This blog post was co-authored by AWS and Max Kelsen. Max Kelsen is one of Australia’s leading Artificial Intelligence (AI) and Machine Learning (ML) solutions businesses. The company delivers innovation, directly linked to the generation of business value and competitive advantage to customers in Australia and globally, including Fortune 500 companies. Max Kelsen is also dedicated to reinvesting our expertise and profits to solve the challenges of humankind, focusing on Genomics, AI Safety, and Quantum Computing.
Robots require the integration of technologies such as image recognition, sensing, artificial intelligence, machine learning (ML), and reinforcement learning (RL) in ways that are new to the field of robotics. Today, we’re launching Amazon SageMaker Reinforcement Learning Kubeflow Components supporting AWS RoboMaker, a cloud robotics service, for orchestrating robotics ML workflows. Orchestrating robotics operations to train, simulate, and deploy RL applications is difficult and time-consuming. Now, with SageMaker RL components and pipelines, it’s faster to experiment and manage robotics ML workflows from perception to controls and optimization, and create end-to-end solutions without having to rebuild each time.
Robots are being used more widely in society for purposes that are increasing in sophistication, such as complex assembly, picking and packing, last-mile delivery, environmental monitoring, search and rescue, and assisted surgery. Robotics often involves training complex sequences of behaviors. RL is an emerging ML technique that can help develop solutions for exactly these kinds of problems. It learns complex behaviors without requiring any labeled training data, and can make short-term decisions while optimizing for a long-term goal. For example, when a robot interacts with its environment, this mostly takes place in a simulator. The robot receives a positive or negative reward for actions that it takes. Rewards are computed by a user-defined function that outputs a numeric representation of the actions that should be incentivized. The agent tries to maximize positive rewards, and as a result the model learns an optimal strategy for decision-making.
SageMaker and AWS RoboMaker are two different services streamlined to serve two separate personas: data scientists and roboticists, respectively. SageMaker is a fully managed service that provides every developer and data scientist with the ability to build, train, and deploy ML models quickly. SageMaker RL builds on top of SageMaker, adding pre-packaged RL toolkits and making it easy to integrate any simulation environment. AWS RoboMaker is the most complete cloud solution for robotic developers to simulate, test, and securely deploy robotic applications at scale. Its managed Robot Operating System (ROS) (https://www.ros.org/) and Gazebo (http://gazebosim.org/), an open-source robot simulation software, stacks free up engineering resources and enable you to start building quickly. The task of stitching together machine learning workflows for robotics using Amazon SageMaker and AWS RoboMaker is non-trivial, consuming valuable time for both data scientists and roboticists.
With Amazon SageMaker RL Components for Kubernetes, you can use SageMaker RL Components in your Kubeflow pipelines to invoke and parallelize SageMaker training jobs and AWS RoboMaker simulation jobs as steps in your RL training workflow, without having to worry about how it runs under the hood. The following diagram illustrates the pipeline workflow for SageMaker RL Components
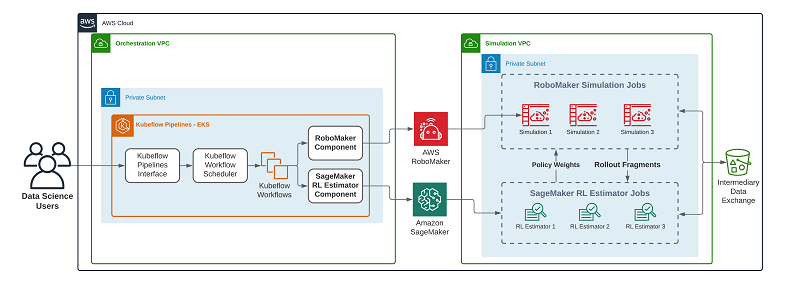
SageMaker Components in your Kubeflow pipeline simply loads the components and describes your pipeline using the Kubeflow Pipelines SDK. SageMaker RL uses open-source libraries such as Anyscale’s Ray to start training an RL agent by collecting experience from Gazebo (an open-source software to simulate populations of robots in complex indoor and outdoor environments) in AWS RoboMaker using ROS (a set of software libraries and tools that help you build robot applications). When the training is completed, the RL agent model is stored in an Amazon Simple Storage Service (Amazon S3) bucket, and an Amazon SageMaker inference node can be created for deployment in production. You can then download the model to the robot with the same ROS structure from the simulation to perform the required tasks.
Although our solution is implemented in Kubeflow components and pipelines, it’s not specific to Kubeflow and can be generalized to MLOps workflows in Argo and Kubernetes to orchestrate parallel robotics ML jobs.
Use case: Woodside Energy deploys robotics in oil and gas environments
Woodside Energy uses AWS RoboMaker with Amazon SageMaker Kubeflow operators to train, tune, and deploy reinforcement learning agents to their robots to perform manipulation tasks that are repetitive or dangerous. This framework will allow the team to iterate and deploy at scale.
“Our team and our partners wanted to start exploring using machine learning methods for robotics manipulation,” says Kyle Saltmarsh, Robotics Engineer at Woodside Energy. “Before we could do this effectively, we needed a framework that would allow us to train, test, tune, and deploy these models efficiently. Utilizing Kubeflow components and pipelines with SageMaker and RoboMaker provides us with this framework and we are excited to have our roboticists and data scientists focus their efforts and time on algorithms and implementation.”
Woodside and AWS engaged Max Kelsen to assist in the development and contribution of the RoboMaker and RLEstimator components that enable the pipelines described in this project. Max Kelsen leverages open source throughout most of its work, and views participation in these communities as strategically important to delivering the best outcomes for our clients.
In the following image, Ripley, a custom-built robotics platform by Woodside Energy, is getting ready to perform a double block and bleed, a manual pump shutdown procedure that involves turning multiple valves in sequence. Ripley is based on a Clearpath Robotics Husky equipped with two Universal Robotics UR5 arms, Intel RealSense D435 cameras on each wrist, and a Kodak PixPro body camera. The reinforcement learning formulation utilizes the joint states and camera views as inputs to the agent and outputs optimal trajectories for valve manipulation.

Getting started with SageMaker RL components
In a typical Kubeflow pipeline, each component encapsulates your logic in a container image. As a developer or data scientist, you bring in your training, data preprocessing, model serving, or other logic wrapped in a Kubeflow Pipelines ContainerOp function, which builds your code into a new container. Alternatively, you can put the code into a custom container image and push it to a container registry such as Amazon Elastic Container Registry (Amazon ECR). When the pipeline runs, the component’s container is instantiated on one of the worker nodes on the Kubernetes cluster running Kubeflow, and your logic is implemented. Pipeline components can read outputs from the previous components and create outputs that the next component in the pipeline can consume.
When you use SageMaker Components in your Kubeflow pipeline, rather than encapsulating your logic in a custom container, you simply load the components and describe your pipeline using the Kubeflow Pipelines SDK. When the pipeline runs, your instructions are translated into a SageMaker job or deployment. This workload runs on the fully managed infrastructure of SageMaker. You also get all the benefits of a typical SageMaker capability, including Managed Spot Training, automatic scaling of endpoints, and more.
You have separate VPCs for orchestration and simulation. The reason is that no direct communication is needed between the RLEstimator or AWS RoboMaker jobs and the Kubeflow Pipelines components. The components interact directly with the AWS RoboMaker and SageMaker APIs, but not the jobs themselves. The components poll the APIs for the status of the jobs and any related Amazon CloudWatch Logs, and the responses are reflected back to the Kubeflow Pipelines UI. This offers a single interface for viewing the status of the running jobs.
The orchestration VPC utilizes both public and private subnets and a NAT gateway. The Amazon Elastic Kubernetes Service (Amazon EKS) worker nodes are launched into a private network, and use a route to the NAT gateway in the public subnet to interact with AWS APIs, and also to pull public Docker images to run on the cluster. For this post, we allow public access to the EKS cluster endpoint. This allows you to run kubectl port forwarding from your local machine and by doing so open up a tunnel to access the Kubeflow UI. In a production system, we suggest placing the Kubeflow service behind an Application Load Balancer (ALB) and secure using AWS Identity and Access Management (IAM).
Prerequisites
To run the following use case, you need the following:
- Kubernetes cluster – You can use your existing cluster or create a new one. The fastest way to get one up and running is to launch an EKS cluster using eksctl. For instructions, see Getting started with eksctl. Create a simple cluster with two CPU nodes to run this example. We tested this example on a 2 c5.xlarge. You just need enough node resources to run the SageMaker Component containers and Kubeflow. Training and deployments run on the SageMaker and AWS RoboMaker managed infrastructure.
- Kubeflow Pipelines – Install Kubeflow Pipelines on your cluster. For instructions, see Step 1 in Deploying Kubeflow Pipelines. Your Kubeflow Pipelines version must be 0.5.0 or above. Optionally, you can install all of Kubeflow, which includes Kubeflow Pipelines.
- SageMaker and AWS RoboMaker components prerequisites – For instructions on setting up IAM roles and permissions, see Amazon SageMaker Components for Kubeflow Pipelines. You need three IAM roles for the following:
- Kubeflow pipeline pods to access SageMaker and AWS RoboMaker and launch training and simulation jobs.
- Amazon SageMaker execution role to access other AWS resources such as Amazon S3.
- AWS RoboMaker execution role to access other AWS resources such as Amazon S3.
You can launch an EKS cluster from your laptop, desktop, Amazon Elastic Compute Cloud (Amazon EC2) instance, or SageMaker notebook instance. This instance is typically called a gateway instance. Because Amazon EKS offers a fully managed control plane, you only use out-of-the-box the gateway instance to interact with the Kubernetes API and worker nodes. The instance should have a role that allows for interaction with the EKS cluster. The code in the examples here was run from a local device with access to the EKS cluster.
Solution overview
The code, configuration files, and Jupyter notebooks used in this post are available on GitHub. The following walkthrough is provided to explain the key concepts. Rather than copying code from these steps, we recommend running the prepared Jupyter notebook. In this post, we walk through the following high-level steps:
- Configure your dependent resources.
- Clone the example repository and install dependencies.
- Open the example Jupyter notebook.
- Install the Kubeflow Pipelines SDK and load SageMaker pipeline components.
- Prepare your training datasets and upload them to Amazon S3.
- Create your Kubernetes pipeline.
- Compile and run your pipeline.
Configuring your dependent resources
If you’re following the proposed architecture from this post, you run the simulation jobs in a private subnet. To ensure that the running jobs have connectivity to AWS resources, add VPC endpoints for the following services:
- Amazon S3
- CloudWatch
Next, create an S3 bucket to host your simulation job and RLEstimator job source files. The jobs also use this bucket to communicate by writing config files. The bucket should be in the same Region that you’re running the rest of your infrastructure, because VPC endpoints are locked to accessing resources within the same Region.
Finally, you need to configure an IAM role with access to the S3 bucket and AmazonSageMakerFullAccess and AWSRoboMaker_FullAccess policies.
Cloning the example repository and installing dependencies
Open a terminal and SSH to the EC2 gateway instance that you use to communicate with your EKS cluster. After you log in, clone the example repository to access the example Jupyter notebook. See the following code:
git clone https://github.com/MaxKelsen/kubeflow-pipelines-robomaker-examples
cd kubeflow-pipelines-robomaker-examples
pip install -r requirements.txtOpening the example Jupyter notebook
As part of the previous step, you installed Jupyter. To open the Jupyter notebook on your gateway instance, complete the following steps:
- Launch JupyterLab on your gateway instance and access it on your local machine with the following code:
jupyter lab
- If you’re running the JupyterLab server on an EC2 instance, set up a tunnel to the EC2 instance so you can access the JupyterLab client on your local laptop or desktop. (If you’re using Amazon Linux instead of Ubuntu, you have to use
ec2-useras the username. Update the IP address of the EC2 instance and use the appropriate key pair.) See the following code:ssh -N -L 0.0.0.0:8081:localhost:8081 -L 0.0.0.0:8888:localhost:8888 -i ~/.ssh/<key_pair>.pem ubuntu@<IP_ADDRESS>
You can now access Jupyter lab at http://localhost:8888 on your local machine.
- Access the Kubeflow dashboard by running the following on your gateway instance:
kubectl port-forward svc/istio-ingressgateway -n istio-system 8081:80
You can now access the Kubeflow dashboard at http://localhost:8081.
Open the example Jupyter notebook (kfp-robomaker-example.ipynb).
SageMaker RLEstimator supports two modes for training jobs (the GitHub repo includes one Jupyter notebook for the latter approach):
- Bring your own Docker container image – In this mode, you can provide your own Docker container for training. Build your container with your training scripts and push it to Amazon ECR, which is a container registry. SageMaker pulls your container image, instantiates it, and runs training.
- Bring your own training script (script mode) – In this mode, you don’t have to deal with Docker containers. Simply bring your RLEstimator training scripts in popular frameworks such as TensorFlow, PyTorch, MXNet, and popular RL toolkits such as Coach and Ray, and upload it to Amazon S3. SageMaker automatically pulls the appropriate container, downloads your training scripts, and runs it. This mode is ideal if you don’t want to deal with Docker containers. The kfp-robomaker-example.ipynb Jupyter notebook implements this approach.
The following example takes a closer look at the first approach (bringing your own Docker container image). You walk through all the important steps in the kfp-robomaker-example.ipynb Jupyter notebook. Having it open makes it easy for you to follow along.
The following screenshot shows the kfp-robomaker-example.ipynb notebook.
Installing Kubeflow Pipelines SDK and loading SageMaker pipeline components
To install the SDK and load the pipeline components, complete the following steps:
- Install the Kubeflow Pipelines SDK with the following code:
pip install kfp –upgrade
- Import Kubeflow Pipeline packages in Python with the following code:
import kfp from kfp import components from kfp.components import func_to_container_op from kfp import dsl
- Load SageMaker Components in Python with the following code:
robomaker_create_sim_app_op = components.load_component_from_url('https://raw.githubusercontent.com/kubeflow/pipelines/ 4aa11c3c7f6f068fdb135e1af4a0af5bb1d72d17 /components/aws/sagemaker/create_simulation_app/component.yaml') robomaker_sim_job_op = components.load_component_from_url('https://raw.githubusercontent.com/kubeflow/pipelines/ 4aa11c3c7f6f068fdb135e1af4a0af5bb1d72d17/components/aws/sagemaker/simulation_job/component.yaml') robomaker_delete_sim_app_op = components.load_component_from_url( 'https://raw.githubusercontent.com/kubeflow/pipelines/ 4aa11c3c7f6f068fdb135e1af4a0af5bb1d72d17/components/aws/sagemaker/delete_simulation_app/component.yaml') sagemaker_rlestimator_op = components.load_component_from_url('https://raw.githubusercontent.com/kubeflow/pipelines/ 4aa11c3c7f6f068fdb135e1af4a0af5bb1d72d17/components/aws/sagemaker/rlestimator/component.yaml')
Preparing training datasets and uploading to Amazon S3
To prepare and upload the source code for SageMaker and AWS RoboMaker, enter the following code:
import boto3
s3 = boto3.resource('s3')
role = "<your_role_name>"
bucket_name = "<your_bucket_name>"
s3.meta.client.upload_file("sourcedir.tar.gz", bucket_name, "sagemaker-sources/sourcedir.tar.gz")
print(f"nUploaded to S3 location: {bucket_name}sagemaker-sources/sourcedir.tar.gz")
s3.meta.client.upload_file("output.tar", bucket_name, "robomaker-sources/output.tar")
print(f"nUploaded to S3 location: {bucket_name}robomaker-sources/output.tar")Here we upload a sourcedir.tar.gz that contains some object_tracker code that the SageMaker RLEstimator training job uses. We also upload an output.tar file, which contains a colcon bundle that is used to create an AWS RoboMaker simulation application.
Creating a Kubeflow pipeline using AWS RoboMaker and SageMaker Components
You can express a Kubeflow pipeline as a function decorated with @dsl.pipeline, as shown in the following code and in kfp-robomaker-example.ipynb. For more information, see Overview of Kubeflow Pipelines.
@dsl.pipeline(
name="SageMaker & RoboMaker pipeline",
description="SageMaker & RoboMaker Reinforcement Learning job where the jobs work together to train an RL model",
)
def sagemaker_robomaker_rl_job(
region="us-east-1",
role=role,
name="robomaker-pipeline-simulation-application"
+ "".join(random.choice(string.ascii_lowercase) for i in range(10)),
sources=[
{
"s3Bucket": bucket_name,
"s3Key": "robomaker-sources/output.tar",
"architecture": "X86_64",
}
],
…In this code example, you create a new function called sagemaker_robomaker_rl_job() and define arguments that are common to all the steps in the pipeline. Within the function, you then define your pipeline components:
- Creating the simulation application
- RLEstimator training job
- AWS RoboMaker simulation jobs
- Deleting the simulation application
Component 1: Creating the simulation application
This component describes options for creating an AWS RoboMaker simulation application from a colcon bundle file. See the following code:
robomaker_create_sim_app = robomaker_create_sim_app_op(
region=region,
app_name=name,
sources=sources,
simulation_software_name=simulation_software_name,
simulation_software_version=simulation_software_version,
robot_software_name=robot_software_name,
robot_software_version=robot_software_version,
rendering_engine_name=rendering_engine_name,
rendering_engine_version=rendering_engine_version,
).set_display_name('Create RoboMaker Sim App')The options include the simulation software name and version, the robot software name and version, and also the sources, which are a link to a colcon bundle in Amazon S3.
Component 2: RLEstimator training job
This component describes an SageMaker RLEstimator training job. The job receives data from the AWS RoboMaker simulation jobs and uses that data to train a model. The job issues new policy weights to the simulation jobs while training. See the following code:
rlestimator_training_toolkit_ray = sagemaker_rlestimator_op(
region=region,
entry_point=entry_point,
source_dir=source_dir,
toolkit=toolkit,
toolkit_version=toolkit_version,
framework=framework,
role=assume_role,
instance_type=instance_type,
instance_count=instance_count,
model_artifact_path=output_path,
job_name=job_name,
metric_definitions=metric_definitions,
max_run=max_run,
hyperparameters={
"rl.training.config.lambda": "0.95",
"robomaker.config.app_arn": robomaker_create_sim_app.outputs["arn"],
"robomaker.config.num_workers": "3",
"robomaker.config.packageName": "object_tracker_simulation",
"robomaker.config.launchFile": "local_client.launch",
"robomaker.config.policyServerPort": "9000",
"robomaker.config.iamRole": assume_role,
"robomaker.config.sagemakerBucket": input_bucket_name,
},
vpc_security_group_ids=vpc_security_group_ids,
vpc_subnets=vpc_subnets,
).set_display_name('Start RLEstimator Training')The options include a reference to the source directory in Amazon S3 where the source code is stored, hyperparameters that are used to configure the training job, and VPC configuration to define where the training job is run. The RLEstimator job spins up a local Redis server that it uses to issue the new policy weights that are consumed by the simulation jobs.
Components 3,4,5: Multiple AWS RoboMaker simulation jobs
These components describe three AWS RoboMaker simulation jobs that use the simulation application created in the robomaker_create_sim_app component. The following code shows one of the components:
robomaker_simulation_job_1 = robomaker_sim_job_op(
region=region,
role=role,
output_bucket=output_bucket,
output_path=robomaker_output_path,
max_run=max_run,
failure_behavior="Fail",
sim_app_arn=robomaker_create_sim_app.outputs["arn"],
sim_app_launch_config={
"packageName": "object_tracker_simulation",
"launchFile": "local_client.launch",
"environmentVariables": {
"RLCAMP_POLICY_SERVER_PORT": "9000",
"RLCAMP_SAGEMAKER_BUCKET": input_bucket_name,
"RLCAMP_SAGEMAKER_JOB_NAME": job_name,
"RLCAMP_AWS_REGION": region,
},
},
vpc_security_group_ids=vpc_security_group_ids,
vpc_subnets=vpc_subnets,
use_public_ip="False",
).set_display_name('RoboMaker Simulation 1')Options include the simulation app launch configuration, which includes environment variables that can configure the S3 bucket used for communication between the RLEstimator job and these simulation jobs.
Component 6: Deleting the simulation application
This component is used to delete the simulation application that we created. There is a soft limit of 40 simulation applications per AWS account, so it makes sense to clean up automatically as we create new pipeline runs. See the following code:
robomaker_delete_sim_app = robomaker_delete_sim_app_op(
region=region, arn=robomaker_create_sim_app.outputs["arn"],
).after(
robomaker_simulation_job_1,
robomaker_simulation_job_2,
robomaker_simulation_job_3,
robomaker_create_sim_app,
).set_display_name('Delete RoboMaker Sim App')The only options are the Region to use to interact with the AWS RoboMaker API and also the ARN of the simulation application to delete. We use the .after() method to define when this component should run as part of the pipeline.
Compiling and running your pipeline
Using the Kubeflow pipeline compiler, you compile the pipeline, create an experiment, and run the pipeline. See the following code:
kfp.compiler.Compiler().compile(sagemaker_robomaker_rl_job,'sagemaker_robomaker_rl_job.zip')
client = kfp.Client()
aws_experiment = client.create_experiment(name='rm-kfp-experiment')
exp_name = f'sagemaker_robomaker_rl_job-{time.strftime("%Y-%m-%d-%H-%M-%S", time.gmtime())}'
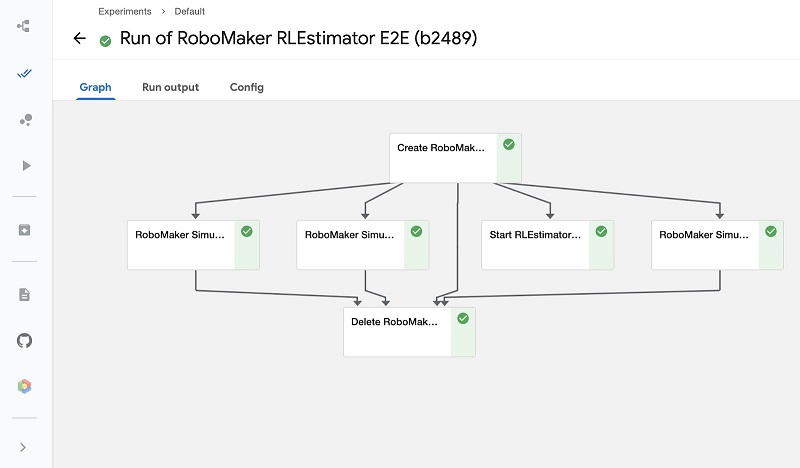
my_run = client.run_pipeline(aws_experiment.id, exp_name, 'sagemaker_robomaker_rl_job.zip')The following is an annotated screenshot of a Kubeflow pipeline after it finishes running. All the steps are SageMaker and AWS RoboMaker capabilities running as part of a Kubeflow pipeline.
Conclusion
In this post, we discussed using SageMaker RL Components to build open-source Kubeflow pipelines. If you have questions or comments about SageMaker RL Components or AWS RoboMaker components, please leave a comment or create an issue on the Kubeflow Pipelines GitHub repo.
About the Authors
Alex Chung is a Senior Product Manager with AWS in enterprise machine learning systems. His role is to make AWS MLOps products more accessible from Kubernetes and custom environments. He’s passionate about accelerating ML adopted for a large body of users to solve global economic and societal problems. Outside machine learning, he is also a board member at a Silicon Valley nonprofit for donating stock to charity, Cocatalyst.org.
Kyle Saltmarsh is a robotics engineer from the Intelligent Assets and Robotics group at Woodside Energy. Kyle enjoys rock climbing, long walks on the beach and robot learning.
Leonard O’Sullivan is a Senior Technical Engineer at Max Kelsen, with numerous AWS certifications including SysOps Admin, Developer and Solution Architect. Leonard has more than 8 years of software development experience, and his passion is creating extensible, maintainable and readable code, with a focus on optimizing workflows and removing bottlenecks. Leonard’s current position centres around the automation and optimization of Machine Learning Operations. In his free time, you can find him playing soccer, eating pizza or trying new activities such as axe throwing and hang gliding.
Nicholas Therkelsen-Terry is CEO and Co-Founder of Max Kelsen, a machine learning and artificial intelligence solutions company. Nick has a broad range of expertise spanning across business, economics, sales, management and law. Nick has a deep theoretical and applied understanding of cutting-edge machine learning techniques and has been widely recognized as an expert and thought-leader in this field. Nick is a founding member and board representative of the Queensland AI Hub, a large investment supporting the development of the AI industry, creating more jobs and providing aspiring AI engineers with a space of their own to contribute to Australia’s innovation growth.
Nicholas Thomson is a Software Development Engineer with AWS Deep Learning. He helps build the open-source deep learning infrastructure projects that power Amazon AI. In his free time, he enjoys playing pool or building proof of concept websites.
Ragha Prasad is a software engineer on the AWS RoboMaker team. Primarily interested in robotics and artificial intelligence. In his spare time, he likes to travel, work on art projects and catch up on documentaries.
Sahika Genc is a senior applied scientist at Amazon artificial intelligence (AI). Her research interests are in smart automation, robotics, predictive control and optimization, and reinforcement learning (RL), and she serves in the industrial committee for the International Federation of Automatic Control. She leads science teams in scalable autonomous driving and automation systems, including consumer products such as AWS DeepRacer and SageMaker RL. Previously, she was a senior research scientist in the Artificial Intelligence and Learning Laboratory at the General Electric (GE) Global Research Center.