Neural networks can perform certain tasks remarkably well, but understanding how they reach their decisions — e.g., identifying which signals in an image cause a model to determine it to be of one class and not another — is often a mystery. Explaining a neural model’s decision process may have high social impact in certain areas, such as analysis of medical images and autonomous driving, where human oversight is critical. These insights can also be helpful in guiding health care providers, revealing model biases, providing support for downstream decision makers, and even aiding scientific discovery.
Previous approaches for visual explanations of classifiers, such as attention maps (e.g., Grad-CAM), highlight which regions in an image affect the classification, but they do not explain what attributes within those regions determine the classification outcome: For example, is it their color? Their shape? Another family of methods provides an explanation by smoothly transforming the image between one class and another (e.g., GANalyze). However, these methods tend to change all attributes at once, thus making it difficult to isolate the individual affecting attributes.
In “Explaining in Style: Training a GAN to explain a classifier in StyleSpace”, presented at ICCV 2021, we propose a new approach for a visual explanation of classifiers. Our approach, StylEx, automatically discovers and visualizes disentangled attributes that affect a classifier. It allows exploring the effect of individual attributes by manipulating those attributes separately (changing one attribute does not affect others). StylEx is applicable to a wide range of domains, including animals, leaves, faces, and retinal images. Our results show that StylEx finds attributes that align well with semantic ones, generate meaningful image-specific explanations, and are interpretable by people as measured in user studies.
 |
| Explaining a Cat vs. Dog Classifier: StylEx provides the top-K discovered disentangled attributes which explain the classification. Moving each knob manipulates only the corresponding attribute in the image, keeping other attributes of the subject fixed. |
For instance, to understand a cat vs. dog classifier on a given image, StylEx can automatically detect disentangled attributes and visualize how manipulating each attribute can affect the classifier probability. The user can then view these attributes and make semantic interpretations for what they represent. For example, in the figure above, one can draw conclusions such as “dogs are more likely to have their mouth open than cats” (attribute #4 in the GIF above), “cats’ pupils are more slit-like” (attribute #5), “cats’ ears do not tend to be folded” (attribute #1), and so on.
The video below provides a short explanation of the method:
How StylEx Works: Training StyleGAN to Explain a Classifier
Given a classifier and an input image, we want to find and visualize the individual attributes that affect its classification. For that, we utilize the StyleGAN2 architecture, which is known to generate high quality images. Our method consists of two phases:
Phase 1: Training StylEx
A recent work showed that StyleGAN2 contains a disentangled latent space called “StyleSpace”, which contains individual semantically meaningful attributes of the images in the training dataset. However, because StyleGAN training is not dependent on the classifier, it may not represent those attributes that are important for the decision of the specific classifier we want to explain. Therefore, we train a StyleGAN-like generator to satisfy the classifier, thus encouraging its StyleSpace to accommodate classifier-specific attributes.
This is achieved by training the StyleGAN generator with two additional components. The first is an encoder, trained together with the GAN with a reconstruction-loss, which forces the generated output image to be visually similar to the input. This allows us to apply the generator on any given input image. However, visual similarity of the image is not enough, as it may not necessarily capture subtle visual details important for a particular classifier (such as medical pathologies). To ensure this, we add a classification-loss to the StyleGAN training, which forces the classifier probability of the generated image to be the same as the classifier probability of the input image. This guarantees that subtle visual details important for the classifier (such as medical pathologies) will be included in the generated image.
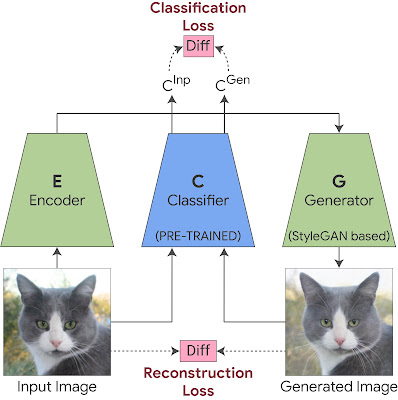 |
| Training StyleEx: We jointly train the generator and the encoder. A reconstruction-loss is applied between the generated image and the original image to preserve visual similarity. A classification-loss is applied between the classifier output of the generated image and the classifier output of the original image to ensure the generator captures subtle visual details important for the classification. |
Phase 2: Extracting Disentangled Attributes
Once trained, we search the StyleSpace of the trained Generator for attributes that significantly affect the classifier. To do so, we manipulate each StyleSpace coordinate and measure its effect on the classification probability. We seek the top attributes that maximize the change in classification probability for the given image. This provides the top-K image-specific attributes. By repeating this process for a large number of images per class, we can further discover the top-K class-specific attributes, which teaches us what the classifier has learned about the specific class. We call our end-to-end system “StylEx”.
A visual illustration of image-specific attribute extraction: once trained, we search for the StyleSpace coordinates that have the highest effect on the classification probability of a given image.

StylEx is Applicable to a Wide Range of Domains and Classifiers
Our method works on a wide variety of domains and classifiers (binary and multi-class). Below are some examples of class-specific explanations. In all the domains tested, the top attributes detected by our method correspond to coherent semantic notions when interpreted by humans, as verified by human evaluation.
For perceived gender and age classifiers, below are the top four detected attributes per classifier. Our method exemplifies each attribute on multiple images that are automatically selected to best demonstrate that attribute. For each attribute we flicker between the source and attribute-manipulated image. The degree to which manipulating the attribute affects the classifier probability is shown at the top-left corner of each image.
 |
| Top-4 automatically detected attributes for a perceived-gender classifier. |
 |
| Top-4 automatically detected attributes for a perceived-age classifier. |
Note that our method explains a classifier, not reality. That is, the method is designed to reveal image attributes that a given classifier has learned to utilize from data; those attributes may not necessarily characterize actual physical differences between class labels (e.g., a younger or older age) in reality. In particular, these detected attributes may reveal biases in the classifier training or dataset, which is another key benefit of our method. It can further be used to improve fairness of neural networks, for example, by augmenting the training dataset with examples that compensate for the biases our method reveals.
Adding the classifier loss into StyleGAN training turns out to be crucial in domains where the classification depends on fine details. For example, a GAN trained on retinal images without a classifier loss will not necessarily generate fine pathological details corresponding to a particular disease. Adding the classification loss causes the GAN to generate these subtle pathologies as an explanation of the classifier. This is exemplified below for a retinal image classifier (DME disease) and a sick/healthy leaf classifier. StylEx is able to discover attributes that are aligned with disease indicators, for instance “hard exudates”, which is a well known marker for retinal DME, and rot for leaf diseases.
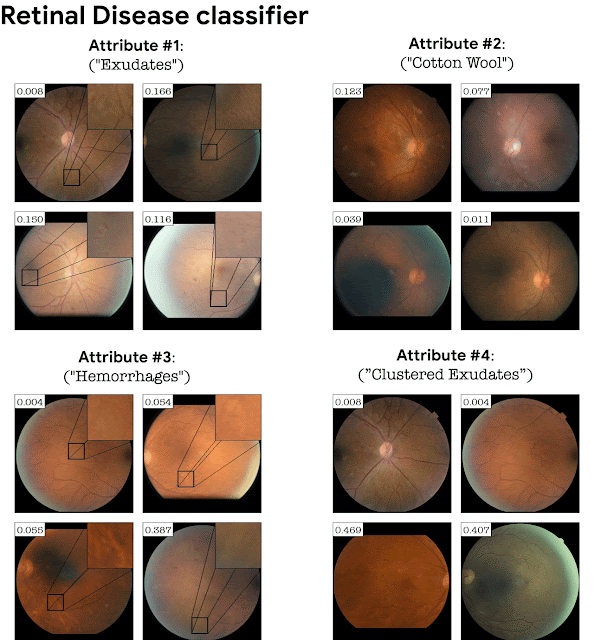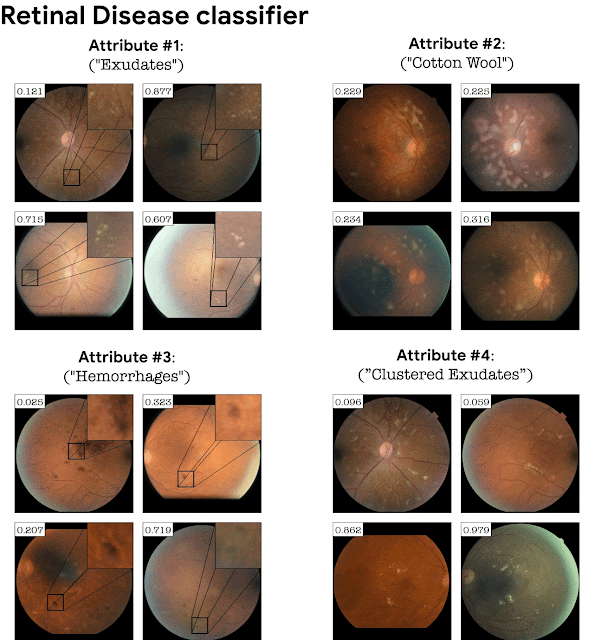 |
| Top-4 automatically detected attributes for a DME classifier of retina images. |
 |
| Top-4 automatically detected attributes for a classifier of sick/healthy leaf images. |
Finally, this method is also applicable to multi-class problems, as demonstrated on a 200-way bird species classifier.
 |
| Top-4 automatically detected attributes in a 200-way classifier trained on CUB-2011 for (a) the class “brewer blackbird”, and (b) the class “yellow bellied flycatcher”. Indeed we observe that StylEx detects attributes that correspond to attributes in CUB taxonomy. |
Broader Impact and Next Steps
Overall, we have introduced a new technique that enables the generation of meaningful explanations for a given classifier on a given image or class. We believe that our technique is a promising step towards detection and mitigation of previously unknown biases in classifiers and/or datasets, in line with Google’s AI Principles. Additionally, our focus on multiple-attribute based explanation is key to providing new insights about previously opaque classification processes and aiding in the process of scientific discovery. Finally, our GitHub repository includes a Colab and model weights for the GANs used in our paper.
Acknowledgements
The research described in this post was done by Oran Lang, Yossi Gandelsman, Michal Yarom, Yoav Wald (as an intern), Gal Elidan, Avinatan Hassidim, William T. Freeman, Phillip Isola, Amir Globerson, Michal Irani and Inbar Mosseri. We would like to thank Jenny Huang and Marilyn Zhang for leading the writing process for this blogpost, and Reena Jana, Paul Nicholas, and Johnny Soraker for ethics reviews of our research paper and this post.
