Introduction
In 2019, Stanford entered the Alexa Prize Socialbot Grand Challenge 3 for the first time, with its bot Chirpy Cardinal, which went on to win 2nd place in the competition. In our previous post, we discussed the technical structure of our socialbot and how developers can use our open-source code to develop their own. In this post we share further research conducted while developing Chirpy Cardinal to discover common pain points that users encounter when interacting with socialbots, and strategies for addressing them.
The Alexa Prize is a unique research setting, as it allows researchers to study how users interact with a bot when doing so solely for their own motivations. During the competition, US-based Alexa users can say the phrase “let’s chat” to speak in English to an anonymous and randomly-selected competing bot. They are free to end the conversation at any time. Since Alexa Prize socialbots are intended to create as natural an experience as possible, they should be capable of long, open-domain social conversations with high coverage of topics. We observed that Chirpy users were interested in many different subjects, from current events (e.g., the coronavirus) to pop culture (e.g., the movie Frozen 2) to personal interests (e.g,. their pets). Chirpy achieves its coverage of these diverse topics by using a modular design that combines both neural generation and scripted dialogue, as described in our previous post.
We used this setting to study three questions about socialbot conversations:
- What do users complain about, and how can we learn from the complaints to improve neurally generated dialogue?
- What strategies are effective and ineffective in handling and deterring offensive user behavior?
- How can we shift the balance of power, such that both users and the bot are meaningfully controlling the conversation?
We’ve published papers on each of these topics at SIGDIAL 2021 and in this post, we’ll share key findings which provide practical insights for both chatbot researchers and developers.
1. Understanding and Predicting User Dissatisfaction
| paper | video |
Neural generative dialogue models like DialoGPT1, Meena2, and BlenderBot3 use large pretrained neural language models to generate responses given a dialogue history. These models perform well when evaluated by crowdworkers in carefully-controlled settings–typically written conversations with certain topical or length constraints.
However, real-life settings like the Alexa Prize are not so tidy. Users have widely varying expectations and personalities, and require fast response times as they speak with the bot in home environments that might feature cross-talk and background noise. Through Chirpy Cardinal, we have a unique opportunity to investigate how modern neural generative dialogue models hold up in this kind of environment.
Chirpy Cardinal uses a GPT2-medium model fine-tuned on the EmpatheticDialogues4 dataset to hold short discussions with users about their everyday experiences and emotions. Particularly during the pandemic, we found it was important for Chirpy to ask users about these issues. Though larger and more powerful pretrained generative models are available, we used GPT2-medium due to budget and latency constraints.
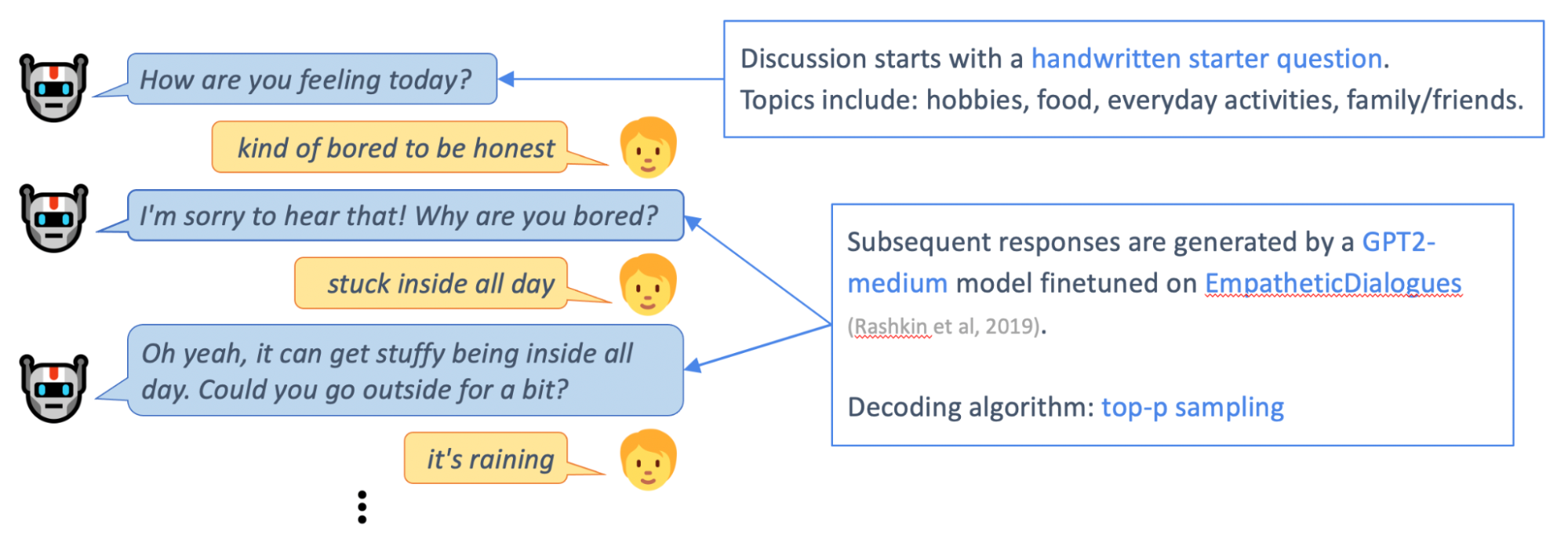
While the GPT2-medium model is capable of chatting about these simple topics for a few utterances, discussions that extend longer tend to derail. Sooner or later, the bot gives a response that doesn’t quite make sense, and it’s hard for the user or the model to recover the conversation.
To understand how these conversations are derailing, we defined 7 types of errors made by the neural generative model – repetition, redundant questions, unclear utterances, hallucination, ignoring, logical errors, and insulting utterances. After annotating a sample of user conversations, we found that bot errors were common, with over half (53%) of neural-generated utterances containing some kind of error.
We also found that due to the challenging noisy environment (which may involve background noise, cross-talk, and ASR errors), almost a quarter (22%) of user utterances were incomprehensible, even to a human annotator. This accounts for some of the more basic bot errors, such as ignoring, hallucination, unclear and repetitive utterances.
Of the remaining bot errors, redundant questions and logical errors are particularly common, indicating that better reasoning and use of the conversational history are a priority for neural generative model development.
We also tracked 9 ways that users express dissatisfaction, such as asking for clarification, criticising the bot, and ending the conversation. Though there is a relationship between bot errors and user dissatisfaction, the correlation is noisy. Even after a bot error, many users do not express dissatisfaction, instead attempting to continue the conversation. This is particularly true after logical errors, in which the bot shows a lack of real-world knowledge or commonsense – some kind-hearted users even take this as an opportunity to educate the bot. Conversely, some users express dissatisfaction unrelated to any obvious bot error – for example, users have widely differing expectations regarding what kinds of personal questions are appropriate from the bot.
Having better understood how and why users express dissatisfaction, we asked: can we learn to predict dissatisfaction, and thus prevent it before it happens?
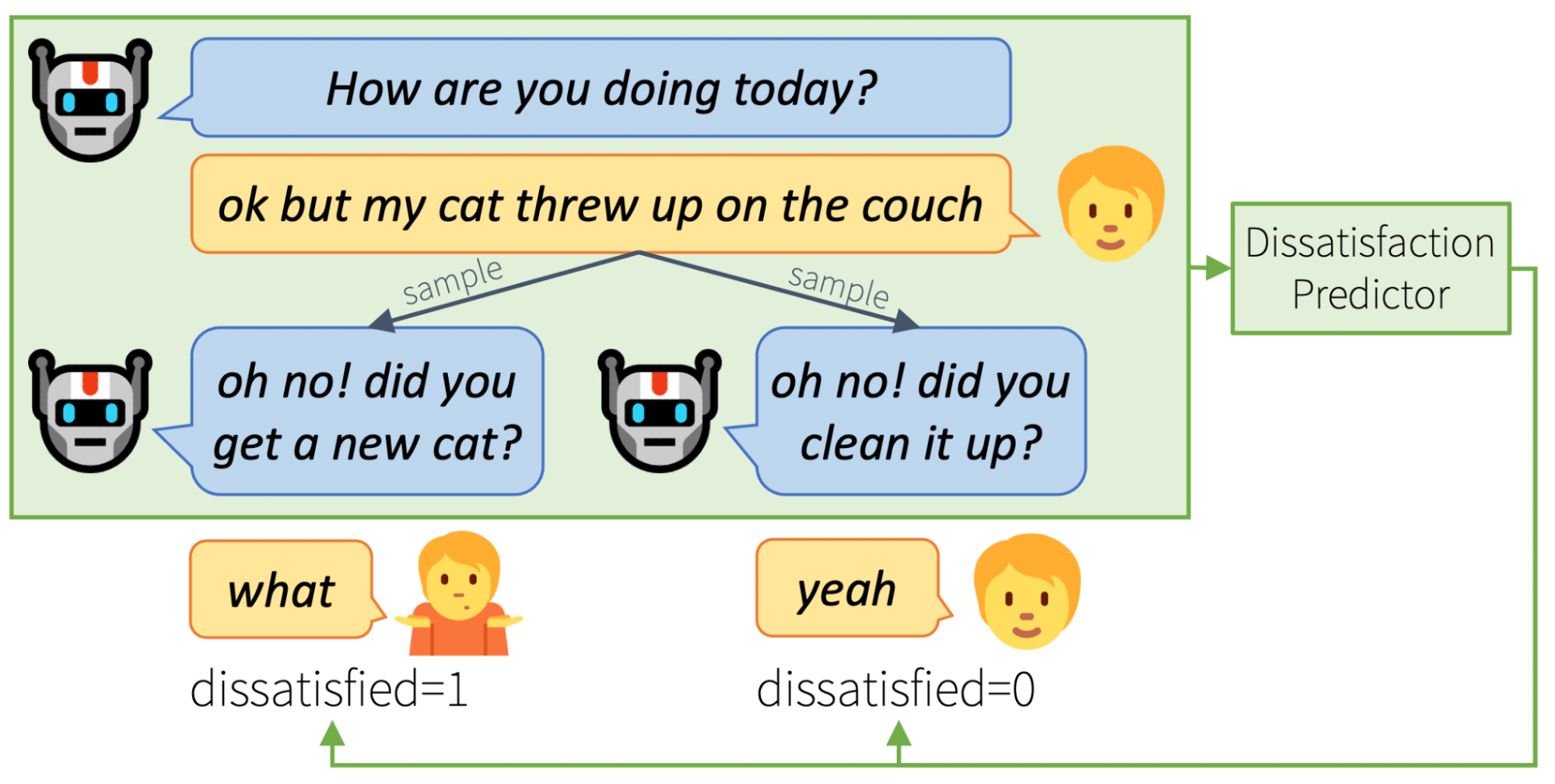
With the user conversations collected during the competition, we trained a model to predict the probability that a certain bot utterance would lead the user to express dissatisfaction. Given the noisy correlation between bot errors and user dissatisfaction, this is inherently challenging. Despite this noise, our predictor model was able to find signal in the users’ dissatisfaction.
Once trained, our dissatisfaction predictor can be used mid-conversation to choose between multiple alternative neural-generated bot utterances. Through human evaluation, we found that the bot responses chosen by the predictor – i.e., those judged least likely to cause user dissatisfaction – are overall better quality than randomly chosen responses.
Though we have not yet incorporated this feedback loop into Chirpy Cardinal, our method demonstrates one viable way to implement a semi-supervised online learning method to continuously improve a neural generative dialogue system.
2. Handling Offensive Users
| paper | video |
Voice assistants are becoming increasingly popular, and with their popularity, they are subject to growing abuse from their user populations. We estimate that more than 10% of user conversations with our bot, Chirpy Cardinal, contain profanity and overtly offensive language. While there is a large body of prior work attempting to address this issue, most prior approaches use qualitative metrics based on surveys conducted in lab settings. In this work, we conduct a large-scale quantitative evaluation of response strategies against offensive users in-the-wild. In our experiments, we found that politely rejecting the user’s offense while redirecting the user to an alternative topic is the best strategy in curbing offenses.
Informed by prior work, we test the following 4 hypotheses:
- Redirect – Inspired by Brahnam5, we hypothesize that using explicit redirection when responding to an offensive user utterance is an effective strategy. For example, “I’d rather not talk about that. So, who’s your favorite musician?”
- Name – Inspired by Suler6 and Chen and Williams7, we hypothesize that including the user’s name in the bot’s response is an effective strategy. For example, “I’d rather not talk about that, Peter.”
- Why – Inspired by Shapiro et al.8, we hypothesize that politely asking the user the reason why they made an offensive remark invites them to reflect on their behavior, reducing future offenses. For example, “Why would you say that?”
- Empathetic & Counter – Inspired by Chin et al.9, we hypothesize that empathetic responses are more effective than generic avoidance responses, while counter-attack responses make no difference. For example, an empathetic response would be “If I could talk about it I would, but I really can’t. Sorry to disappoint”, and a counter-attack response would be “That’s a very suggestive thing to say. I don’t think we should be talking about that.”
We constructed the responses crossing multiple factors listed above. For example, avoidance + name + redirect would yield the utterance “I’d rather not talk about that (avoidance), Peter (name). So, who’s your favorite musician? (redirect)”
To measure the effectiveness of a response strategy, we propose 3 metrics:
- Re-offense – measured as the number of conversations that contained another offensive utterance after the initial bot response.
- End – measured as the length of the conversation after bot response assuming no future offenses.
- Next – measured as the number of turns passed until the user offends again.
We believe that these metrics measure the effectiveness of a response strategy more directly than user ratings as done in Cohn et al.10 which measure the overall quality of the conversation.
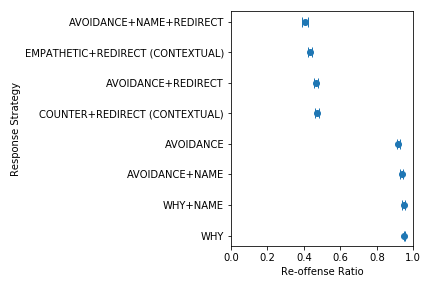
The figure above shows the differences of strategies on the Re-offense ratio. As we can see, strategies with (redirects) performed significantly better than strategies without redirects, reducing re-offense rate by as much as 53%. Our pairwise hypothesis tests further shows that using user’s name with a redirect further reduces re-offense rate by about 6%, and that asking the user why they made an offensive remark had a 3% increase in re-offense rate which shows that asking the user why only invites user re-offenses instead of self-reflection. Empathetic responses also reduced re-offense rate by 3%, while counter responses did not have any significant effect.
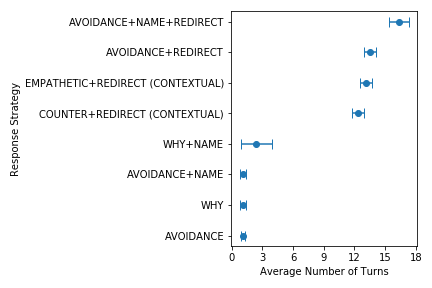
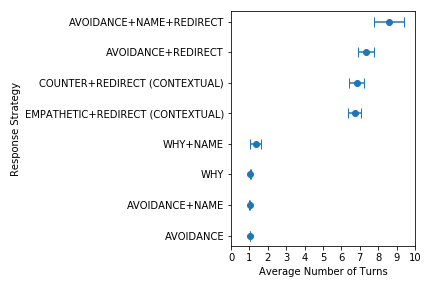
The figure on the left shows the differences in average number of turns until the next re-offense (Next), and the figure on the right shows the differences in average number of turns until the end of the conversation (End). We again see that strategies with (redirects are able to significantly prolong a non-offensive conversation. This further shows that redirection is incredibly effective method to curb user offenses.
The main takeaway from this is that the bot should always empathetically respond to user offenses with a redirection, and use the user’s name whenever possible.
Despite the empirical effectiveness of the passive avoidance and redirection strategy, we would like to remind researchers of the societal dangers of adopting similar strategies. Since most voice-based agents have a default female voice, these strategies could further gender stereotypes and set unreasonable expectations of how women would react to verbal abuse in the real world 11 12 13. Thus, caution must be taken when deploying these strategies.
3. Increasing User Initiative
| paper | video |
Conversations are either controlled by the user (for example, bots such as Apple’s Siri, which passively waits for user commands) or the bot (for example, CVS’s customer service bot, which repeatedly prompts the user for specific pieces of information).
This property – which agent has control at a given moment – is called initiative.
It wouldn’t be fun to go to a cocktail party and have a single person choose every topic, never giving you the opportunity to share your own interests. It’s also tedious to talk to someone who forces you to carry the conversation by refusing to bring up their own subjects. Ideally, everyone would take turns responding to prompts, sharing information about themselves, and introducing new topics. We call this pattern of dialogue mixed initiative and hypothesize that just as it’s an enjoyable type of human-human social conversation, it’s also a more engaging and desirable form of human-bot dialogue.
We designed our bot, Chirpy Cardinal, to keep conversations moving forward by asking questions on every turn. Although this helped prevent conversations from stagnating, it also made it difficult for users to take initiative. In our data, we observe users complaining about this, with comments such as you ask too many questions, or that’s not what I wanted to talk about.
Since our goal in studying initiative was to make human-bot conversations more like human-human ones, we looked to research on human dialogue for inspiration.
Based on this research, we formed three hypotheses for how to increase user initiative.
The images below show the types of utterances we experimented with as well as representative user utterances. Per Alexa Prize competition rules, these are not actual user utterances received by our bot.
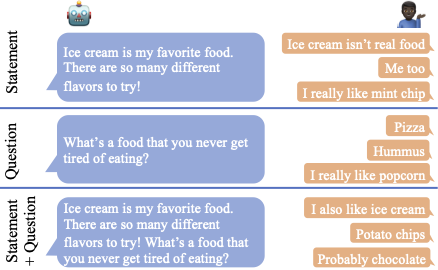
1. Giving statements instead of questions
In human dialogue research 14, the person asking a question has initiative, since they are giving a direction that the person answering follows. By contrast, an open-ended statement gives the listener an opportunity to take initiative. This was the basis of our first strategy: using statements instead of questions.

2. Sharing personal information
Work on both human-human 15 and human-bot 16 dialogue has found that personal self disclosure has a reciprocal effect. If one participant shares about themself, then the other person is more likely to do the same. We hypothesized that if Chirpy gave personal statements rather than general ones, then users would take initiative and reciprocate.


The figure on the left is an example of a conversation with back-channeling, the right, without. In this case, back-channeling allows the user to direct the conversation towards what they want (getting suggestions) rather than forcing them to talk about something they’re not interested in (hobbies).
3. Introducing back-channeling
Back-channels, such as “hmm”, “I see”, and “mm-hmm”, are brief utterances which are used as a signal from the listener to the speaker that the speaker should continue taking initiative. Our final hypothesis was that they could be used in human-bot conversation to the same effect, i.e. that if our bot back-channeled, then the user would direct the conversation.
Experiments and results
To test these strategies, we altered different components of our bot. We conducted small experiments, only altering a single turn of conversation, to test questions vs statements and personal vs general statements. To test the effect of replacing statements with questions on a larger number of turns, we altered components of our bot that used neurally generated dialogue, since these were more flexible to changing user inputs. Finally, we experimented with back-channeling in a fully neural module of our bot.
Using a set of automated metrics, which we validated using manual annotations, we found the following results, which provide direction for future conversational design:
- Using statements alone outperformed questions or combined statements and questions
- Giving personal opinion statements (e.g. “I like Bojack Horseman”) was more effective than both personal experience statements (e.g. “I watched Bojack Horseman yesterday”) and general statements (e.g. “Bojack Horseman was created by Raphael Bob-Waksberg and Lisa Hanawalt”)
- As the number of questions decreased, user initiative increased
- User initiative was greatest when we back-channeled 33% of the time (as opposed to 0%, 66%, or 100%)
Since these experiments were conducted in a limited environment, we do not expect that they would transfer perfectly to all social bots; however, we believe that these simple yet effective strategies are a promising direction for building more natural conversational AI.
4. Listen with empathy
Each of our projects began with dissatisfied users who told us, in their own words, what our bot could do better. By conducting a systematic analysis of these complaints, we gained a more precise understanding of what specifically was bothering users about our neurally generated responses. Using this feedback, we trained a model which was able to successfully predict when a generated response might lead the conversation astray. At times, it was the users who would make an offensive statement. We studied these cases and determined that an empathetic redirection, which incorporated the users name, was most effective at keeping the conversation on track. Finally, we experimented with simply saying less and creating greater opportunities for the user to lead the conversation. When presented with that chance, many took it, leading to longer and more informative dialogues.
Across all of our work, the intuitive principles of human conversation apply to socialbots: be a good listener, respond with empathy, and when you’re given feedback and the opportunity to learn, take it.
-
Zhang, Yizhe, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, and Bill Dolan. Dialogpt: Large-scale generative pre-training for conversational response generation](https://www.google.com/url?q=https://arxiv.org/abs/1911.00536&sa=D&source=editors&ust=1643077986262380&usg=AOvVaw1khQv7HglJrP1gK8dkiE3n).” arXiv preprint arXiv:1911.00536 (2019). ↩
-
Adiwardana, Daniel, Minh-Thang Luong, David R. So, Jamie Hall, Noah Fiedel, Romal Thoppilan, Zi Yang et al. Towards a human-like open-domain chatbot arXiv preprint arXiv:2001.09977 (2020). ↩
-
Roller, Stephen, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu et al. Recipes for building an open-domain chatbot arXiv preprint arXiv:2004.13637 (2020). ↩
-
Hannah Raskin, Eric Michael Smith, Margaret Li, and Y-Lan Boureau. 2019. Towards empathetic open-domain conversation models: A new benchmark and dataset. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 5370-5381, Florence, Italy. Association for Computational Linguistics. ↩
-
Sheryl Brahnam. 2005. Strategies for handling cus- tomer abuse of ECAs. In Proc. Interact 2005 work- shop Abuse: The darker side of Human-Computer Interaction, pages 62–67. ↩
-
John Suler. 2004. The online disinhibition effect. Cyberpsychology & behavior, 7(3):321–326. ↩
-
Xiangyu Chen and Andrew Williams. 2020. Improving Engagement by Letting Social Robots Learn and Call Your Name. In Companion of the 2020 ACM/IEEE International Conference on Human-Robot Interaction, HRI ’20, page 160–162, New York, NY, USA. Association for Computing Machinery. ↩
-
Shauna Shapiro, Kristen Lyons, Richard Miller, Britta Butler, Cassandra Vieten, and Philip Zelazo. 2014. Contemplation in the Classroom: a New Direction for Improving Childhood Education. Educational Psychology Review, 27. ↩
-
Hyojin Chin, Lebogang Wame Molefi, and Mun Yong Yi. 2020. Empathy Is All You Need: How a Conversational Agent Should Sespond to Verbal Abuse. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, pages 1–13. ↩
-
Michelle Cohn, Chun-Yen Chen, and Zhou Yu. 2019. A large-scale user study of an Alexa Prize chatbot: Effect of TTS dynamism on perceived quality of social dialog. In Proceedings of the 20th Annual SIGdial Meeting on Discourse and Dialogue, pages 293– 306, Stockholm, Sweden. Association for Computational Linguistics. ↩
-
Amanda Cercas Curry and Verena Rieser. 2019. A crowd-based evaluation of abuse response strategies in conversational agents. In Proceedings of the 20th Annual SIGdial Meeting on Discourse and Dialogue, pages 361–366, Stockholm, Sweden. Association for Computational Linguistics. ↩
-
Mark West, Rebecca Kraut, and Han Ei Chew. 2019. I’d blush if i could: closing gender divides in digital skills through education. ↩
-
Amanda Cercas Curry, Judy Robertson, and Verena Rieser. 2020. Conversational assistants and gender stereotypes: Public perceptions and desiderata for voice personas. In Proceedings of the Second Work- shop on Gender Bias in Natural Language Processing, pages 72–78, Barcelona, Spain (Online). Association for Computational Linguistics. ↩
-
Marilyn Walker and Steve Whittaker. 1990. Mixed initiative in dialogue: An investigation into discourse segmentation. In Proceedings of the 28th Annual Meeting on Association for Computational Linguistics, ACL ’90, page 70–78, USA. Association for Computational Linguistics. ↩
-
Nancy Collins and Lynn Miller. 1994. Self-disclosure and liking: A meta-analytic review. Psychological bulletin, 116:457–75. ↩
-
Yi-Chieh Lee, Naomi Yamashita, Yun Huang, and Wai Fu. 2020. “I hear you, I feel you”: Encouraging deep self-disclosure through a chatbot. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, CHI ’20, page 1–12, New York, NY, USA. Association for Computing Machinery. ↩