For modern companies that deal with enormous volumes of documents such as contracts, invoices, resumes, and reports, efficiently processing and retrieving pertinent data is critical to maintaining a competitive edge. However, traditional methods of storing and searching for documents can be time-consuming and often result in a large effort to find a specific document, especially when they include handwriting. What if there was a way to process documents intelligently and make them searchable in with high accuracy?
This is made possible with Amazon Textract, AWS’s Intelligent Document Processing service, coupled with the fast search capabilities of OpenSearch. In this post, we’ll take you on a journey to rapidly build and deploy a document search indexing solution that helps your organization to better harness and extract insights from documents.
Whether you’re in Human Resources looking for specific clauses in employee contracts, or a financial analyst sifting through a mountain of invoices to extract payment data, this solution is tailored to empower you to access the information you need with unprecedented speed and accuracy.
With the proposed solution, your documents are automatically ingested, their content parsed and subsequently indexed into a highly responsive and scalable OpenSearch index.
We’ll cover how technologies such as Amazon Textract, AWS Lambda, Amazon Simple Storage Service (Amazon S3), and Amazon OpenSearch Service can be integrated into a workflow that seamlessly processes documents. Then we dive into indexing this data into OpenSearch and demonstrate the search capabilities that become available at your fingertips.
Whether your organization is taking the first steps into the digital transformation era or is an established giant seeking to turbocharge information retrieval, this guide is your compass to navigating the opportunities that AWS Intelligent Document Processing and OpenSearch offer.
The implementation used in this post utilizes the Amazon Textract IDP CDK constructs – AWS Cloud Development Kit (CDK) components to define infrastructure for Intelligent Document Processing (IDP) workflows – which allow you to build use case specific customizable IDP workflows. The IDP CDK constructs and samples are a collection of components to enable definition of IDP processes on AWS and published to GitHub. The main concepts used are the AWS Cloud Development Kit (CDK) constructs, the actual CDK stacks and AWS Step Functions. The workshop Use machine learning to automate and process documents at scale is a good starting point to learn more about customizing workflows and using the other sample workflows as a base for your own.
Solution overview
In this solution, we focus on indexing documents into an OpenSearch index for quick search-and-retrieval of information and documents. Documents in PDF, TIFF, JPEG or PNG format are put in an Amazon Simple Storage Service (Amazon S3) bucket and subsequently indexed into OpenSearch using this Step Functions workflow.
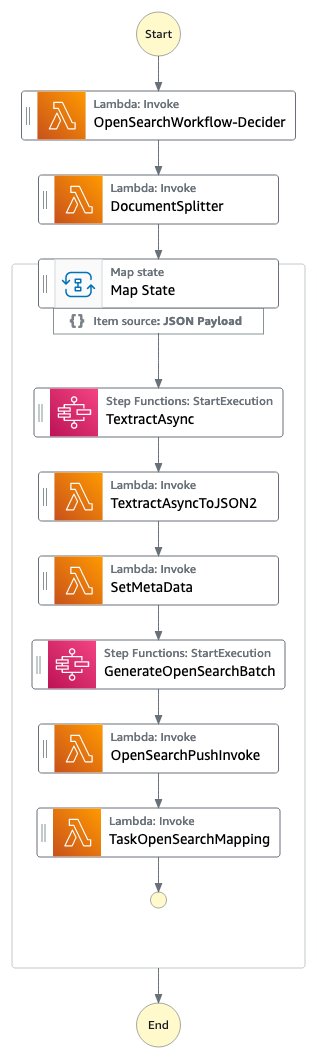
Figure 1: The Step Functions OpenSearch workflow
The OpenSearchWorkflow-Decider looks at the document and verifies that the document is one of the supported mime types (PDF, TIFF, PNG or JPEG). It consists of one AWS Lambda function.
The DocumentSplitter generates maximum of 2500-pages chunk from documents. This means even though Amazon Textract supports documents of up to 3000 pages, you can pass in documents with many more pages and the process still works fine and puts the pages into OpenSearch and creates correct page numbers. The DocumentSplitter is implemented as an AWS Lambda function.
The Map State processes each chunk in parallel.
The TextractAsync task calls Amazon Textract using the asynchronous Application Programming Interface (API) following best practices with Amazon Simple Notification Service (Amazon SNS) notifications and OutputConfig to store the Amazon Textract JSON output to a customer Amazon S3 bucket. It consists of two Amazon Lambda functions: one to submit the document for processing and one getting triggered on the Amazon SNS notification.
Because the TextractAsync task can produce multiple paginated output files, the TextractAsyncToJSON2 process combines them into one JSON file.
The Step Functions context is enriched with information that should also be searchable in the OpenSearch index in the SetMetaData step. The sample implementation adds ORIGIN_FILE_NAME, START_PAGE_NUMBER, and ORIGIN_FILE_URI. You can add any information to enrich the search experience, like information from other backend systems, specific IDs or classification information.
The GenerateOpenSearchBatch takes the generated Amazon Textract output JSON, combines it with the information from the context set by SetMetaData and prepares a file that is optimized for batch import into OpenSearch.
In the OpenSearchPushInvoke, this batch import file is sent into the OpenSearch index and available for search. This AWS Lambda function is connected with the aws-lambda-opensearch construct from the AWS Solutions library using the m6g.large.search instances, OpenSearch version 2.7, and configured the Amazon Elastic Block Service (Amazon EBS) volume size to General Purpose 2 (GP2) with 200 GB. You can change the OpenSearch configuration according to your requirements.
The final TaskOpenSearchMapping step clears the context, which otherwise could exceed the Step Functions Quota of Maximum input or output size for a task, state, or execution.
Prerequisites
To deploy the samples, you need an AWS account , the AWS Cloud Development Kit (AWS CDK), a current Python version and Docker are required. You need permissions to deploy AWS CloudFormation templates, push to the Amazon Elastic Container Registry (Amazon ECR), create Amazon Identity and Access Management (AWS IAM) roles, Amazon Lambda functions, Amazon S3 buckets, Amazon Step Functions, Amazon OpenSearch cluster, and an Amazon Cognito user pool. Make sure your AWS CLI environment is setup with the according permissions.
You can also spin up a AWS Cloud9 instance with AWS CDK, Python and Docker pre-installed to initiate the deployment.
Walkthrough
Deployment
- After you set up the prerequisites, you need to first clone the repository:
- Then cd into the repository folder and install the dependencies:
- Deploy the OpenSearchWorkflow stack:
The deployment takes around 25 minutes with the default configuration settings from the GitHub samples, and creates a Step Functions workflow, which is invoked when a document is put at an Amazon S3 bucket/prefix and subsequently is processed till the content of the document is indexed in an OpenSearch cluster.
The following is a sample output including useful links and information generated fromcdk deploy OpenSearchWorkflowcommand:
This information is also available in the AWS CloudFormation Console.
When a new document is placed under the OpenSearchWorkflow.DocumentUploadLocation, a new Step Functions workflow is started for this document.
To check the status of this document, the OpenSearchWorkflow.StepFunctionFlowLink provides a link to the list of StepFunction executions in the AWS Management Console, displaying the status of the document processing for each document uploaded to Amazon S3. The tutorial Viewing and debugging executions on the Step Functions console provides an overview of the components and views in the AWS Console.
Testing
- First test using a sample file.
- After selecting the link to the StepFunction workflow or open the AWS Management Console and going to the Step Functions service page, you can look at the different workflow invocations.
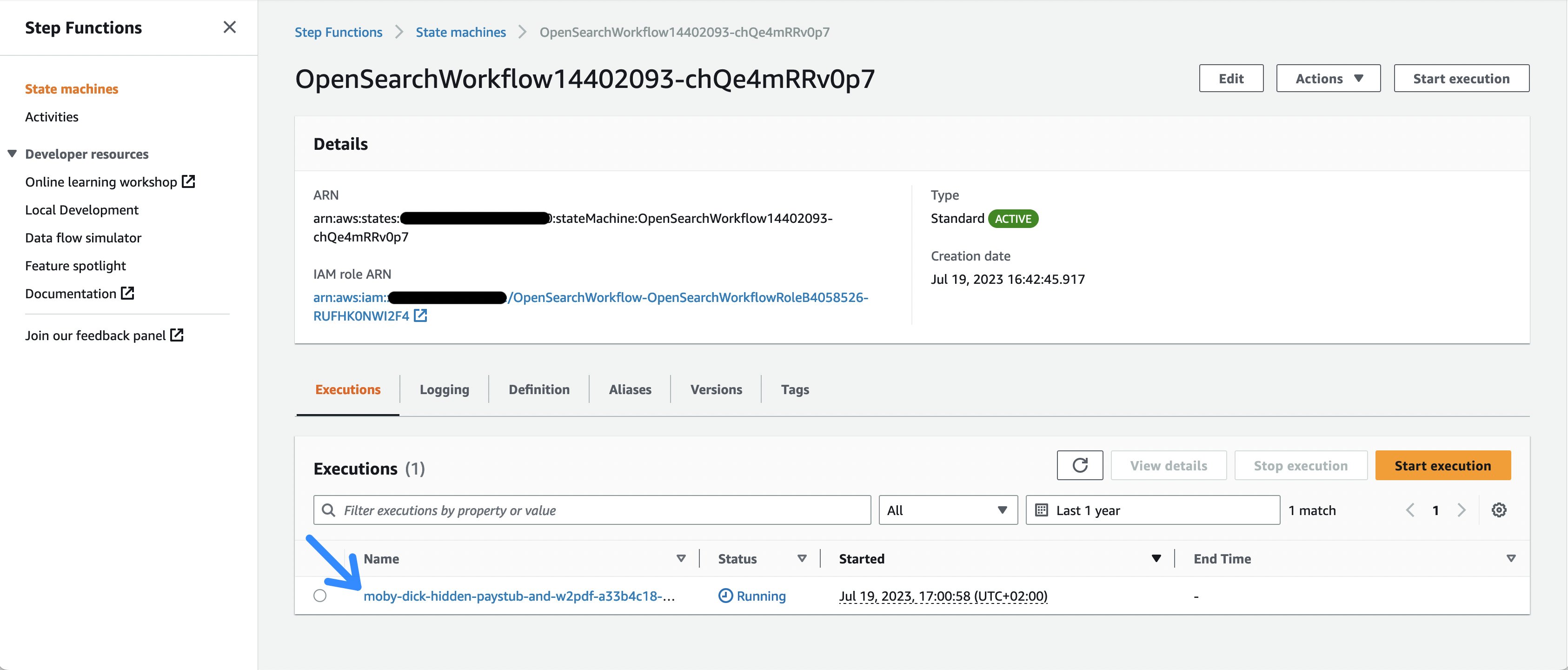
Figure 2: The Step Functions executions list
- Take a look at the currently running sample document execution, where you can follow the execution of the individual workflow tasks.
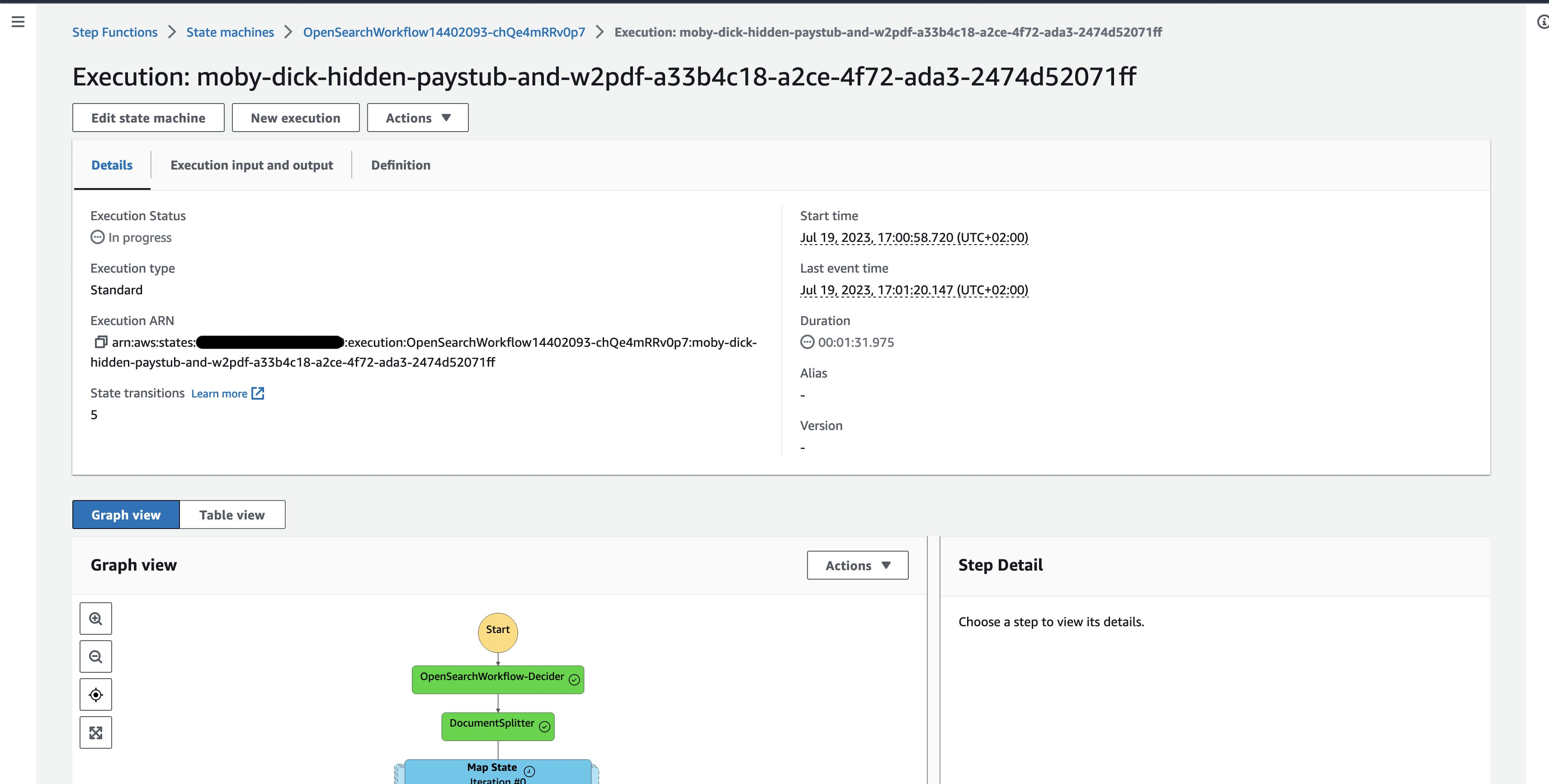
Figure 3: One document Step Functions workflow execution
Search
Once the process finished, we can validate that the document is indexed in the OpenSearch index.
- To do so, first we create an Amazon Cognito user. Amazon Cognito is used for Authentication of users against the OpenSearch index. Select the link in the output from the cdk deploy (or look at the AWS CloudFormation output in the AWS Management Console) named OpenSearchWorkflow.CognitoUserPoolLink.
Figure 4: The Cognito user pool
- Next, select the Create user button, which directs you to a page to enter a username and a password for accessing the OpenSearch Dashboard.
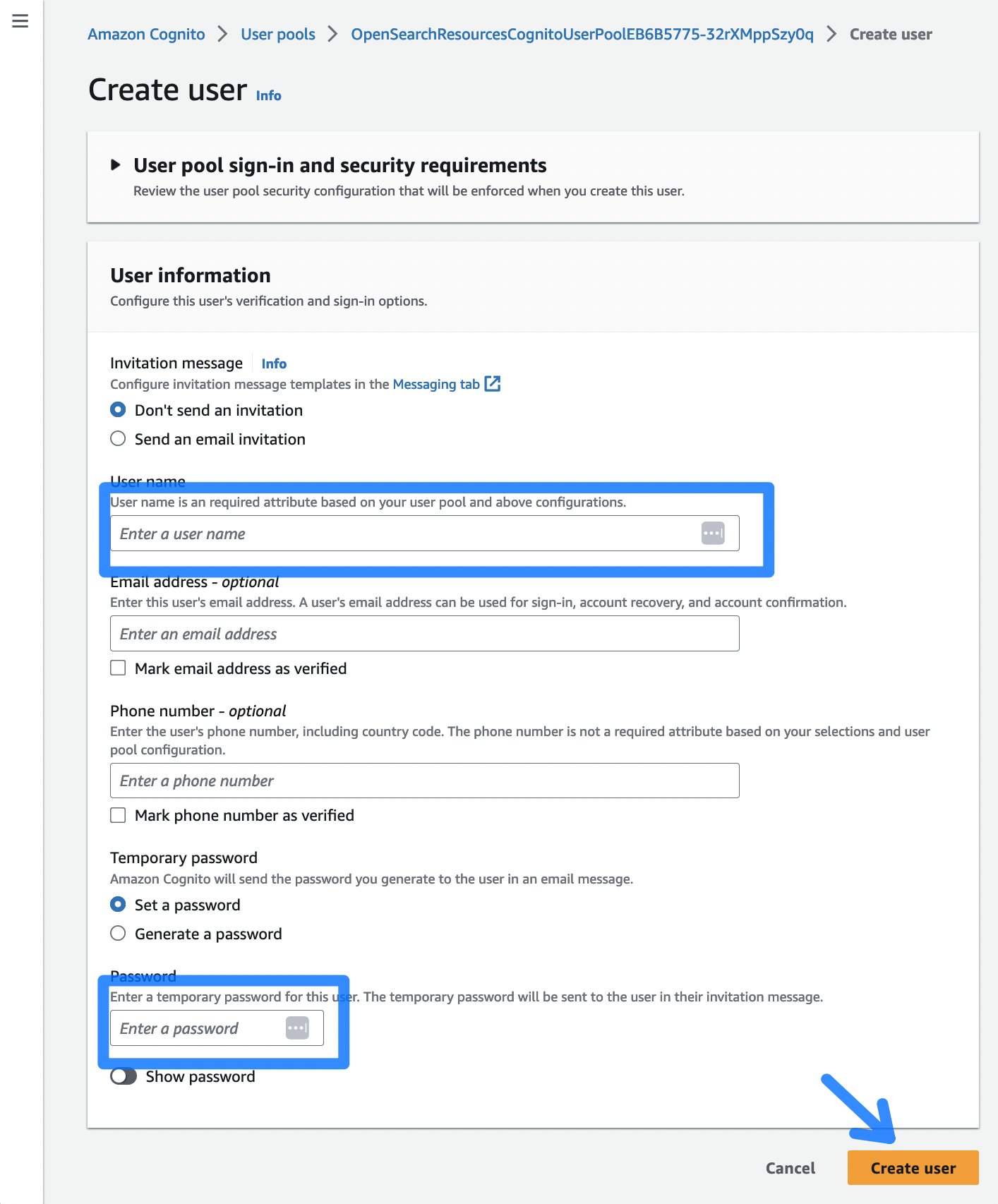
Figure 5: The Cognito create user dialog
- After choosing Create user, you can continue to the OpenSearch Dashboard by clicking on the OpenSearchWorkflow.OpenSearchDashboard from the CDK deployment output. Login using the previously created username and password. The first time you login, you have to change the password.
- Once being logged in to the OpenSearch Dashboard, select the Stack Management section, followed by Index Patterns to create a search index.
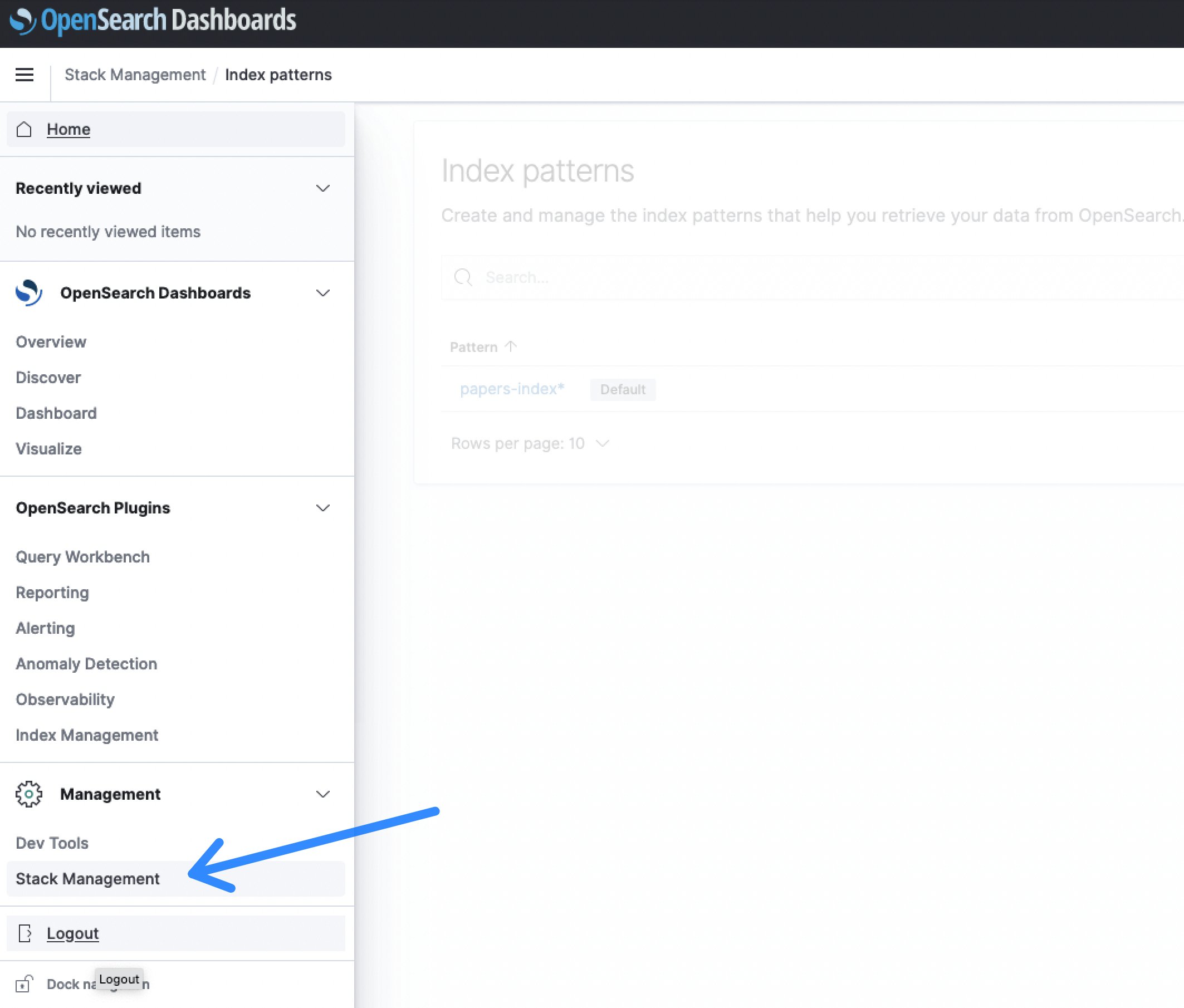
Figure 6: OpenSearch Dashboards Stack Management
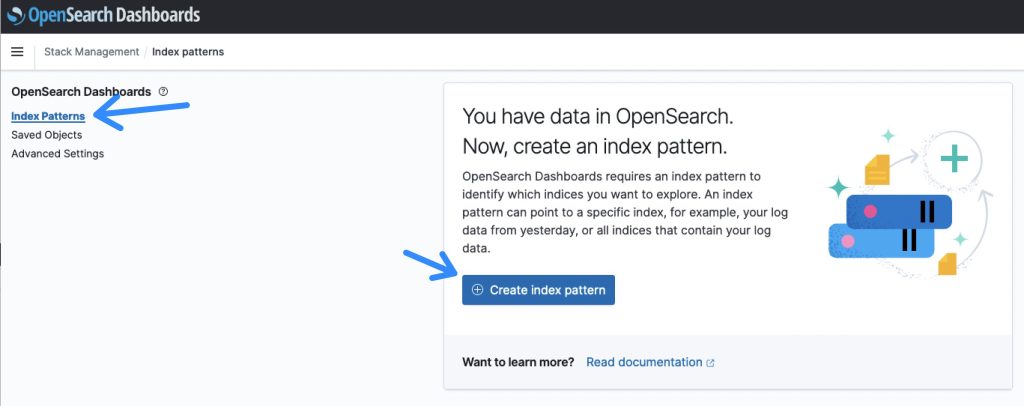
Figure 7: OpenSearch Index Patterns overview
- The default name for the index is papers-index and an index pattern name of papers-index* will match that.
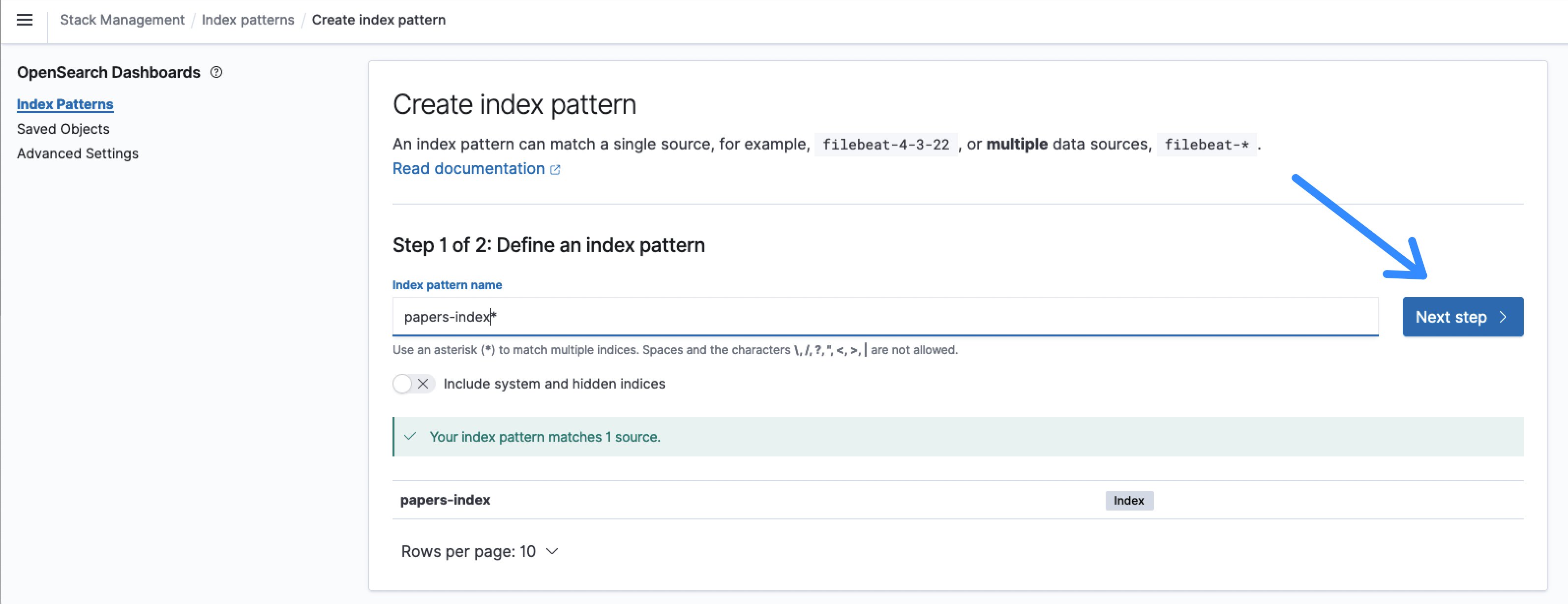
Figure 8: Define the OpenSearch index pattern
- After clicking Next step, select timestamp as the Time field and Create index pattern.
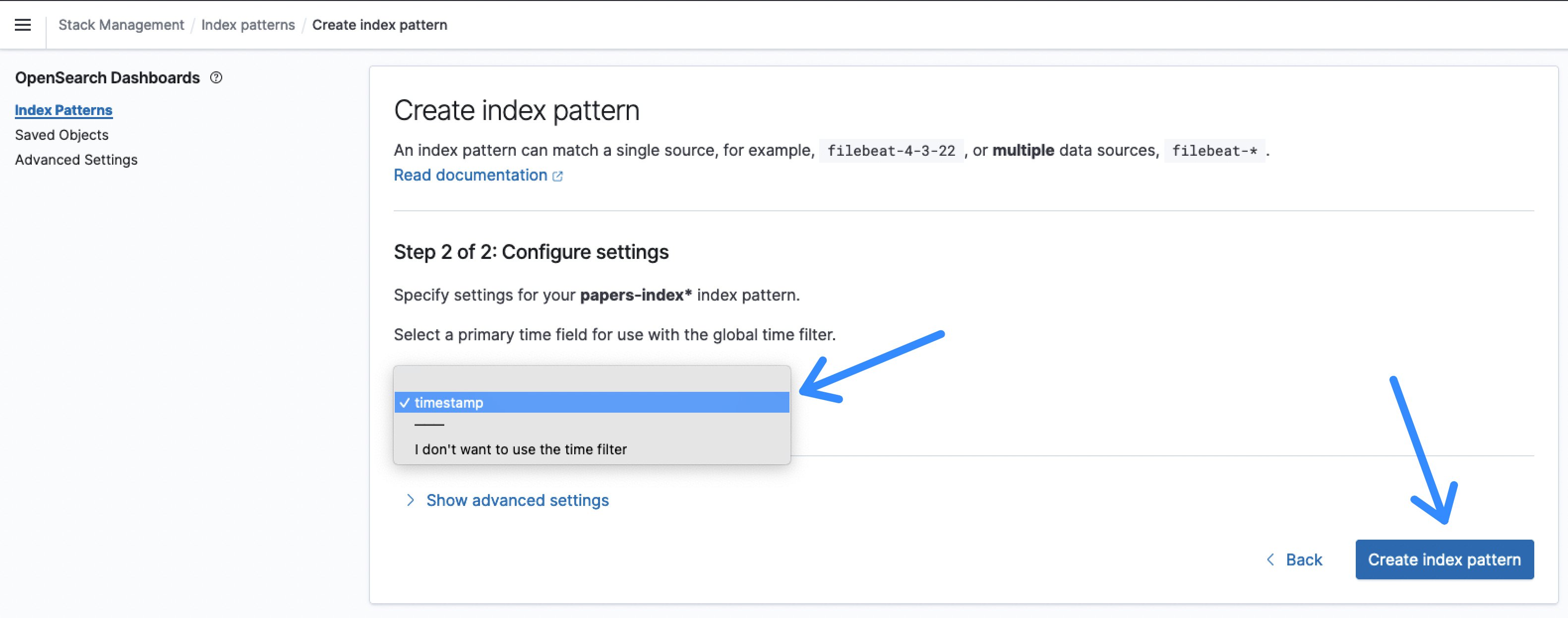
Figure 9: OpenSearch index pattern time field
- Now, from the menu, select Discover.
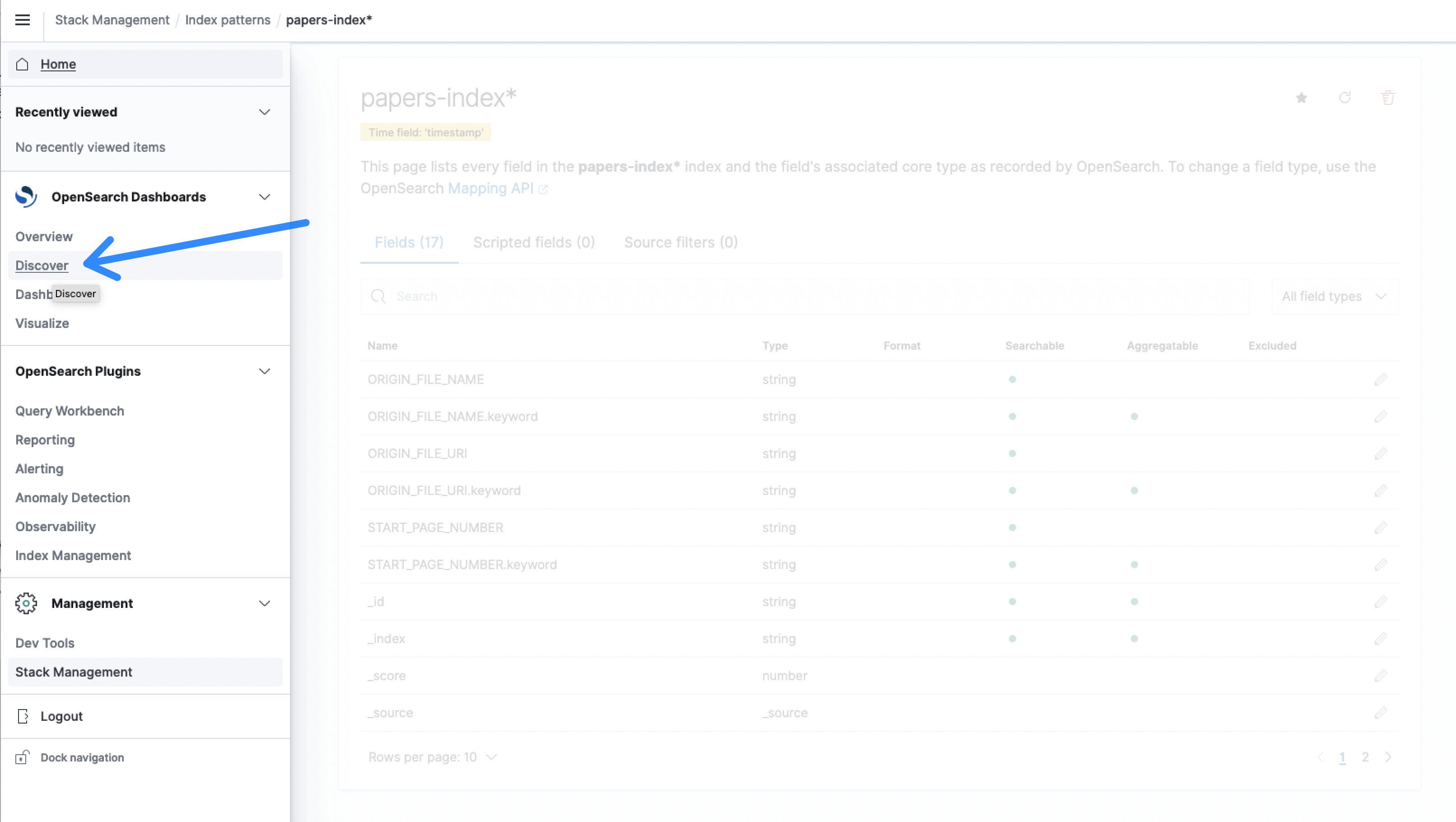
Figure 10: OpenSearch Discover
In most cases ,you need to change the time-span according to your last ingest. The default is 15 minutes and often there was no activity in the last 15 minutes. In this example, it changed to 15 days to visualize the ingest.
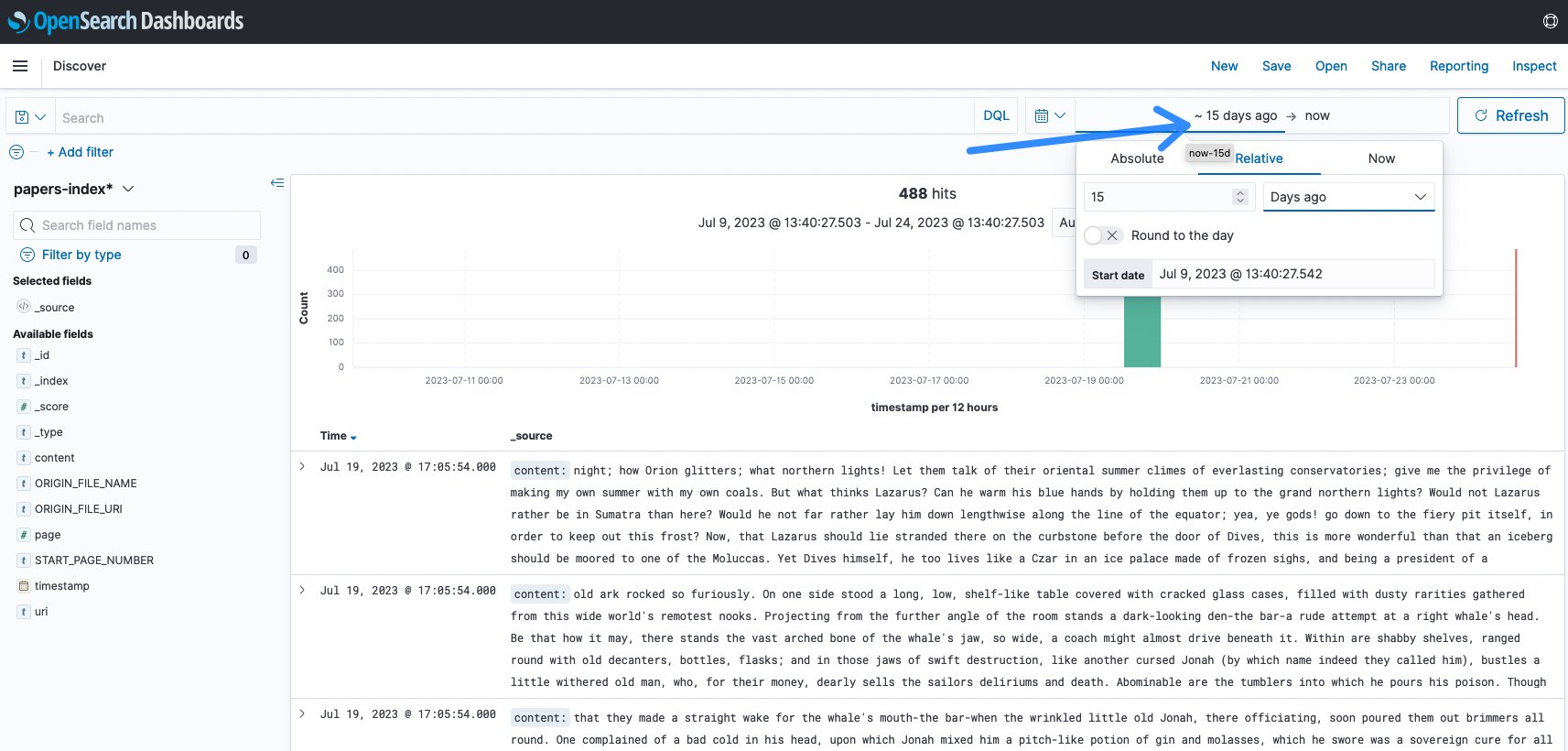
Figure 11: OpenSearch timespan change
- Now you can start to search. A novel was indexed, you can search for any terms like call me Ishmael and see the results.
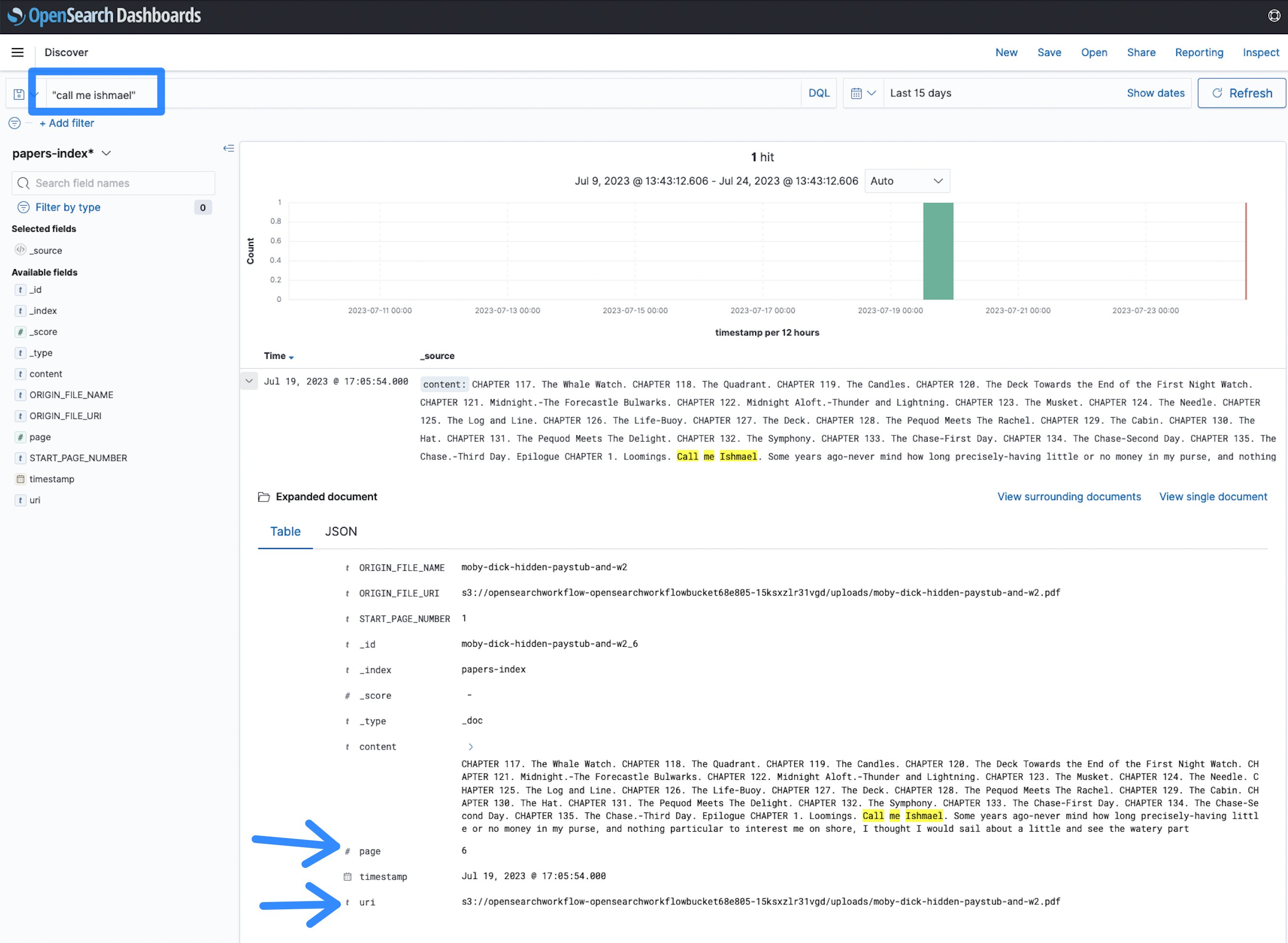
Figure 12: OpenSearch search term
In this case, the term call me Ishmael appears on page 6 of the document at the given Uniform Resource Identifier (URI), which points to the Amazon S3 location of the file. This makes it faster to identify documents and find information across a large corpus of PDF, TIFF or image documents, compared to manually skipping through them.
Running at scale
In order to estimate scale and duration of an indexing process, the implementation was tested with 93,997 documents and a total sum of 1,583,197 pages (average 16.84 pages/document and the largest file having 3755 pages), which all got indexed into OpenSearch. Processing all files and indexing them into OpenSearch took 5.5 hours in the US East (N. Virginia – us-east-1) region using default Amazon Textract Service Quotas. The graph below shows an initial test at 18:00 followed by the main ingest at 21:00 and all done by 2:30.
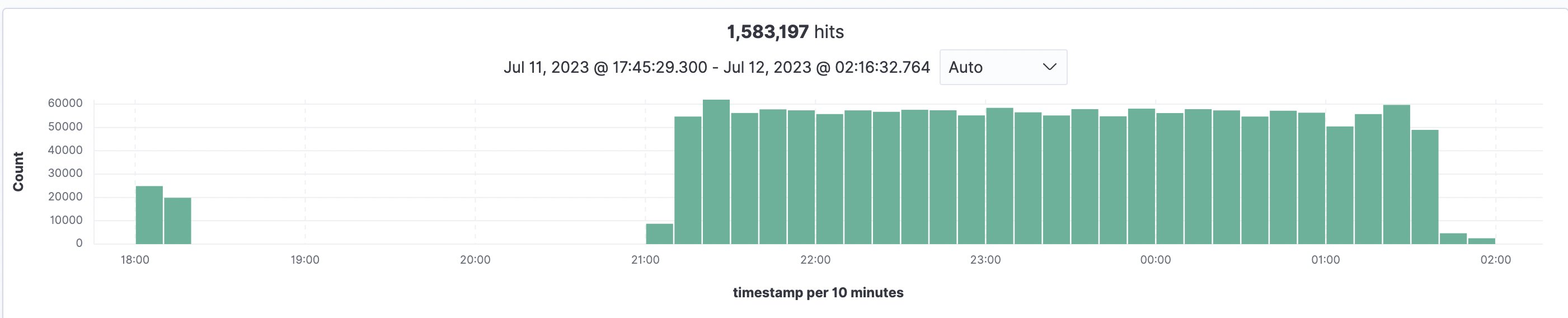
Figure 13: OpenSearch indexing overview
For the processing, the tcdk.SFExecutionsStartThrottle was set to an executions_concurrency_threshold=550, which means that concurrent document processing workflows are capped at 550 and excess requests are queued to an Amazon SQS Fist-In-First-Out (FIFO) queue, which is subsequently drained when current workflows finish. The threshold of 550 is based on the Textract Service quota of 600 in the us-east-1 region. Therefore, the queue depth and age of oldest message are metrics worth monitoring.
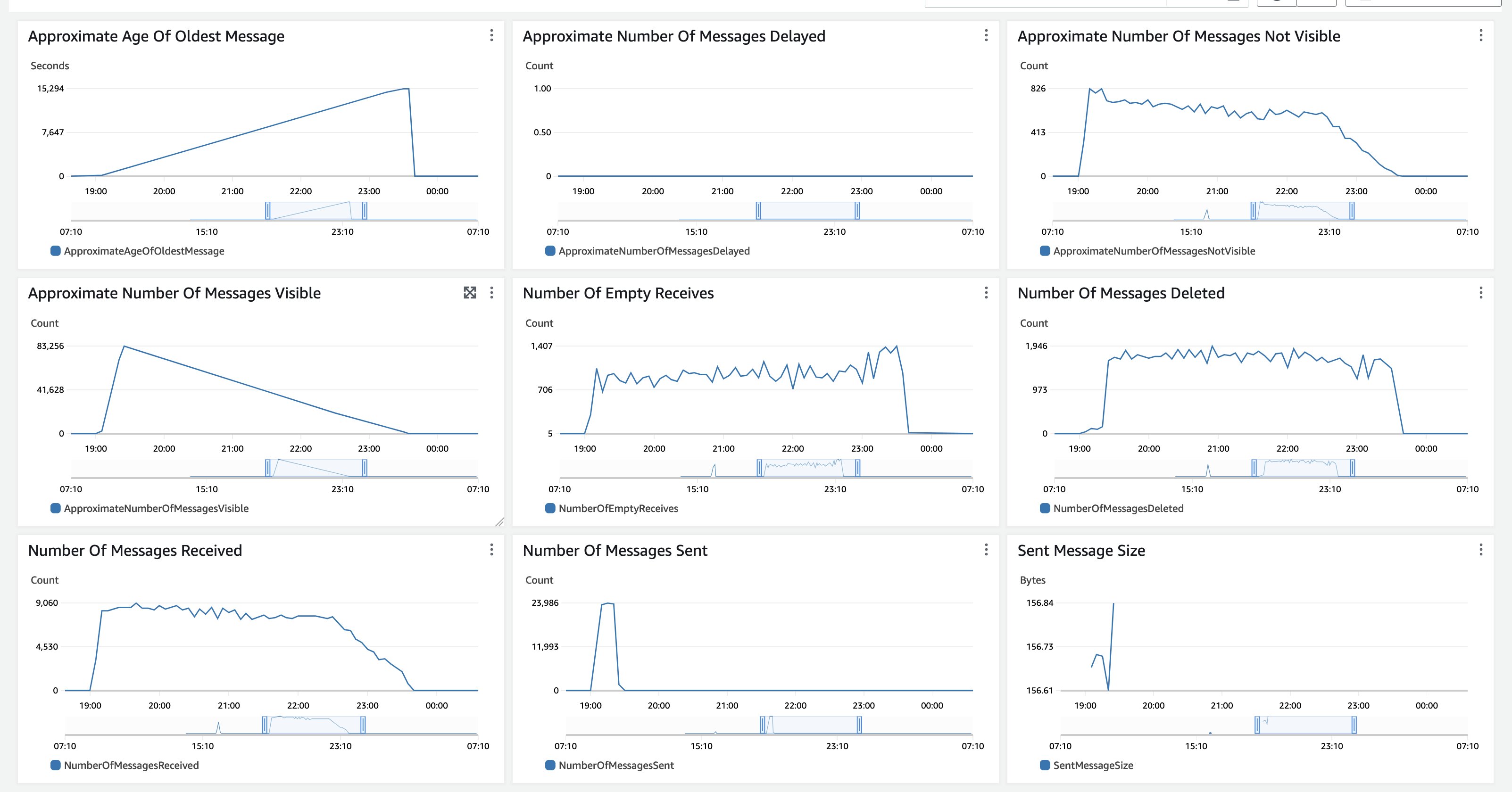
Figure 14: Amazon SQS monitoring
In this test, all documents were uploaded to Amazon S3 at once, therefore the Approximate Number of Messages Visible has a steep increase and then a slow decline as no new documents are ingested. The Approximate Age Of Oldest Message increases until all messages are processed. The Amazon SQS MessageRetentionPeriod is set to 14 days. For very long running backlog processing that could exceed 14 days processing, start with processing a smaller subset of representative documents and monitor the duration of execution to estimate how many documents you can pass in before exceeding 14 days. The Amazon SQS CloudWatch metrics look similar for a use case of processing a large backlog of documents, which is ingested at once then processed fully. If your use case is a steady flow of documents, both metrics, the Approximate Number of Messages Visible and the Approximate Age Of Oldest Message will be more linear. You can also use the threshold parameter to mix a steady load with backlog processing and allocate capacity according to your processing needs.
Another metrics to monitor is the health of the OpenSearch cluster, which you should setup according to the Opernational best practices for Amazon OpenSearch Service. The default deployment uses m6g.large.search instances.
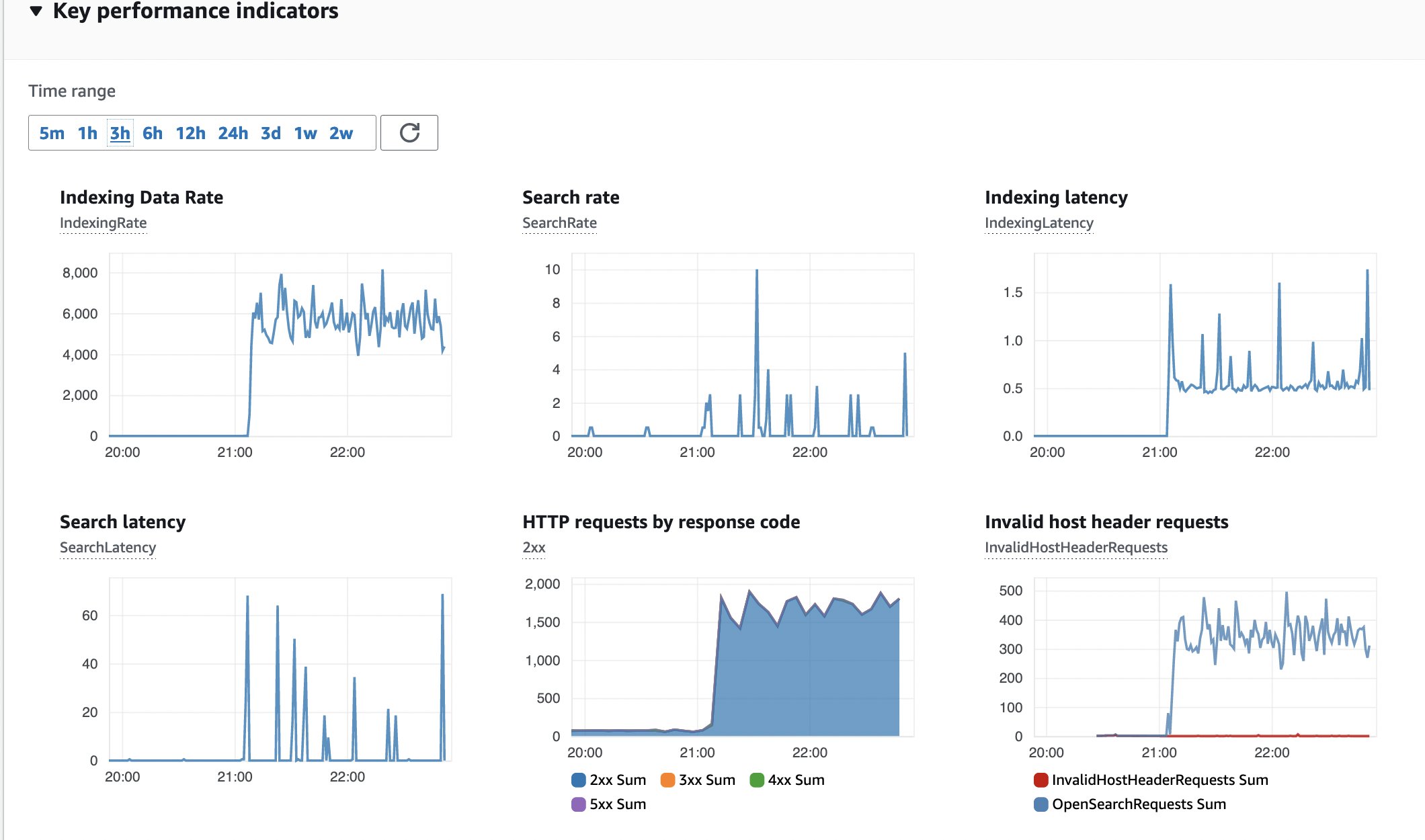
Figure 15: OpenSearch monitoring
Here is a snapshot of the Key Performance Indicators (KPI) for the OpenSearch cluster. No errors, constant indexing data rate and latency.
The Step Functions workflow executions show the state of processing for each individual document. If you see executions in Failed state, then select the details. A good metric to monitor is the AWS CloudWatch Automatic Dashboard for Step Functions, which exposes some of the Step Functions CloudWatch metrics.
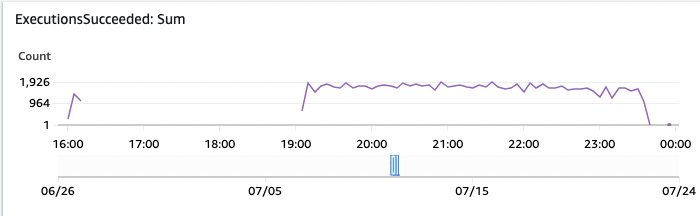
Figure 16: Step Functions monitoring executions succeeded
In this AWS CloudWatch Dashboard graph, you see the successful Step Functions executions over time.
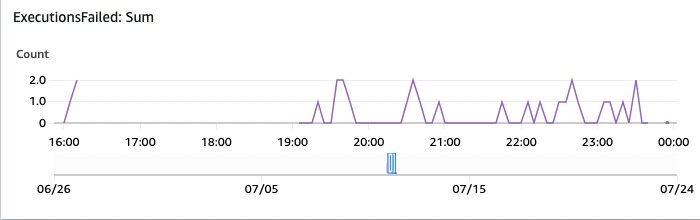
Figure 17: OpenSearch monitoring executions failed
And this one shows the failed executions. These are worth investigating through the AWS Console Step Functions overview.
The following screenshot shows one example of a failed execution due to the origin file being of 0 size, which makes sense because the file has no content and could not be processed. It is important to filter failed processes and visualizes failures, in order for you to go back to the source document and validate the root cause.
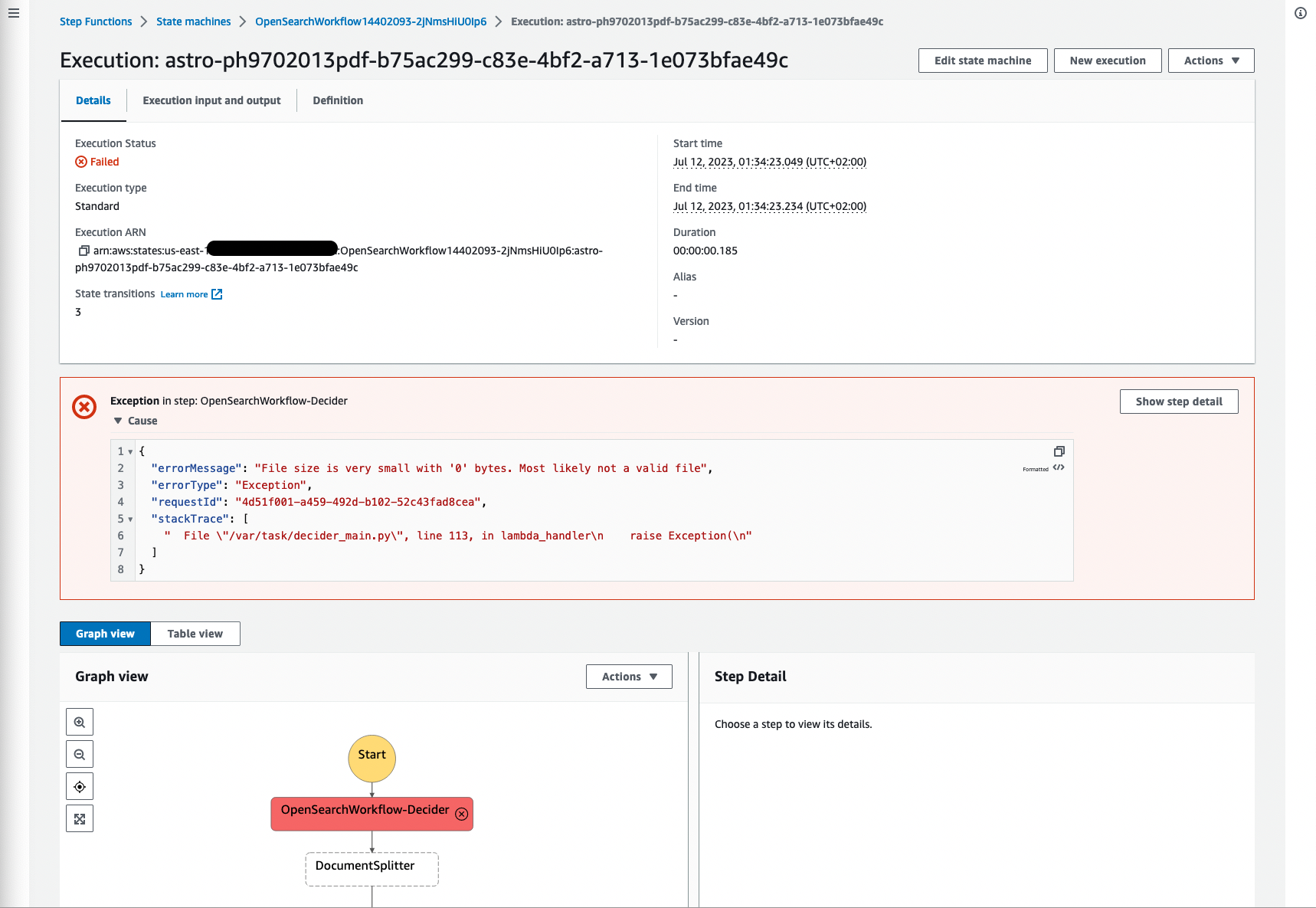
Figure 18: Step Functions failed workflow
Other failures might include documents that are not of mime type: application/pdf, image/png, image/jpeg, or image/tiff because other document types are not supported by Amazon Textract.
Cost
The total cost of ingesting 1,583,278 pages was split across AWS services used for the implementation. The following list serves as approximate numbers, because your actual cost and processing duration vary depending on the size of documents, the number of pages per document, the density of information in the documents, and the AWS Region. Amazon DynamoDB was consuming $0.55, Amazon S3 $3.33, OpenSearch Service $14.71, Step Functions $17.92, AWS Lambda $28.95, and Amazon Textract $1,849.97. Also, keep in mind that the deployed Amazon OpenSearch Service cluster is billed by the hour and will accumulate higher cost when run over a period of time.
Modifications
Most likely, you want to modify the implementation and customize for your use case and documents. The workshop Use machine learning to automate and process documents at scale presents a good overview on how to manipulate the actual workflows, changing the flow, and adding new components. To add custom fields to the OpenSearch index, look at the SetMetaData task in the workflow using the set-manifest-meta-data-opensearch AWS Lambda function to add meta-data to the context, which will be added as a field to the OpenSearch index. Any meta-data information will become part of the index.
Cleaning up
Delete the example resources if you no longer need them, to avoid incurring future costs using the followind command:
in the same environment as the cdk deploy command. Beware that this removes everything, including the OpenSearch cluster and all documents and the Amazon S3 bucket. If you want to maintain that information, backup your Amazon S3 bucket and create an index snapshot from your OpenSearch cluster. If you processed many files, then you may have to empty the Amazon S3 bucket first using the AWS Management Console (i.e., after you took a backup or synced them to a different bucket if you want to retain the information), because the cleanup function can time out and then destroy the AWS CloudFormation stack.
Conclusion
In this post, we showed you how to deploy a full stack solution to ingest a large number of documents into an OpenSearch index, which are ready to be used for search use cases. The individual components of the implementation were discussed as well as scaling considerations, cost, and modification options. All code is accessible as OpenSource on GitHub as IDP CDK samples and as IDP CDK constructs to build your own solutions from scratch. As a next step you can start to modify the workflow, add information to the documents in the search index and explore the IDP workshop. Please comment below on your experience and ideas to expand the current solution.
About the Author
 Martin Schade is a Senior ML Product SA with the Amazon Textract team. He has over 20 years of experience with internet-related technologies, engineering, and architecting solutions. He joined AWS in 2014, first guiding some of the largest AWS customers on the most efficient and scalable use of AWS services, and later focused on AI/ML with a focus on computer vision. Currently, he’s obsessed with extracting information from documents.
Martin Schade is a Senior ML Product SA with the Amazon Textract team. He has over 20 years of experience with internet-related technologies, engineering, and architecting solutions. He joined AWS in 2014, first guiding some of the largest AWS customers on the most efficient and scalable use of AWS services, and later focused on AI/ML with a focus on computer vision. Currently, he’s obsessed with extracting information from documents.