This is the first in a two-part blog series on how Tyson Foods, Inc., is utilizing Amazon SageMaker and AWS Panorama to automate industrial processes at their meat packing plants by bringing the benefits of artificial intelligence applications at the edge. In part one, we discuss an inventory counting application for packaging lines. In part two, we discuss a vision-based anomaly detection solution at the edge for predictive maintenance of industrial equipment.
As one of the largest processors and marketers of chicken, beef, and pork in the world, Tyson Foods, Inc., is known for bringing innovative solutions to their production and packing plants. In Feb 2020, Tyson announced its plan to bring Computer Vision (CV) to its chicken plants and launched a pilot with AWS to pioneer efforts on inventory management. Tyson collaborated with Amazon ML Solutions Lab to create a state-of-the-art chicken tray counting CV solution that provides real-time insights into packed inventory levels. In this post, we provide an overview of the AWS architecture and a complete walkthrough of the solution to demonstrate the key components in the tray counting pipeline set up at Tyson’s plant. We will focus on the data collection and labeling, training, and deploying of CV models at the edge using Amazon SageMaker, Apache MXNet Gluon, and AWS Panorama.
Operational excellence is a key priority at Tyson Foods. Tyson employs strict quality assurance (QA) measures in their packaging lines, ensuring that only those packaged products that pass their quality control protocols are shipped to its customers. In order to meet customer demand and to stay ahead of any production issue, Tyson closely monitors packed chicken tray counts. However, current manual techniques to count chicken trays that pass QA are not accurate and do not present a clear picture of over/under production levels. Alternate strategies such as monitoring hourly total weight of production per rack does not provide immediate feedback to the plant employees. With a chicken processing capacity of 45,000,000 head per week, production accuracy and efficiency are critical to Tyson’s business. CV can be effectively used in such scenarios to accurately estimate the amount of chicken processed in real-time, empowering employees to identify potential bottlenecks in packaging and production lines as they occur. This enables implementation of corrective measures and improves production efficiency.
Streaming and processing on-premise video streams at the cloud for CV applications requires high network bandwidth and provisioning of relevant infrastructure. This can be a cost prohibitive task. AWS Panorama removes these requirements and enables Tyson to process video streams at the edge on the AWS Panorama Appliance. It reduces latency to/from the cloud and bandwidth costs, while providing an easy-to-use interface for managing devices and applications at the edge.
Object detection is one of the most commonly used CV algorithms that can localize the position of objects in images and videos. This technology is currently being used in various real-life applications such as pedestrian spotting in autonomous vehicles, detecting tumors in medical scans, people counting systems to monitor footfall in retail spaces, amongst others. It is also crucial for inventory management use cases, such as meat tray counting for Tyson, to reduce waste by creating a feedback loop with production processes, cost savings, and delivery of customer shipments on time.
The following sections of this blog post outline how we use live-stream videos from one of the Tyson Foods plants to train an object detection model using Amazon SageMaker. We then deploy it at the edge with the AWS Panorama device.
AWS Panorama
AWS Panorama is a machine learning(ML) appliance that allows organizations to bring CV to on-premise cameras to make predictions locally with high accuracy and low latency. The AWS Panorama Appliance is a hardware device that allows you to run applications that use ML to collect data from video streams, output video with text and graphical overlays, and interact with other AWS services. The appliance can run multiple CV models against multiple video streams in parallel and output the results in real time. It is designed for use in commercial and industrial settings.
The AWS Panorama Appliance enables you to run self-contained CV applications at the edge, without sending images to the AWS Cloud. You can also use the AWS SDK on the AWS Panorama Appliance to integrate with other AWS services and use them to track data from the application over time. To build and deploy applications, you use the AWS Panorama Application CLI. The CLI is a command line tool that generates default application folders and configuration files, builds containers with Docker, and uploads assets.
AWS Panorama supports models built with Apache MXNet, DarkNet, GluonCV, Keras, ONNX, PyTorch, TensorFlow, and TensorFlow Lite. Refer to this blog post to learn more about building applications on AWS Panorama. During the deployment process AWS Panorama takes care of compiling the model specific to the edge platform through Amazon SageMaker Neo compilation. The inference results can be routed to AWS services such as Amazon S3, Amazon CloudWatch or integrated with on-premise line-of-business applications. The deployment logs are stored in Amazon CloudWatch.
To track any change in inference script logic or trained model, one can create a new version of the application. Application versions are immutable snapshots of an application’s configuration. AWS Panorama saves previous versions of your applications so that you can roll back updates that aren’t successful, or run different versions on different appliances.
For more information, refer to the AWS Panorama page. To learn more about building sample applications, refer to AWS Panorama Samples.
Approach

A plant employee continuously fills-in packed chicken trays into plastic bins and stacks them over time, as show in the preceding figure. We want to be able to detect and count the total number of trays across all the bins stacked vertically.
A trained object detection model can predict bounding boxes of all the trays placed in a bin at every video frame. This can be used to gauge tray counts in a bin at a given instance. We also know that at any point in time, only one bin is being filled with packed trays; the tray counts continuously oscillate from high (during filling) to low (when a new bin obstructs the view of filled bin).
With this knowledge, we adopt the following strategy to count total number of chicken trays:
- Maintain two different counters – local and global. Global counter maintains total trays binned and local counter stores maximum number of trays placed in a new bin.
- Update local counter as new trays are placed in the bin.
- Detect a new bin event in the following ways:
- The tray count in a given frame goes to zero. (or)
- The stream of tray numbers in the last n frames drops continuously.
- Once the new bin event is detected, add the local counter value to global counter.
- Reset local counter to zero.
We tested this algorithm on several hours of video and got consistent results.
Training an object detection model with Amazon SageMaker
Dataset creation:
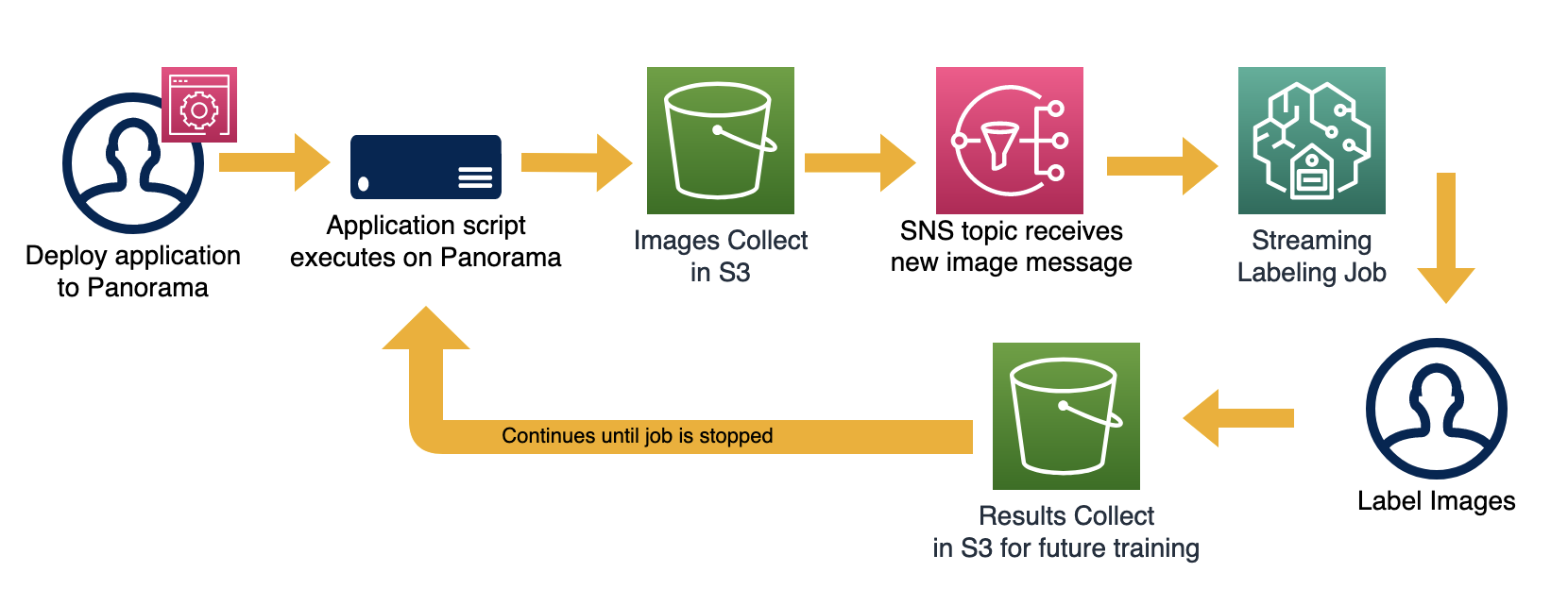
Capturing new images for labeling jobs
We collected image samples from the packaging line using the AWS Panorama Appliance. The script to process images and save them was packaged as an application and deployed on AWS Panorama. The application collects video frames from an on-premise camera set up near the packaging zone and saves them at 60 seconds intervals to an Amazon S3 bucket; this prevents capturing similar images in the video sequence that are a few seconds apart. We also mask out adjacent regions in the image that are not relevant for the use-case.
We labeled the chicken trays with bounding boxes using Amazon SageMaker Ground Truth’s streaming labeling job. We also set up an Amazon S3 Event notification that publishes object-created events to an Amazon Simple Notification Service (SNS) topic, which acts as the input source for the labeling job. When the AWS Panorama application script saves an image to an S3 bucket, an event notification is published to the SNS topic, which then sends this image to the labeling job. As the annotators label every incoming image, Ground Truth saves the labels into a manifest file, which contains S3 path of the image as well as coordinates of chicken tray bounding boxes.
We perform several data augmentations (for example: random noise, random contrast and brightness, channel shuffle) on the labeled images to make the model robust to variations in real-life. The original and augmented images were combined to form a unified dataset.
Model Training:

Once the labeling job is completed, we manually trigger an AWS Lambda function. This Lambda function bundles images and their corresponding labels from the output manifest into an LST file. Our training and test files had images collected from different packaging lines to prevent any data leak in evaluation. The Lambda function then triggers an Amazon SageMaker training job.
We use SageMaker Script Mode, which allows you to bring your own training algorithms and directly train models while staying within the user-friendly confines of Amazon SageMaker. We train models like SSD, Yolo-v3 (for real-time inference latency) with various backbone network combinations from GluonCV Model Zoo for object detection in script-mode. Neural networks have the tendency to overfit training data, leading to poor out-of-sample results. GluonCV provides image normalization and image augmentations, such as randomized image flipping and cropping, to help reduce overfitting during training. The model training code is containerized and uses the Docker image in our AWS Elastic Container Registry. The training job takes the S3 image folder and LST file paths as inputs and saves the best model artifact (.params and .json) to S3 upon completion.
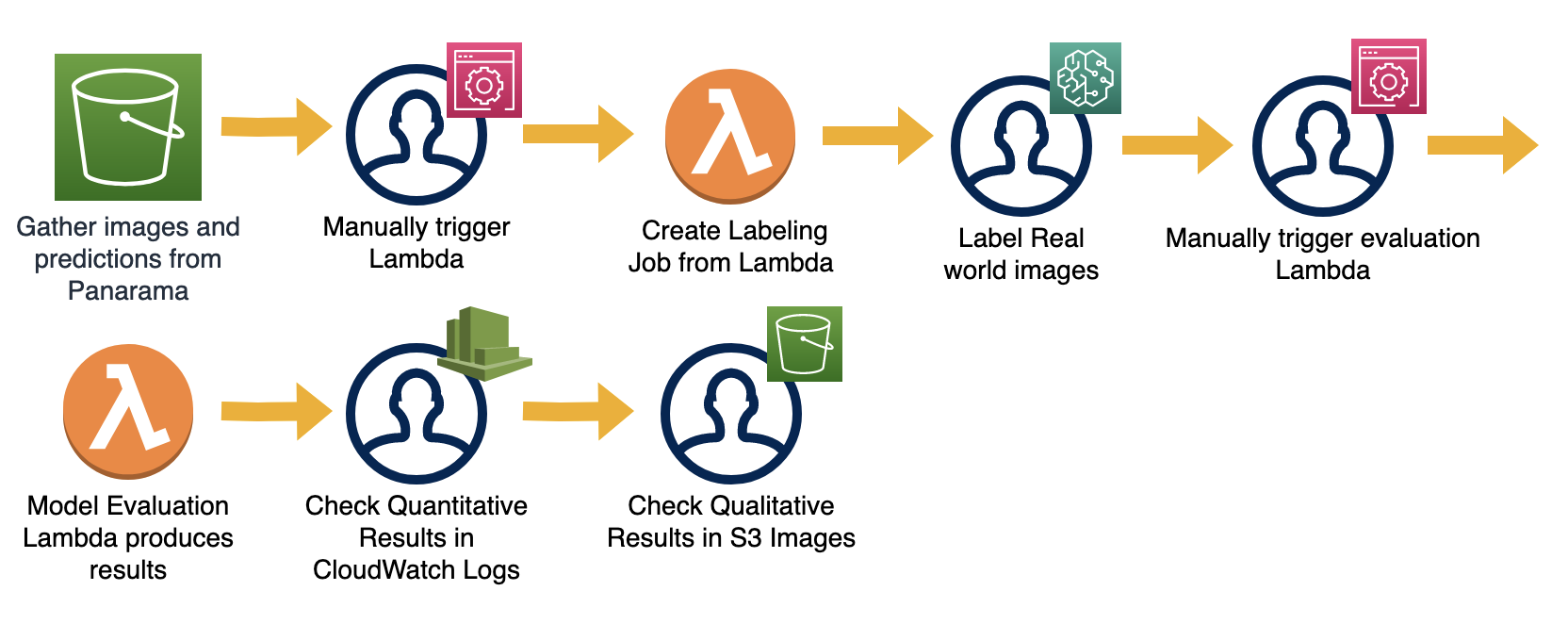
Model Evaluation Pipeline
The top-2 models based on our test set were SSD-resnet50 and Yolov3-darketnet53, with a mAP score of 0.91 each. We also performed real-world testing by deploying an inference application on AWS Panorama device along with the trained model. The inference script saves the predictions and video frames to an Amazon S3 bucket. We created another SageMaker Ground Truth job for annotating ground truth and then performed additional quantitative model evaluation. The ground truth and predicted bounding box labels on images were saved in S3 for qualitative evaluation. The models were able to generalize on the real-world data and yielded consistent performance similar to that on our test-set.
You can find full, end-to-end examples of creating custom training jobs, training state-of-the-art object detection models, implementing Hyperparameter Optimization (HPO), and model deployment on Amazon SageMaker on the AWS Labs GitHub repo.
Deploying meat-tray counting application

Production Architecture
Before deployment, we package all our assets – model, inference script, camera and global variable configuration into a single container as mentioned in this blog post. Our continuous integration and continuous deployment (CI/CD) pipeline updates any change in the inference script as a new application version. Once the new application version is published, we deploy it programmatically using boto3 SDK in Python.
Upon application deployment, AWS Panorama first creates an AWS SageMaker Neo Compilation job to compile the model for the AWS Panorama device. The inference application script imports the compiled-model on the device and performs chicken-tray detection at every frame. In addition to SageMaker Neo-Compilation, we enabled post-training quantization by adding a os.environ['TVM_TENSORRT_USE_FP16'] = '1' flag in the script. This reduces the size of model weights from float 32 to float 16, decreasing model size by half and improving latency without degradation in performance. The inference results are captured in AWS SiteWise Monitor through MQTT messages from the AWS Panorama device via AWS IoT core. The results are then pushed to Amazon S3 and visualized in Amazon QuickSight Dashboards. The plant managers and employees can directly view these dashboards to understand throughput of every packaging line in real-time.
Conclusion
By combining AWS Cloud service like Amazon SageMaker, Amazon S3 and edge service like AWS Panorama, Tyson Foods Inc., is infusing artificial intelligence to automate human-intensive industrial processes like inventory counting in its manufacturing plants. Real-time edge inference capabilities enable Tyson to identify over/under production and dynamically adjust their production flow to maximize efficiency. Furthermore, by owning the AWS Panorama device at the edge, Tyson is also able to save costs associated with expensive network bandwidth to transfer video files to the cloud and can now process all their video/image assets locally in their network.
This blog post provides you with an end-end edge application overview and reference architectures for developing a CV application with AWS Panorama. We discussed 3 different aspects of building an edge CV application.
- Data: Data collection, processing and labeling using AWS Panorama and Amazon SageMaker Ground Truth.
- Model: Model training and evaluation using Amazon SageMaker and AWS Lambda
- Application Package: Bundling trained model, scripts and configuration files for AWS Panorama.
Stay tuned for part two of this series on how Tyson is using AWS Panorama for CV based predictive maintenance of industrial machines.
Click here to start your journey with AWS Panorama. To learn more about collaborating with ML Solutions Lab, see Amazon Machine Learning Solutions Lab.
About the Authors
 Divya Bhargavi is a data scientist at the Amazon ML Solutions Lab where she works with customers across various verticals and applies creative problem solving to generate value for customers with state-of-the-art ML/AI solutions.
Divya Bhargavi is a data scientist at the Amazon ML Solutions Lab where she works with customers across various verticals and applies creative problem solving to generate value for customers with state-of-the-art ML/AI solutions.
 Dilip Subramaniam is a Senior Developer with the Emerging Technologies team at Tyson Foods. He is passionate about building large-scale distributed applications to solve business problems and simplify processes using his knowledge in Software Development, Machine Learning, and Big Data.
Dilip Subramaniam is a Senior Developer with the Emerging Technologies team at Tyson Foods. He is passionate about building large-scale distributed applications to solve business problems and simplify processes using his knowledge in Software Development, Machine Learning, and Big Data.