Business analysts work with data and like to analyze, explore, and understand data to achieve effective business outcomes. To address business problems, they often rely on machine learning (ML) practitioners such as data scientists to assist with techniques such as utilizing ML to build models using existing data and generate predictions. However, it isn’t always possible, as data scientists are typically tied up with their tasks and don’t have the bandwidth to help the analysts.
To be independent and achieve your goals as a business analyst, it would be ideal to work with easy-to-use, intuitive, and visual tools that use ML without the need to know the details and use code. Using these tools will help you solve your business problems and achieve the desired outcomes.
With a goal to help you and your organization become more effective, and use ML without writing code, we introduced Amazon SageMaker Canvas. This is a no-code ML solution that helps you build accurate ML models without the need to learn about technical details, such as ML algorithms and evaluation metrics. SageMaker Canvas offers a visual, intuitive interface that lets you import data, train ML models, perform model analysis, and generate ML predictions, all without writing a single line of code.
When using SageMaker Canvas to experiment, you may encounter data quality issues such as missing values or having the wrong problem type. These issues may not be discovered until quite late in the process after training a ML model. To alleviate this challenge, SageMaker Canvas now supports data validation. This feature proactively checks for issues in your data and provides guidance on resolutions.
In this post, we’ll demonstrate how you can use the data validation capability within SageMaker Canvas prior to model building. As the name suggests, this feature validates your dataset, reports issues, and provides useful pointers to fix them. By using better quality data, you will end up with a better performing ML model.
Validate data in SageMaker Canvas
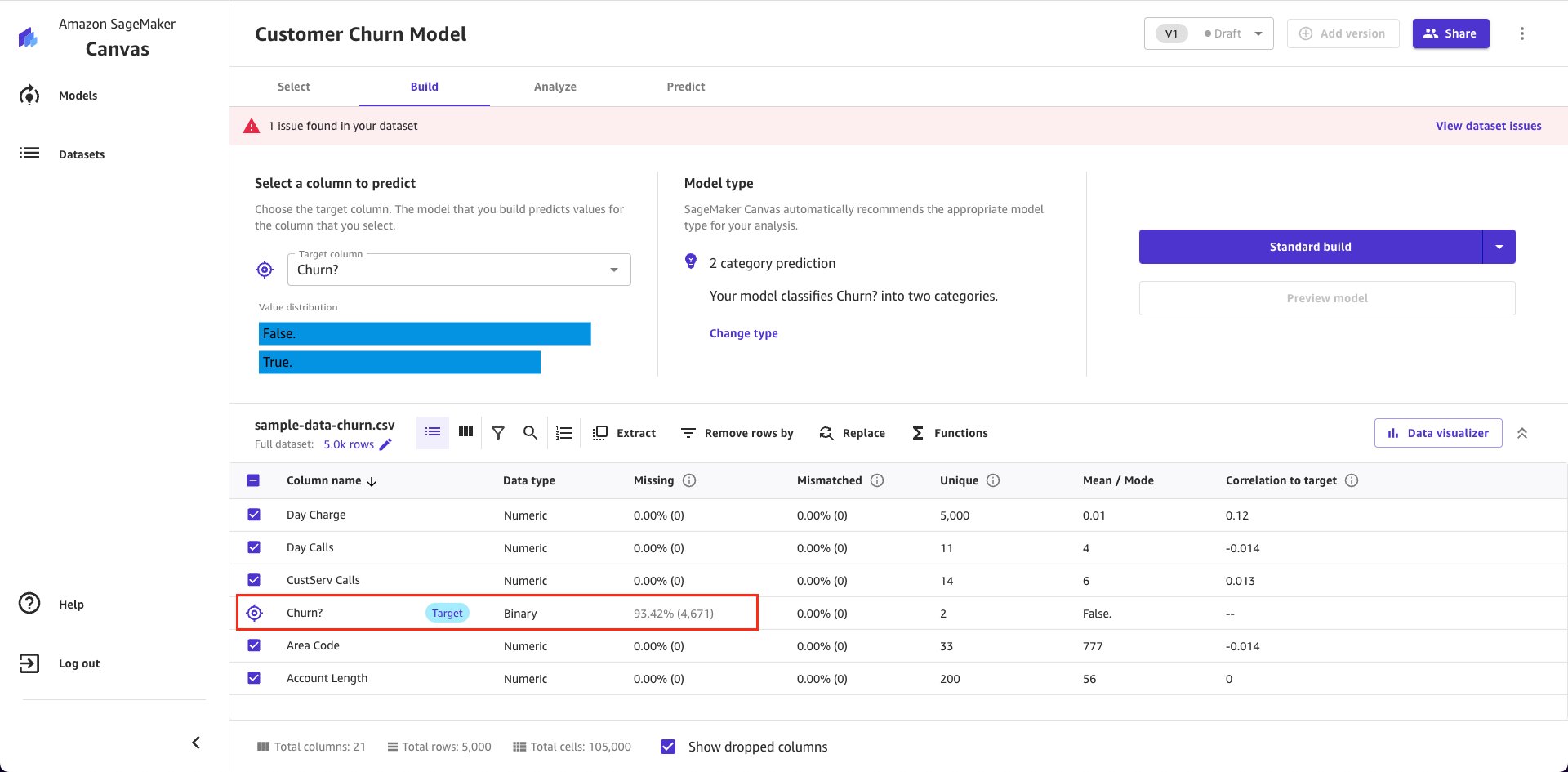
Data Validation is a new feature in SageMaker Canvas to proactively check for potential data quality issues. After you import the data and select a target column, you’re given a choice to validate your data as shown here:
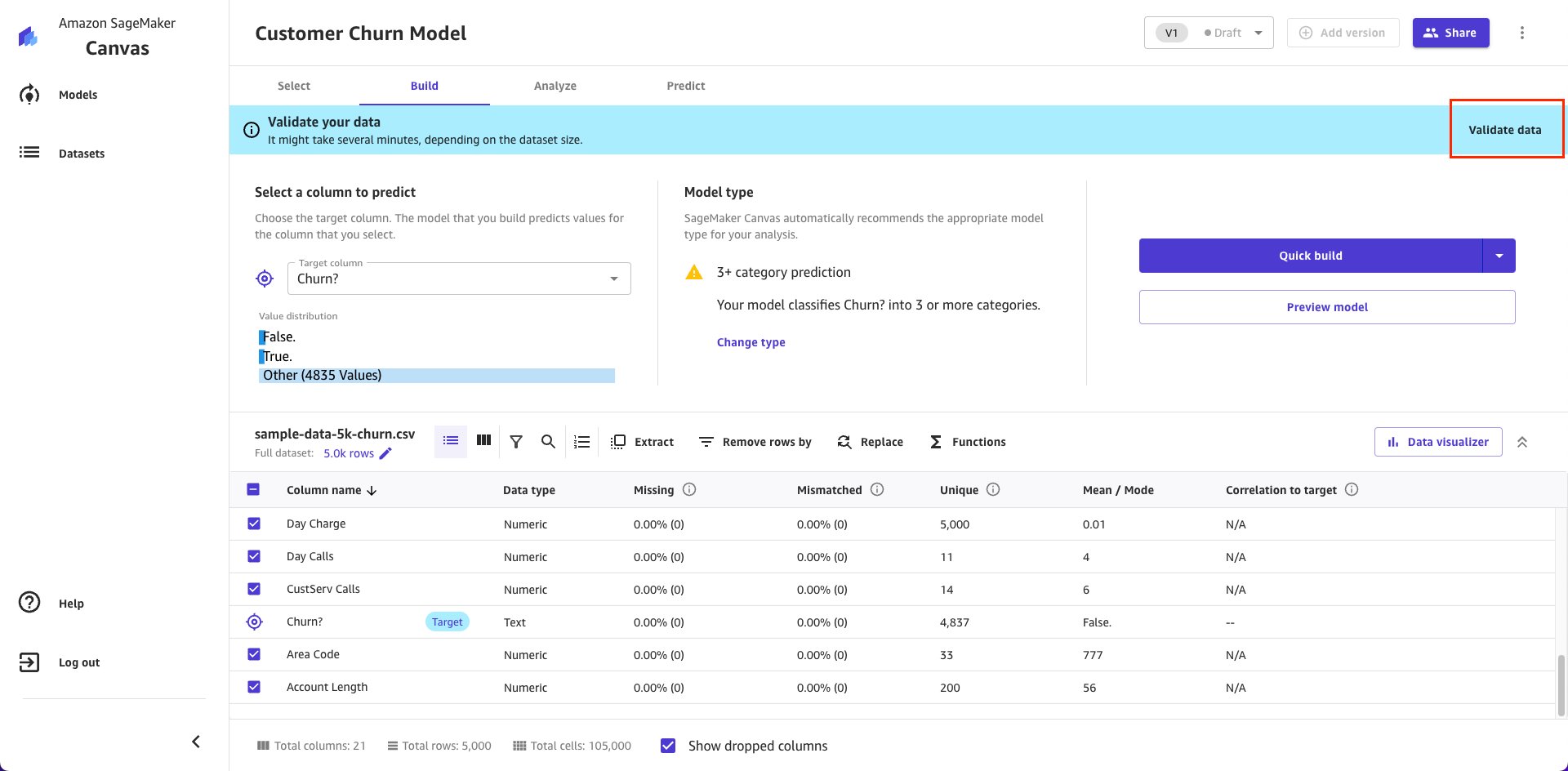
If you choose to validate your data, Canvas analyzes your data for numerous conditions including:
- Too many unique labels in your target column – for the category prediction model type
- Too many unique labels in your target column for the number of rows in your data – for the category prediction model type
- Wrong model type for your data – the model type doesn’t fit the data you’re predicting in the Target column
- Too many invalid rows – missing values in your target column
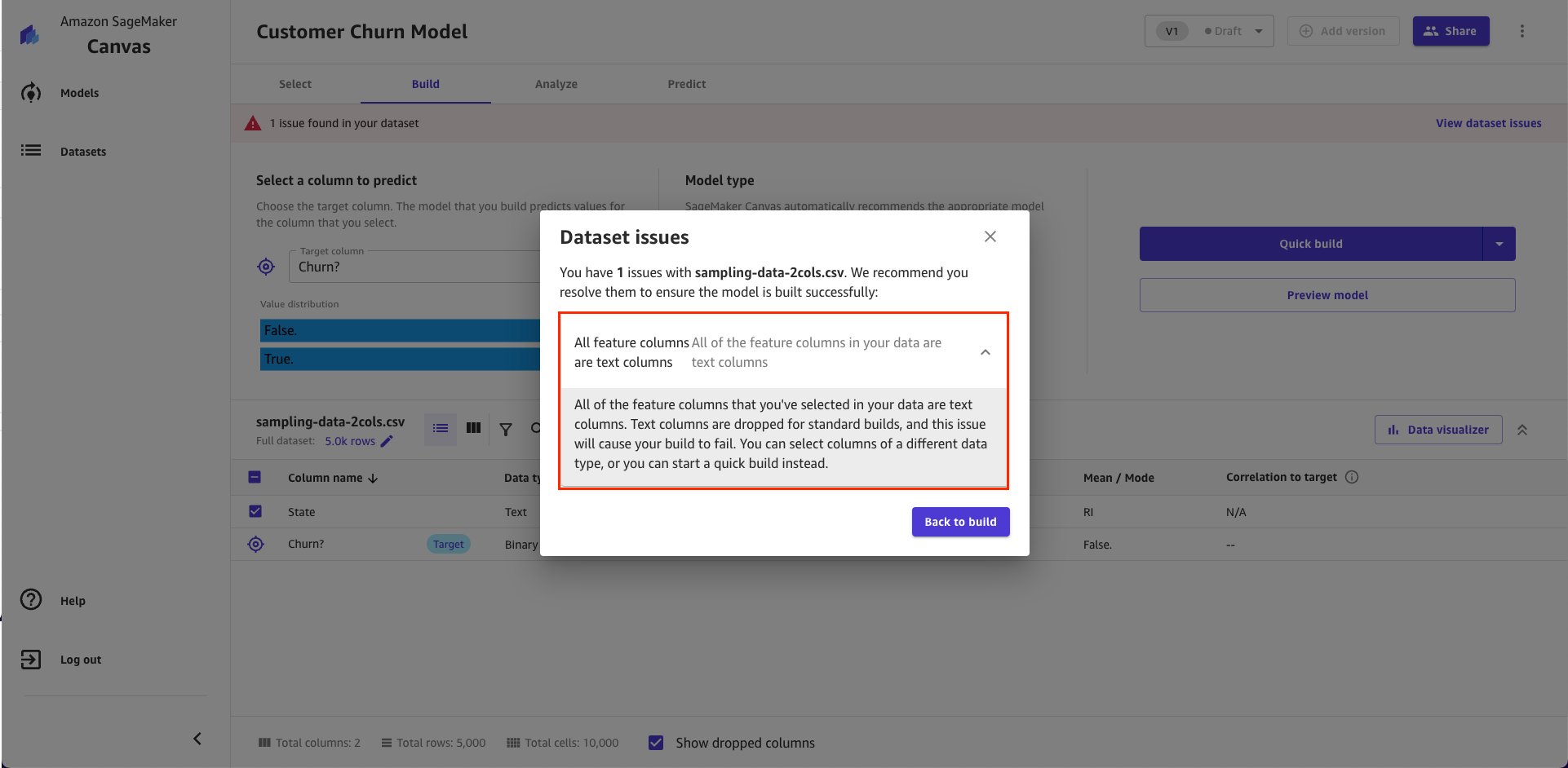
- All feature columns are text columns – they will be dropped for standard builds
- Too few columns – too few columns in your data
- No complete rows – all of the rows in your data contain missing values
- One or more column names contain double underscores – SageMaker can’t handle (__) in the column header
Details for each validation criteria will be provided in the later sections of this post.
If all of the checks are passed, then you’ll get the following confirmation: “No issues have been found in your dataset”.

If any issue is found, you’ll get a notification to view and understand. This surfaces the data quality issues early, and it lets you address them immediately before wasting time and resources further in the process.

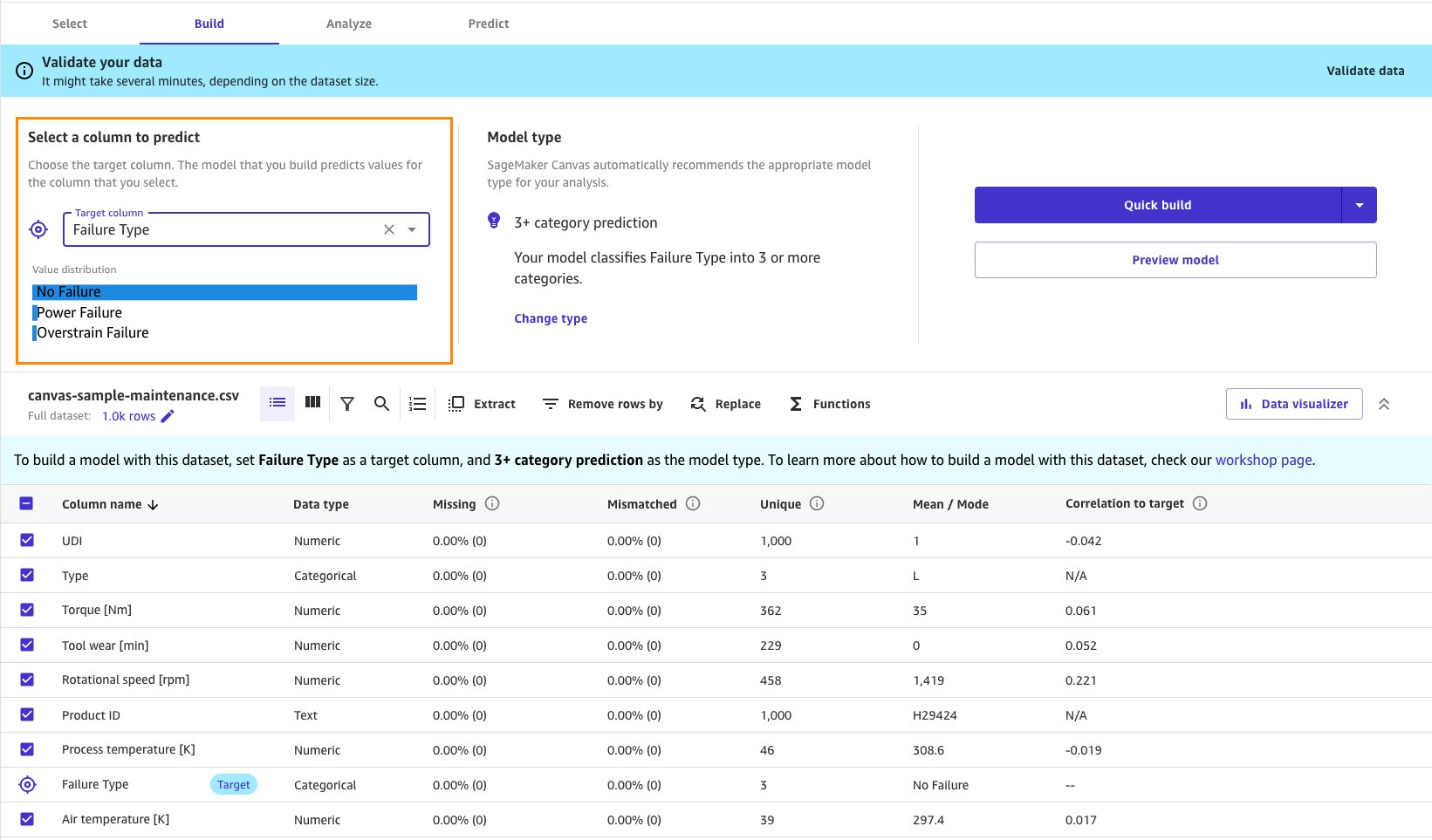
You can make your adjustments and keep validating your dataset until all of the issues are addressed.
Validate target column and model types
When you’re building an ML model in SageMaker Canvas, several data quality issues related to the target column may cause your model build to fail. SageMaker Canvas checks for different kinds of problems that may impact your target column.
- For your target column, check the Wrong model type for your data. For example, if a 2-category prediction model is selected but your target column has more than 2 unique labels, then SageMaker Canvas will provide the following validation warning.

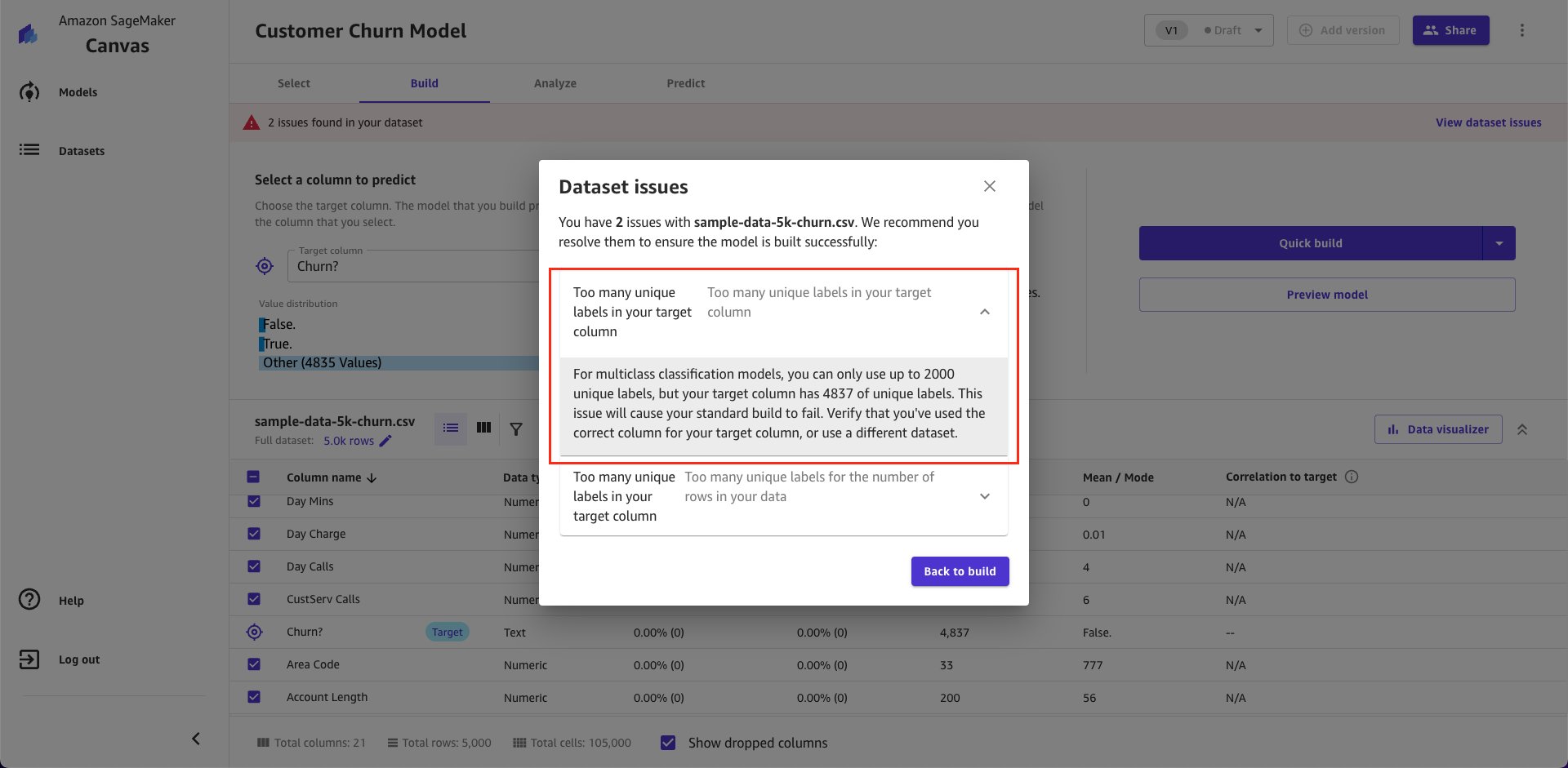
- If the model type is 2 or 3+ category prediction, then you must validate too many unique labels for your target column. The maximum number of unique classes is 2000. If you select a column with more than 2000 unique values in your Target column, then Canvas will provide the following validation warning.
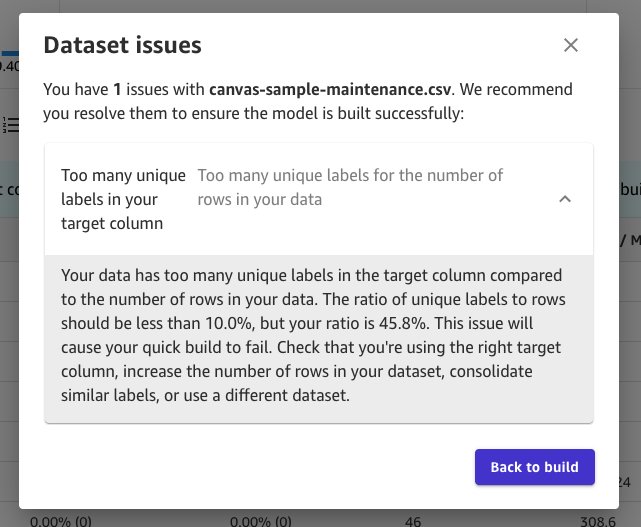
- In addition to too many unique target labels, you should also beware of too many unique target labels for the number of rows in your data. SageMaker Canvas enforces a ratio of target label to the number of total rows to be less than 10%. This makes sure you have enough representation for each category for a high quality model and reduce the potential for overfitting. Your model is considered overfitting when it predicts well on the training data but not on new data it hasn’t seen before. Refer here to learn more.

- Finally, the last check for the target column is too many invalid rows. If your target column has more than 10% of the data missing or invalid, then it will impact your model performance, and in some cases cause your model build to fail. The following example has many missing values (>90% missing) in the target column, and you get the following validation warning.
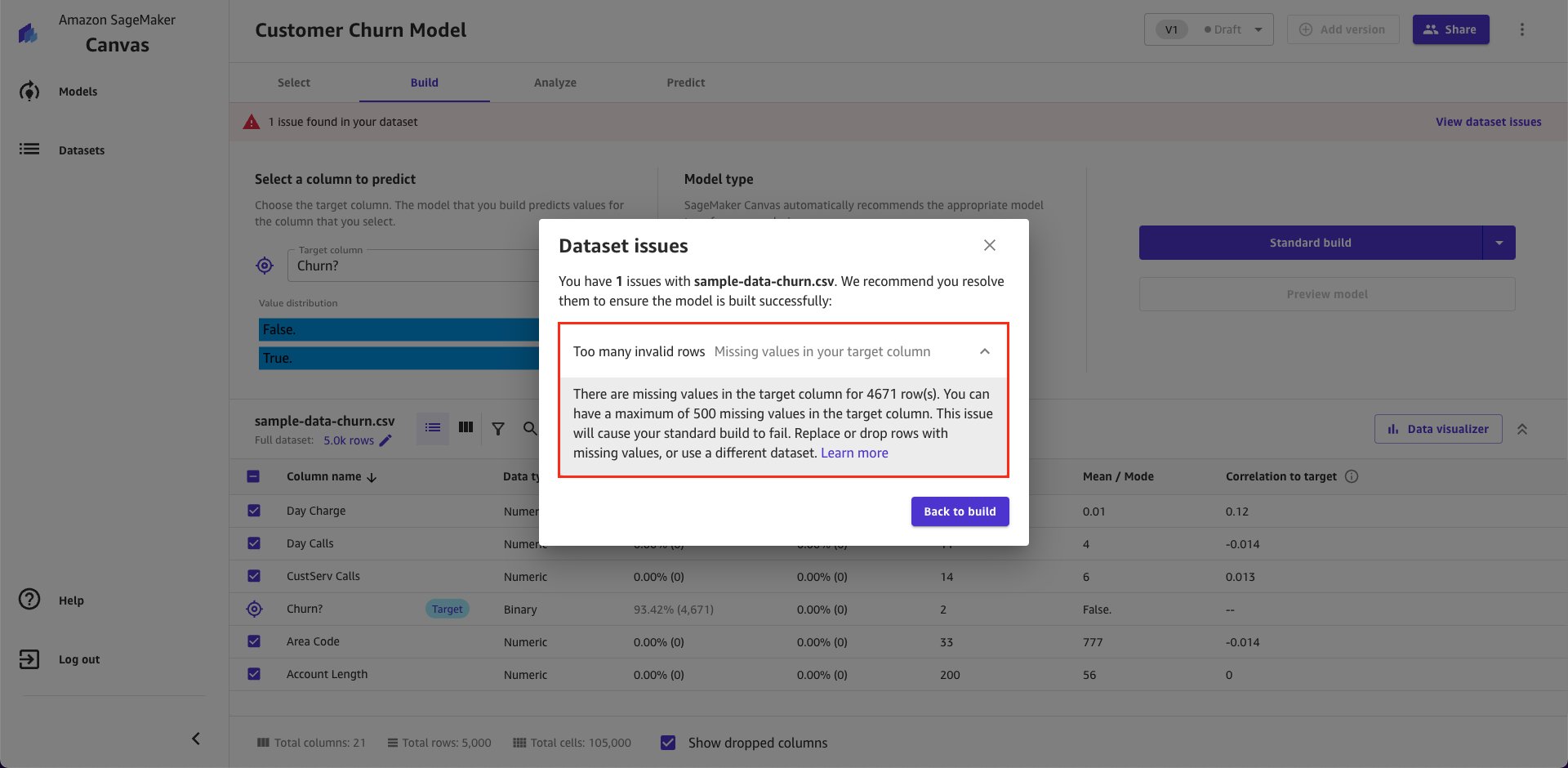
If you get any of the above warnings for your target column, then use the following steps to mitigate the issues:
- Are you using the right target column?
- Did you select the correct model type?
- Can you increase the number of rows in your dataset per target label?
- Can you consolidate/group similar labels together?
- Can you fill-in the missing/invalid values?
- Do you have enough data that you can drop the missing/invalid values?
- If all of the above options aren’t clearing the warning, then you should consider using a different dataset.
Refer to the SageMaker Canvas data transformation documentation to perform the imputation steps mentioned above.
Validate all columns
Aside from the target column, you may run into data quality issues with other data columns (feature columns) as well. Features columns are input data used to make an ML prediction.
- Every dataset should have at least 1 feature column and 1 target column (2 columns in total). Otherwise, SageMaker Canvas will give you a Too few columns in your data warning. You must satisfy this requirement before you can proceed with building a model.
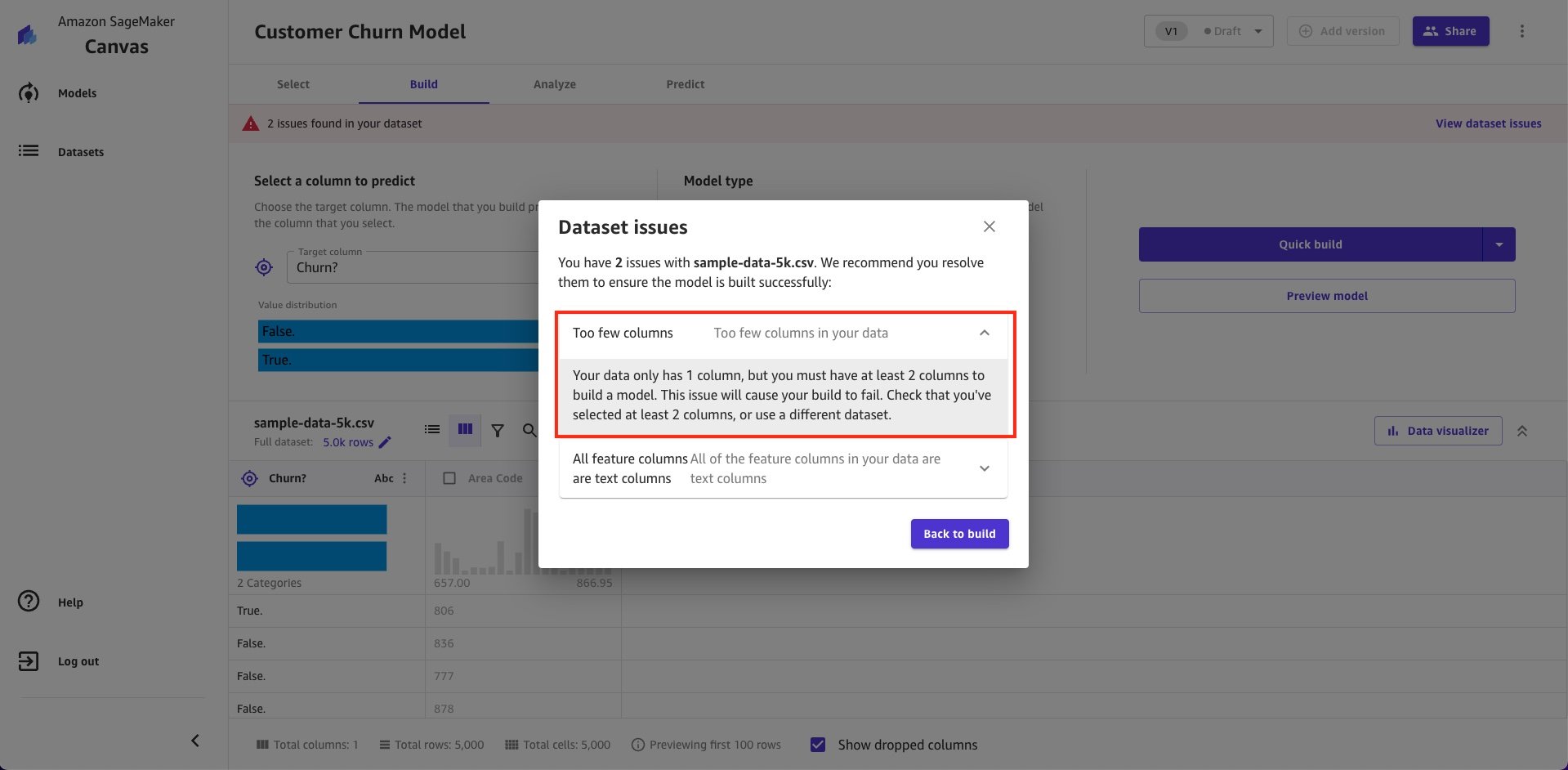
- After that, you must make sure that your data has at-least 1 numeric column. If not, then you’ll get the all feature columns are text columns warning. This is because text columns are usually dropped during standard builds, thereby leaving the model with no features to train. Therefore, this will cause your model building to fail. You can use SageMaker Canvas to encode some of the text columns to numbers or use quick build instead of standard build.
- The third type of warning you may get for feature columns is No complete rows. This validation checks if you have at least one row with no missing values. SageMaker Canvas requires at least one complete row, otherwise your quick build will fail. Try to fill in the missing values before building the model.

- The last type of validation is One or more column names contain double underscores. This is a SageMaker Canvas specific requirement. If you have double underscores (__) in your column headers, then this will cause your quick build to fail. Rename the columns to remove any double underscores, and then try again.

Clean up
To avoid incurring future session charges, log out of SageMaker Canvas.

Conclusion
SageMaker Canvas is a no-code ML solution that allows business analysts to create accurate ML models and generate predictions through a visual, point-and-click interface. We showed you how SageMaker Canvas helps you to make sure of data quality and mitigate data issues by proactively validating the dataset. By identifying the issues early, SageMaker Canvas helps you build quality ML models and reduce build iterations without expertise in data science and programming. To learn more about this new feature, refer to the SageMaker Canvas documentation.
To get started and learn more about SageMaker Canvas, refer to the following resources:
- Amazon SageMaker Canvas
- Product documentation
- Enable intelligent decision-making with Amazon SageMaker Canvas and Amazon QuickSight
- Predict types of machine failures with no-code machine learning using Amazon SageMaker Canvas
About the authors
 Hariharan Suresh is a Senior Solutions Architect at AWS. He is passionate about databases, machine learning, and designing innovative solutions. Prior to joining AWS, Hariharan was a product architect, core banking implementation specialist, and developer, and worked with BFSI organizations for over 11 years. Outside of technology, he enjoys paragliding and cycling.
Hariharan Suresh is a Senior Solutions Architect at AWS. He is passionate about databases, machine learning, and designing innovative solutions. Prior to joining AWS, Hariharan was a product architect, core banking implementation specialist, and developer, and worked with BFSI organizations for over 11 years. Outside of technology, he enjoys paragliding and cycling.
 Sainath Miriyala is a Senior Technical Account Manager at AWS working for automotive customers in the US. Sainath is passionate about designing and building large-scale distributed applications using AI/ML. In his spare time Sainath spends time with family and friends.
Sainath Miriyala is a Senior Technical Account Manager at AWS working for automotive customers in the US. Sainath is passionate about designing and building large-scale distributed applications using AI/ML. In his spare time Sainath spends time with family and friends.
 James Wu is a Senior AI/ML Specialist Solution Architect at AWS. helping customers design and build AI/ML solutions. James’s work covers a wide range of ML use cases, with a primary interest in computer vision, deep learning, and scaling ML across the enterprise. Prior to joining AWS, James was an architect, developer, and technology leader for over 10 years, including 6 years in engineering and 4 years in marketing & advertising industries.
James Wu is a Senior AI/ML Specialist Solution Architect at AWS. helping customers design and build AI/ML solutions. James’s work covers a wide range of ML use cases, with a primary interest in computer vision, deep learning, and scaling ML across the enterprise. Prior to joining AWS, James was an architect, developer, and technology leader for over 10 years, including 6 years in engineering and 4 years in marketing & advertising industries.