“Intelligent document processing (IDP) solutions extract data to support automation of high-volume, repetitive document processing tasks and for analysis and insight. IDP uses natural language technologies and computer vision to extract data from structured and unstructured content, especially from documents, to support automation and augmentation.” – Gartner
The goal of Amazon’s intelligent document processing (IDP) is to automate the processing of large amounts of documents using machine learning (ML) in order to increase productivity, reduce costs associated with human labor, and provide a seamless user experience. Customers spend a significant amount of time and effort identifying documents and extracting critical information from them for various use cases. Today, Amazon Comprehend supports classification for plain text documents, which requires you to preprocess documents in semi-structured formats (scanned, digital PDF or images such as PNG, JPG, TIFF) and then use the plain text output to run inference with your custom classification model. Similarly, for custom entity recognition in real time, preprocessing to extract text is required for semi-structured documents such as PDF and image files. This two-step process introduces complexities in document processing workflows.
Last year, we announced support for native document formats with custom named entity recognition (NER) asynchronous jobs. Today, we are excited to announce one-step document classification and real-time analysis for NER for semi-structured documents in native formats (PDF, TIFF, JPG, PNG) using Amazon Comprehend. Specifically, we are announcing the following capabilities:
- Support for documents in native formats for custom classification real-time analysis and asynchronous jobs
- Support for documents in native formats for custom entity recognition real-time analysis
With this new release, Amazon Comprehend custom classification and custom entity recognition (NER) supports documents in formats such as PDF, TIFF, PNG, and JPEG directly, without the need to extract UTF8 encoded plain text from them. The following figure compares the previous process to the new procedure and support.
This feature simplifies document processing workflows by eliminating any preprocessing steps required to extract plain text from documents, and reduces the overall time required to process them.
In this post, we discuss a high-level IDP workflow solution design, a few industry use cases, the new features of Amazon Comprehend, and how to use them.
Overview of solution
Let’s start by exploring a common use case in the insurance industry. A typical insurance claim process involves a claim package that may contain multiple documents. When an insurance claim is filed, it includes documents like insurance claim form, incident reports, identity documents, and third-party claim documents. The volume of documents to process and adjudicate an insurance claim can run up to hundreds and even thousands of pages depending on the type of claim and business processes involved. Insurance claim representatives and adjudicators typically spend hundreds of hours manually sifting, sorting, and extracting information from hundreds or even thousands of claim filings.
Similar to the insurance industry use case, the payment industry also processes large volumes of semi-structured documents for cross-border payment agreements, invoices, and forex statements. Business users spend the majority of their time on manual activities such as identifying, organizing, validating, extracting, and passing required information to downstream applications. This manual process is tedious, repetitive, error prone, expensive, and difficult to scale. Other industries that face similar challenges include mortgage and lending, healthcare and life sciences, legal, accounting, and tax management. It is extremely important for businesses to process such large volumes of documents in a timely manner with a high level of accuracy and nominal manual effort.
Amazon Comprehend provides key capabilities to automate document classification and information extraction from a large volume of documents with high accuracy, in a scalable and cost-effective way. The following diagram shows an IDP logical workflow with Amazon Comprehend. The core of the workflow consists of document classification and information extraction using NER with Amazon Comprehend custom models. The diagram also demonstrates how the custom models can be continuously improved to provide higher accuracies as documents and business processes evolve.
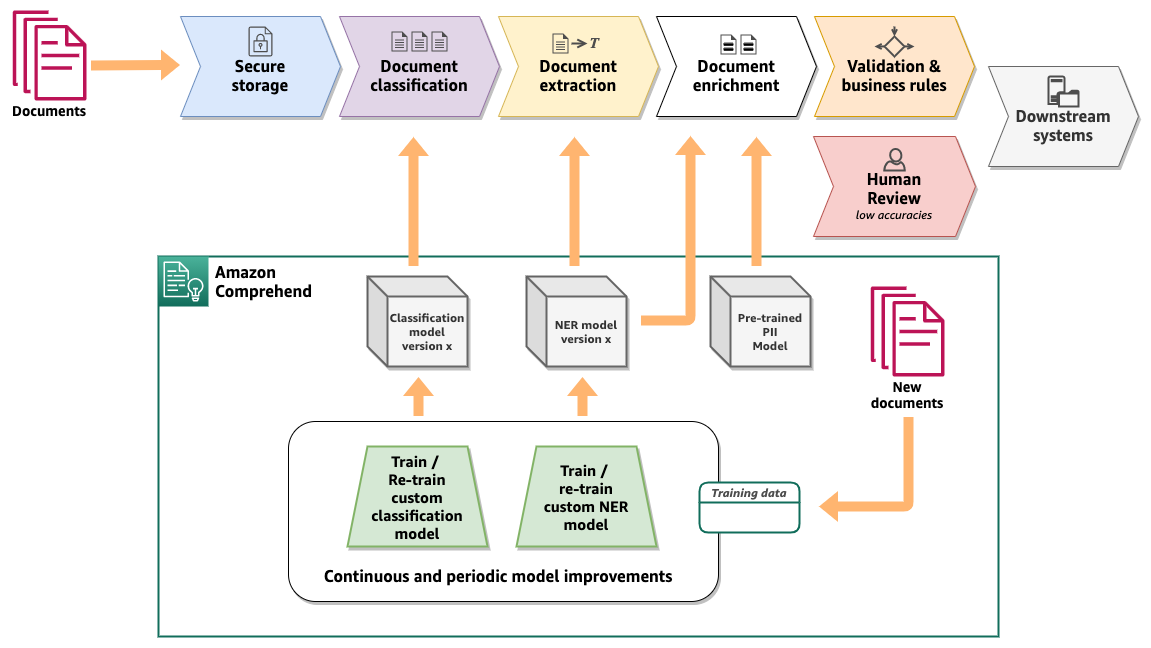
Custom document classification
With Amazon Comprehend custom classification, you can organize your documents into predefined categories (classes). At a high level, the following are the steps to set up a custom document classifier and perform document classification:
- Prepare training data to train a custom document classifier.
- Train a customer document classifier with the training data.
- After the model is trained, optionally deploy a real-time endpoint.
- Perform document classification with either an asynchronous job or in real time using the endpoint.
Steps 1 and 2 are typically done at the beginning of an IDP project after the document classes relevant to the business process are identified. A custom classifier model can then be periodically retrained to improve accuracy and introduce new document classes. You can train a custom classification model either in multi-class mode or multi-label mode. Training can be done for each in one of two ways: using a CSV file, or using an augmented manifest file. Refer to Preparing training data for more details on training a custom classification model. After a custom classifier model is trained, a document can be classified either using real-time analysis or an asynchronous job. Real-time analysis requires an endpoint to be deployed with the trained model and is best suited for small documents depending on the use case. For a large number of documents, an asynchronous classification job is best suited.
Train a custom document classification model
To demonstrate the new feature, we trained a custom classification model in multi-label mode, which can classify insurance documents into one of seven different classes. The classes are INSURANCE_ID, PASSPORT, LICENSE, INVOICE_RECEIPT, MEDICAL_TRANSCRIPTION, DISCHARGE_SUMMARY, and CMS1500. We want to classify sample documents in native PDF, PNG, and JPEG format, stored in an Amazon Simple Storage Service (Amazon S3) bucket, using the classification model. To start an asynchronous classification job, complete the following steps:
- On the Amazon Comprehend console, choose Analysis jobs in the navigation pane.
- Choose Create job.

- For Name, enter a name for your classification job.
- For Analysis type¸ choose Custom classification.
- For Classifier model, choose the appropriate trained classification model.
- For Version, choose the appropriate model version.

In the Input data section, we provide the location where our documents are stored.
- For Input format, choose One document per file.
- For Document read mode¸ choose Force document read action.
- For Document read action, choose Textract detect document text.
This enables Amazon Comprehend to use the Amazon Textract DetectDocumentText API to read the documents before running the classification. The DetectDocumentText API is helpful in extracting lines and words of text from the documents. You may also choose Textract analyze document for Document read action, in which case Amazon Comprehend uses the Amazon Textract AnalyzeDocument API to read the documents. With the AnalyzeDocument API, you can choose to extract Tables, Forms, or both. The Document read mode option enables Amazon Comprehend to extract the text from documents behind the scenes, which helps reduce the extra step of extracting text from the document, which is required in our document processing workflow.
The Amazon Comprehend custom classifier can also process raw JSON responses generated by the DetectDocumentText and AnalyzeDocument APIs, without any modification or preprocessing. This is useful for existing workflows where Amazon Textract is involved in extracting text from the documents already. In this case, the JSON output from Amazon Textract can be fed directly to the Amazon Comprehend document classification APIs.
- In the Output data section, for S3 location, specify an Amazon S3 location where you want the asynchronous job to write the results of the inference.
- Leave the remaining options as default.
- Choose Create job to start the job.

You can view the status of the job on the Analysis jobs page.
When the job is complete, we can view the output of the analysis job, which is stored in the Amazon S3 location provided during the job configuration. The classification output for our single-page PDF sample CMS1500 document is as follows. The output is a file in JSON lines format, which has been formatted to improve readability.
The preceding sample is a single-page PDF document; however, custom classification can also handle multi-page PDF documents. In the case of multi-page documents, the output contains multiple JSON lines, where each line is the classification result of each of the pages in a document. The following is a sample multi-page classification output:
Custom entity recognition
With an Amazon Comprehend custom entity recognizer, you can analyze documents and extract entities like product codes or business-specific entities that fit your particular needs. At a high level, the following are the steps to set up a custom entity recognizer and perform entity detection:
- Prepare training data to train a custom entity recognizer.
- Train a custom entity recognizer with the training data.
- After the model is trained, optionally deploy a real-time endpoint.
- Perform entity detection with either an asynchronous job or in real time using the endpoint.
A custom entity recognizer model can be periodically retrained to improve accuracy and to introduce new entity types. You can train a custom entity recognizer model with either entity lists or annotations. In both cases, Amazon Comprehend learns about the kind of documents and the context where the entities occur to build an entity recognizer model that can generalize to detect new entities. Refer to Preparing the training data to learn more about preparing training data for custom entity recognizer.
After a custom entity recognizer model is trained, entity detection can be done either using real-time analysis or an asynchronous job. Real-time analysis requires an endpoint to be deployed with the trained model and is best suited for small documents depending on the use case. For a large number of documents, an asynchronous classification job is best suited.
Train a custom entity recognition model
To demonstrate the entity detection in real time, we trained a custom entity recognizer model with insurance documents and augmented manifest files using custom annotations and deployed the endpoint using the trained model. The entity types are Law Firm, Law Office Address, Insurance Company, Insurance Company Address, Policy Holder Name, Beneficiary Name, Policy Number, Payout, Required Action, and Sender. We want to detect entities from sample documents in native PDF, PNG, and JPEG format, stored in an S3 bucket, using the recognizer model.
Note that you can use a custom entity recognition model that is trained with PDF documents to extract custom entities from PDF, TIFF, image, Word, and plain text documents. If your model is trained using text documents and an entity list, you can only use plain text documents to extract the entities.
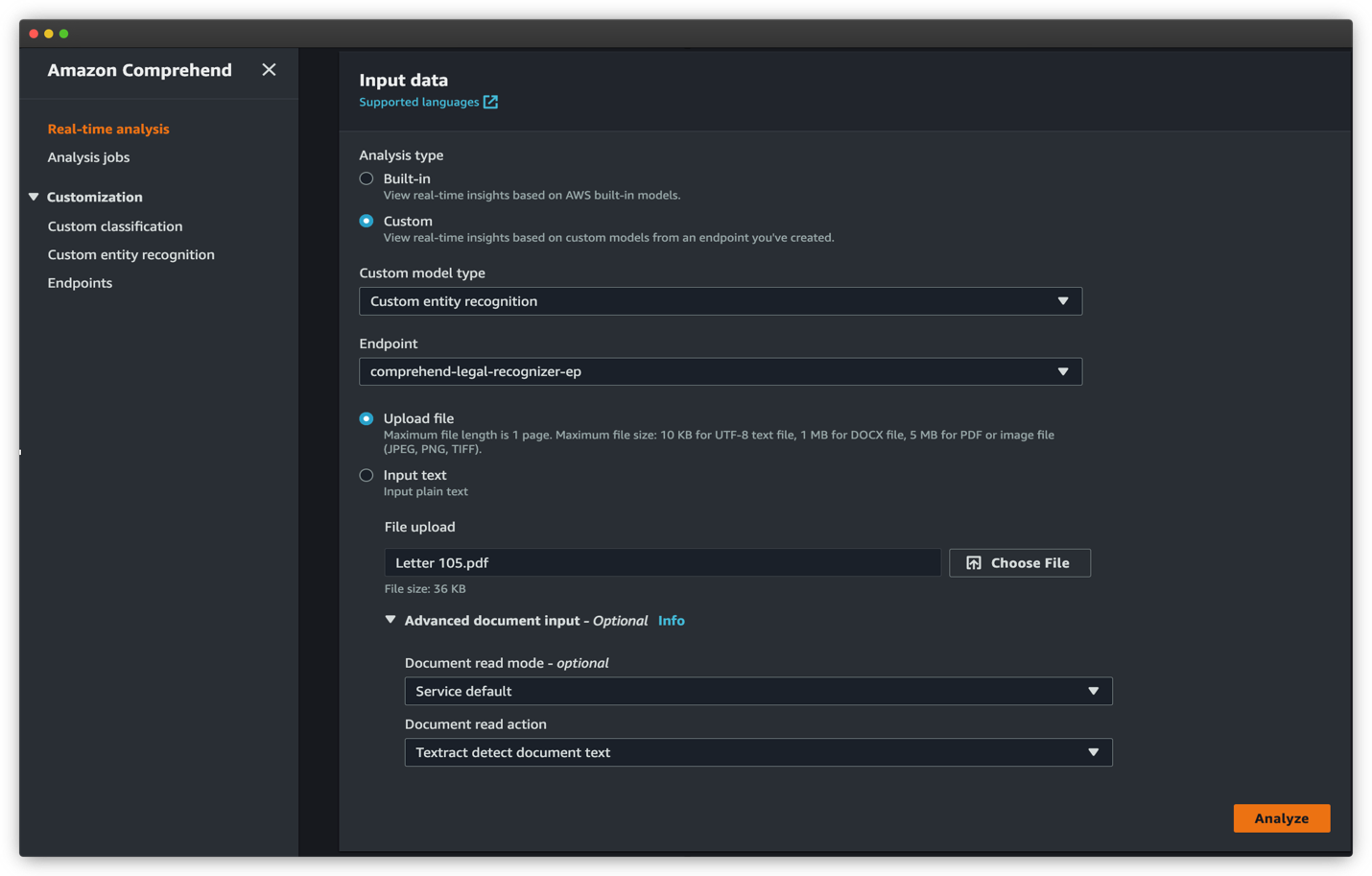
We need to detect entities from a sample document in any native PDF, PNG, and JPEG format using the recognizer model. To start a synchronous entity detection job, complete the following steps:
- On the Amazon Comprehend console, choose Real-time analysis in the navigation pane.
- Under Analysis type, select Custom.
- For Custom entity recognition, choose the custom model type.
- For Endpoint, choose the real-time endpoint that you created for your entity recognizer model.
- Select Upload file and choose Choose File to upload the PDF or image file for inference.
- Expand the Advanced document input section and for Document read mode, choose Service default.
- For Document read action, choose Textract detect document text.
- Choose Analyze to analyze the document in real time.
The recognized entities are listed in the Insights section. Each entity contains the entity value (the text), the type of entity as defined by your during the training process, and the corresponding confidence score.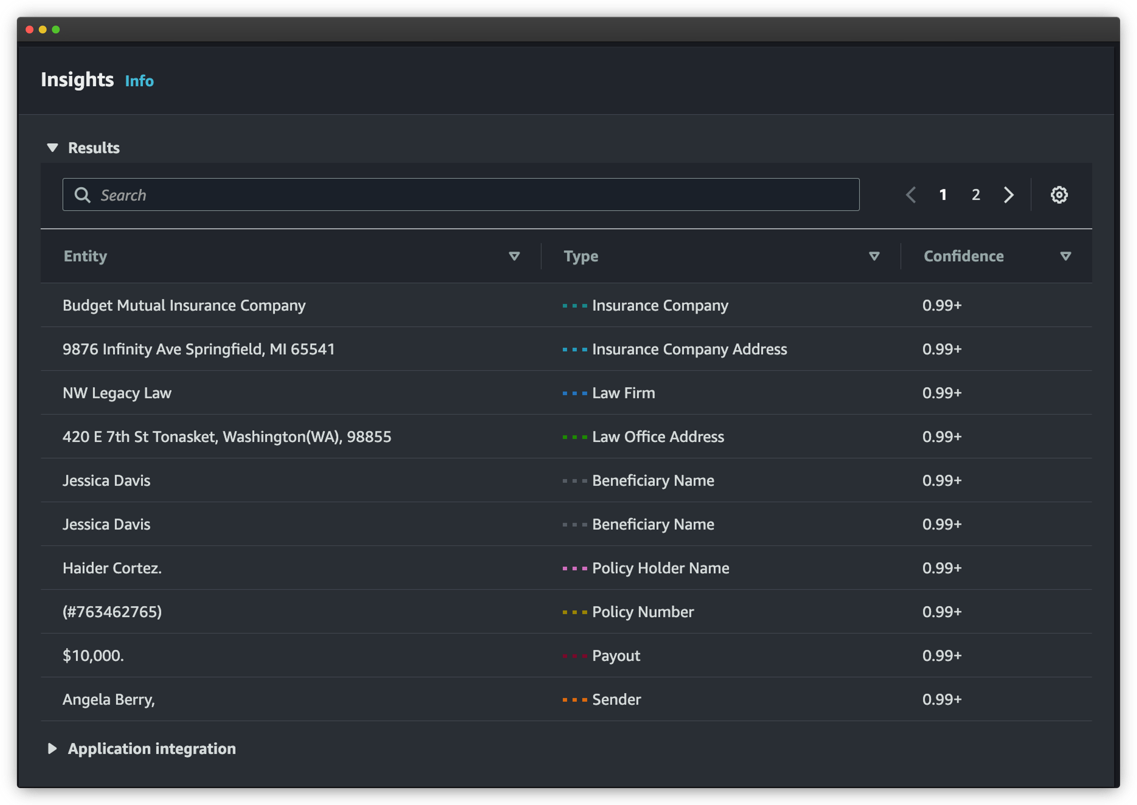
For more details and a complete walkthrough on how to train a custom entity recognizer model and use it to perform asynchronous inference using asynchronous analysis jobs, refer to Extract custom entities from documents in their native format with Amazon Comprehend.
Conclusion
This post demonstrated how you can classify and categorize semi-structured documents in their native format and detect business-specific entities from them using Amazon Comprehend. You can use real-time APIs for low-latency use cases, or use asynchronous analysis jobs for bulk document processing.
As a next step, we encourage you to visit the Amazon Comprehend GitHub repository for full code samples to try out these new features. You can also visit the Amazon Comprehend Developer Guide and Amazon Comprehend developer resources for videos, tutorials, blogs, and more.
About the authors
 Wrick Talukdar is a Senior Architect with the Amazon Comprehend Service team. He works with AWS customers to help them adopt machine learning on a large scale. Outside of work, he enjoys reading and photography.
Wrick Talukdar is a Senior Architect with the Amazon Comprehend Service team. He works with AWS customers to help them adopt machine learning on a large scale. Outside of work, he enjoys reading and photography.
 Anjan Biswas is a Senior AI Services Solutions Architect with a focus on AI/ML and Data Analytics. Anjan is part of the world-wide AI services team and works with customers to help them understand and develop solutions to business problems with AI and ML. Anjan has over 14 years of experience working with global supply chain, manufacturing, and retail organizations, and is actively helping customers get started and scale on AWS AI services.
Anjan Biswas is a Senior AI Services Solutions Architect with a focus on AI/ML and Data Analytics. Anjan is part of the world-wide AI services team and works with customers to help them understand and develop solutions to business problems with AI and ML. Anjan has over 14 years of experience working with global supply chain, manufacturing, and retail organizations, and is actively helping customers get started and scale on AWS AI services.
 Godwin Sahayaraj Vincent is an Enterprise Solutions Architect at AWS who is passionate about machine learning and providing guidance to customers to design, deploy, and manage their AWS workloads and architectures. In his spare time, he loves to play cricket with his friends and tennis with his three kids.
Godwin Sahayaraj Vincent is an Enterprise Solutions Architect at AWS who is passionate about machine learning and providing guidance to customers to design, deploy, and manage their AWS workloads and architectures. In his spare time, he loves to play cricket with his friends and tennis with his three kids.