Although we might think the world is already sufficiently mapped by the advent of global satellite images and street views, it’s far from complete because much of the world is still uncharted territory. Maps are designed for humans, and can’t be consumed by autonomous vehicles, which need a very different technology of maps with much higher precision.
DeepMap, a Palo Alto startup, is the leading technology provider of HD mapping and localization services for autonomous vehicles. These two services are integrated to provide high-precision localization maps, likely down to a centimeter precision. This demands processing a high volume of data to maintain precision and localization accuracy. In addition, road conditions can change minute to minute, so the maps guiding self-driving cars have to update in real time. DeepMap accumulates years of experience of mapping server development and uses the latest big data, machine learning (ML), and AI technology to build out their video inferencing and mapping pipeline.
In this post, we describe how DeepMap is revamping their video inference workflow by using Amazon SageMaker Processing, a customizable data processing and model evaluation feature, to streamline their workload by reducing complexity, processing time, and cost. We start out by describing the current challenges DeepMap is facing. Then we go over the proof of concept (POC) implementation and production architecture for the new solution using Amazon SageMaker Processing. Finally, we conclude with the performance improvements they achieved with this solution.
Challenges
DeepMap’s current video inference pipeline needs to process large amounts of video data collected by their cars, which are equipped with cameras and LIDAR laser scanning devices and drive on streets and freeways to collect video and image data. It’s a complicated, multi-step, batch processing workflow. The following diagram shows the high-level architecture view of the video processing and inferencing workflow.
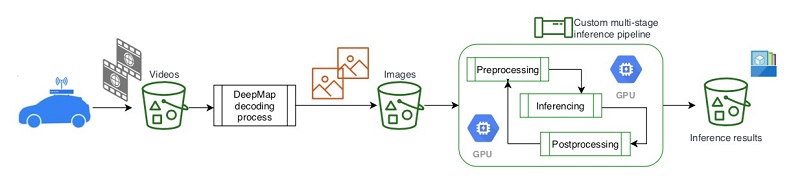
With their previous workflow architecture, DeepMap discovered a scalability issue that increased processing time and cost due to the following reasons:
- Multiple steps and separate batch processing stages, which could be error-prone and interrupt the workflow
- Additional storage required in Amazon Simple Storage Service (Amazon S3) for intermediate steps
- Sequential processing steps that prolonged the total time to complete inference
DeepMap’s infrastructure team recognized the issue and approached the AWS account team for guidance on how to better optimize their workflow using AWS services. The problem was originally presented as a workflow orchestration issue. A few AWS services were proposed and discussed for workflow orchestration, including:
- Amazon Simple Workflow Service (Amazon SWF)
- AWS Step Functions
However, after a further deep dive into their objectives and requirements, they determined that these services addressed the multiple steps coordination issue but not the storage and performance optimization objectives. Also, DeepMap wanted to keep the solution in the realm of the Amazon SageMaker ML ecosystem, if possible. After a debrief and further engagement with the Amazon SageMaker product team, a recently released Amazon SageMaker feature—Amazon SageMaker Processing—was proposed as a viable and potentially best fit solution for the problem.
Amazon SageMaker Processing comes to the rescue
Amazon SageMaker Processing lets you easily run the preprocessing, postprocessing, and model evaluation workloads on a fully managed infrastructure. Besides the full set of additional data and processing capabilities, Amazon SageMaker Processing is particularly attractive and promising for DeepMap’s problem at hand because of its flexibility in the following areas:
- Setting up your customized container environment, also known as bring your own container (BYOC)
- Custom coding to integrate with other application APIs that reside in your VPCs
These were the key functionalities DeepMap was looking for to redesign and optimize their current inference workflow. They quickly agreed on a proposal to explore Amazon SageMaker Processing and move forward as a proof of concept (POC).
Solution POC
The following diagram shows the POC architecture, which illustrates how a container in Amazon SageMaker Processing can make real-time API calls to a private VPC endpoint. The full architecture of the new video inference workload is depicted in the next section.

The POC demonstration includes the following implementation details:
- Sample source data – Two video files (from car view). The following images show examples of Paris and Beijing streets.


- Data stores – Two S3 buckets:
- Source video bucket –
s3://sourcebucket/input - Target inference result bucket –
s3://targetbucket/output
- Source video bucket –
- Custom container – An AWS pre-built deep learning container based on MXNET with other needed packages and the pretrained model.
- Model – A pre-trained semantic segmentation GluonCV model from the GluonCV model zoo. GluonCV provides implementations of state-of-the-art deep learning algorithms in computer vision. It aims to help engineers, researchers, and students quickly prototype products, validate new ideas, and learn computer vision. The GluonCV model zoo contains six kinds of pretrained models: classification, object detection, segmentation, pose estimation, action recognition, and depth prediction. For this post, we use deeplab_resnet101_citys, which was trained with Cityscape dataset and focuses on semantic understanding of urban street scenes, so this model is suitable for car view images. The following images are a sample of segmentation inference; we can see the model assigned red for people and blue for cars.


- Amazon SageMaker Processing environment – Two instances (p3.2xlarge) configured for private access to the VPC API endpoint.
- Mock API server – A web server in a private VPC mimicking DeepMap’s video indexing APIs. When invoked, it responds with a “Hello, Builders!” message.
- Custom processing script – An API call to the mock API endpoint in the private VPC to extract frames from the videos, perform segmentation model inference on the frames, and store the results.
Amazon SageMaker Processing launches the instances you specified, downloads the container image and datasets, runs your script, and uploads the results to the S3 bucket automatically. We use the Amazon SageMaker Python SDK to launch the processing job. See the following code:
from sagemaker.network import NetworkConfig
from sagemaker.processing import (ProcessingInput, ProcessingOutput,
ScriptProcessor)
instance_count = 2
"""
This network_config is for Enable VPC mode, which means the processing instance could access resources within vpc
change to your security_group_id and subnets_id
security_group_ids = ['YOUR_SECURITY_GROUP_ID']
subnets = ["YOUR_SUBNETS_ID1","YOUR_SUBNETS_ID2"]
"""
security_group_ids = vpc_security_group_ids
subnets = vpc_subnets
network_config = NetworkConfig(enable_network_isolation=False,
security_group_ids=security_group_ids,
subnets=subnets)
video_formats = [".mp4", ".avi"]
image_width = 1280
image_height = 720
frame_time_interval = 1000
script_processor = ScriptProcessor(command=['python3'],
image_uri=processing_repository_uri,
role=role,
instance_count=instance_count,
instance_type='ml.p3.2xlarge',
network_config=network_config)
# with S3 shard key
script_processor.run(code='processing.py',
inputs=[ProcessingInput(
source=input_data,
destination='/opt/ml/processing/input_data',
s3_data_distribution_type='ShardedByS3Key')],
outputs=[ProcessingOutput(destination=output_data,
source='/opt/ml/processing/output_data',
s3_upload_mode = 'Continuous')],
arguments=['--api_server_address', vpc_api_server_address,
'--video_formats', "".join(video_formats),
'--image_width', str(image_width),
'--image_height', str(image_height),
'--frame_time_interval', str(frame_time_interval)]
)
script_processor_job_description = script_processor.jobs[-1].describe()
print(script_processor_job_description)We use the ShardedByS3Key mode for the S3_data_distribution_type to leverage the feature in Amazon SageMaker that shards the objects by Amazon S3 prefix, so the instance receives 1/N of the total objects for faster parallel processing. Because this video inference job is just one part of DeepMap’s entire map processing workflow, S3_upload_mode is set to Continuous to streamline with the subsequent processing tasks. For the complete POC sample codes, see the GitHub repo.
The POC was successfully completed, and the positive results demonstrated the capability and flexibility of Amazon SageMaker Processing. It met the following requirements for DeepMap:
- Dynamically invoke an API in a private VPC endpoint for real-time custom processing needs
- Reduce the unnecessary intermediate storage for video frames
Production solution architecture
With the positive results from the demonstration of the POC, DeepMap’s team decided to re-architect their current video process and inference workflow by using Amazon SageMaker Processing. The following diagram depicts the high-level architecture of the new workflow.
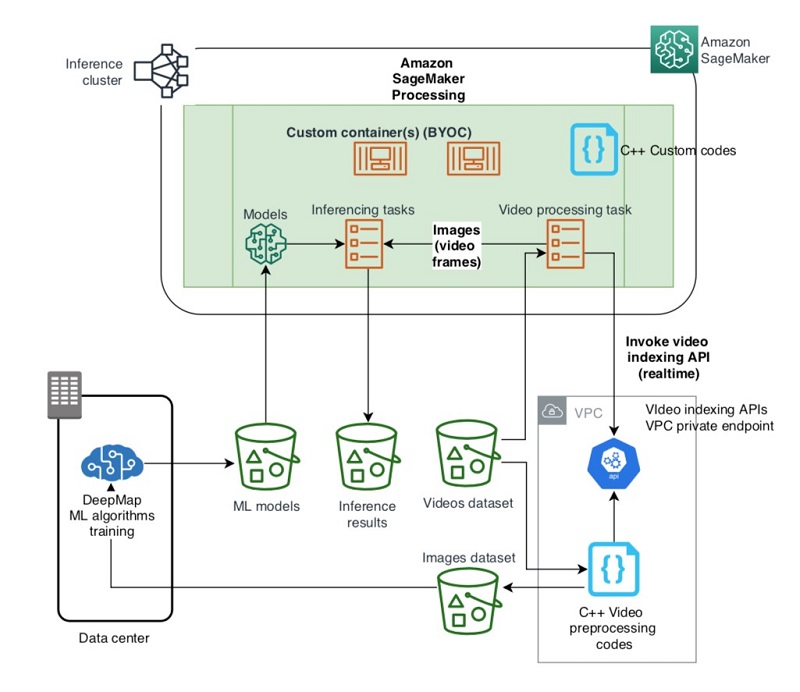
The DeepMap team initiated a project to implement this new architecture. The initial production development setting is as follows:
- Data source – Camera streams (30fps) collected from the cars are chopped and stored as 1-second h264 encoded video clips. All video clips are stored in the source S3 buckets.
- Video processing – Within a video clip (of 30 frames in total), only a fraction of key frames are useful for map making. The relevant key frames information is stored in DeepMap’s video metadata database. Video processing codes run in an Amazon SageMaker Processing container, which call a video indexing API via a VPC private endpoint to retrieve relevant key frames for inferencing.
- Deep learning inference – Deep learning inference code queries the key frame information from the database, decodes the key frames in memory, and applies the deep learning model using the semantic segmentation algorithm to produce the results and store the output in the S3 result bucket. The inference codes also run within the Amazon SageMaker Processing custom containers.
- Testing example – We use a video clip of a collected road scene in .h264 format (000462.h264). Key frame metadata information about the video clip is stored in the database. The following is an excerpt of the key frame metadata information dumped from the database:
image_paths { image_id { track_id: 12728 sample_id: 4686 } camera_video_data { stream_index: 13862 key_frame_index: 13860 video_path: "s3://sensor-data/4e78__update1534_vehicle117_2020-06-11__upload11960/image_00/rectified-video/000462.h264" } } image_paths { image_id { track_id: 12728 sample_id: 4687 } camera_video_data { stream_index: 13864 key_frame_index: 13860 video_path: "s3://sensor-data/4e78__update1534_vehicle117_2020-06-11__upload11960/image_00/rectified-video/000462.h264" } }
A relevant key frame is returned from the video index API call for the subsequent inference task (such as the following image).

The deep learning inference result is performed using the semantic segmentation algorithm running in Amazon SageMaker Processing to determine the proper lane line from the key frame. Using the preceding image as input, we receive the following output.

Performance improvements
As of this writing, DeepMap has already seen the expected performance improvements using the newly optimized workflow, and been able to achieve the following:
- Streamline and reduce the complexity of current video-to-image preprocessing workflow. The real-time API video indexing call has reduced two steps to one.
- Reduce the total time for video preprocessing and image DL inferencing. Through the streamlined process, they can now run decoding and deep learning inference on different processors (CPU and GPU) in different threads, potentially saving 100% preprocessing time (as long as the inference takes longer than the video decoding, which is true in most cases).
- Reduce the intermediate storage spaces to store the images for inference job. Each camera frame (1920×1200, encoded as JPEG format) takes 500 KB to store, but a 1-second video clip (x264 encoded) with 30 continuous frames takes less than 2 MB storage (thanks to the video encoding). So, the storage reduction rate is about (1 – 2MB / (500KB * 30)) ~= 85%.
The following table summarizes the overall improvements of the new optimized workflow.
| Measurements | Before | After | Performance Improvements |
| Processing steps | Two steps | One step | 50% simpler workflow |
| Processing time | Video preprocessing to extract key frames | Parallel processing (with multiple threads in Amazon SageMaker Processing containers) | 100% reduction of video preprocessing time |
| Storage | Intermediate S3 buckets for preprocessed video frames | None (in-memory) | 85% reduction |
| Compute | Separate compute resources for video pre-processing using Amazon Elastic Compute Cloud (Amazon EC2) | None (running in the Amazon SageMaker Processing container) | 100% reduction of video preprocessing compute resources |
Conclusion
In this post, we described how DeepMap used the new Amazon SageMaker Processing capability to redesign their video inference workflow to achieve a more streamlined workflow. Not only did they save on storage costs, they also improved their total processing time.
Their successful use case also demonstrates the flexibility and scalability of Amazon SageMaker Processing, which can help you build more scalable ML processing and inferencing workloads. For more information about integrating Amazon SageMaker Processing, see Amazon SageMaker Processing – Fully Managed Data Processing and Model Evaluation. For more information about using services such as Step Functions to build more efficient ML workflows, see Building machine learning workflows with Amazon SageMaker Processing jobs and AWS Step Functions.
Try out Amazon SageMaker Processing today to further optimize your ML workloads.
About the Authors
 Frank Wang is a Startup Senior Solutions Architect at AWS. He has worked with a wide range of customers with focus on Independent Software Vendors (ISVs) and now startups. He has several years of engineering leadership, software architecture, and IT enterprise architecture experiences, and now focuses on helping customers through their cloud journey on AWS.
Frank Wang is a Startup Senior Solutions Architect at AWS. He has worked with a wide range of customers with focus on Independent Software Vendors (ISVs) and now startups. He has several years of engineering leadership, software architecture, and IT enterprise architecture experiences, and now focuses on helping customers through their cloud journey on AWS.
 Shishuai Wang is an ML Specialist Solutions Architect working with the AWS WWSO team. He works with AWS customers to help them adopt machine learning on a large scale. He enjoys watching movies and traveling around the world.
Shishuai Wang is an ML Specialist Solutions Architect working with the AWS WWSO team. He works with AWS customers to help them adopt machine learning on a large scale. He enjoys watching movies and traveling around the world.
 Yu Zhang is a staff software engineer and the technical lead of the Deep Learning platform at DeepMap. His research interests include Large-Scale Image Concept Learning, Image Retrieval, and Geo and Climate Informatic
Yu Zhang is a staff software engineer and the technical lead of the Deep Learning platform at DeepMap. His research interests include Large-Scale Image Concept Learning, Image Retrieval, and Geo and Climate Informatic
 Tom Wang is a founding team member and Director of Engineering at DeepMap, managing their cloud infrastructure, backend services, and map pipelines. Tom has 20+ years of industry experience in database storage systems, distributed big data processing, and map data infrastructure. Prior to DeepMap, Tom was a tech lead at Apple Maps and key contributor to Apple’s map data infrastructure and map data validation platform. Tom holds an MS degree in computer science from the University of Wisconsin-Madison.
Tom Wang is a founding team member and Director of Engineering at DeepMap, managing their cloud infrastructure, backend services, and map pipelines. Tom has 20+ years of industry experience in database storage systems, distributed big data processing, and map data infrastructure. Prior to DeepMap, Tom was a tech lead at Apple Maps and key contributor to Apple’s map data infrastructure and map data validation platform. Tom holds an MS degree in computer science from the University of Wisconsin-Madison.