Organizations moving towards a data-driven culture embrace the use of data and machine learning (ML) in decision-making. To make ML-based decisions from data, you need your data available, accessible, clean, and in the right format to train ML models. Organizations with a multi-account architecture want to avoid situations where they must extract data from one account and load it into another for data preparation activities. Manually building and maintaining the different extract, transform, and load (ETL) jobs in different accounts adds complexity and cost, and makes it more difficult to maintain the governance, compliance, and security best practices to keep your data safe.
Amazon Redshift is a fast, fully managed cloud data warehouse. The Amazon Redshift cross-account data sharing feature provides a simple and secure way to share fresh, complete, and consistent data in your Amazon Redshift data warehouse with any number of stakeholders in different AWS accounts. Amazon SageMaker Data Wrangler is a capability of Amazon SageMaker that makes it faster for data scientists and engineers to prepare data for ML applications by using a visual interface. Data Wrangler allows you to explore and transform data for ML by connecting to Amazon Redshift datashares.
In this post, we walk through setting up a cross-account integration using an Amazon Redshift datashare and preparing data using Data Wrangler.
Solution overview
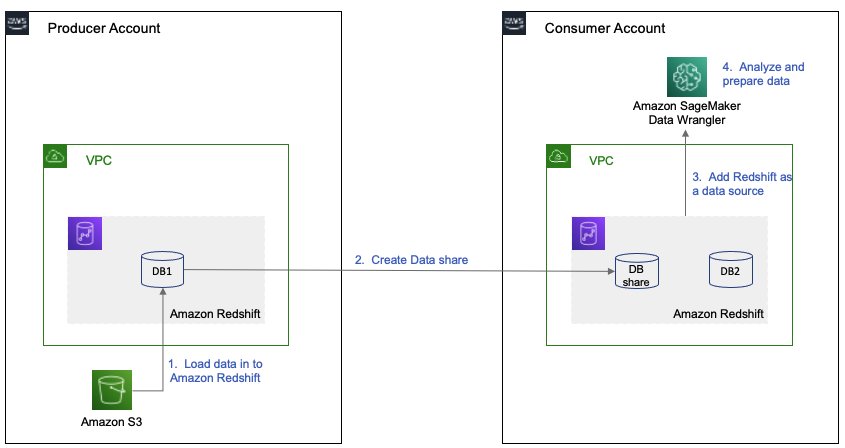
We start with two AWS accounts: a producer account with the Amazon Redshift data warehouse, and a consumer account for SageMaker ML use cases. For this post, we use the banking dataset. To follow along, download the dataset to your local machine. The following is a high-level overview of the workflow:
- Instantiate an Amazon Redshift RA3 cluster in the producer account and load the dataset.
- Create an Amazon Redshift datashare in the producer account and allow the consumer account to access the data.
- Access the Amazon Redshift datashare in the consumer account.
- Analyze and process data with Data Wrangler in the consumer account and build your data preparation workflows.
Be aware of the considerations for working with Amazon Redshift data sharing:
- Multiple AWS accounts – You need at least two AWS accounts: a producer account and a consumer account.
- Cluster type – Data sharing is supported in the RA3 cluster type. When instantiating an Amazon Redshift cluster, make sure to choose the RA3 cluster type.
- Encryption – For data sharing to work, both the producer and consumer clusters must be encrypted and should be in the same AWS Region.
- Regions – Cross-account data sharing is available for all Amazon Redshift RA3 node types in US East (N. Virginia), US East (Ohio), US West (N. California), US West (Oregon), Asia Pacific (Mumbai), Asia Pacific (Seoul), Asia Pacific (Singapore), Asia Pacific (Sydney), Asia Pacific (Tokyo), Canada (Central), Europe (Frankfurt), Europe (Ireland), Europe (London), Europe (Paris), Europe (Stockholm), and South America (São Paulo).
- Pricing – Cross-account data sharing is available across clusters that are in the same Region. There is no cost to share data. You just pay for the Amazon Redshift clusters that participate in sharing.
Cross-account data sharing is a two-step process. First, a producer cluster administrator creates a datashare, adds objects, and gives access to the consumer account. Then the producer account administrator authorizes sharing data for the specified consumer. You can do this from the Amazon Redshift console.
Create an Amazon Redshift datashare in the producer account
To create your datashare, complete the following steps:
- On the Amazon Redshift console, create an Amazon Redshift cluster.
- Specify Production and choose the RA3 node type.
- Under Additional configurations, deselect Use defaults.
- Under Database configurations, set up encryption for your cluster.

- After you create the cluster, import the direct marketing bank dataset. You can download from the following URL: https://sagemaker-sample-data-us-west-2.s3-us-west-2.amazonaws.com/autopilot/direct_marketing/bank-additional.zip.
- Upload
bank-additional-full.csvto an Amazon Simple Storage Service (Amazon S3) bucket your cluster has access to. - Use the Amazon Redshift query editor and run the following SQL query to copy the data into Amazon Redshift:
- Navigate to the cluster details page and on the Datashares tab, choose Create datashare.

- For Datashare name, enter a name.
- For Database name, choose a database.

- In the Add datashare objects section, choose the objects from the database you want to include in the datashare.
You have granular control of what you choose to share with others. For simplicity, we share all the tables. In practice, you might choose one or more tables, views, or user-defined functions. - Choose Add.

- To add data consumers, select Add AWS accounts to the datashare and add your secondary AWS account ID.
- Choose Create datashare.

- To authorize the data consumer you just created, go to the Datashares page on the Amazon Redshift console and choose the new datashare.

- Select the data consumer and choose Authorize.
The consumer status changes from Pending authorization to Authorized.

Access the Amazon Redshift cross-account datashare in the consumer AWS account
Now that the datashare is set up, switch to your consumer AWS account to consume the datashare. Make sure you have at least one Amazon Redshift cluster created in your consumer account. The cluster has to be encrypted and in the same Region as the source.
- On the Amazon Redshift console, choose Datashares in the navigation pane.
- On the From other accounts tab, select the datashare you created and choose Associate.
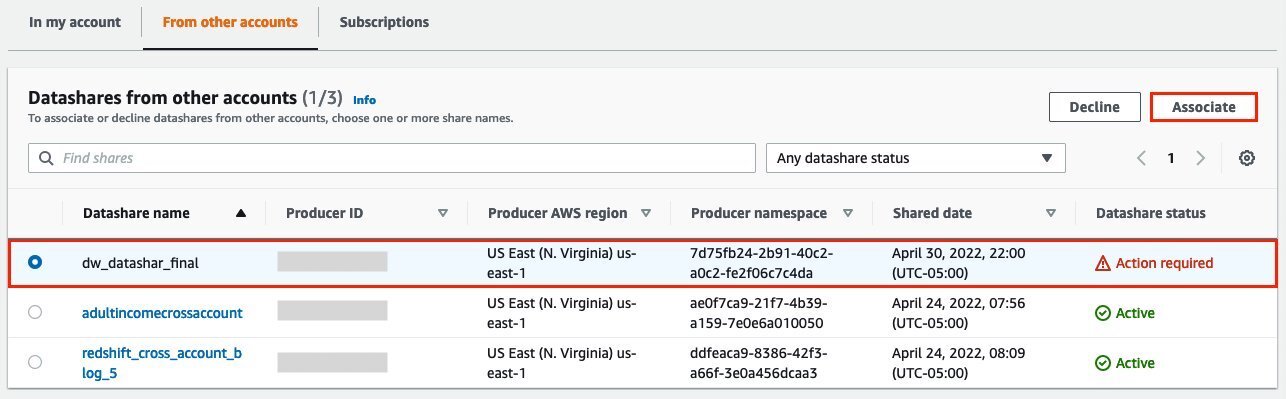
- You can associate the datashare with one or more clusters in this account or associate the datashare to the entire account so that the current and future clusters in the consumer account get access to this share.

- Specify your connection details and choose Connect.

- Choose Create database from datashare and enter a name for your new database.

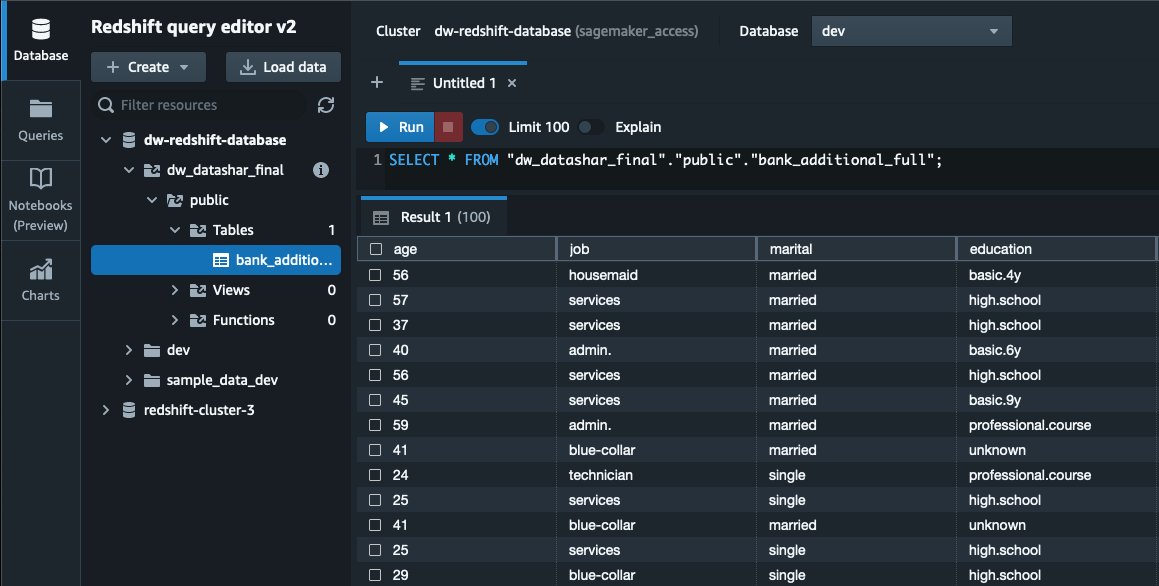
- To test the datashare, go to query editor and run queries against the new database to make sure all the objects are available as part of the datashare.
Analyze and process data with Data Wrangler
You can now use Data Wrangler to access the cross-account data created as a datashare in Amazon Redshift.
- Open Amazon SageMaker Studio.
- On the File menu, choose New and Data Wrangler Flow.

- On the Import tab, choose Add data source and Amazon Redshift.
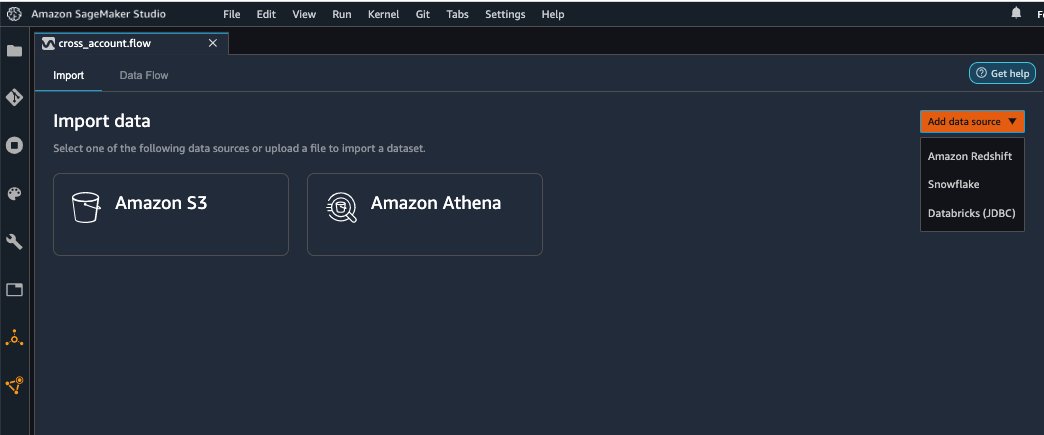
- Enter the connection details of the Amazon Redshift cluster you just created in the consumer account for the datashare.
- Choose Connect.
- Use the AWS Identity and Access Management (IAM) role you used for your Amazon Redshift cluster.
Note that even though the datashare is a new database in the Amazon Redshift cluster, you can’t connect to it directly from Data Wrangler.


The correct way is to connect to the default cluster database first, and then use SQL to query the datashare database. Provide the required information for connecting to the default cluster database. Note that an AWS Key Management Service (AWS KMS) key ID is not required in order to connect.
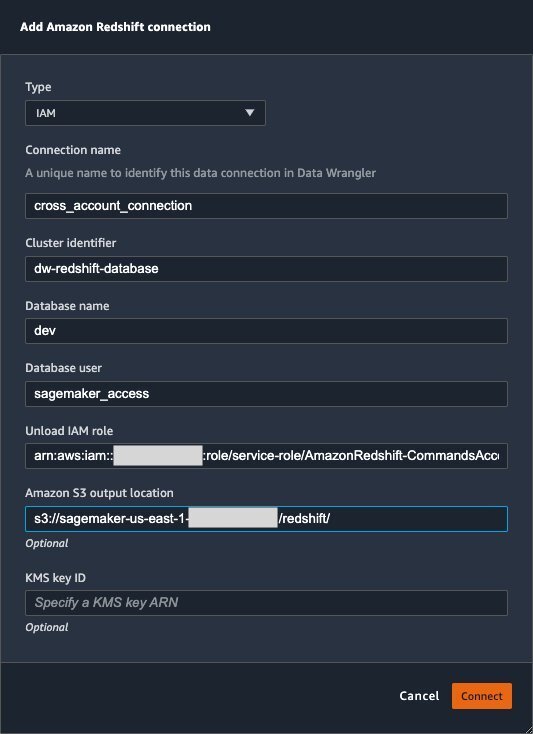
Data Wrangler is now connected to the Amazon Redshift instance.
- Query the data in the Amazon Redshift datashare database using a SQL editor.
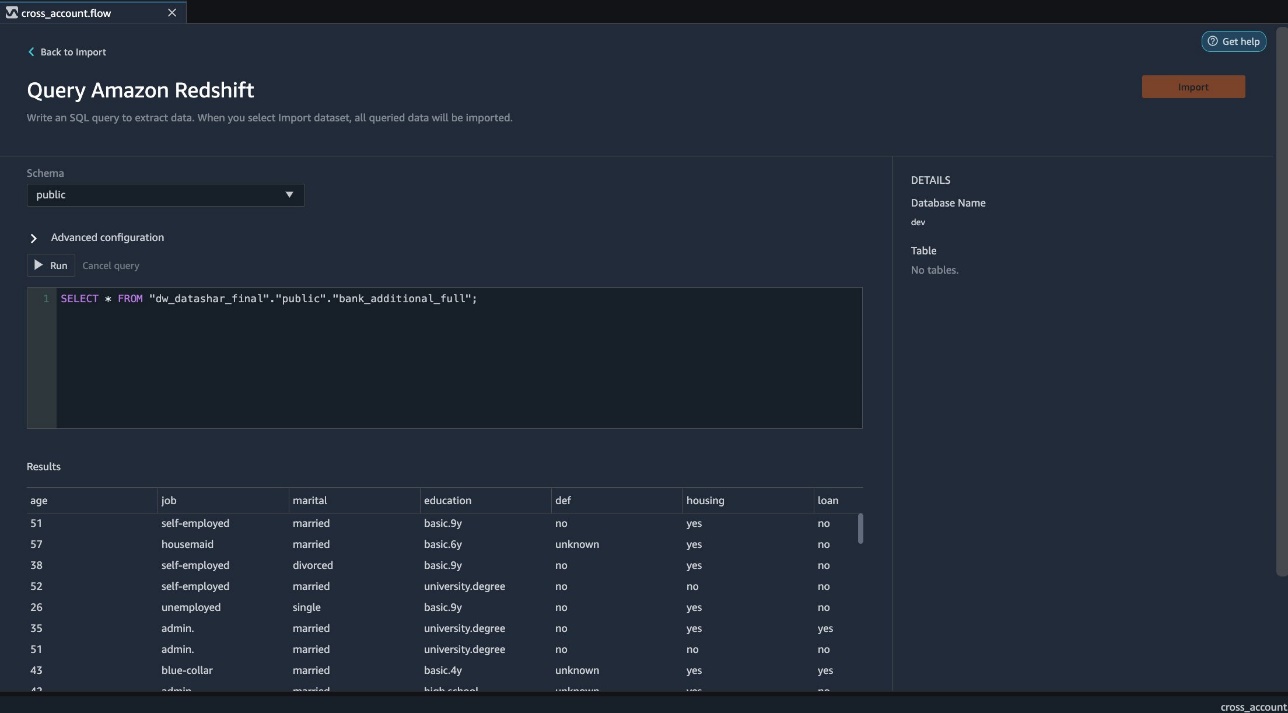
- Choose Import to import the dataset to Data Wrangler.
- Enter a name for the dataset and choose Add.

You can now see the flow on the Data Flow tab of Data Wrangler.
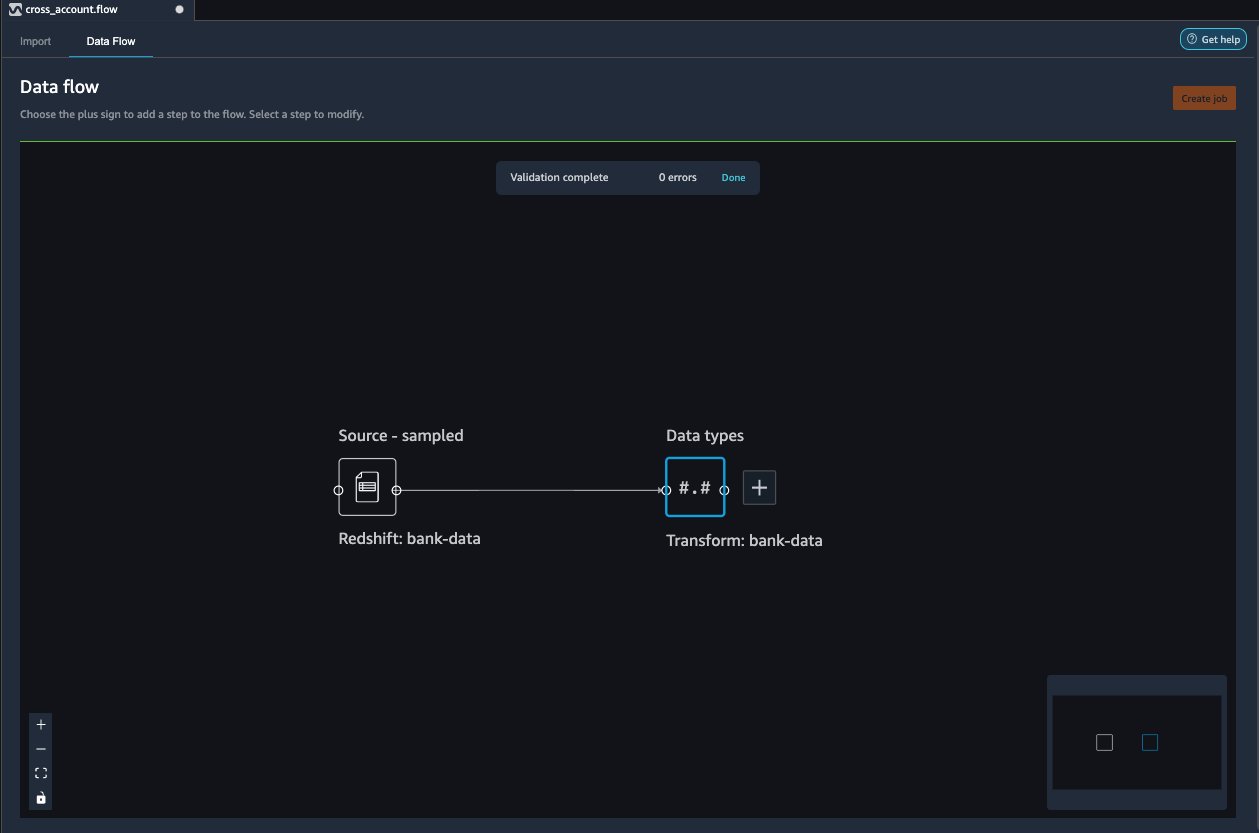
After you have loaded the data into Data Wrangler, you can do exploratory data analysis and prepare data for ML.
- Choose the plus sign and choose Add analysis.
Data Wrangler provides built-in analyses. These include but aren’t limited to a data quality and insights report, data correlation, a pre-training bias report, a summary of your dataset, and visualizations (such as histograms and scatter plots). You can also create your own custom visualization.
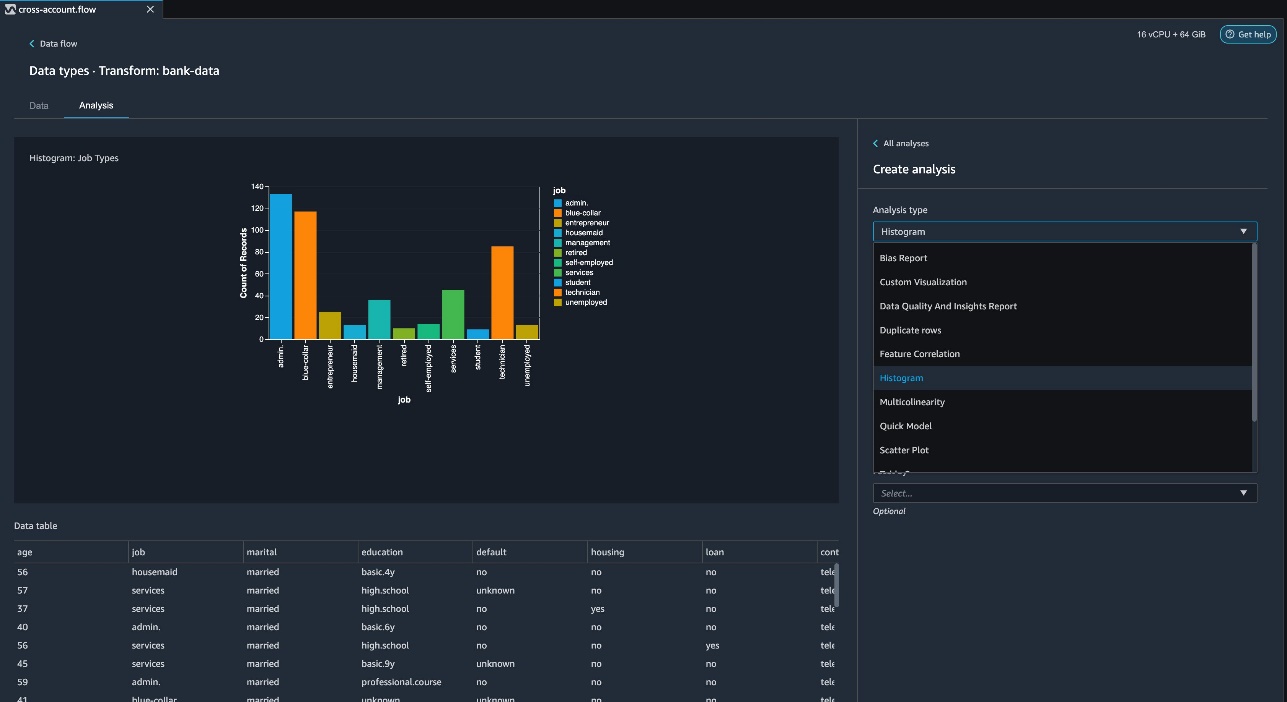
You can use the Data Quality and Insights Report to automatically generate visualizations and analyses to identify data quality issues, and recommend the right transformation required for your dataset.
- Choose Data Quality and Insights Report, and choose the Target column as y.
- Because this is a classification problem statement, for Problem type, select Classification.
- Choose Create.

Data Wrangler creates a detailed report on your dataset. You can also download the report to your local machine.
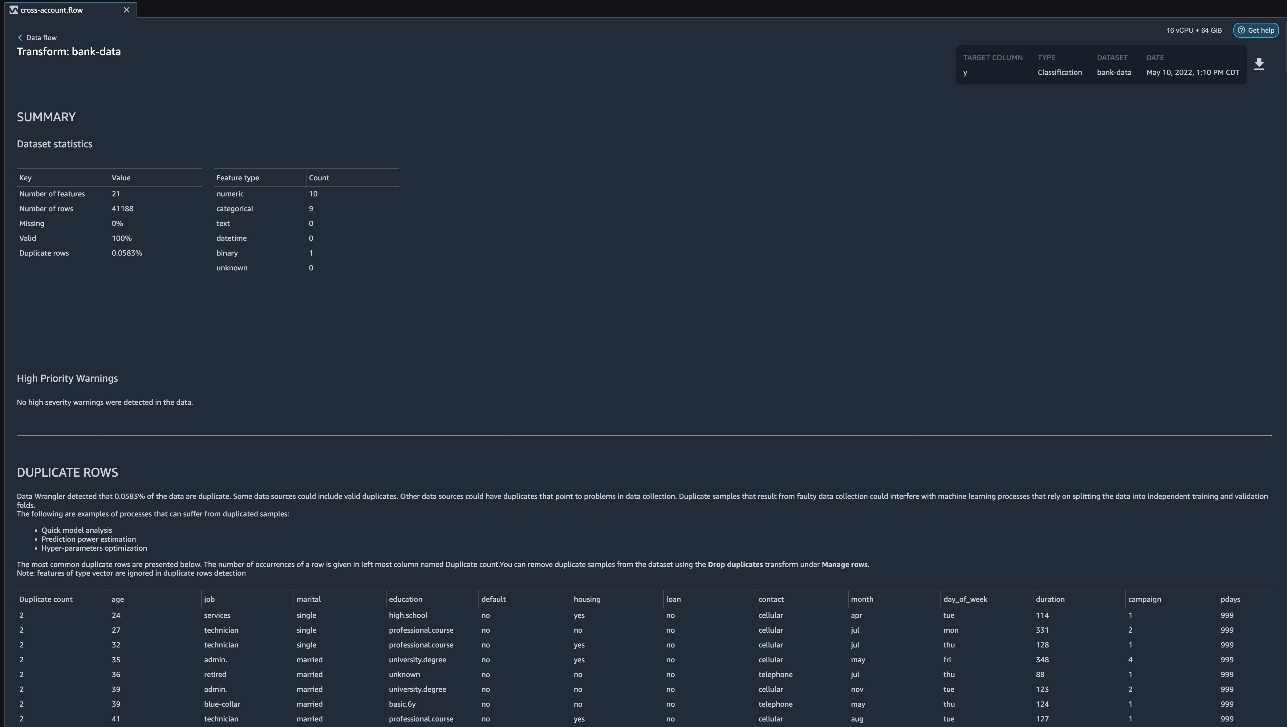
- For data preparation, choose the plus sign and choose Add analysis.
- Choose Add step to start building your transformations.

At the time of this writing, Data Wrangler provides over 300 built-in transformations. You can also write your own transformations using Pandas or PySpark.
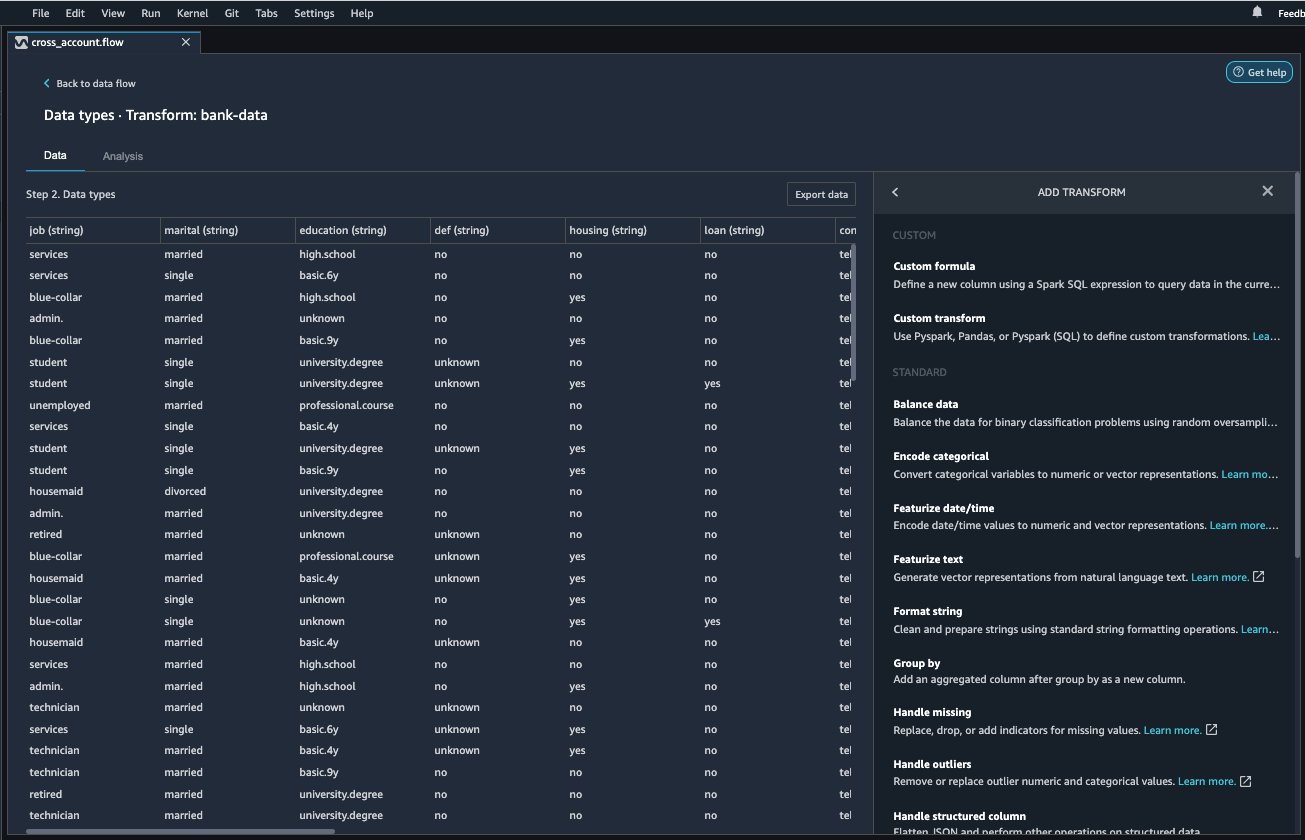
You can now start building your transforms and analysis based on your business requirement.
Conclusion
In this post, we explored sharing data across accounts using Amazon Redshift datashares without having to manually download and upload data. We walked through how to access the shared data using Data Wrangler and prepare the data for your ML use cases. This no-code/low-code capability of Amazon Redshift datashares and Data Wrangler accelerates training data preparation and increases the agility of data engineers and data scientists with faster iterative data preparation.
To learn more about Amazon Redshift and SageMaker, refer to the Amazon Redshift Database Developer Guide and Amazon SageMaker Documentation.
About the Authors
 Meenakshisundaram Thandavarayan is a Senior AI/ML specialist with AWS. He helps hi-tech strategic accounts on their AI and ML journey. He is very passionate about data-driven AI.
Meenakshisundaram Thandavarayan is a Senior AI/ML specialist with AWS. He helps hi-tech strategic accounts on their AI and ML journey. He is very passionate about data-driven AI.
 James Wu is a Senior AI/ML Specialist Solution Architect at AWS. helping customers design and build AI/ML solutions. James’s work covers a wide range of ML use cases, with a primary interest in computer vision, deep learning, and scaling ML across the enterprise. Prior to joining AWS, James was an architect, developer, and technology leader for over 10 years, including 6 years in engineering and 4 years in marketing & advertising industries.
James Wu is a Senior AI/ML Specialist Solution Architect at AWS. helping customers design and build AI/ML solutions. James’s work covers a wide range of ML use cases, with a primary interest in computer vision, deep learning, and scaling ML across the enterprise. Prior to joining AWS, James was an architect, developer, and technology leader for over 10 years, including 6 years in engineering and 4 years in marketing & advertising industries.