Machine learning (ML) has shown great promise across domains such as predictive analysis, speech processing, image recognition, recommendation systems, bioinformatics, and more. Training ML models is a time- and compute-intensive process, requiring multiple training runs with different hyperparameters before a model yields acceptable accuracy. CPU- and GPU-based distributed training with frameworks such as Horovod and Parameter Servers addresses this issue by allowing training to be easily scalable to a cluster of resources. However, distributed training makes it harder to identify and debug resource bottlenecks. Gaining insight into the training in progress, both at the ML framework level and the underlying compute resources level, is a critical step towards understanding resource usage patterns and reducing resource wastage. Analyzing bottleneck issues is necessary to maximize the utilization of compute resources and optimize model training performance to deliver state-of-the-art ML models with target accuracy.
Amazon SageMaker is a fully managed service that enables developers and data scientists to quickly and easily build, train, and deploy ML models at scale. Amazon SageMaker Debugger is a feature of SageMaker training that makes it easy to train ML models faster by capturing real-time metrics such as learning gradients and weights. This provides transparency into the training process, so you can correct anomalies such as losses, overfitting, and overtraining. Debugger provides built-in rules to easily analyze emitted data, including tensors that are critical for the success of training jobs.
With the newly introduced profiling capability, Debugger now automatically monitors system resources such as CPU, GPU, network, I/O, and memory, providing a complete resource utilization view of training jobs. You can also profile your entire training job or portions thereof to emit detailed framework metrics during different phases of the training job. Framework metrics are metrics that are captured from within the training script, such as step duration, data loading, preprocessing, and operator runtime on CPU and GPU.
Debugger correlates system and framework metrics, which helps you identify possible root causes. For example, if utilization on GPU drops to zero, you can inspect what has been happening within the training script at this particular time. You can right-size resources and quickly identify bottlenecks and fix them using insights from the profiler.
You can re-allocate resources based on recommendations from the profiling capability. Metrics and insights are captured and monitored programmatically using the SageMaker Python SDK or visually through Amazon SageMaker Studio.
In this post, we demonstrate Debugger profiling capabilities using a TensorFlow-based sentiment analysis use case. In the notebook included in this post, we set a Convolutional Neural Network (CNN) using TensorFlow script mode on SageMaker. For our dataset, we use the IMDB dataset, which consists of movie reviews labeled as positive or negative sentiment. We use Debugger to showcase how to gain visibility into utilizing system resources of the training instances, profile framework metrics, and identify an underutilized training resource due to resource bottlenecks. We further demonstrate how to improve resource utilization after implementing the recommendations from Debugger.
Walkthrough overview
The remainder of this post details how to use the Debugger profiler capability to gain visibility into ML training jobs and analysis of profiler recommendations. The notebook includes details of using TensorFlow Horovod distributed training where the profiling capability enabled us to improve resource utilization up to 36%. The first training run was on three p3.8xlarge instances for 503 seconds, and the second training run after implementing the profiler recommendations took 502 seconds on two p3.2xlarge instances, resulting in 83% cost savings. Profiler analysis of the second training run provided additional recommendations highlighting the possibility of further cost savings and better resource utilization.
The walkthrough includes the following high-level steps:
- Train a TensorFlow sentiment analysis CNN model using SageMaker distributed training with custom profiler configuration.
- Visualize the system and framework metrics generated to analyze the profiler data.
- Access Debugger Insights in Studio.
- Analyze the profiler report generated by Debugger.
- Analyze and Implement recommendations from the profiler report.
Additional steps such as importing the necessary libraries and examining the dataset are included in the notebook. Review the notebook for complete details.
Training a CNN model using SageMaker distributed training with custom profiler configuration
In this step, you train the sentiment analysis model using TensorFlow estimator with the profiler enabled.
First ensure that Debugger libraries are imported. See the following code:
# import debugger libraries
from sagemaker.debugger import ProfilerConfig, DebuggerHookConfig, Rule, ProfilerRule, rule_configs, FrameworkProfileNext, set up Horovod distribution for TensorFlow distributed training. Horovod is a distributed deep learning training framework for TensorFlow, Keras, and PyTorch. The objective is to take a single-GPU training script and successfully scale it to train across many GPUs in parallel. After a training script has been written for scale with Horovod, it can run on a single GPU, multiple GPUs, or even multiple hosts without any further code changes. In addition to being easy to use, Horovod is fast. For more information, see the Horovod GitHub page.
We can set up hyperparameters such as number of epochs, batch size, and data augmentation:
hyperparameters = {'epoch': 25,
'batch_size': 256,
'data_augmentation': True}Changing these hyperparameters might impact resource utilization with your training job.
For our training, we start off using three p3.8xlarge instances and change our training configuration based on profiling recommendations from Debugger:
distributions = {
"mpi": {
"enabled": True,
"processes_per_host": 3,
"custom_mpi_options": "-verbose -x HOROVOD_TIMELINE=./hvd_timeline.json -x NCCL_DEBUG=INFO -x OMPI_MCA_btl_vader_single_copy_mechanism=none",
}
}
model_dir = '/opt/ml/model'
train_instance_type='ml.p3.8xlarge'
instance_count = 3The p3.8xlarge instance comes with 4 GPUs and 32 vCPU cores with 10 Gbps networking performance. For more information, see Amazon EC2 Instance Types. Take your AWS account limits into consideration while setting up the instance_type and instance_count of the cluster.
Then we define the profiler configuration. With the following profiler_config parameter configuration, Debugger calls the default settings of monitoring and profiling. Debugger monitors system metrics every 500 milliseconds. You specify additional details on when to start and how long to run profiling. You can set different profiling settings to profile target steps and target time intervals in detail.
profiler_config = ProfilerConfig(
system_monitor_interval_millis=500,
framework_profile_params=FrameworkProfile(start_step=2, num_steps=7)
)For complete list of parameters, see Amazon SageMaker Debugger.
Then we configure a training job using TensorFlow estimator and pass in the profiler configuration. For framework_version and py_version, specify the TensorFlow framework version and supported Python version, respectively:
estimator = TensorFlow(
role=sagemaker.get_execution_role(),
base_job_name= 'tf-keras-silent',
image_uri=f"763104351884.dkr.ecr.{region}.amazonaws.com/tensorflow-training:2.3.1-gpu-py37-cu110-ubuntu18.04",
model_dir=model_dir,
instance_count=instance_count,
instance_type=train_instance_type,
entry_point= 'sentiment-distributed.py',
source_dir='./tf-sentiment-script-mode',
profiler_config=profiler_config,
script_mode=True,
hyperparameters=hyperparameters,
distribution=distributions
)For complete list of the supported framework versions and the corresponding Python version to use, see Amazon SageMaker Debugger.
Finally, start the training job:
estimator.fit(inputs, wait= False)Visualizing the system and framework metrics generated
Now that our training job is running, we can perform interactive analysis of the data captured by Debugger. The analysis is organized in order of training phases: initialization, training, and finalization. The profiling data results are categorized as system metrics and algorithm (framework) metrics. After the training job initiates, Debugger starts collecting system and framework metrics. The smdebug library provides profiler analysis tools that enable you to access and analyze the profiling data.
First, we collect the system and framework metrics using the S3SystemMetricsReader library:
from smdebug.profiler.system_metrics_reader import S3SystemMetricsReader
import time
path = estimator.latest_job_profiler_artifacts_path()
system_metrics_reader = S3SystemMetricsReader(path)Check if we have metrics available for analysis:
while system_metrics_reader.get_timestamp_of_latest_available_file() == 0:
system_metrics_reader.refresh_event_file_list()
client = sagemaker_client.describe_training_job(
TrainingJobName=training_job_name
)
if 'TrainingJobStatus' in client:
training_job_status = f"TrainingJobStatus: {client['TrainingJobStatus']}"
if 'SecondaryStatus' in client:
training_job_secondary_status = f"TrainingJobSecondaryStatus: {client['SecondaryStatus']}"When the data is available, we can query and inspect it:
system_metrics_reader.refresh_event_file_list()
last_timestamp = system_metrics_reader.get_timestamp_of_latest_available_file()
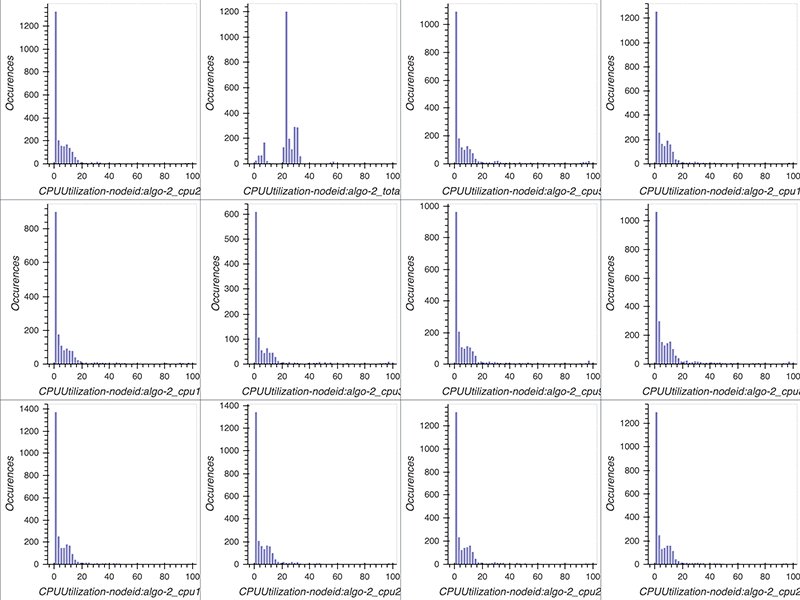
events = system_metrics_reader.get_events(0, last_timestamp)Along with the notebook, the smdebug SDK contains several utility classes that can be used for visualizations. From the data collected, you can visualize the CPU and GPU utilization values as a histogram using the utility class MetricHistogram. MetricHistogram computes a histogram on GPU and CPU utilization values. Bins are between 0–100. Good system utilization means that the center of the distribution should be between 80–90. In case of multi-GPU training, if distributions of GPU utilization values aren’t similar, it indicates an issue with workload distribution.
The following code plots the histograms per metric. To only plot specific metrics, define the list select_dimensions and select_events. A dimension can be CPUUtilization, GPUUtilization, or GPUMemoryUtilization IOPS. If no event is specified, then for the CPU utilization, a histogram for each single core and total CPU usage is plotted.
from smdebug.profiler.analysis.notebook_utils.metrics_histogram import MetricsHistogram
system_metrics_reader.refresh_event_file_list()
metrics_histogram = MetricsHistogram(system_metrics_reader)The following screenshot shows our histograms.
Similar to system metrics, let’s retrieve all the events emitted from the framework or algorithm metrics using the following code:
from smdebug.profiler.algorithm_metrics_reader import S3AlgorithmMetricsReader
framework_metrics_reader = S3AlgorithmMetricsReader(path)
events = []
while framework_metrics_reader.get_timestamp_of_latest_available_file() == 0 or len(events) == 0:
framework_metrics_reader.refresh_event_file_list()
last_timestamp = framework_metrics_reader.get_timestamp_of_latest_available_file()
events = framework_metrics_reader.get_events(0, last_timestamp)
framework_metrics_reader.refresh_event_file_list()
last_timestamp = framework_metrics_reader.get_timestamp_of_latest_available_file()
events = framework_metrics_reader.get_events(0, last_timestamp)We can inspect one of the recorded events to get the following:
print("Event name:", events[0].event_name,
"nStart time:", timestamp_to_utc(events[0].start_time/1000000000),
"nEnd time:", timestamp_to_utc(events[0].end_time/1000000000),
"nDuration:", events[0].duration, "nanosecond")
Event name: Step:ModeKeys.TRAIN
Start time: 2020-12-04 22:44:14
End time: 2020-12-04 22:44:25
Duration: 10966842000 nanosecondFor more information about system and framework metrics, see documentation.
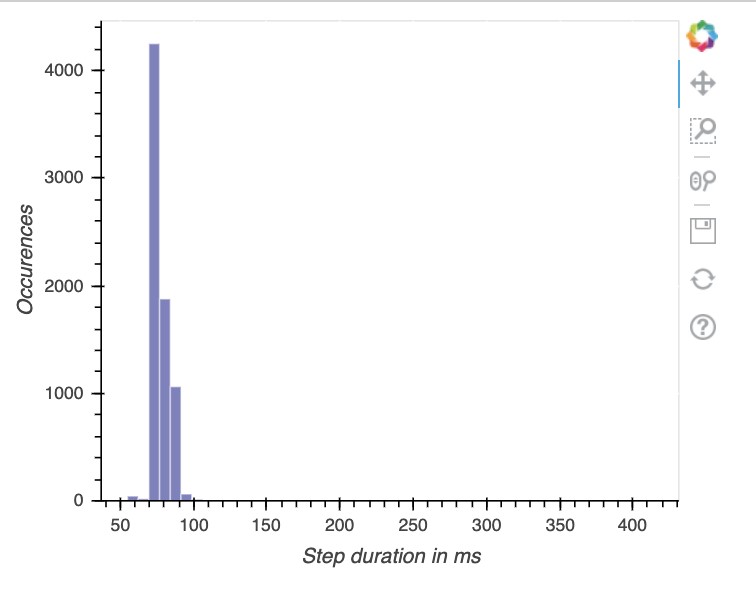
Next, we use the StepHistogram utility class to create a histogram of step duration values. Significant outliers in step durations are an indication of a bottleneck. It allows you to easily identify clusters of step duration values.
from smdebug.profiler.analysis.notebook_utils.step_histogram import StepHistogram
framework_metrics_reader.refresh_event_file_list()
step_histogram = StepHistogram(framework_metrics_reader)
The following screenshot shows our visualization.
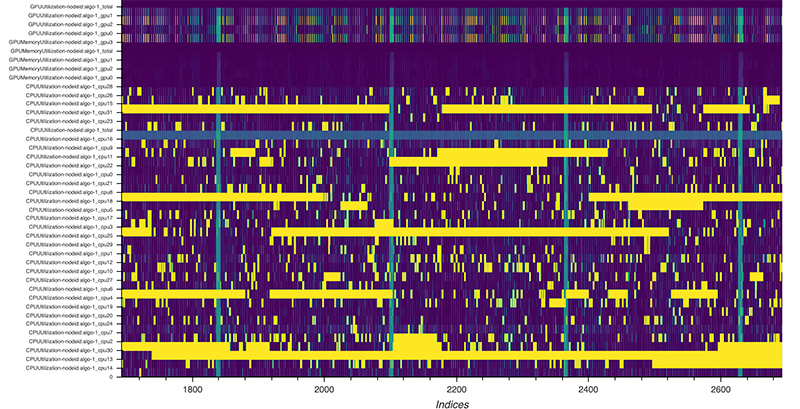
For an alternative view of CPU and GPU utilizations, the following code creates a heat map where each row corresponds to one metric (CPU core and GPU utilizations) and the x-axis is the duration of the training job. It allows you to more easily spot CPU bottlenecks, for example, if utilization on GPU is low but a utilization of one or more cores is high.
from smdebug.profiler.analysis.notebook_utils.heatmap import Heatmap
view_heatmap = Heatmap(
system_metrics_reader,
framework_metrics_reader,
select_dimensions=["CPU", "GPU", "I/O"], # optional
select_events=["total"], # optional
plot_height=450
)The following screenshot shows the heat map of a training job that has been using 4 GPUs and 32 CPU cores. The first few rows show the GPUs’ utilization, and the remaining rows show the utilization on CPU cores. Yellow indicates maximum utilization, and purple means that utilization was 0. GPUs have frequent stalled cycles where utilization drops to 0, whereas at the same time, utilization on CPU cores is at a maximum. This is a clear indication of a CPU bottleneck where GPUs are waiting for the data to arrive. Such a bottleneck can occur by a too compute-heavy preprocessing.
Accessing Debugger Insights in Studio
You can also use Studio to perform training with our existing notebook. Studio provides built-in visualizations to analyze profiling insights. Alternatively, you can move to next section in this post to directly analyze the profiler report generated.
If you trained in a SageMaker notebook instance, you can still find the Debugger insights for that training in Studio if the training happened in same Region.
- On the navigation pane, choose Components and registries.
- Choose Experiments and trails.
- Choose your training job (right-click).
- Choose Debugger Insights.
For more information about setting up Studio, see Set up Amazon SageMaker.
Reviewing Debugger reports
After you have set up and run this notebook in Studio, you can access Debugger Insights.
- On the navigation pane, choose Components and registries.
- Choose Experiments and trails.
- Choose your training job (right-click).
- Choose View Debugger for insights.
A Debugger tab opens for this training job. For more information, see Debugger Insights.
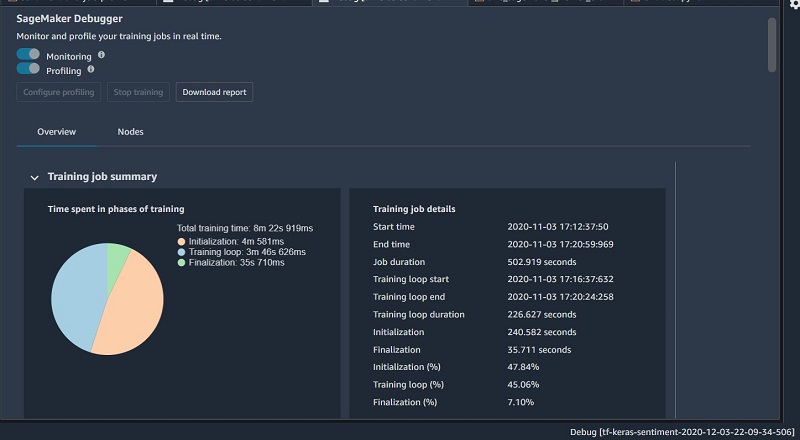
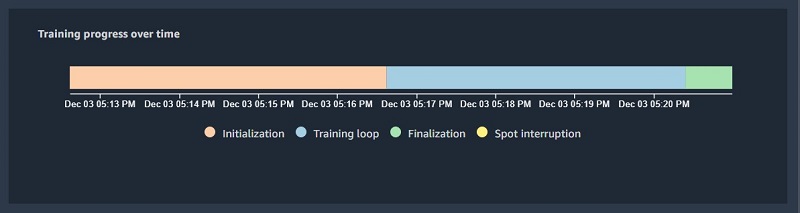
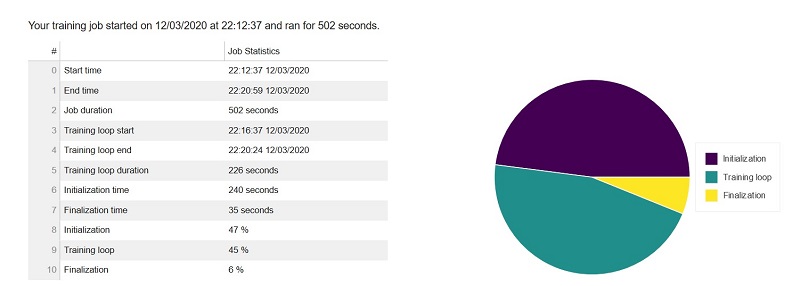
Training job summary
This section of the report shows details of the training job, such as the start time, end time, duration, and time spent in individual phases of the training. The pie chart visualization of these delays shows the time spent in initialization, training, and finalization phases relative to each other.
System usage statistics
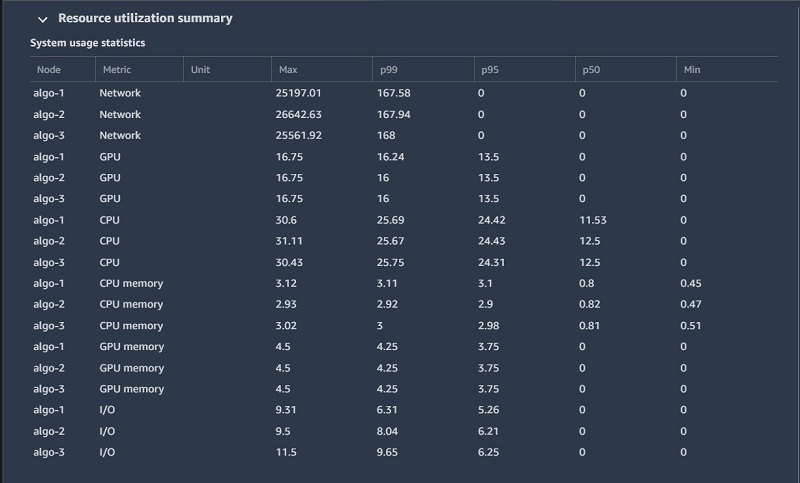
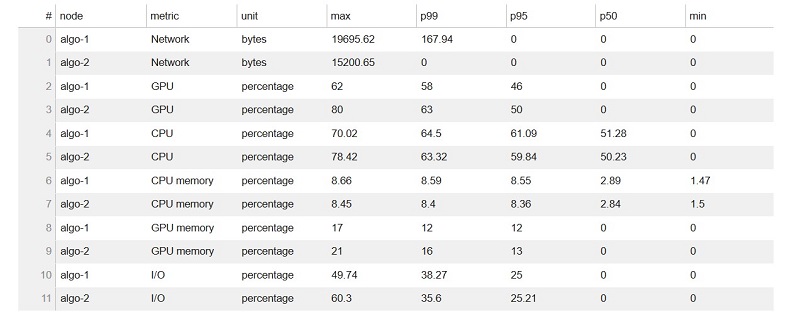
This portion of the report gives detailed system usage statistics for both training instances involved in training, along with analysis and suggestions for improvements. The following text is an excerpt from the report, with key issues highlighted:
The 95th quantile of the total GPU utilization on node algo-1 is only 13%. The 95th quantile of the total CPU utilization is only 24%. Node algo-1 is under-utilized. You may want to consider switching to a smaller instance type. The 95th quantile of the total GPU utilization on node algo-2 is only 13%. The 95th quantile of the total CPU utilization is only 24%. Node algo-2 is under-utilized. You may want to consider switching to a smaller instance type. The 95th quantile of the total GPU utilization on node algo-3 is only 13%. The 95th quantile of the total CPU utilization is only 24%. Node algo-3 is under-utilized. You may want to consider switching to a smaller instance type.
The following table shows usage statistics per worker node, such as total CPU and GPU utilization, total CPU, and memory footprint. The table also include total I/O wait time and total sent and received bytes. The table shows minimum and maximum values as well as p99, p90, and p50 percentiles.
Framework metrics summary
In this section, the following pie charts show the breakdown of framework operations on CPUs and GPUs.

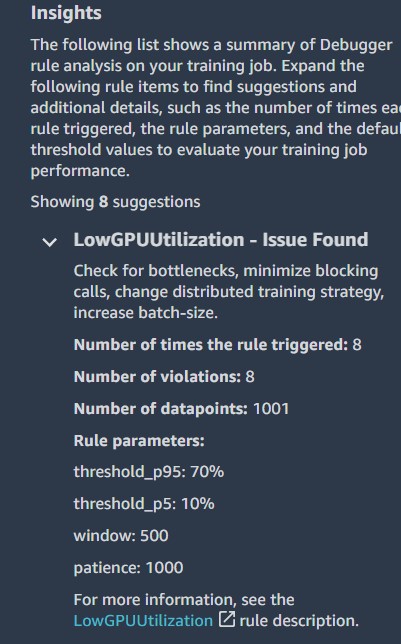
Insights
Insights provides suggestions and additional details, such as the number of times each rule triggered, the rule parameters, and the default threshold values to evaluate your training job performance. According to the insights for our TensorFlow training job, profiler rules were run for three out of the eight insights. The following screenshot shows the insights.
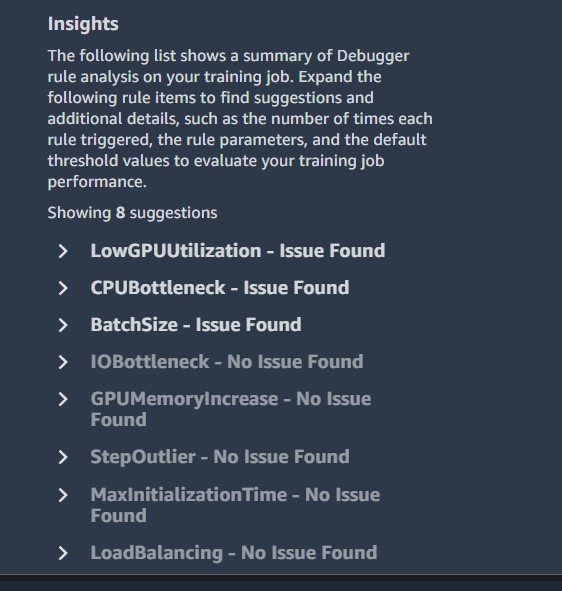
If you choose an insight, you can view the profiler recommendations.
By default, we are showing the overview report, but you could choose Nodes to show the dashboard.
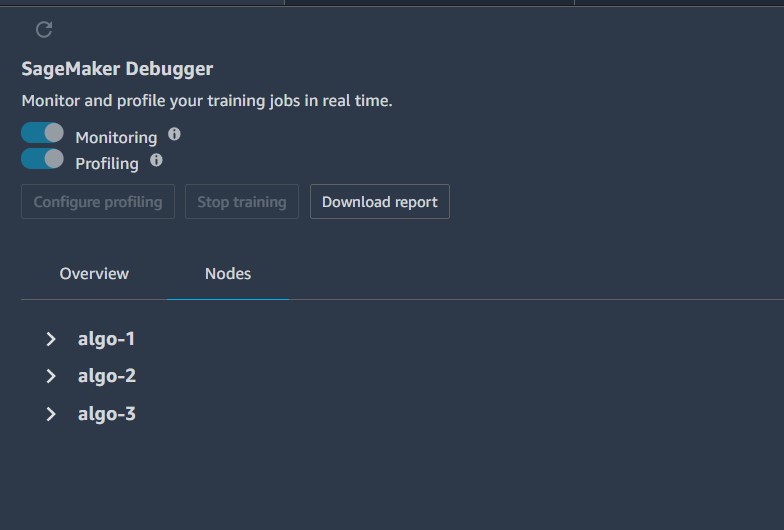
You can expand each algorithm to get deep dive information such as CPU utilization, network utilization, and system metrics per algorithm used during training.
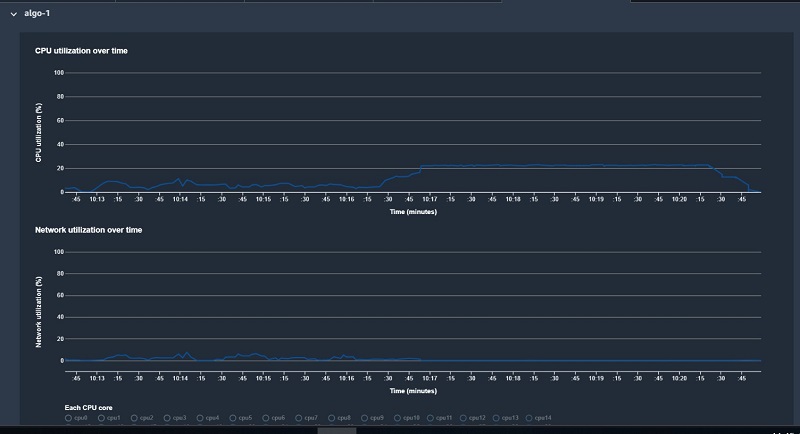
Furthermore, you can scroll down to analyze GPU memory utilization over time and system utilization over time for each algorithm.
Analyzing the profiler report generated by Debugger
Download the profiler report by choosing Download report.
Alternatively, if you’re not using Studio, you can download your report directly from Amazon Simple Storage Service (Amazon S3) at s3://<your bucket> /tf-keras-sentiment-<job id>/profiler-output/.
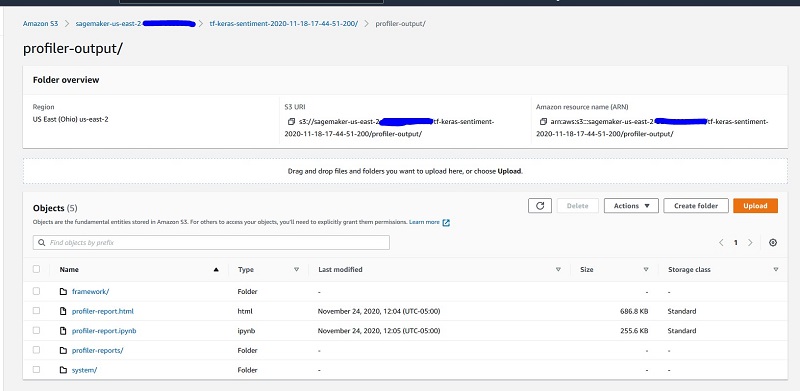
Next, we review a few sections of the generated report. For additional details, see SageMaker Debugger report . You can also use the SMDebug client library for performing data analysis.
Framework metrics summary
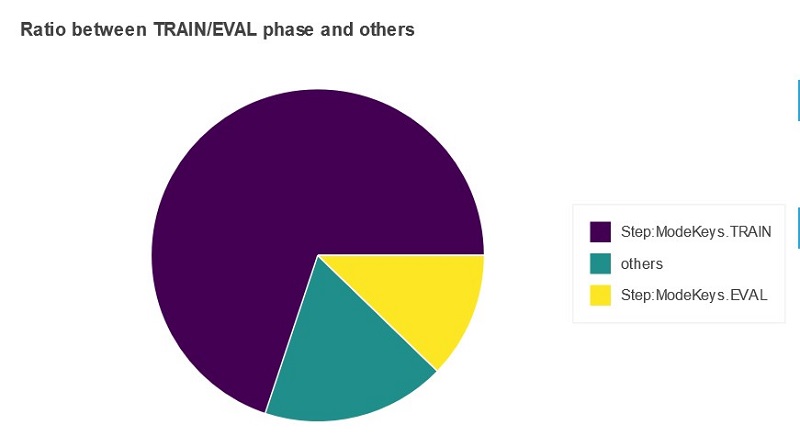
In this section of the report, you see a pie chart that shows the time the training job spent in the training phase, validation phase, or “others.” “Others” represents the accumulated time between steps; that is, the time between when a step has finished but the next step hasn’t started. Ideally, most time should be spent in training steps.
Identifying the most expensive CPU operator
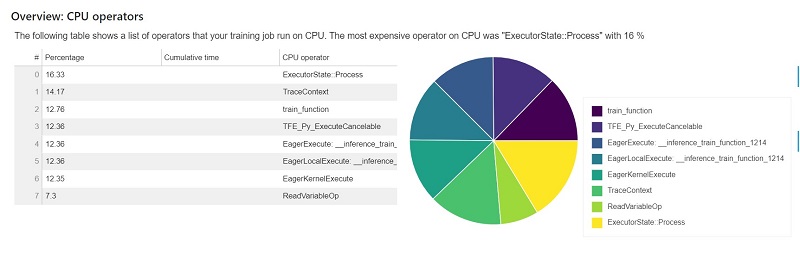
This section provides information of the CPU operators in detail. The table shows the percentage of the time and the absolute cumulative time spent on the most frequently called CPU operators.
The following table shows a list of operators that your training job run on CPU. The most expensive operator on CPU was ExecutorState::Process with 16%.
Identifying the most expensive GPU operator
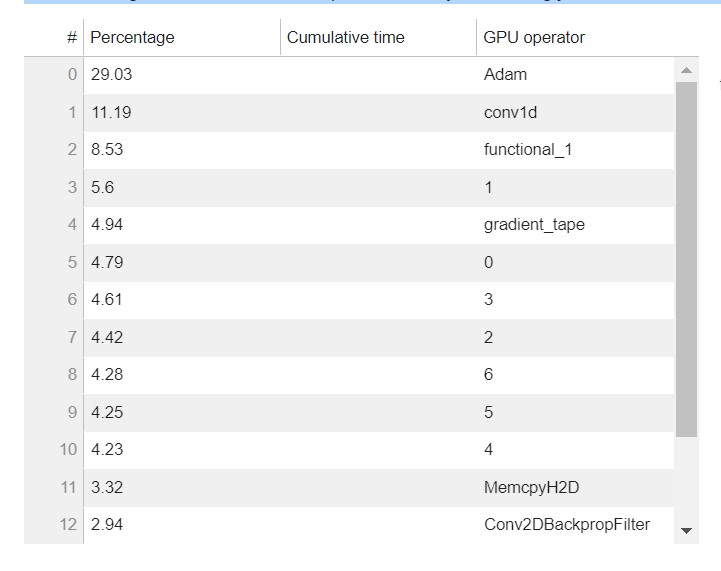
This section provides information of the GPU operators in detail. The table shows the percentage of the time and the absolute cumulative time spent on the most frequently called GPU operators.
The following table shows a list of operators that your training job ran on GPU. The most expensive operator on GPU was Adam with 29%.
Rules summary
In this section, Debugger aggregates all the rule evaluation results, analysis, rule descriptions, and suggestions. The following table shows a summary of the profiler rules that ran. The table is sorted by the rules that triggered most frequently. In the training job, this was the case for rule LowGPUUtilization. It processed 1,001 data points and was triggered 8 times.
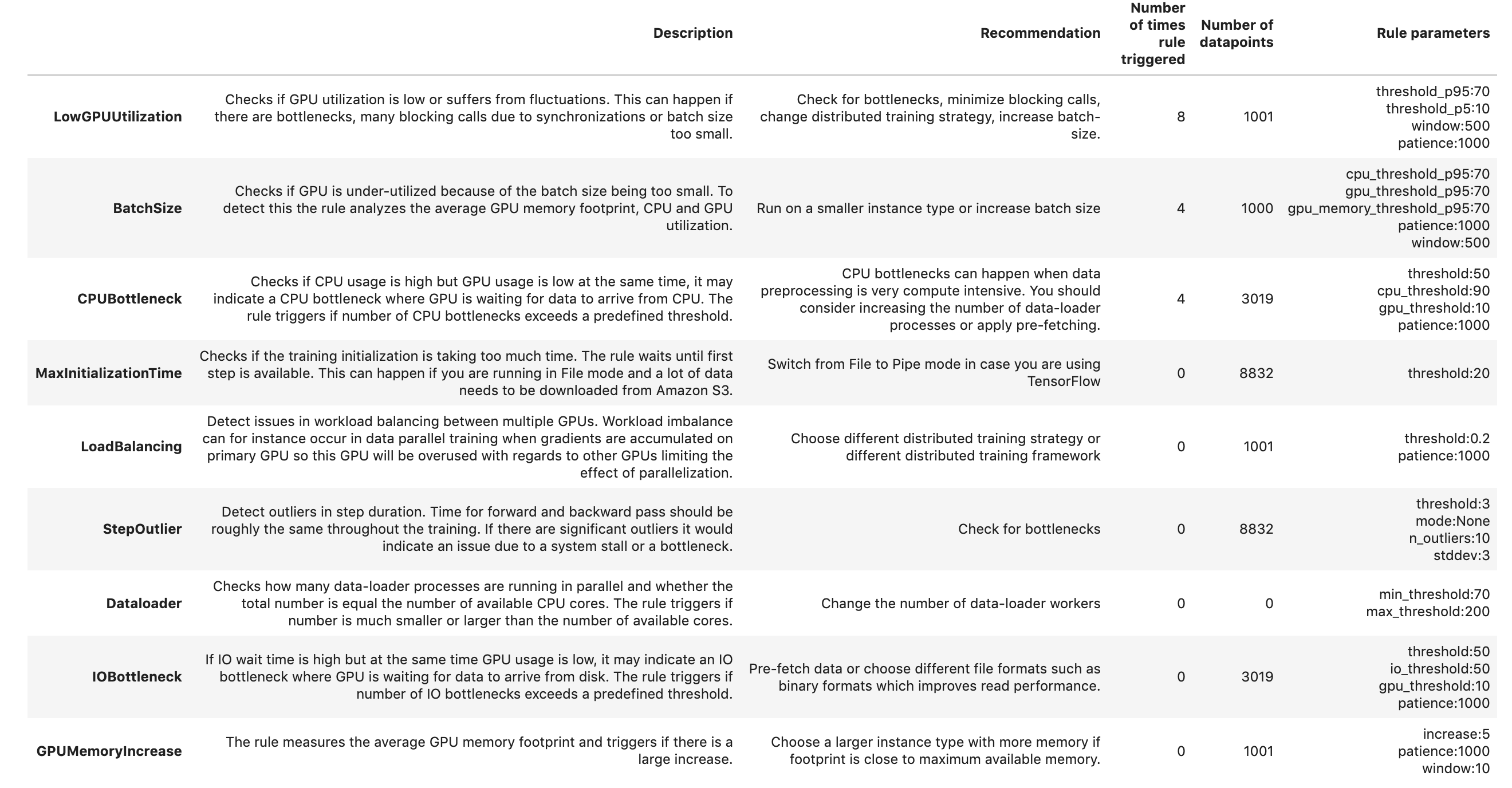
Because the rules were triggered for LowGPUUTilization, Batchsize, and CPUBottleneck, lets deep dive into each to understand the profiler recommendations for each.
LowGPUUtilization
The LowGPUUtilization rule checks for low and fluctuating GPU usage. If usage is consistently low, it might be caused by bottlenecks or if batch size or model is too small. If usage is heavily fluctuating, it can be caused by bottlenecks or blocking calls.
The rule computed the 95th and 5th quantile of GPU utilization on 500 continuous data points and found eight cases where p95 was above 70% and p5 was below 10%. If p95 is high and p5 is low, it indicates that the usage is highly fluctuating. If both values are very low, it means that the machine is under-utilized. During initialization, utilization is likely 0, so the rule skipped the first 1,000 data points. The rule analyzed 1,001 data points and was triggered eight times. Moreover it also provides the time when this rule was last triggered.
BatchSize
The BatchSize rule helps detect if GPU is under-utilized because of the batch size being too small. To detect this, the rule analyzes the GPU memory footprint and CPU and GPU utilization. The rule analyzed 1,000 data points and was triggered four times. Your training job is under-utilizing the instance. You may want to consider switching to a smaller instance type or increasing the batch size of your model training. Moreover it also provides the time when this rule was last triggered.
The following boxplot is a snapshot from this timestamp that shows for each node the total CPU utilization and the utilization and memory usage per GPU.

CPUBottleneck
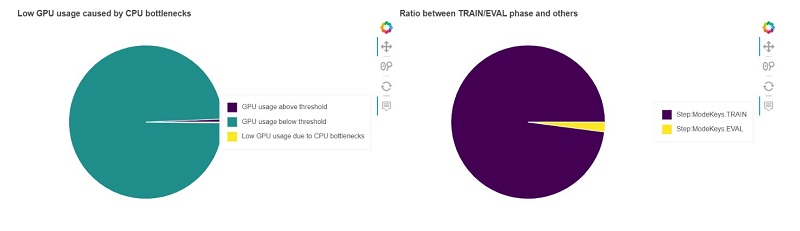
The CPUBottleneck rule checks when CPU utilization was above cpu_threshold of 90% and GPU utilization was below gpu_threshold of 10%. During initialization, utilization is likely 0, so the rule skipped the first 1,000 data points. With this configuration, the rule found 2,129 CPU bottlenecks, which is 70% of the total time. This is above the threshold of 50%. The rule analyzed 3,019 data points and was triggered four times.
The following chart (left) shows how many data points were below the gpu_threshold of 10% and how many of those data points were likely caused by a CPU bottleneck. The rule found 3,000 out of 3,019 data points that had a GPU utilization below 10%. Out of those data points, 70.52% were likely caused by CPU bottlenecks. The second chart (right) shows whether CPU bottlenecks mainly happened during the train or validation phase.
Analyzing and implementing recommendations from the profiler report
Let’s now analyze and implement the profiling recommendations for our training job to improve resource utilization and make our training efficient. First let’s review the configuration of our training job and check the three rules that were triggered by Debugger during the training run.
The following table summarizes the training job configuration.
| Instance Type | Instance Count | Number of processes per host | Profiling Configuration | Number of Epochs | Batch Size |
| P3.8xlarge | 3 | 3 | FrameworkProfile(start_step=2, num_steps=7), Monitoring Interval = 500 milliseconds | 25 | 256 |
The following table summarizes the Debugger profiling recommendations.
| Rule Triggered | Reason | Recommendations |
| BatchSize | Checks if GPU is under-utilized because of the batch size being too small. | Run on a smaller instance type or increase batch size. |
| LowGPUUtilization | Checks if GPU utilization is low or suffers from fluctuations. This can happen if there are bottlenecks, many blocking calls due to synchronizations, or batch size being too small. | Check for bottlenecks, minimize blocking calls, change distributed training strategy, increase batch size. |
|
CPUBottleneck
|
Checks if CPU usage is high but GPU usage is low at the same time, which may indicate a CPU bottleneck where GPU is waiting for data to arrive from CPU. | CPU bottlenecks can happen when data preprocessing is very compute intensive. You should consider increasing the number of data-loader processes or apply pre-fetching. |
Based on the recommendation to consider switching to a smaller instance type and to increase the batch size, we change the training configuration settings and rerun the training. In the notebook, the training instances are changed from p3.8xlarge to p3.2xlarge instances, the number of instances is reduced to two, and only one process per host for MPI is configured to increase the number of data loaders. The batch size is also changed in parallel to 512.
The following table summarizes the revised training job configuration.
| Instance Type | Instance Count | Number of processes per host | Profiling Configuration | Number of Epochs | Batch Size |
| P3.2xlarge | 2 | 1 | FrameworkProfile(start_step=2, num_steps=7), Monitoring Interval = 500 milliseconds | 25 | 512 |
After running the second training job with the new settings, a new report is generated, but with no rules triggered, indicating all the issues identified in the earlier run were resolved. Now let’s compare the report analysis from the two training jobs and understand the impact of the configuration changes made.
The training job summary shows that the training time was almost similar, with 502 seconds in the revised run compared to 503 seconds in the first run. The amount of time spent in the training loop for both jobs was also comparable at 45%.
Examining the system usage statistics shows that both CPU and GPU utilization of the two training instances increased when compared to the original run. For the first training run, GPU utilization was constant at 13.5% across the three instances for the 95th quantile of GPU utilization, and the CPU utilization was constant at 24.4% across the three instances for the 95th quantile of CPU utilization. For the second training run, GPU utilization increased to 46% for the 95th quantile, and the CPU utilization increased to 61% for the 95th quantile.
Although no rules were triggered during this run, there is still room for improvement in resource utilization.
The following screenshot shows the rules summary for our revised training run.

You can continue to tune your training job, change the training parameters, rerun the training, and compare the results against previous training runs. Repeat this process to fine-tune your training strategy and training resources to achieve the optimal combination of training cost and training performance according to your business needs.
Optimizing costs
The following table shows a cost comparison of the two training runs.
| Instance Count | Instance Type | Training Time (in Seconds) |
Instance Hourly Cost (us-west-2) |
Training Cost | Cost Savings | |
| First training run | 3 | p3.8xlarge | 503 | $14.688 | $6.16 | N/A |
| Second training run with Debugger profiling recommendations | 2 | p3.2xlarge | 502 | $3.825 | $1.07 | 82.6% |
Considering the cost of the training instances in a specific Region at the time of the this writing, for example us-west-2, training with three ml.p3.8xlarge instances for 503 seconds costs $6.16, and training with two ml.p3.2xlarge for 502 seconds costs $1.07. That is 83% cost savings by simply implementing the profiler recommendation to reduce the instance type.
Conclusion
The profiling feature of SageMaker Debugger is a powerful tool to gain visibility into ML training jobs. In this post, we provided insight into training resource utilization to identify bottlenecks, analyze the various phases of training, and identify expensive framework functions. We also showed how to analyze and implement profiler recommendations. We applied profiler recommendations to a TensorFlow Horovod distributed training for a sentiment analysis model and achieved resource utilization improvement up to 60% and cost savings of 83%. Debugger provides profiling capabilities for all leading deep learning frameworks, including TensorFlow, PyTorch, and Keras.
Give Debugger profiling a try and leave your feedback in the comments. For additional information on SageMaker Debugger, check out the announcement post linked below.
About the Authors
 Mona Mona is an AI/ML Specialist Solutions Architect based out of Arlington, VA. She works with the World Wide Public Sector team and helps customers adopt machine learning on a large scale. Prior to joining Amazon, she worked as an IT Consultant and completed her masters in Computer Information Systems from Georgia State University, with a focus in big data analytics. She is passionate about NLP and ML explainability in AI/ML.
Mona Mona is an AI/ML Specialist Solutions Architect based out of Arlington, VA. She works with the World Wide Public Sector team and helps customers adopt machine learning on a large scale. Prior to joining Amazon, she worked as an IT Consultant and completed her masters in Computer Information Systems from Georgia State University, with a focus in big data analytics. She is passionate about NLP and ML explainability in AI/ML.
 Prem Ranga is an Enterprise Solutions Architect based out of Houston, Texas. He is part of the Machine Learning Technical Field Community and loves working with customers on their ML and AI journey. Prem is passionate about robotics, is an Autonomous Vehicles researcher, and also built the Alexa-controlled Beer Pours in Houston and other locations.
Prem Ranga is an Enterprise Solutions Architect based out of Houston, Texas. He is part of the Machine Learning Technical Field Community and loves working with customers on their ML and AI journey. Prem is passionate about robotics, is an Autonomous Vehicles researcher, and also built the Alexa-controlled Beer Pours in Houston and other locations.
 Sireesha Muppala is an AI/ML Specialist Solutions Architect at AWS, providing guidance to customers on architecting and implementing machine learning solutions at scale. She received her Ph.D. in Computer Science from the University of Colorado, Colorado Springs. In her spare time, Sireesha loves to run and hike Colorado trails.
Sireesha Muppala is an AI/ML Specialist Solutions Architect at AWS, providing guidance to customers on architecting and implementing machine learning solutions at scale. She received her Ph.D. in Computer Science from the University of Colorado, Colorado Springs. In her spare time, Sireesha loves to run and hike Colorado trails.