
Posted by Daniel Situnayake, Founding TinyML Engineer, Edge Impulse.
Microcontrollers that run our world
No matter where you are reading this right now—your home, your office, or sitting in a vehicle—you are likely surrounded by microcontrollers. They are the tiny, low-power computers that animate our modern world: from smart watches and kitchen appliances to industrial equipment and public transportation. Mostly hidden inside other products, microcontrollers are actually the most numerous type of computer, with more than 28 billion of them shipped in 2020.
The software that powers all these devices is written by embedded software engineers. They’re some of the most talented, detail-oriented programmers in the industry, tasked with squeezing every last drop of efficiency from tiny, inexpensive processors. A typical mid-range microcontroller—based around Arm’s popular Cortex-M4 architecture—might have a 32-bit processor running at just 64Mhz, with 256KB of RAM and 1MB of flash memory for storing a program. That doesn’t leave a lot of room for waste.
Since microcontrollers interface directly with sensors and hardware, embedded engineers are often experts in signal processing and electrical engineering—and they tend to have a lot of domain knowledge in their area of focus. One engineer might be an expert on the niche sensors used for medical applications, while another might focus on analyzing audio signals.
Embedded machine learning
In the past few years, a set of technologies have been developed that make it possible to run miniature, highly optimized machine learning models on low-power microcontrollers like the one described above. By using machine learning to interpret sensor data right at the source, embedded applications can become smarter, faster, and more energy efficient, making their own decisions rather than having to stream data to the cloud and wait for a response. This concept is known as embedded machine learning, or TinyML.
With their deep signal processing and domain expertise, embedded engineers are ideally placed to design this new generation of smart applications. However, embedded engineers tend to have highly specialized skill sets and use development toolchains that are often far removed from the Python-heavy stack preferred by data scientists and machine learning engineers.
It isn’t reasonable to expect domain experts to retrain as data scientists, or for data scientists to learn the embedded development skills required to work with microcontrollers. Instead, a new generation of tooling is required that will allow those with domain expertise to capture their knowledge and insight as machine learning models and deploy them to embedded devices—with help from machine learning experts an optional extra.
The TinyML development process is similar to the traditional machine learning workflow. It starts with collecting, exploring, and evaluating a dataset. Next up, feature engineering takes the form of sophisticated digital signal processing, often using the types of algorithms that embedded engineers are already familiar with. Once features have been extracted from the data, a machine learning model is trained and evaluated—with a critical eye on its size, to make sure it will fit on a tiny microcontroller and run fast enough to be useful.
After the training, the model is optimized for size and efficiency. This often involves quantization, reducing the precision of the model’s weights so that they take up less precious memory. Once the model is ready, it must be deployed as a C++ library (the language of choice for the majority of embedded platforms) that includes all of the operator kernels required to run it. The embedded engineer can then write and tune an application that interprets the model’s output and uses it to make decisions.
Throughout this process, it’s important to carefully evaluate the model and application to ensure that it functions in the way that it is intended to when used in a real world environment. Without adequate monitoring and review, it’s possible to create models that seem superficially accurate but that fail in harmful ways when exposed to real world data.
Edge Impulse and TensorFlow
The Edge Impulse team has created an end-to-end suite of tooling that helps embedded engineers and domain experts build and test machine learning applications. Edge Impulse is designed to integrate beautifully with the tools that embedded engineers use every day, providing a high-level interface for incorporating machine learning into projects.
Edge Impulse makes use of the TensorFlow ecosystem for training, optimizing, and deploying deep learning models to embedded devices. While it was designed with non-ML engineers in mind, the philosophy behind Edge Impulse is that it should be extensible by machine learning experts and flexible enough to incorporate their insights and additions—from hand-tuned model architectures and loss functions to custom operator kernels.
This extensibility is made possible by the TensorFlow ecosystem, which provides a set of standards and integration points that experts can use to make their own improvements.
Training a tiny model
This process starts during training. Novice ML developers using Edge Impulse can use a library of preset deep learning model architectures designed to work well with embedded devices. For example, this simple convolutional model is intended for classifying ambient noise:
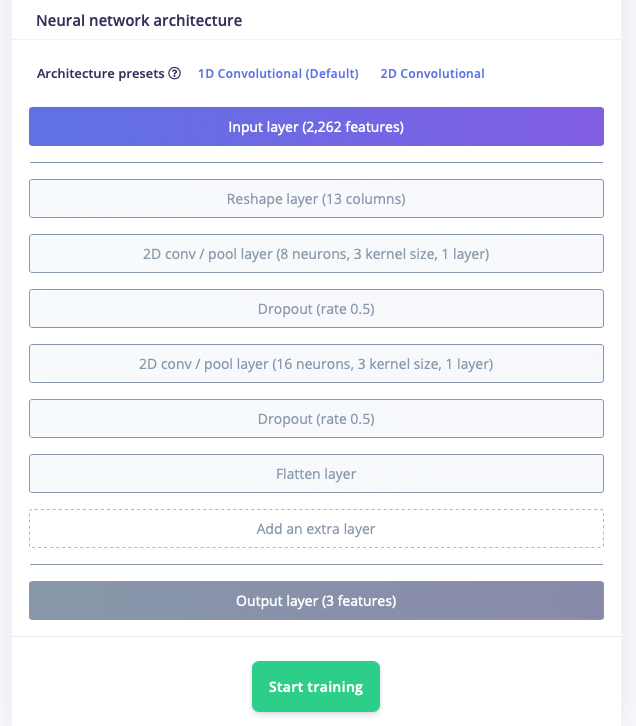
Under the hood, Edge Impulse generates a Python implementation of the model using TensorFlow’s Keras APIs. More experienced developers can customize the layers of the deep learning network, tweaking parameters and adding new layers that are reflected in the underlying Keras model. And expert developers have access to edit the training code itself, directly within the UI:
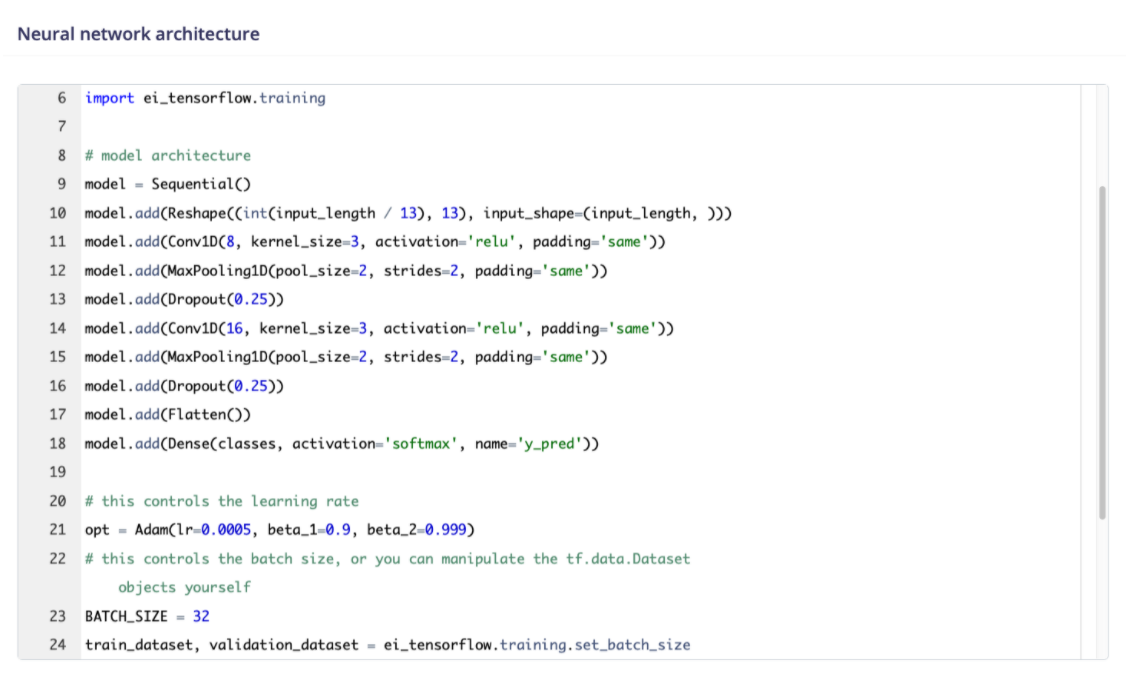
Since Edge Impulse uses TensorFlow libraries and APIs, it’s incredibly simple to extend the built-in training code with your own logic. For example, the tf.data.Dataset class is used to provide an efficient pipeline to the training and validation datasets. This pipeline can easily be extended to add transformations, such as the data augmentation function seen in the following screenshot from an image classification project:

For in-depth experiments, developers can download a Jupyter Notebook containing all of the dependencies required to run their training script locally.
Any custom model code using the TensorFlow APIs fits seamlessly into the end-to-end pipeline hosted by Edge Impulse. Training is run in the cloud, and trained models are automatically optimized for embedded deployment using a combination of TensorFlow utilities and Edge Impulse’s own open source technologies.
Model optimization
Quantization is the most common form of optimization used when deploying deep learning models to embedded devices. Edge Impulse uses TensorFlow’s Model Optimization Toolkit to quantize models, reducing their weights’ precision from float32 to int8 with minimal impact on accuracy.
Using TensorFlow Lite for Microcontrollers along with the emulation software Renode, Edge Impulse provides developers with an accurate estimate of the latency and memory usage of their model once it is deployed to the target embedded device. This makes it easy to determine the impact of optimizations such as quantization across different slices of the dataset:
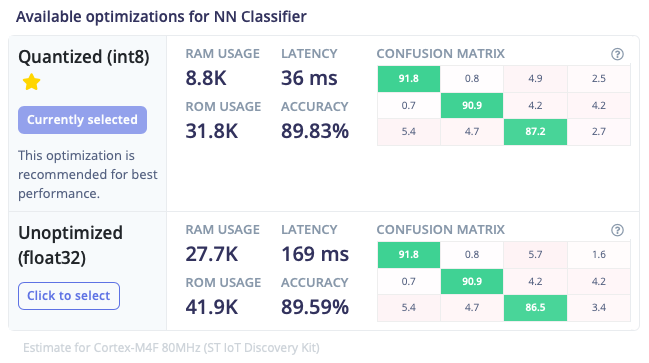 |
| A comparison between int8 quantized and unoptimized versions of the same mode, showing the difference in performance and results. |
For maximum flexibility and compatibility with developers’ existing workflows, the trained model is available for download in multiple formats. Developers can choose to export the original model as a TensorFlow SavedModel, or download one of several optimized models using the portable TensorFlow Lite flatbuffer format:
 |
| Download links for models serialized using TensorFlow’s SavedModel and TensorFlow Lite formats. |
Deployment
Once a model has been trained and tested there are multiple ways to deploy it to the target device. Embedded engineers work heavily with C++, so the standard option is to export a C++ SDK: a library of optimized source code that implements both the signal processing pipeline and the deep learning model. The SDK has a permissive open source license, so developers are free to use it in any project or share it with others.
There are two main options for running deep learning models, both of which make use of TensorFlow technologies. The first, Edge Impulse’s EON Compiler, is a code generation tool that converts TensorFlow Lite models into human readable C++ programs.
 |
| Enabling EON Compiler can reduce memory usage by up to 50% with no impact on model accuracy. |
EON Compiler makes use of the operator kernels implemented in TensorFlow Lite for Microcontrollers, invoking them in an efficient manner that doesn’t require the use of an interpreter. This results in memory savings of up to 50%. It automatically applies any available optimized kernels for the target device, meaning libraries such as Arm’s CMSIS-NN will be used where appropriate.
Some projects benefit from additional flexibility. In these cases, developers can choose to export a library that uses the TensorFlow Lite for Microcontrollers interpreter to run the model. This can be useful for developers who wish to experiment with custom kernel implementations for their specific hardware, or who are working within an environment that has TensorFlow Lite for Microcontrollers built in.
In addition to the C++ SDK, developers can choose to target specific environments. For example, a TensorRT library provides optimized support for NVidia’s Jetson Nano embedded Linux developer kit. This interoperability is enabled by the extensive TensorFlow ecosystem and open source community, which has tooling for numerous platforms and targets.
 |
| Models can be optimized and exported for targets in the broader TensorFlow ecosystem, such as NVidia’s Jetson Nano. |
Enabling new technologies
TensorFlow is unique amongst deep learning frameworks due to its broad, mature, and extensible set of technologies for training and deploying models to embedded devices. TensorFlow formats, such as the TensorFlow Lite flatbuffer, have become de-facto standards amongst companies bringing deep learning models to the edge.
The TensorFlow ecosystem has been key to enabling the growth of embedded machine learning, enabling companies like Edge Impulse to put artificial intelligence in the hands of domain experts who are building the next generation of consumer and industrial technologies.
If you’d like to learn more about embedded machine learning using Edge Impulse and TensorFlow, there are many options. Take a look at the Introduction to Embedded Machine Learning course on Coursera, or jump right in with the Getting Started guide or Recognize sounds from audio tutorial. You can even check out a public Edge Impulse project that you can clone and customize with a single click.
Daniel Situnayake
Founding TinyML Engineer, Edge Impulse.