Recently, Llama 2 was released and has attracted a lot of interest from the machine learning community. Amazon EC2 Inf2 instances, powered by AWS Inferentia2, now support training and inference of Llama 2 models. In this post, we show low-latency and cost-effective inference of Llama-2 models on Amazon EC2 Inf2 instances using the latest AWS Neuron SDK release. We first introduce how to create, compile and deploy the Llama-2 model and explain the optimization techniques introduced by AWS Neuron SDK to achieve high performance at low cost. We then present our benchmarking results. Lastly, we show how the Llama-2 model can be deployed through Amazon SageMaker using TorchServe on an Inf2 instance.
What is Llama 2
Llama 2 is an auto-regressive language model that uses an optimized transformer architecture. Llama 2 is intended for commercial and research use in English. It comes in multiple sizes—7 billion, 13 billion, and 70 billion parameters—as well as pre-trained and fine-tuned variations. According to Meta, the tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align to human preferences for helpfulness and safety. Llama 2 was pre-trained on 2 trillion tokens of data from publicly available sources. The tuned models are intended for assistant-like chat, whereas pre-trained models can be adapted for a variety of natural language generation tasks. Regardless of which version of the model a developer uses, the responsible use guide from Meta can assist in guiding additional fine-tuning that may be necessary to customize and optimize the models with appropriate safety mitigations.
Amazon EC2 Inf2 instances Overview
Amazon EC2 Inf2 instances, featuring Inferentia2, provide 3x higher compute, 4x more accelerator memory, resulting in up to 4x higher throughput, and up to 10x lower latency, compared to the first generation Inf1 instances.
Large language model (LLM) inference is a memory bound workload, performance scales up with more accelerator memory bandwidth. Inf2 instances are the only inference optimized instances in Amazon EC2 to provide high speed accelerator interconnect (NeuronLink) enabling high performance large LLM model deployments with cost effective distributed inference. You can now efficiently and cost-effectively deploy billion-scale LLMs across multiple accelerators on Inf2 instances.
Inferentia2 supports FP32, TF32, BF16, FP16, UINT8, and the new configurable FP8 (cFP8) data type. AWS Neuron can take high-precision FP32 and FP16 models and autocast them to lower-precision data types while optimizing accuracy and performance. Autocasting reduces time to market by removing the need for lower-precision retraining and enabling higher-performance inference with smaller data types.
To make it flexible and extendable to deploy constantly evolving deep learning models, Inf2 instances have hardware optimizations and software support for dynamic input shapes as well as custom operators written in C++ through the standard PyTorch custom operator programming interfaces.
Transformers Neuron (transformers-neuronx)
Transformers Neuron is a software package that enables PyTorch users to deploy performance optimized LLM inference. It has an optimized version of transformer models implemented with XLA high level operators (HLO), which enables sharding tensors across multiple NeuronCores, a.k.a. tensor parallelism, and performance optimizations such as parallel context encoding and KV caching for Neuron hardware. The Llama 2 source code in XLA HLOs can be found here.
Llama 2 is supported in Transformers Neuron through the LlamaForSampling class. Transformers Neuron provides a seamless user experience with Hugging Face models to provide optimized inference on Inf2 instances. More details can be found from the Transforms Neuron Developer Guide. In the following section, we will explain how to deploy the Llama-2 13B model using Transformers Neuron. And, this example also applies to other Llama-based models.
Llama 2 model inference with Transformers Neuron
Create model, compile and deploy
We have three simple steps here to create, compile and deploy the model on Inf2 instances.
- Create a CPU model, use this script or the following code snippet to serialize and save checkpoints in a local directory.
from transformers import AutoModelForCausalLM
from transformers_neuronx.module import save_pretrained_split
model_cpu = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-13b-hf", low_cpu_mem_usage=True)
model_dir = "./llama-2-13b-split"
save_pretrained_split(model_cpu, model_dir)
- Load and compile model from the local directory that you saved serialized checkpoints using the following.
To load the Llama 2 model, we useLlamaForSamplingfrom Transformers Neuron. Note that the environment variableNEURON_RT_NUM_CORESspecifies the number of NeuronCores to be used at runtime and it should match the tensor parallelism (TP) degree specified for the model. Also,NEURON_CC_FLAGSenables compiler optimization on decoder-only LLM models.
from transformers_neuronx.llama.model import LlamaForSampling
os.environ['NEURON_RT_NUM_CORES'] = '24'
os.environ['NEURON_CC_FLAGS'] = '--model-type=transformer'
model = LlamaForSampling.from_pretrained(
model_dir,
batch_size=1,
tp_degree=24,
amp='bf16',
n_positions=16,
context_length_estimate=[8]
)
Now let’s compile the model and load model weights into device memory with a one liner API.
model.to_neuron()
- Finally let’s run the inference on the compiled model. Note that both input and output of the
samplefunction are a sequence of tokens.
inputs = torch.tensor([[1, 16644, 31844, 312, 31876, 31836, 260, 3067, 2228, 31844]])
seq_len = 16
outputs = model.sample(inputs, seq_len, top_k=1)
Inference optimizations in Transformers Neuron
Tensor parallelism
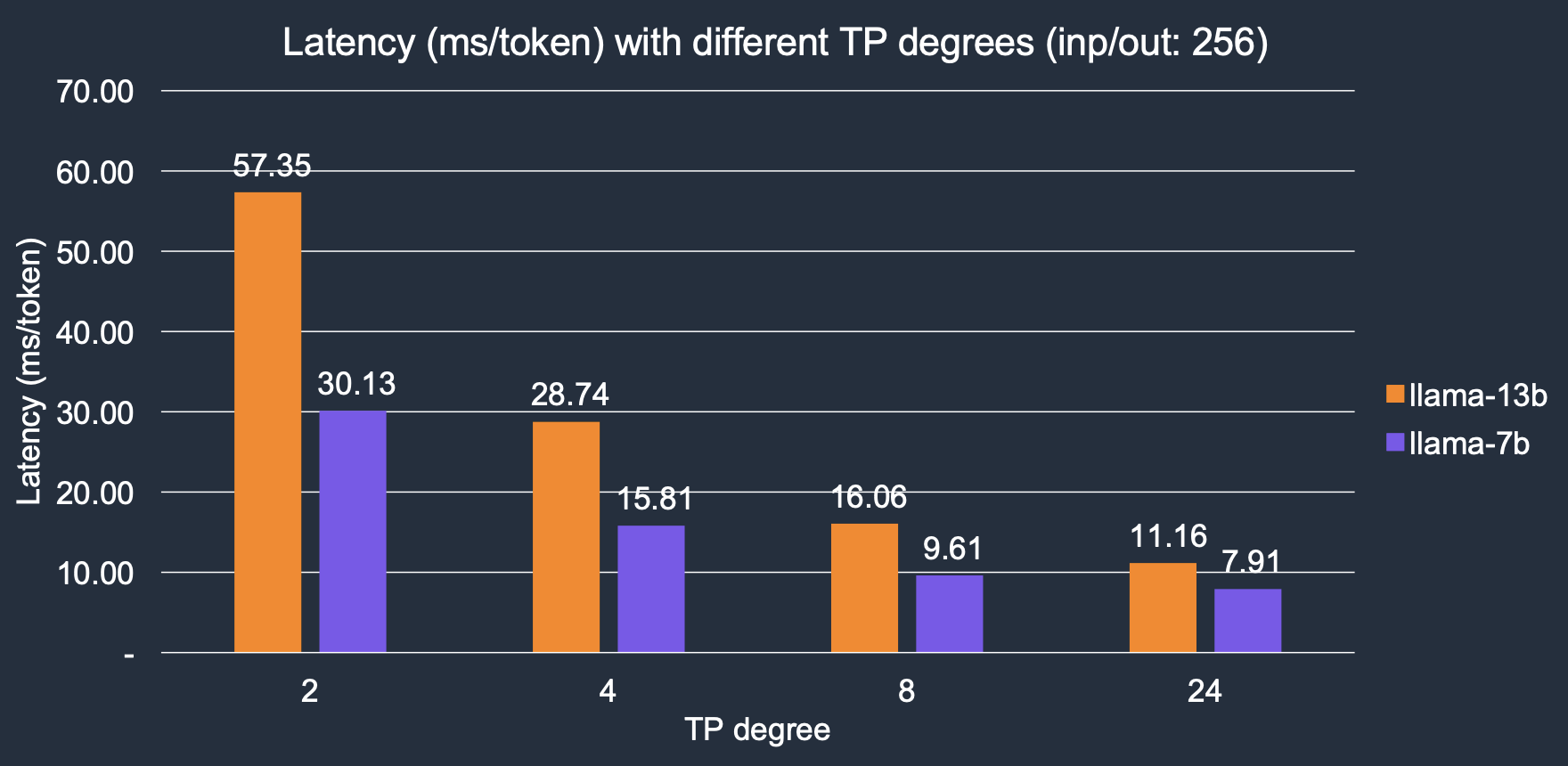
Transformer Neuron implements parallel tensor operations across multiple NeuronCores. We denote the number of cores to be used for inference as TP degree. Larger TP degree provides higher memory bandwidth, leading to lower latency, as LLM token generation is a memory-IO bound workload. With increasing the TP degree, the inference latency has decreased significantly, our results shows, ~4x overall speed up with increased TP degrees from 2 to 24. For the Llama-2 7B model, latency decreases from 30.1 ms/token with 2 cores to 7.9 ms/token with 24 cores; similarly for the Llama-2 13B model, it goes down from 57.3 ms/token to 11.1 ms/token.
Parallel context encoding
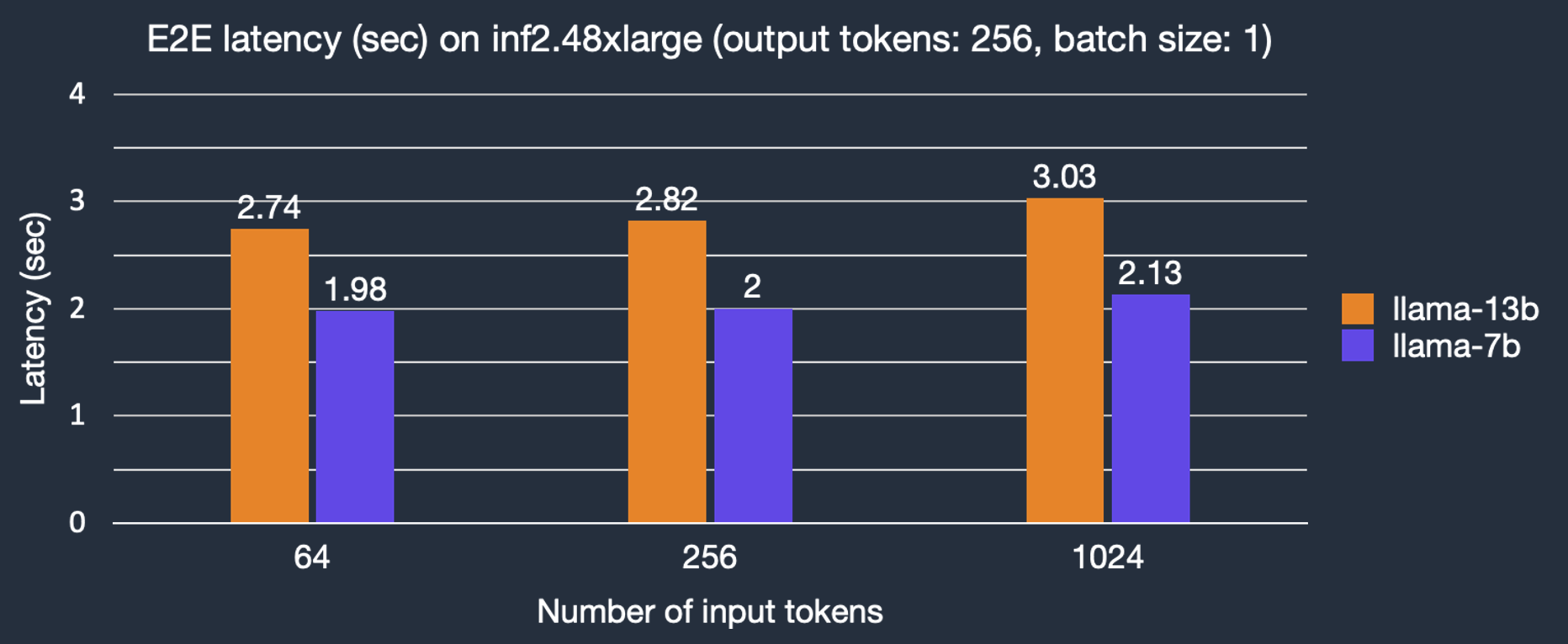
In the transformer architecture, tokens are produced in a sequential procedure called autoregressive sampling while input prompt tokens can be processed in parallel with parallel context encoding. This can significantly reduce the latency for input prompt context encoding before token generation through autoregressive sampling. By default, the parameter context_length_estimate would be set as a list of power-of-2 numbers which aims to cover a wide variety of context lengths. Depending on the use case, it can be set to custom numbers. This can be done when creating the Llama 2 model using LlamaForSampling.from_pretrained. We characterize the impact of input token length on end-to-end (E2E) latency. As shown in the figure, latency for text generation with the Llama-2 7B model only slightly increases with bigger input prompts, thanks to parallel context encoding.
KV caching
Self-attention block performs the self-attention operation with KV vectors. And, KV vectors are calculated using token embeddings and weights of KV and thus associated with tokens. In naive implementations, for each generated token, the entire KV cache is recalculated, but this reduces performance. Therefore Transformers Neuron library is reusing previously calculated KV vectors to avoid unnecessary computation, also known as KV caching, to reduce latency in the autoregressive sampling phase.
Benchmarking results
We benchmarked the latency and cost for both Llama-2 7B and 13B models under different conditions, i.e., number of output tokens, instance types. Unless specified, we use data type ‘bf16’ and batch size of 1 as this is a common configuration for real-time applications like chatbot and code assistant.
Latency
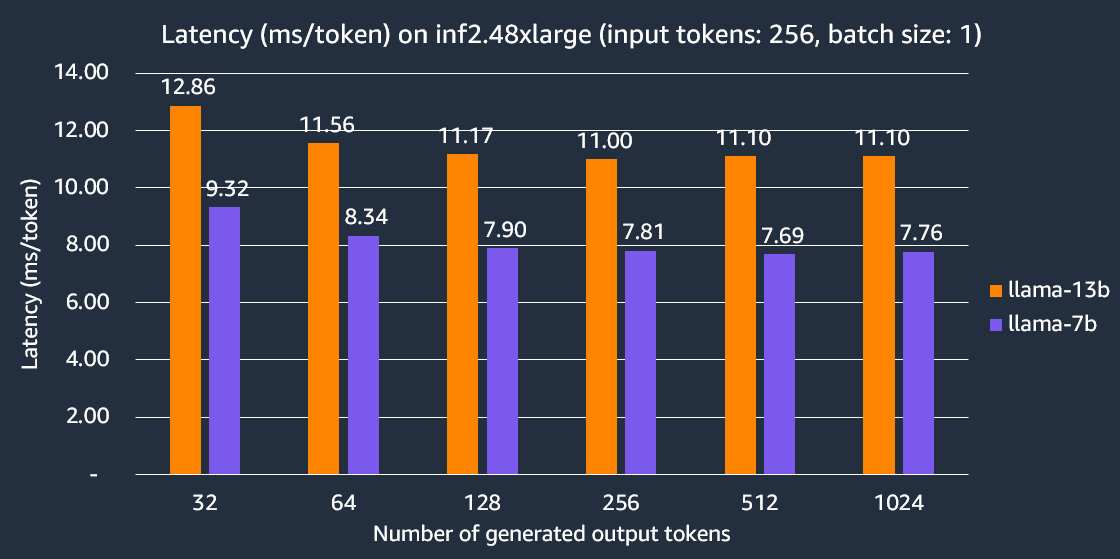
The following graphs shows the per token latency on inf2.48xlarge instance with TP degree 24. Here, the latency per output token is calculated as the end-to-end latency divided by the number of output tokens. Our experiments show Llama-2 7B end-to-end latency to generate 256 tokens is 2x faster compared to other comparable inference-optimized EC2 instances.
Throughput
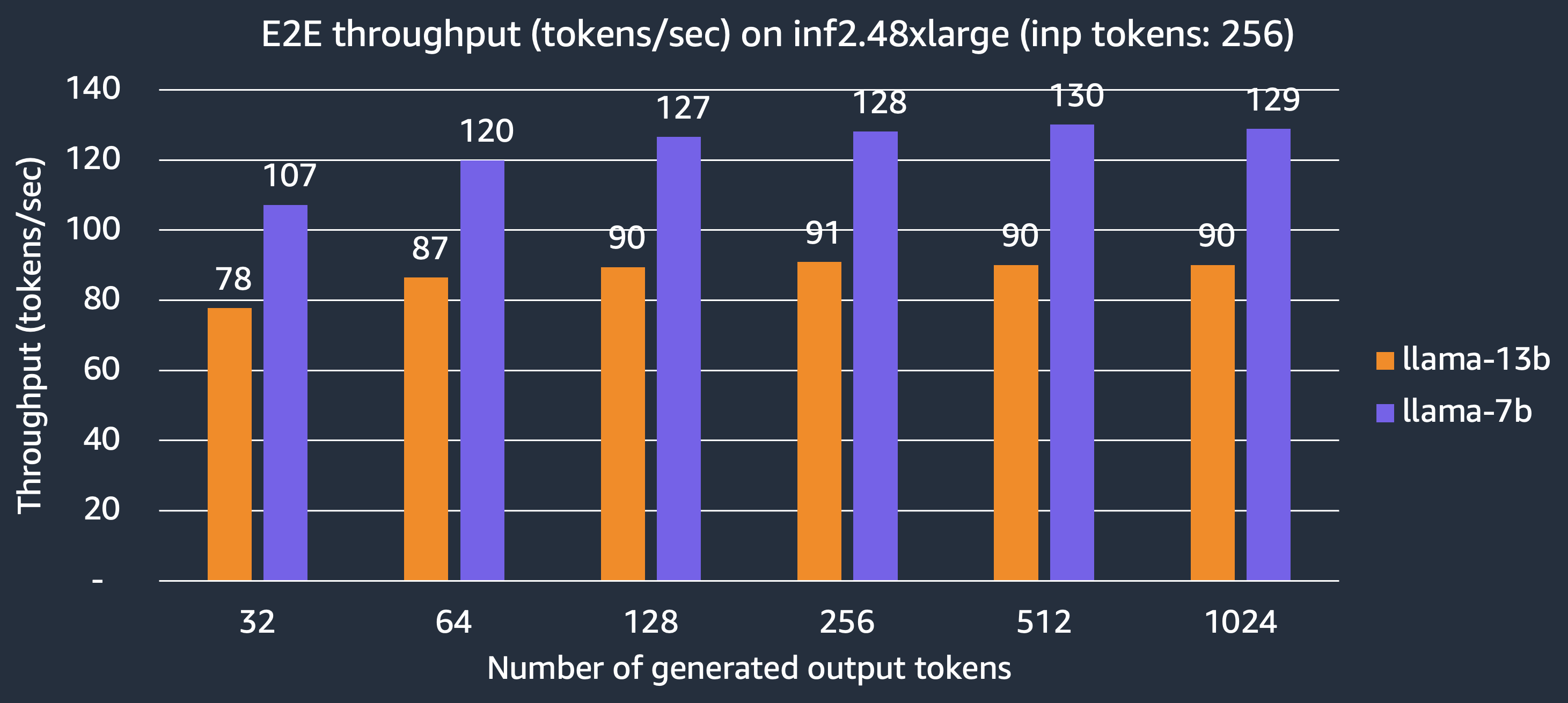
We now show the number of tokens generated per second for the Llama-2 7B and 13B models that can be delivered by the inf2.48xlarge instance. With TP degree 24, fully utilizing all the 24 NeuronCores, we can achieve 130 tokens/sec and 90 tokens/sec for the Llama-2 7B and 13B models, respectively.
Cost
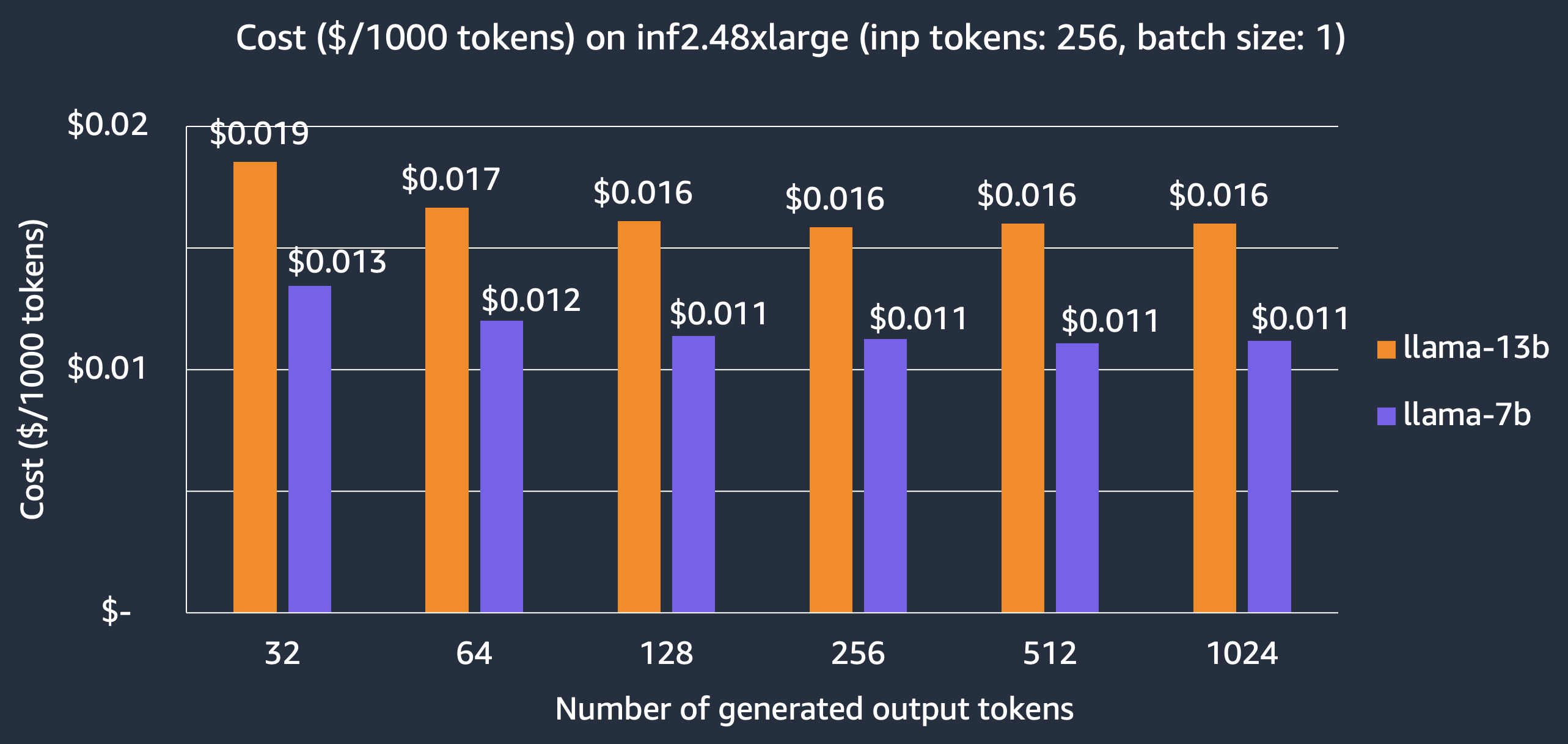
For latency-first applications, we show the cost of hosting Llama-2 models on the inf2.48xlarge instance, $0.011 per 1000 tokens and $0.016 per 1000 tokens for the 7B and 13B models, respectively, which achieve 3x cost saving over other comparable inference-optimized EC2 instances. Note that we report the cost based on 3-year reserved instance price which is what customers use for large production deployments.
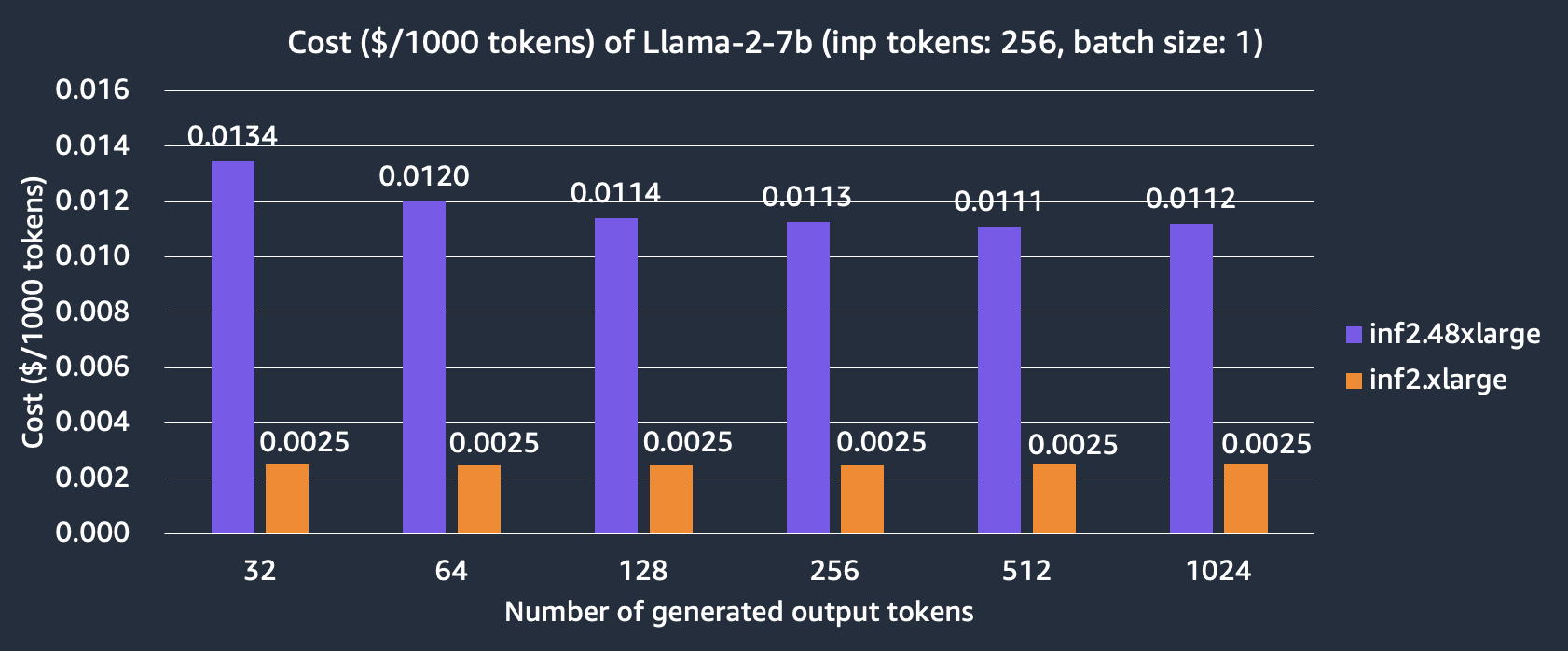
We also compare the cost of hosting the Llama-2 7B model on inf2.xlarge and inf2.48xlarge instances. We can see that inf2.xlarge is more than 4x cheaper than inf2.48xlarge but at the expense of longer latency due to smaller TP degree. For example, it takes 7.9 ms for the model to generate 256 output tokens with 256 input tokens on inf2.48xlarge but 30.1 ms on Inf2.xlarge.
Serving Llama2 with TorchServe on EC2 Inf2 instance
Now, we move on to model deployment. In this section, we show you how to deploy the Llama-2 13B model through SageMaker using TorchServe, which is the recommended model server for PyTorch, preinstalled in the AWS PyTorch Deep Learning Containers (DLC).
This section describes the preparation work needed for using TorchServe, particularly, how to configure model_config.yaml and inf2_handler.py as well as how to generate model artifacts and pre-compile the model for use in later model deployment. Preparing the model artifacts ahead-of-time avoids model compilation during model deployment and thus reduces the model loading time.
Model configuration model-config.yaml
The parameters defined in section handler and micro_batching are used in customer handler inf2_handler.py. More details about model_config.yaml are here. TorchServe micro-batching is a mechanism to pre-process and post-process a batch of inference requests in parallel. It is able to achieve higher throughput by better utilizing the available accelerator when the backend is steadily fed with incoming data, see here for more details. For model inference on Inf2, micro_batch_size, amp, tp_degree and max_length specify the batch size, data type, tensor parallelism degree and max sequence length, respectively.
# TorchServe Frontend Parameters
minWorkers: 1
maxWorkers: 1
maxBatchDelay: 100
responseTimeout: 10800
batchSize: 16
# TorchServe Backend Custom Handler Parameters
handler:
model_checkpoint_dir: "llama-2-13b-split"
amp: "bf16"
tp_degree: 12
max_length: 100
micro_batching:
# Used by batch_size in function LlamaForSampling.from_pretrained
micro_batch_size: 1
parallelism:
preprocess: 2
inference: 1
postprocess: 2
Custom handler inf2_handler.py
Custom handler in Torchserve is a simple Python script that lets you define the model initialization, preprocessing, inference and post-processing logic as functions. Here, we create our Inf2 custom handler.
- The initialize function is used to load the model. Here, Neuron SDK will compile the model for the first time and save the precompiled model in the directory as enabled by
NEURONX_CACHEin the directory specified byNEURONX_DUMP_TO. After the first time, subsequent runs will check if there are already pre-compiled model artifacts. If so, it will skip model compilation.
Once the model is loaded, we initiate warm-up inference requests so that the compiled version is cached. When the neuron persistent cache is utilized, it can significantly reduce the model loading latency, ensuring that the subsequent inference runs swiftly.
os.environ["NEURONX_CACHE"] = "on"
os.environ["NEURONX_DUMP_TO"] = f"{model_dir}/neuron_cache"
TorchServe `TextIteratorStreamerBatch` extends Hugging Face transformers `BaseStreamer` to support response streaming when `batchSize` is larger than 1.
self.output_streamer = TextIteratorStreamerBatch(
self.tokenizer,
batch_size=self.handle.micro_batch_size,
skip_special_tokens=True,
)
- The inference function calls send_intermediate_predict_response to send the streaming response.
for new_text in self.output_streamer:
logger.debug("send response stream")
send_intermediate_predict_response(
new_text[: len(micro_batch_req_id_map)],
micro_batch_req_id_map,
"Intermediate Prediction success",
200,
self.context,
)
Package model artifacts
Package all the model artifacts into a folder llama-2-13b-neuronx-b1 using the torch-model-archiver.
torch-model-archiver --model-name llama-2-13b-neuronx-b1 --version 1.0 --handler inf2_handler.py -r requirements.txt --config-file model-config.yaml --archive-format no-archive
Serve the model
export TS_INSTALL_PY_DEP_PER_MODEL="true"
torchserve --ncs --start --model-store model_store --models llama-2-13b-neuronx-b1
Once the log shows “WORKER_MODEL_LOADED”, the pre-compiled model should be saved in the folder llama-2-13b-neuronx-b1/neuron_cache, which is tightly coupled with Neuron SDK version. Then, upload the folder llama-2-13b-neuronx-b1 to your S3 bucket for later use in the product deployment. The Llama-2 13B model artifacts in this blog can be found here, which is associated with Neuron SDK 2.13.2, in the TorchServe model zoo.
Deploy Llama-2 13B model on SageMaker Inf2 instance using TorchServe
In this section, we deploy the Llama-2 13B model using a PyTorch Neuronx container on a SageMaker endpoint with an ml.inf2.24xlarge hosting instance, which has 6 Inferentia2 accelerators corresponding to our model configuration model_config.yaml handler’s setting – tp_degree: 12. Given that we have packaged all the model artifacts into a folder using torch-model-archiver and uploaded to S3 bucket, we will now use the SageMaker Python SDK to create a SageMaker model and deploy it to a SageMaker real-time endpoint using the deploy uncompressed model method. Speed is the key benefit to deploying in this manner with SageMaker and you get a fully functional production ready endpoint complete with a secure RESTful endpoint without any effort spent on infrastructure. There are 3 steps to deploying the model and running inference on SageMaker. The notebook example can be found here.
- Create a SageMaker model
from datetime import datetime
instance_type = "ml.inf2.24xlarge"
endpoint_name = sagemaker.utils.name_from_base("ts-inf2-llama2-13b-b1")
model = Model(
name="torchserve-inf2-llama2-13b" + datetime.now().strftime("%Y-%m-%d-%H-%M-%S"),
# Enable SageMaker uncompressed model artifacts
model_data={
"S3DataSource": {
"S3Uri": s3_uri,
"S3DataType": "S3Prefix",
"CompressionType": "None",
}
},
image_uri=container,
role=role,
sagemaker_session=sess,
env={"TS_INSTALL_PY_DEP_PER_MODEL": "true"},
)
- Deploy a SageMaker model
model.deploy(
initial_instance_count=1,
instance_type=instance_type,
endpoint_name=endpoint_name,
volume_size=512, # increase the size to store large model
model_data_download_timeout=3600, # increase the timeout to download large model
container_startup_health_check_timeout=600, # increase the timeout to load large model
)
- Run streaming response inference on SageMaker
When the endpoint is in service, you can use theinvoke_endpoint_with_response_streamAPI call to invoke the model. This feature enables the return of each generated token to the user, enhancing the user experience. It’s especially beneficial when generating an entire sequence is time-consuming.
import json
body = "Today the weather is really nice and I am planning on".encode('utf-8')
resp = smr.invoke_endpoint_with_response_stream(EndpointName=endpoint_name, Body=body, ContentType="application/json")
event_stream = resp['Body']
parser = Parser()
for event in event_stream:
parser.write(event['PayloadPart']['Bytes'])
for line in parser.scan_lines():
print(line.decode("utf-8"), end=' ')
Sample inference:
Input
“Today the weather is really nice and I am planning on”
Output
“Today the weather is really nice and I am planning on going to the beach. I am going to take my camera and take some pictures of the beach. I am going to take pictures of the sand, the water, and the people. I am also going to take pictures of the sunset. I am really excited to go to the beach and take pictures.
The beach is a great place to take pictures. The sand, the water, and the people are all great subjects for pictures. The sunset is also a great subject for pictures.”
Conclusion
In this post, we showcased how to run Llama 2 model inference using Transformers Neuron and deploy Llama 2 model serving using TorchServe through Amazon SageMaker on an EC2 Inf2 instance. We demonstrated the benefits of using Inferentia2—low latency and low cost—enabled by optimizations in AWS Neuron SDK including tensor parallelism, parallel context encoding and KV caching, particularly for LLM inference. To stay up to date, please follow AWS Neuron’s latest release for new features.
Get started today with Llama 2 examples on EC2 and through SageMaker and stay tuned for how to optimize Llama 70B on Inf2!