This is a guest post by Dr. Naoki Okada, Lead Data Scientist at BrainPad Inc.
Founded in 2004, BrainPad Inc. is a pioneering partner in the field of data utilization, helping companies create business and improve their management through the use of data. To date, BrainPad has helped more than 1,300 companies, primarily industry leaders. BrainPad has the advantage of providing a one-stop service from formulating a data utilization strategy to proof of concept and implementation. BrainPad’s unique style is to work together with clients to solve problems on the ground, such as data that isn’t being collected due to a siloed organizational structure or data that exists but isn’t organized.
This post discusses how to structure internal knowledge sharing using Amazon Kendra and AWS Lambda and how Amazon Kendra solves the obstacles around knowledge sharing many companies face. We summarize BrainPad’s efforts in four key areas:
- What are the knowledge sharing problems that many companies face?
- Why did we choose Amazon Kendra?
- How did we implement the knowledge sharing system?
- Even if a tool is useful, it is meaningless if it is not used. How did we overcome the barrier to adoption?
Knowledge sharing problems that many companies face
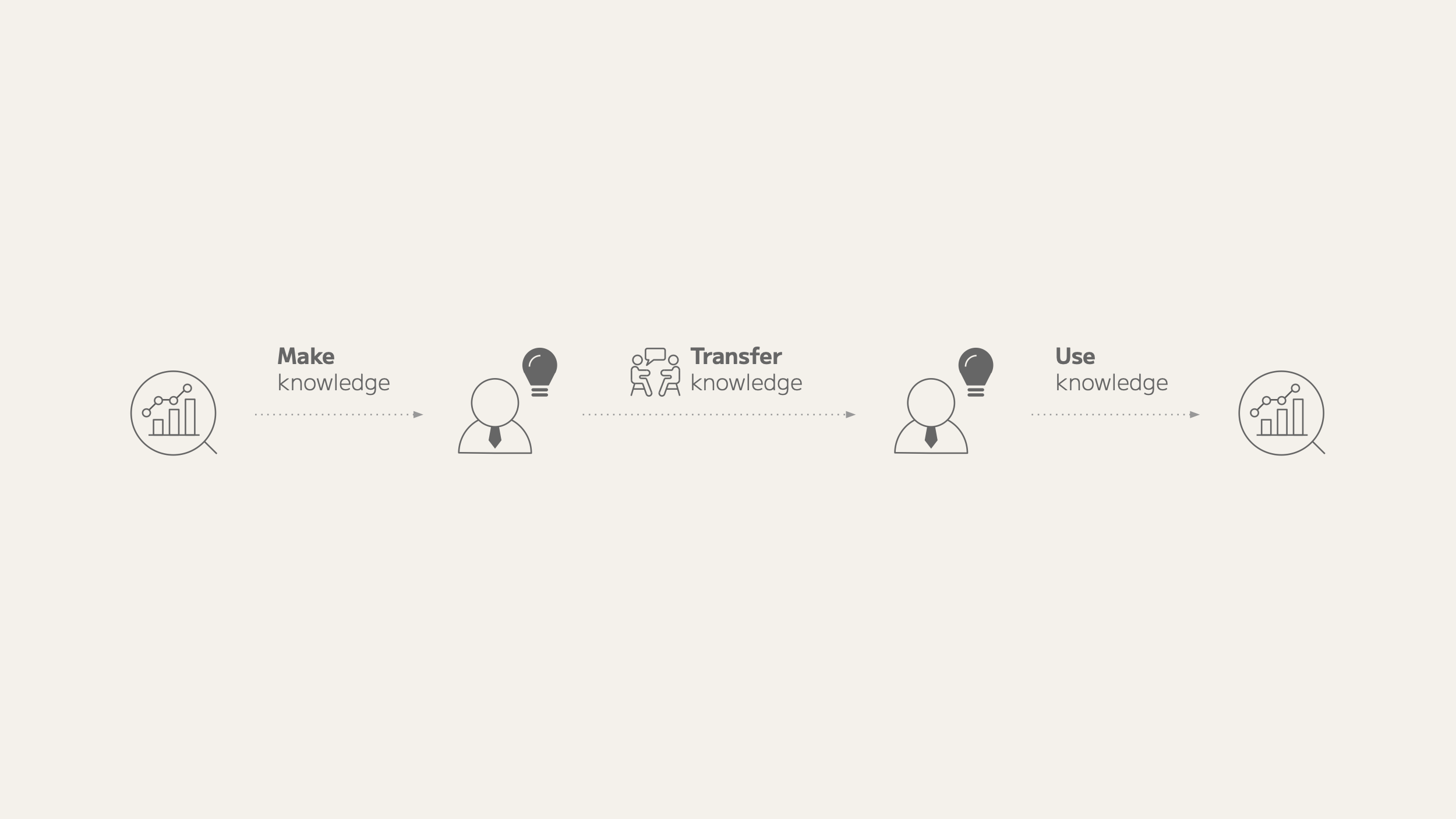
Many companies achieve their results by dividing their work into different areas. Each of these activities generates new ideas every day. This knowledge is accumulated on an individual basis. If this knowledge can be shared among people and organizations, synergies in related work can be created, and the efficiency and quality of work will increase dramatically. This is the power of knowledge sharing.
However, there are many common barriers to knowledge sharing:
- Few people are proactively involved, and the process can’t be sustained for long due to busy schedules.
- Knowledge is scattered across multiple media, such as internal wikis and PDFs, making it difficult to find the information you need.
- No one enters knowledge into the knowledge consolidation system. The system will not be widely used because of its poor searchability.
Our company faced a similar situation. The fundamental problem with knowledge sharing is that although most employees have a strong need to obtain knowledge, they have little motivation to share their own knowledge at a cost. Changing employee behavior for the sole purpose of knowledge sharing is not easy.
In addition, each employee or department has its own preferred method of accumulating knowledge, and trying to force unification won’t lead to motivation or performance in knowledge sharing. This is a headache for management, who wants to consolidate knowledge, while those in the field want to have knowledge in a decentralized way.
At our company, Amazon Kendra is the cloud service that has solved these problems.
Why we chose Amazon Kendra
Amazon Kendra is a cloud service that allows us to search for internal information from a common interface. In other words, it is a search engine that specializes in internal information. In this section, we discuss the three key reasons why we chose Amazon Kendra.
Easy aggregation of knowledge
As mentioned in the previous section, knowledge, even when it exists, tends to be scattered across multiple media. In our case, it was scattered across our internal wiki and various document files. Amazon Kendra provides powerful connectors for this situation. We can easily import documents from a variety of media, including groupware, wikis, Microsoft PowerPoint files, PDFs, and more, without any hassle.
This means that employees don’t have to change the way they store knowledge in order to share it. Although knowledge aggregation can be achieved temporarily, it’s very costly to maintain. The ability to automate this was a very desirable factor for us.
Great searchability
There are a lot of groupware and wikis out there that excel at information input. However, they often have weaknesses in information output (searchability). This is especially true for Japanese search. For example, in English, word-level matching provides a reasonable level of searchability. In Japanese, however, word extraction is more difficult, and there are cases where matching is done by separating words by an appropriate number of characters. If a search for “Tokyo-to (東京都)” is separated by two characters, “Tokyo (東京)” and “Kyoto (京都),” it will be difficult to find the knowledge you are looking for.
Amazon Kendra offers great searchability through machine learning. In addition to traditional keyword searches such as “technology trends,” natural language searches such as “I want information on new technology initiatives” can greatly enhance the user experience. The ability to search appropriately for collected information is the second reason we chose Amazon Kendra.
Low cost of ownership
IT tools that specialize in knowledge aggregation and retrieval are called enterprise search systems. One problem with implementing these systems is the cost. For an organization with several hundred employees, operating costs can exceed 10 million yen per year. This is not a cheap way to start a knowledge sharing initiative.
Amazon Kendra is offered at a much lower cost than most enterprise search systems. As mentioned earlier, knowledge sharing initiatives are not easy to implement. We wanted to start small, and Amazon Kendra’s low cost of ownership was a key factor in our decision.
In addition, Amazon Kendra’s ease of implementation and flexibility are also great advantages for us. The next section summarizes an example of our implementation.
How we implemented the knowledge sharing system
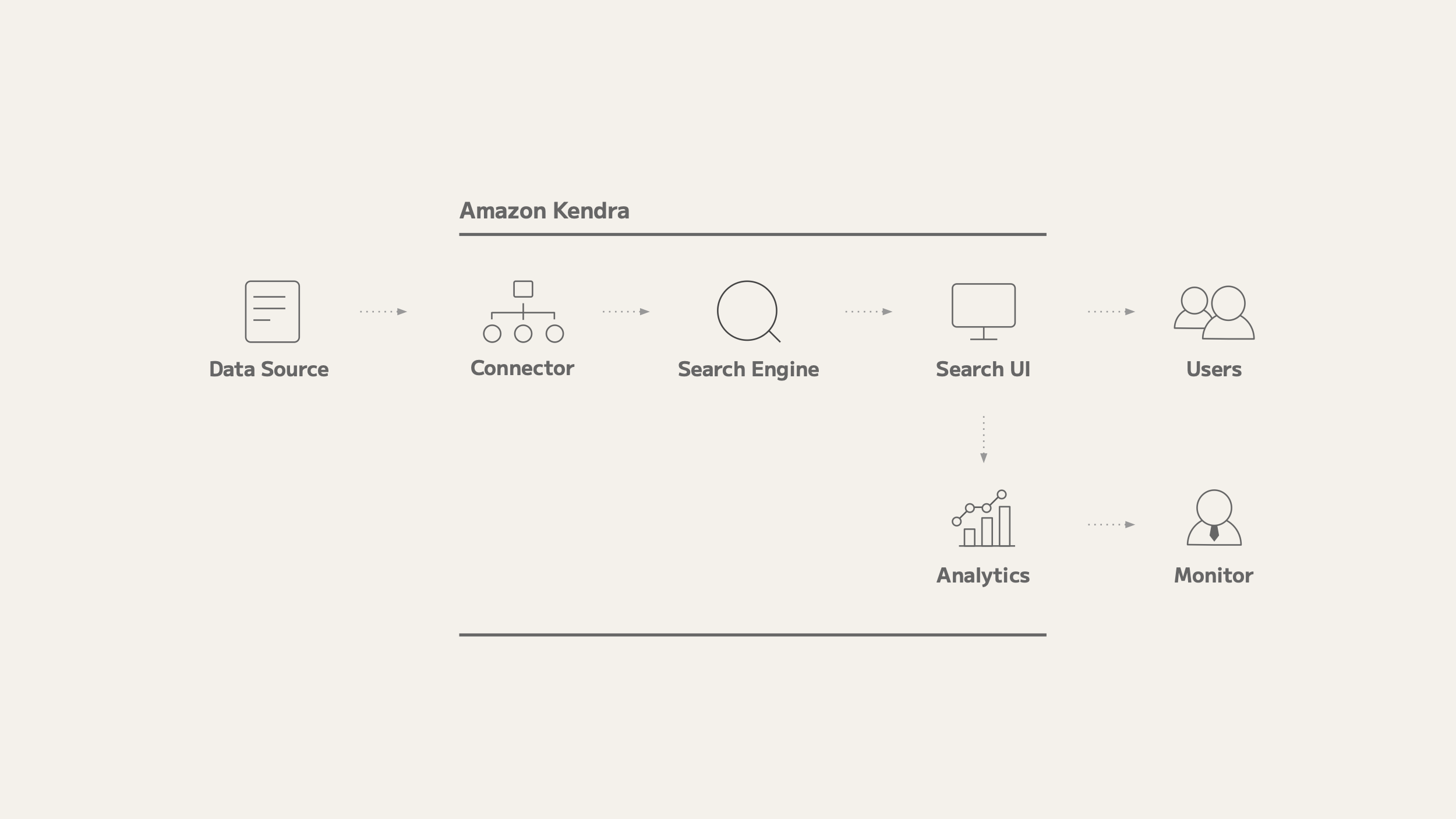
Implementation is not an exaggerated development process; it can be done without code by following the Amazon Kendra processing flow. Here are five key points in the implementation process:
- Data source (accumulating knowledge) – Each department and employee of our company frequently held internal study sessions, and through these activities, knowledge was accumulated in multiple media, such as wikis and various types of storage. At that time, it was easy to review the information from the study sessions later. However, in order to extract knowledge about a specific area or technology, it was necessary to review each medium in detail, which was not very convenient.
- Connectors (aggregating knowledge) – With the connector functionality in Amazon Kendra, we were able to link knowledge scattered throughout the company into Amazon Kendra and achieve cross-sectional searchability. In addition, the connector is loaded through a restricted account, allowing for a security-conscious implementation.
- Search engine (finding information) – Because Amazon Kendra has a search page for usability testing, we were able to quickly test the usability of the search engine immediately after loading documents to see what kind of knowledge could be found. This was very helpful in solidifying the image of the launch.
- Search UI (search page for users) – Amazon Kendra has a feature called Experience Builder that exposes the search screen to users. This feature can be implemented with no code, which was very helpful in getting feedback during the test deployment. In addition to Experience Builder, Amazon Kendra also supports Python and React.js API implementations, so we can eventually provide customized search pages to our employees to improve their experience.
- Analytics (monitoring usage trends) – An enterprise search system is only valuable if a lot of people are using it. Amazon Kendra has the ability to monitor how many searches are being performed and for what terms. We use this feature to track usage trends.
We also have some Q&A related to our implementation:
- What were some of the challenges in gathering internal knowledge? We had to start by collecting the knowledge that each department and employee had, but not necessarily in a place that could be directly connected to Amazon Kendra.
- How did we benefit from Amazon Kendra? We had tried to share knowledge many times in the past, but had often failed. The reasons were information aggregation, searchability, operational costs, and implementation costs. Amazon Kendra has features that solve these problems, and we successfully launched it within about 3 months of conception. Now we can use Amazon Kendra to find solutions to tasks that previously required the knowledge of individuals or departments as the collective knowledge of the entire organization.
- How did you evaluate the searchability of the system, and what did you do to improve it? First, we had many employees interact with the system and get feedback. One problem that arose at the beginning of the implementation was that there was a scattering of information that had little value as knowledge. This was because some of the data sources contained information from internal blog posts, for example. We are continually working to improve the user experience by selecting the right data sources.
As mentioned earlier, by using Amazon Kendra, we were able to overcome many implementation hurdles at minimal cost. However, the biggest challenge with this type of tool is the adoption barrier that comes after implementation. The next section provides an example of how we overcame this hurdle.
How we overcame the barrier to adoption
Have you ever seen a tool that you spent a lot of effort, time, and money implementing become obsolete without widespread use? No matter how good the functionality is at solving problems, it will not be effective if people are not using it.
One of the initiatives we took with the launch of Amazon Kendra was to provide a chatbot. In other words, when you ask a question in a chat tool, you get a response with the appropriate knowledge. Because all of our telecommuting employees use a chat tool on a daily basis, using chatbots is much more compatible than having them open a new search screen in their browsers.
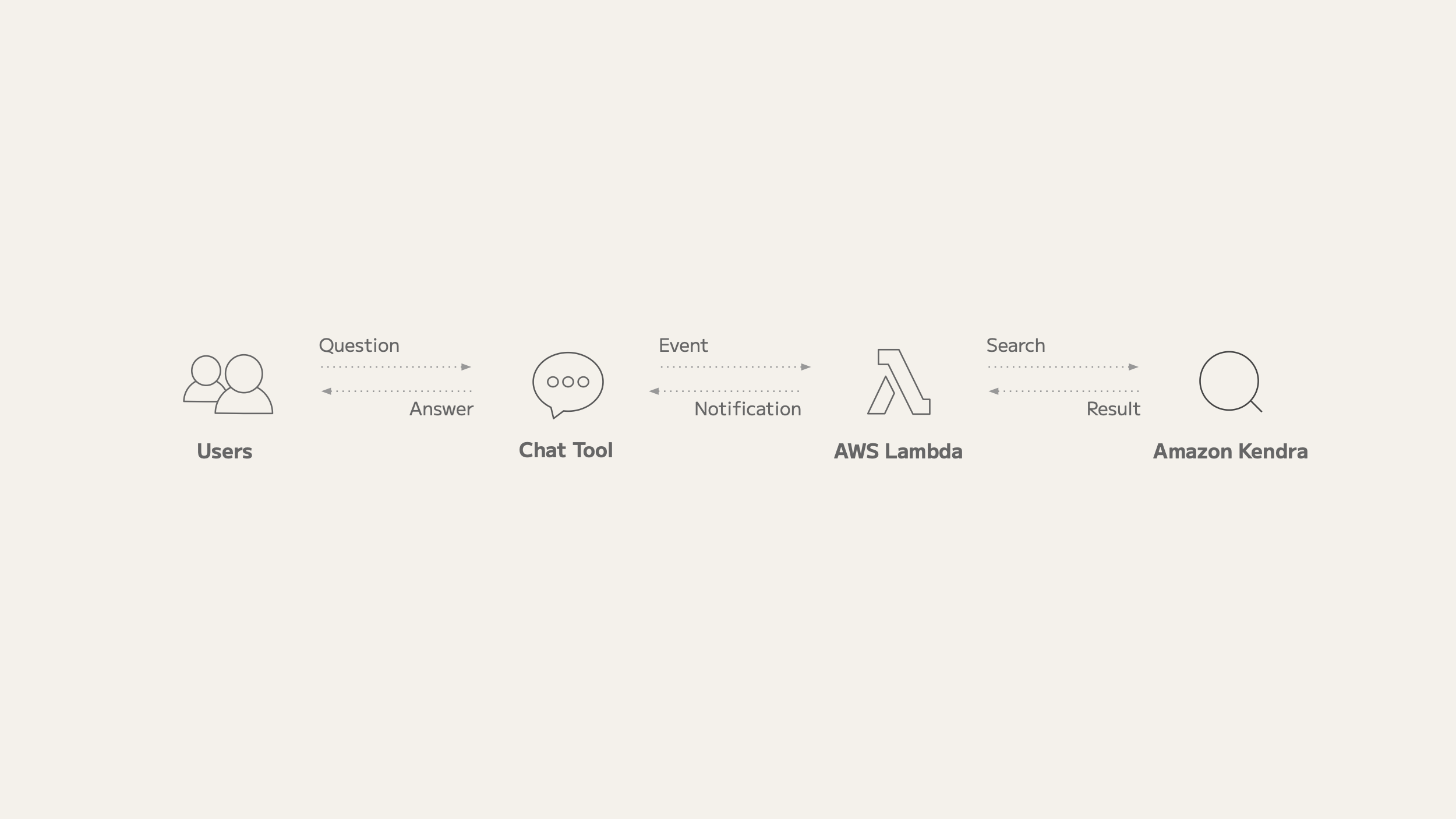
To implement this chatbot, we use Lambda, a service that allows us to run serverless, event-driven programs. Specifically, the following workflow is implemented:
- A user posts a question to the chatbot with a mention.
- The chatbot issues an event to Lambda.
- A Lambda function detects the event and searches Amazon Kendra for the question.
- The Lambda function posts the search results to the chat tool.
- The user views the search results.
This process takes only a few seconds and provides a high-quality user experience for knowledge discovery. The majority of employees were exposed to the knowledge sharing mechanism through the chatbot, and there is no doubt that the chatbot contributed to the diffusion of the mechanism. And because there are some areas that can’t be covered by the chatbot alone, we have also asked them to use the customized search screen in conjunction with the chatbot to provide an even better user experience.
Conclusion
In this post, we presented a case study of Amazon Kendra for knowledge sharing and an example of a chatbot implementation using Lambda to propagate the mechanism. We look forward to seeing Amazon Kendra take another leap forward as large-scale language models continue to evolve.
If you are interested in trying out Amazon Kendra, check out Enhancing enterprise search with Amazon Kendra. BrainPad can also help you with internal knowledge sharing and document exploitation using generative AI. Please contact us for more information.
About the Author

Dr. Naoki Okada is a Lead Data Scientist at BrainPad Inc. With his cross-functional experience in business, analytics, and engineering, he supports a wide range of clients from building up DX organizations to leveraging data in unexplored areas.