![]()
A guest post by Larry Price, OpenX
Edited by Robert Crowe, Anusha Ramesh – TensorFlow
Overview
Adtech is an industry built on latency at scale. At OpenX this means that during peak traffic periods our exchange processes more than one million requests for ads every second, most of which require a response in under 300 milliseconds. Under such high volume and strict time budgets, it’s crucial to prioritize traffic to ensure we’re simultaneously helping publishers get top dollar for their inventory as well as ensuring buyers hit their campaign goals.
To accomplish this, we’ve leveraged several products in the TensorFlow ecosystem & Google Cloud including TensorFlow Extended (TFX), TF Serving, and Kubeflow Pipelines – to build a service that prioritizes traffic to our buyers (demand side platforms, or DSPs in adtech lingo) and more specifically to brands, and agencies within those DSPs.
About OpenX
OpenX operates the world’s largest independent advertising exchange. At a basic level, the exchange is a marketplace connecting tens of thousands of top brands to consumers across the most-visited websites and mobile apps.
The fundamental means of transacting is the auction, where buyers representing brands bid on publishers’ inventory, which are ad impressions on websites and mobile apps. The auctions themselves are fairly straightforward, but there are two facts that make this system incredibly complicated:
- Scale: At peak traffic our systems process more than one million requests for ads every second. A typical day sees more than 1.5 trillion bid transactions, resulting in petabytes of raw data.
- Latency: Preserving user experience on both the web and mobile apps is crucial to publishers, so most of the requests we process have strict time limits of 300 milliseconds or less, most of which is spent asking for and receiving the buyers’ bids. This means that any overhead introduced by machine learning models at auction time must be limited to at most about 15 milliseconds, otherwise we risk not giving buyers enough time to submit their bids.
This need for low latency coupled with the high throughput requirement is fairly atypical for machine learning systems. Before we get to the details of how we built a machine learning infrastructure capable of dealing with both requirements, we’ll dig a little deeper into how we got here and what problem we’re trying to solve.
Cloud Transformation: A rare opportunity
In 2019 OpenX undertook the ambitious task of moving off of on-premise computing resources to Google Cloud Platform (GCP). We completed the process over a span of seven months. As a company, we were empowered to utilize managed services and modify our stack as we transition, so it wasn’t just a simple “lift-and-shift”. We really took this to heart on the Data Science team.
Prior to the move to GCP, our legacy machine learning infrastructure followed a pattern where models trained by scientists had to be re-implemented by engineers in the components that needed to execute the models. This scenario satisfies the scale and latency requirements but comes with a whole host of other issues:
- It takes a long time to get models to production because the scientist’s work (typically in Python) now has to be reproduced by an engineer in the native language of the component that has to call it.
- The same is true for changes to model architecture, or even the way data transformations are performed.
- It’s essentially a recipe for training-serving skew.
- QA was challenging.
For these and several other reasons we decided to start from scratch. At the same time, we were working on a new problem and decided to tie the two efforts together and develop a new framework as part of the new project.
Our problem
The OpenX marketplace is not completely unlike an equities market or stock exchange. And much like high volume financial markets, to ensure the buyers fulfill their campaign goals and simultaneously help publishers monetize appropriately on their inventory, there’s a need to prioritize traffic. Fundamentally, this means we need a model that can accurately value and hence rank every single request that hits the exchange.
Why TensorFlow
As we looked for a solution for our next-generation platform we had a couple of goals in mind. We were looking primarily to drastically reduce the time and effort to put a model into production, and as part of getting there try to use managed services wherever possible. TensorFlow had already been in use at OpenX for a while prior to our migration to GCP, but our legacy infrastructure involved a number of custom scripts for data transformation and pipelining. At the same time as we were researching our options, both TensorFlow Extended (TFX) and Kubeflow Pipelines (KFP) were reaching a level of maturity that made them interesting for our purposes. It was a no-brainer to adopt these technologies into our stack.
How we solved it
Training Terabytes of Data Every Day
Our pipeline looks something like this.
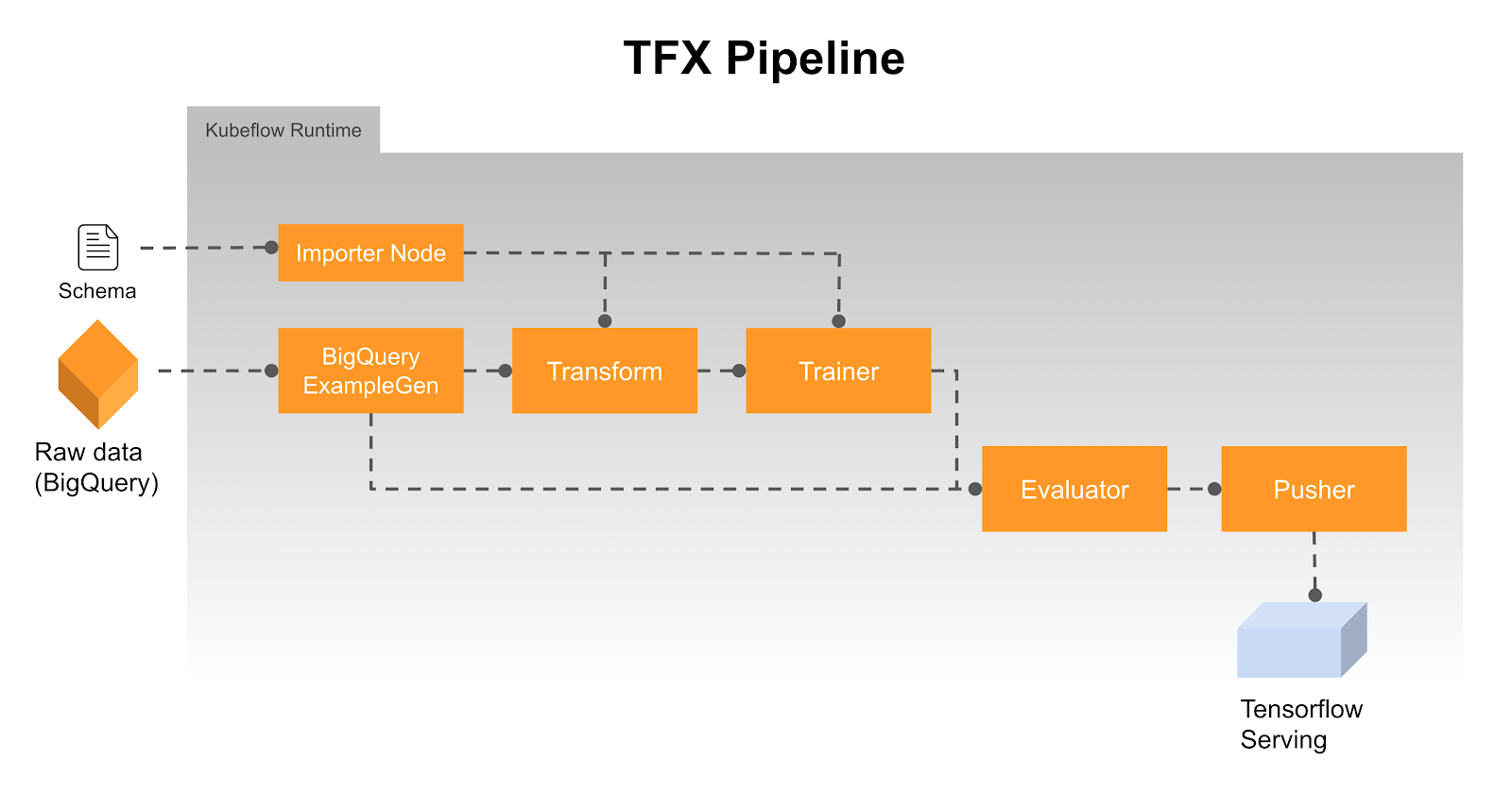
It’s useful to spend some time breaking down the topology of the pipeline:
- Raw Data – Our data consists of transaction logs that are streamed directly from StackDriver into a BigQuery sink as they arrive. To help avoid bias in our model we train on a fraction of the total data that is held out from our prioritization system, resulting in roughly 50TB of new data daily. This was a simple design choice as it was very straightforward to implement, and the big benefit is that we can use BigQuery on the data directly without an additional ETL.
- BigQueryExampleGen – The first place we leverage BigQuery is using builtin functions to preprocess the data. By embedding our own specific processes into the query calls made by the ExampleGen component, we were able to avoid building out a separate ETL that would exist outside the scope of a TFX pipeline. This ultimately proved to be a good way to get the model in production more quickly. This preprocessed data is then split into training and test sets and converted to tf.Examples via the ExampleGen component.
- Transform – This component does the necessary feature engineering and transformations necessary to handle strings, normalize values, setup embeddings etc. The major benefit here is that the resulting transformation is ultimately prepended to the computational graph, so that the exact same code is used for training and serving.
- Trainer – The Trainer component does just that. We leverage parallel training on AI Platform to speed things up.
- Evaluator – The Evaluator compares the existing production model to the model received by the Trainer and blesses the “better” one for use in production. The decisioning criteria is based on custom metrics aligned with business requirements (as opposed to, e.g. precision and recall). It was easy to implement the custom metrics meeting the business requirements owing to the extensibility of the evaluator component.
- Pusher – The Pusher’s primary function is to send the blessed model to our TFServing deployment for production. However, we added functionality to use the custom metrics produced in the Evaluator to determine decisioning criteria to be used in serving, and attach that to the computational graph. The level of abstraction available in TFX components made it easy to make this custom modification. Overall, the modification allows the pipeline to operate without a human in the loop so that we are able to make model updates frequently, while continuing to deliver consistent performance on metrics that are important to our business.
Overall, out-of-the box TFX components provided most of the functionality we require. The biggest need we had to address is that our marketplace changes constantly, which requires frequent model updates. As mentioned previously, the design of TFX made those augmentations straightforward to implement.
However this really only solves the model training part of our problem. Serving up a million queries per second, each in under 15 milliseconds, is a major challenge. For that we turned to TensorFlow Serving.
Serving Over a Million Queries Per Second (QPS)
TensorFlow Serving enabled us to quickly take our TensorFlow models and serve them in production in a performant and scalable way. Using TensorFlow Serving provided us with a number of benefits. First, because it natively supports Google Cloud Storage as a model warehouse, we can automatically update our models used in serving simply by uploading to a GCS bucket. This allows us to quickly refresh our models with the newest data and have them instantly served in production. Next, TensorFlow Serving supports a batching mode that drastically increases throughput by queuing up several requests and processing them in a single graph run at the same time. This was an essential feature that massively helped us achieve our throughput goals just by setting a single option. Finally, TensorFlow Serving exposes metrics out of the box that allow us to monitor the throughput and latency of our requests and observe any scaling bottlenecks and inefficiencies.
All of these out of the box features in TensorFlow Serving were a massive win for us and helped us achieve our goals, but scaling it to millions of requests a second was not without challenges. By using large virtual machines with many CPUs we were able to hit our target goal of 15 millisecond predictions, but it did not scale very cost effectively and we knew we could do better. Luckily, TensorFlow Serving has several knobs and parameters that we used to tune our production VMs for better efficiency and scalability. By setting things like the number of batch threads, inter- and intra-op parallelism, and batch timeout, we were able to efficiently autoscale on custom sized VMs while still maintaining our throughput and latency goals.
The end result was a TensorFlow Serving deployment running on Google Kubernetes Engine serving 2.5 million prediction requests per second under 15 milliseconds each. This deployment spans over 25 kubernetes clusters across 10 different GCP regions and is able to scale up and down seamlessly to respond to spikes in traffic and save costs by scaling down during quiet periods. With around 500 TensorFlow Serving instances running around the world at peak times, each 8-CPU deployment is able to handle 5000 requests per second.
Building on Success
In the few months since implementing this we’ve been able to make dozens of improvements to the model – everything from changing the architecture of the original model, to changing the way certain features are processed – without support from any other engineering team. Changes at this pace were all but impossible with our legacy architecture. Moreover, each of these improvements brings new value to our customers – the buyers and sellers in our marketplace – more quickly than we’ve been able to in the past.
Since our initial implementation of this reference architecture, we’ve used it as a template for both new projects and the migration of existing models. It’s quite remarkable how many of the existing TFX components that we have in place carry over to new projects, and even more so how drastically we’ve reduced the time it takes to get a model in production. As a result, data scientists are able to spend more of their time optimizing the parameters and architectures of the models they produce, understanding their impact on the business, and ultimately delivering more value to our customers.
Acknowledgements
None of this would have been possible without the hard work of Michal Brys, Andy Gooden, Junbo Park, and Paul Selden, along with the rest of the OpenX Data Science and Engineering Teams as well as the support of Paul Ryan. We’re also grateful for the support of strategic cloud engineers Will Beebe and Leonid Kuligin, as well as Dillon Do, Iman Kafarah, and Kyle Winn from the GCP account management team. Many thanks to the TensorFlow (TFX, TF Serving), and Kubeflow Teams, particularly Robert Crowe and Anusha Ramesh for helping to bring this case study to life.