Google products such as Google Meet.
Inference speed:
To quantify the inference speed of BlazePose, we benchmark the model across multiple devices.
|
MacBook Pro 15” 2019. Intel core i9. AMD Radeon Pro Vega 20 Graphics. (FPS) |
iPhone 11 (FPS) |
Pixel 5 (FPS) |
Desktop Intel i9-10900K. Nvidia GTX 1070 GPU. (FPS) |
|
|
MediaPipe Runtime With WASM & GPU Accel. |
92 | 81 | 38 |
N/A |
32 | 22 | N/A |
160 | 140 | 98 |
|
TensorFlow.js Runtime |
48 | 53 | 28 |
34 | 30 | N/A |
13 | 11 | 5 |
44 | 40 | 30 |
Inference speed of BlazePose across different devices and runtimes. The first number in each cell is for the lite model, and the second number is for the full model, the third number is for the heavy model. Certain model types and runtime do not work at time of this release, and we will be adding the support soon.
To see the model’s FPS on your device, try our demo. You can switch the model type and runtime live in the demo UI to see what works best for your device.
Loading times:
Bundle size can affect initial page loading experience, such as Time-To-Interactive (TTI), UI rendering, etc. We evaluate the pose-detection API and the two runtime options. The bundle size affects file fetching time and UI smoothness, because processing the code and loading them into memory will compete with UI rendering on CPU. It also affects when the model is available to make inference.
There is a difference of how things are loaded between the two runtimes. For the MediaPipe runtime, only the @tensorflow-models/pose-detection and the @mediapipe/pose library are loaded at initial page download; the runtime and the model assets are loaded when the createDetector method is called. For the TF.js runtime with WebGL backend, the runtime is loaded at initial page download; only the model assets are loaded when the createDetector method is called. The TensorFlow.js package sizes can be further reduced with a custom bundle technique. Also, if your application is currently using TensorFlow.js, you don’t need to load those packages again, models will share the same TensorFlow.js runtime. Choose the runtime that best suits your latency and bundle size requirements. A summary of loading times and bundle sizes is provided below:
|
Bundle Size gzipped + minified |
Average Loading Time WiFi: download speed 100Mbps |
|
|
MediaPipe Runtime |
||
|
Initial Page Load |
22.1KB |
0.04s |
|
Initial Detector Creation: |
||
|
Runtime |
1.57MB |
|
|
Lite model |
10.6MB |
1.91s |
|
Full model |
14MB |
1.91s |
|
Heavy model |
34.9MB |
4.82s |
|
TensorFlow.js Runtime |
||
|
Initial Page Load |
162.6KB |
0.07s |
|
Initial Detector Creation: |
||
|
Lite model |
10.4MB |
1.91s |
|
Full model |
13.8MB |
1.91s |
|
Heavy model |
34.7MB |
4.82s |
Bundle size and loading time analysis for MediaPipe and TF.js runtime. The loading time is estimated based on a simulated WiFi network with 100Mbps download speed and includes time from request sent to content downloaded, see what is included in more detail here.
Looking ahead
In the future, we plan to extend TensorFlow.js pose-detection API with new features like BlazePose GHUM 3D pose. We also plan to speed up the TensorFlow.js WebGL backend to make model execution even faster. This will be achieved through repeated benchmarking and backend optimization, such as operator fusion. We will also bring Node.js support in the near future.
Acknowledgements
We would like to acknowledge our colleagues, who participated in creating BlazePose GHUM 3D: Eduard Gabriel Bazavan, Cristian Sminchisescu, Tyler Zhu, the other contributors to MediaPipe: Chuo-Ling Chang, Michael Hays and Ming Guang Yong, along with those involved with the TensorFlow.js pose-detection API: Ping Yu, Sandeep Gupta, Jason Mayes, and Masoud Charkhabi.