In this post, we discuss how United Airlines, in collaboration with the Amazon Machine Learning Solutions Lab, build an active learning framework on AWS to automate the processing of passenger documents.
“In order to deliver the best flying experience for our passengers and make our internal business process as efficient as possible, we have developed an automated machine learning-based document processing pipeline in AWS. In order to power these applications, as well as those using other data modalities like computer vision, we need a robust and efficient workflow to quickly annotate data, train and evaluate models, and iterate quickly. Over the course a couple months, United partnered with the Amazon Machine Learning Solutions Labs to design and develop a reusable, use case-agnostic active learning workflow using AWS CDK. This workflow will be foundational to our unstructured data-based machine learning applications as it will enable us to minimize human labeling effort, deliver strong model performance quickly, and adapt to data drift.”
– Jon Nelson, Senior Manager of Data Science and Machine Learning at United Airlines.
Problem
United’s Digital Technology team is made up of globally diverse individuals working together with cutting-edge technology to drive business outcomes and keep customer satisfaction levels high. They wanted to take advantage of machine learning (ML) techniques such as computer vision (CV) and natural language processing (NLP) to automate document processing pipelines. As part of this strategy, they developed an in-house passport analysis model to verify passenger IDs. The process relies on manual annotations to train ML models, which are very costly.
United wanted to create a flexible, resilient, and cost-efficient ML framework for automating passport information verification, validating passenger’s identities and detecting possible fraudulent documents. They engaged the ML Solutions Lab to help achieve this goal, which allows United to continue delivering world-class service in the face of future passenger growth.
Solution overview
Our joint team designed and developed an active learning framework powered by the AWS Cloud Development Kit (AWS CDK), which programmatically configures and provisions all necessary AWS services. The framework uses Amazon SageMaker to process unlabeled data, creates soft labels, launches manual labeling jobs with Amazon SageMaker Ground Truth, and trains an arbitrary ML model with the resulting dataset. We used Amazon Textract to automate information extraction from specific document fields such as name and passport number. On a high level, the approach can be described with the following diagram.
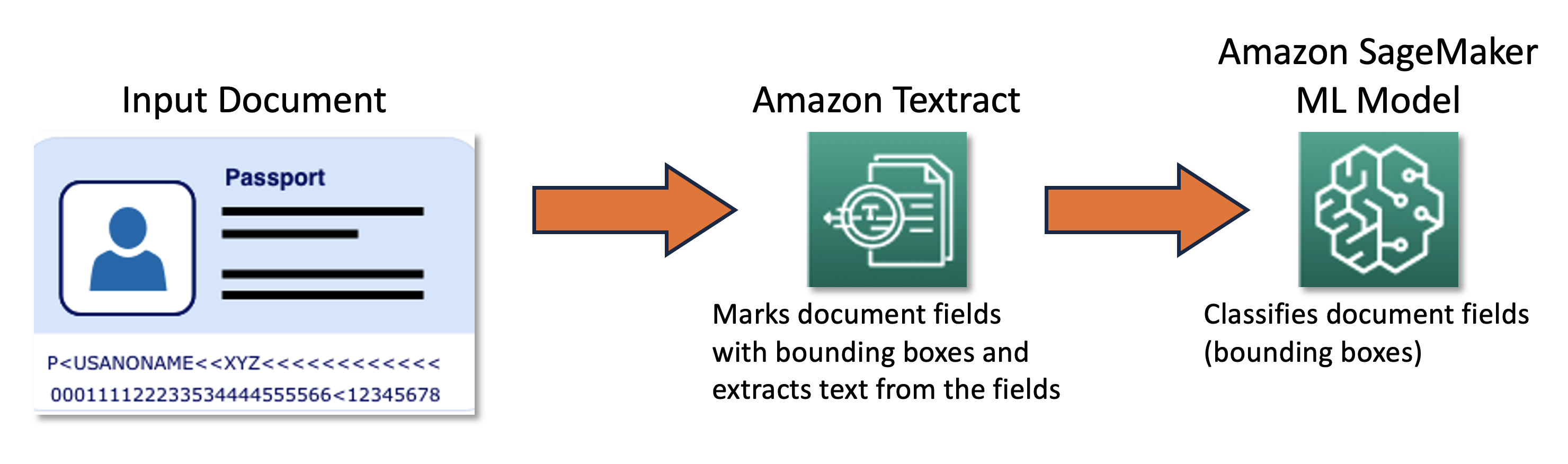
Data
The primary dataset for this problem is comprised of tens of thousands of main-page passport images from which personal information (name, date of birth, passport number, and so on) must be extracted. Image size, layout, and structure vary depending on the document issuing country. We normalize these images into a set of uniform thumbnails, which constitute the functional input for the active learning pipeline (auto-labeling and inference).
The second dataset contains JSON line formatted manifest files that relate raw passport images, thumbnail images, and label information such as soft labels and bounding box positions. Manifest files serve as a metadata set storing results from various AWS services in a unified format, and decouple the active learning pipeline from downstream services used by United. The following diagram illustrates this architecture.
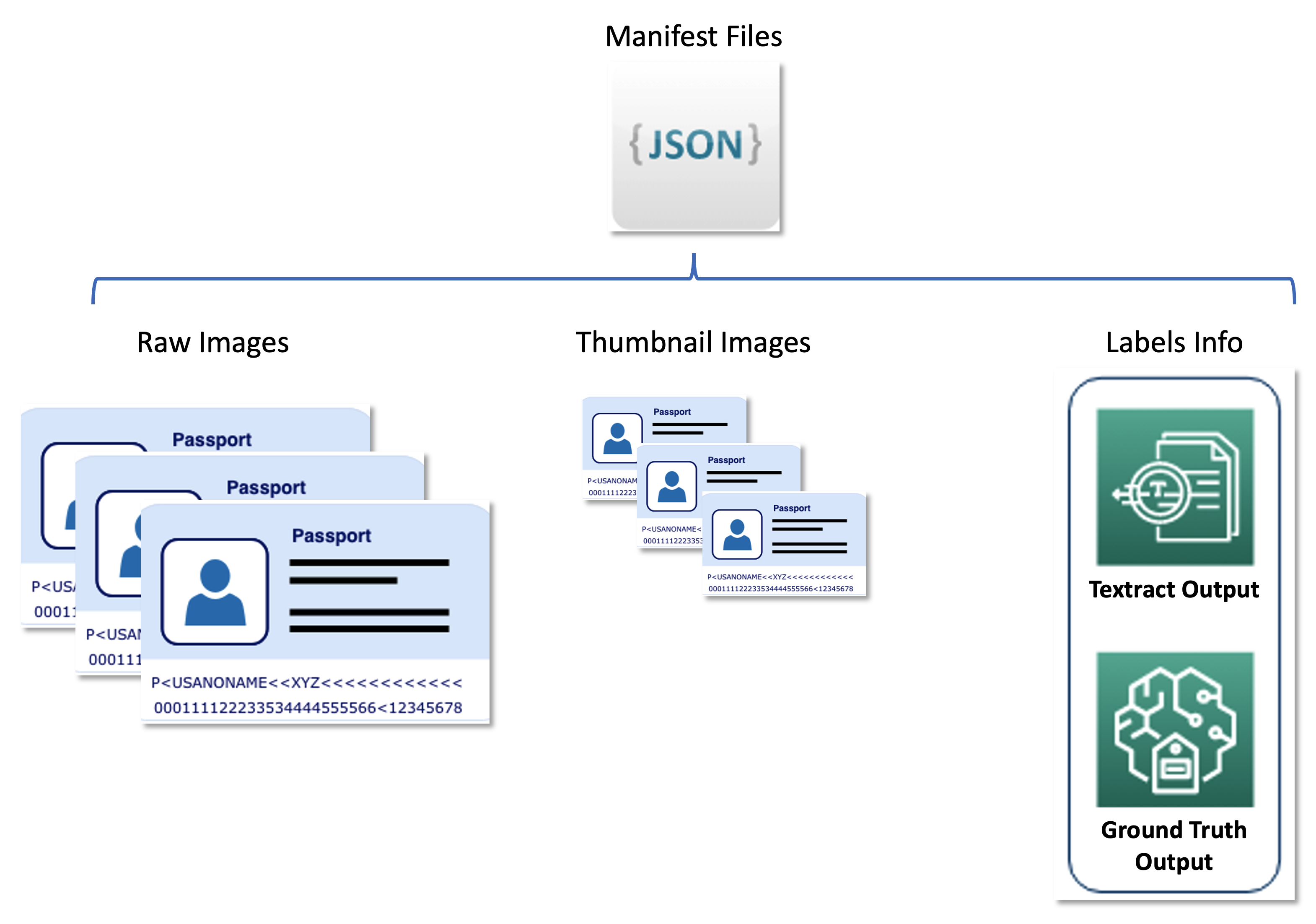
The following code is an example manifest file:
Solution components
The solution includes two main components:
- An ML framework, which is responsible for training the model
- An auto-labeling pipeline, which is responsible for improving trained model accuracy in a cost-efficient manner
The ML framework is responsible for training the ML model and deploying it as a SageMaker endpoint. The auto-labeling pipeline focuses on automating SageMaker Ground Truth jobs and sampling images for labeling through those jobs.
The two components are decoupled from each other and only interact through the set of labeled images produced by the auto-labeling pipeline. That is, the labeling pipeline creates labels that are later used by the ML framework to train the ML model.
ML framework
The ML Solutions Lab team built the ML framework using the Hugging Face implementation of the state-of-art LayoutLMV2 model (LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding, Yang Xu, et al.). Training was based on Amazon Textract outputs, which served as a preprocessor and produced bounding boxes around text of interest. The framework uses distributed training and runs on a custom Docker container based on the SageMaker pre-built Hugging Face image with additional dependencies (dependencies that are missing in the pre-built SageMaker Docker image but required for Hugging Face LayoutLMv2).
The ML model was trained to classify document fields in the following 11 classes:
The training pipeline can be summarized in the following diagram.
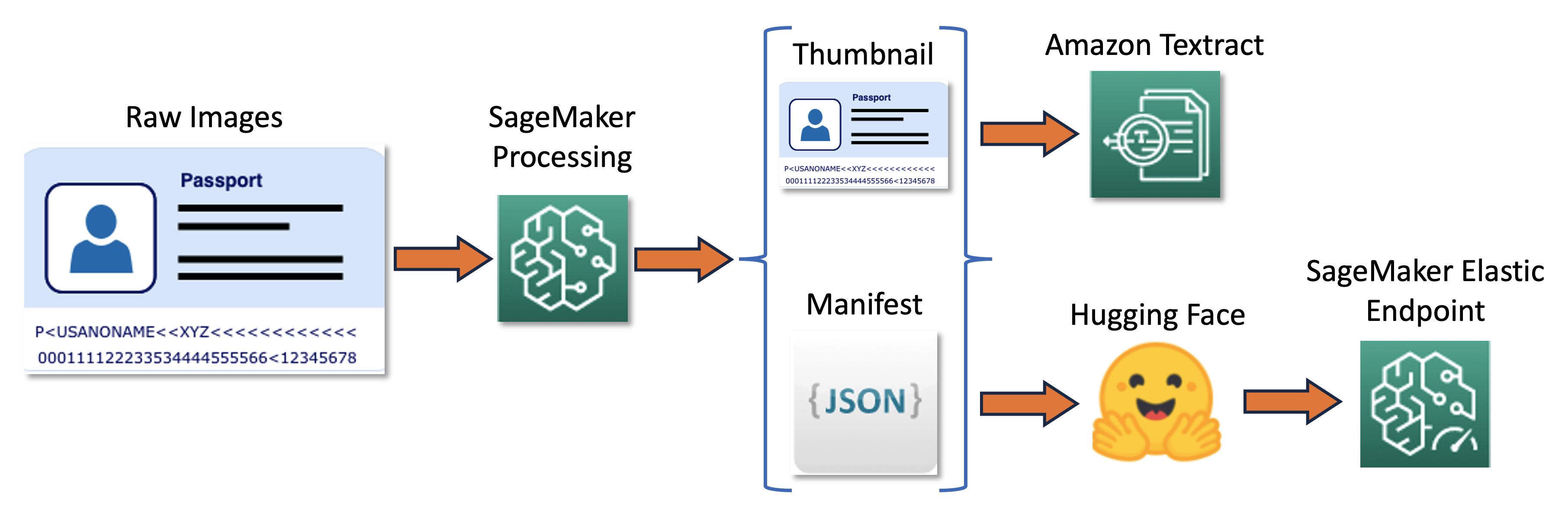
First, we resize and normalize a batch of raw images into thumbnails. At the same time, a JSON line manifest file with one line per image is created with information about raw and thumbnail images from the batch. Next, we use Amazon Textract to extract text bounding boxes in the thumbnail images. All information produced by Amazon Textract is recorded in the same manifest file. Finally, we use the thumbnail images and manifest data to train a model, which is later deployed as a SageMaker endpoint.
Auto-labeling pipeline
We developed an auto-labeling pipeline designed to perform the following functions:
- Run periodic batch inference on an unlabeled dataset.
- Filter results based on a specific uncertainty sampling strategy.
- Trigger a SageMaker Ground Truth job to label the sampled images using a human workforce.
- Add newly labeled images to the training dataset for subsequent model refinement.
The uncertainty sampling strategy reduces the number of images sent to the human labeling job by selecting images that would likely contribute the most to improving model accuracy. Because human labeling is an expensive task, such sampling is an important cost reduction technique. We support four sampling strategies, which can be selected as a parameter stored in Parameter Store, a capability of AWS Systems Manager:
- Least confidence
- Margin confidence
- Ratio of confidence
- Entropy
The entire auto-labeling workflow was implemented with AWS Step Functions, which orchestrates the processing job (called the elastic endpoint for batch inference), uncertainty sampling, and SageMaker Ground Truth. The following diagram illustrates the Step Functions workflow.

Cost-efficiency
The main factor influencing labeling costs is manual annotation. Before deploying this solution, the United team had to use a rule-based approach, which required expensive manual data annotation and third-party parsing OCR techniques. With our solution, United reduced their manual labeling workload by manually labeling only images that would result in the largest model improvements. Because the framework is model-agnostic, it can be used in other similar scenarios, extending its value beyond passport images to a much broader set of documents.
We performed a cost analysis based on the following assumptions:
- Each batch contains 1,000 images
- Training is performed using an mlg4dn.16xlarge instance
- Inference is performed on an mlg4dn.xlarge instance
- Training is done after each batch with 10% of annotated labels
- Each round of training results in the following accuracy improvements:
- 50% after the first batch
- 25% after the second batch
- 10% after the third batch
Our analysis shows that training cost remains constant and high without active learning. Incorporating active learning results in exponentially decreasing costs with each new batch of data.
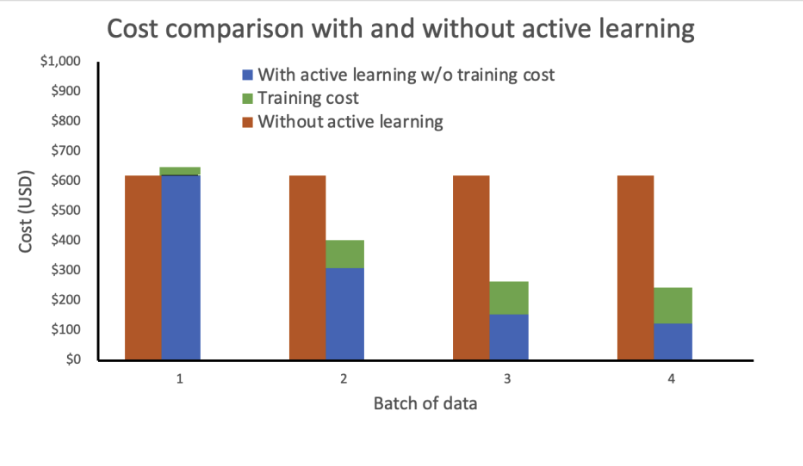
We further reduced costs by deploying the inference endpoint as an elastic endpoint by adding an auto scaling policy. The endpoint resources can scale up or down between zero and a configured maximum number of instances.
Final solution architecture
Our focus was to help the United team meet their functional requirements while building a scalable and flexible cloud application. The ML Solutions Lab team developed the complete production-ready solution with help of AWS CDK, automating management and provisioning of all cloud resources and services. The final cloud application was deployed as a single AWS CloudFormation stack with four nested stacks, each represented a single functional component.
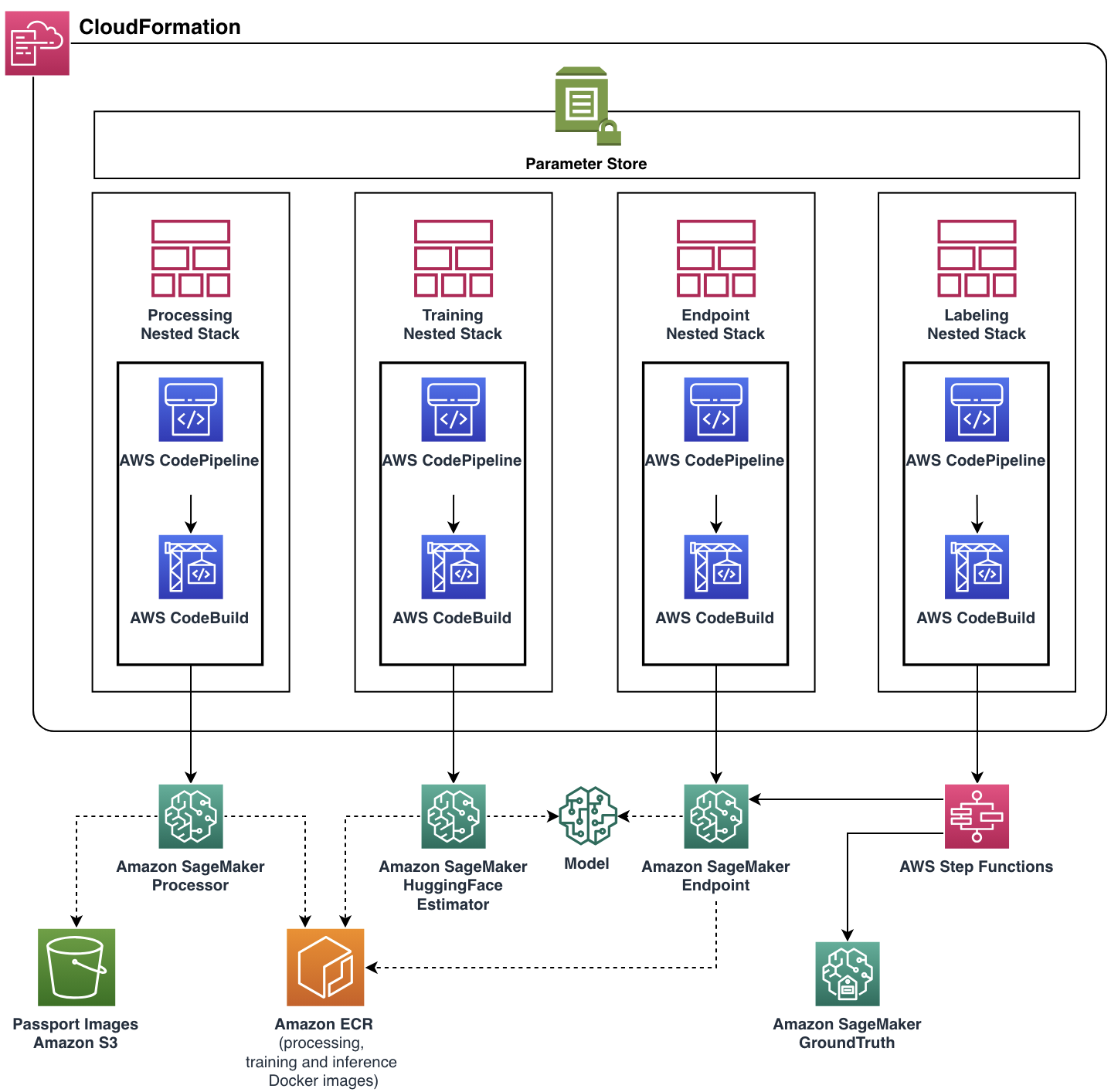
Almost every pipeline feature, including Docker images, endpoint auto scaling policy, and more, was parameterized through Parameter Store. With such flexibility, the same pipeline instance could be run with a broad range of settings, adding the ability to experiment.
Conclusion
In this post, we discussed how United Airlines, in collaboration with the ML Solutions Lab, built an active learning framework on AWS to automate the processing of passenger documents. The solution had great impact on two important aspects of United’s automation goals:
- Reusability – Due to the modular design and model-agnostic implementation, United Airlines can reuse this solution on almost any other auto-labeling ML use case
- Recurring cost reduction – By intelligently combining manual and auto-labeling processes, the United team can reduce average labeling costs and replace expensive third-party labeling services
If you are interested in implementing a similar solution or want to learn more about the ML Solutions Lab, contact your account manager or visit us at Amazon Machine Learning Solutions Lab.
About the Authors
 Xin Gu is the Lead Data Scientist – Machine Learning at United Airlines’ Advanced Analytics and Innovation division. She contributed significantly to designing machine-learning-assisted document understanding automation and played a key role in expanding data annotation active learning workflows across diverse tasks and models. Her expertise lies in elevating AI efficacy and efficiency, achieving remarkable progress in the field of intelligent technological advancements at United Airlines.
Xin Gu is the Lead Data Scientist – Machine Learning at United Airlines’ Advanced Analytics and Innovation division. She contributed significantly to designing machine-learning-assisted document understanding automation and played a key role in expanding data annotation active learning workflows across diverse tasks and models. Her expertise lies in elevating AI efficacy and efficiency, achieving remarkable progress in the field of intelligent technological advancements at United Airlines.
 Jon Nelson is the Senior Manager of Data Science and Machine Learning at United Airlines.
Jon Nelson is the Senior Manager of Data Science and Machine Learning at United Airlines.
 Alex Goryainov is Machine Learning Engineer at Amazon AWS. He builds architecture and implements core components of active learning and auto-labeling pipeline powered by AWS CDK. Alex is an expert in MLOps, cloud computing architecture, statistical data analysis and large scale data processing.
Alex Goryainov is Machine Learning Engineer at Amazon AWS. He builds architecture and implements core components of active learning and auto-labeling pipeline powered by AWS CDK. Alex is an expert in MLOps, cloud computing architecture, statistical data analysis and large scale data processing.
 Vishal Das is an Applied Scientist at the Amazon ML Solutions Lab. Prior to MLSL, Vishal was a Solutions Architect, Energy, AWS. He received his PhD in Geophysics with a PhD minor in Statistics from Stanford University. He is committed to working with customers in helping them think big and deliver business results. He is an expert in machine learning and its application in solving business problems.
Vishal Das is an Applied Scientist at the Amazon ML Solutions Lab. Prior to MLSL, Vishal was a Solutions Architect, Energy, AWS. He received his PhD in Geophysics with a PhD minor in Statistics from Stanford University. He is committed to working with customers in helping them think big and deliver business results. He is an expert in machine learning and its application in solving business problems.
 Tianyi Mao is an Applied Scientist at AWS based out of Chicago area. He has 5+ years of experience in building machine learning and deep learning solutions and focuses on computer vision and reinforcement learning with human feedbacks. He enjoys working with customers to understand their challenges and solve them by creating innovative solutions using AWS services.
Tianyi Mao is an Applied Scientist at AWS based out of Chicago area. He has 5+ years of experience in building machine learning and deep learning solutions and focuses on computer vision and reinforcement learning with human feedbacks. He enjoys working with customers to understand their challenges and solve them by creating innovative solutions using AWS services.
 Yunzhi Shi is an Applied Scientist at the Amazon ML Solutions Lab, where he works with customers across different industry verticals to help them ideate, develop, and deploy AI/ML solutions built on AWS Cloud services to solve their business challenges. He has worked with customers in automotive, geospatial, transportation, and manufacturing. Yunzhi obtained his Ph.D. in Geophysics from The University of Texas at Austin.
Yunzhi Shi is an Applied Scientist at the Amazon ML Solutions Lab, where he works with customers across different industry verticals to help them ideate, develop, and deploy AI/ML solutions built on AWS Cloud services to solve their business challenges. He has worked with customers in automotive, geospatial, transportation, and manufacturing. Yunzhi obtained his Ph.D. in Geophysics from The University of Texas at Austin.
 Diego Socolinsky is a Senior Applied Science Manager with the AWS Generative AI Innovation Center, where he leads the delivery team for the Eastern US and Latin America regions. He has over twenty years of experience in machine learning and computer vision, and holds a PhD degree in mathematics from The Johns Hopkins University.
Diego Socolinsky is a Senior Applied Science Manager with the AWS Generative AI Innovation Center, where he leads the delivery team for the Eastern US and Latin America regions. He has over twenty years of experience in machine learning and computer vision, and holds a PhD degree in mathematics from The Johns Hopkins University.
 Xin Chen is currently the Head of People Science Solutions Lab at Amazon People eXperience Technology (PXT, aka HR) Central Science. He leads a team of applied scientists to build production grade science solutions to proactively identify and launch mechanisms and process improvements. Previously, he was head of Central US, Greater China Region, LATAM and Automotive Vertical in AWS Machine Learning Solutions Lab. He helped AWS customers identify and build machine learning solutions to address their organization’s highest return-on-investment machine learning opportunities. Xin is adjunct faculty at Northwestern University and Illinois Institute of Technology. He obtained his PhD in Computer Science and Engineering at the University of Notre Dame.
Xin Chen is currently the Head of People Science Solutions Lab at Amazon People eXperience Technology (PXT, aka HR) Central Science. He leads a team of applied scientists to build production grade science solutions to proactively identify and launch mechanisms and process improvements. Previously, he was head of Central US, Greater China Region, LATAM and Automotive Vertical in AWS Machine Learning Solutions Lab. He helped AWS customers identify and build machine learning solutions to address their organization’s highest return-on-investment machine learning opportunities. Xin is adjunct faculty at Northwestern University and Illinois Institute of Technology. He obtained his PhD in Computer Science and Engineering at the University of Notre Dame.