Data lakes have become the norm in the industry for storing critical business data. The primary rationale for a data lake is to land all types of data, from raw data to preprocessed and postprocessed data, and may include both structured and unstructured data formats. Having a centralized data store for all types of data allows modern big data applications to load, transform, and process whatever type of data is needed. Benefits include storing data as is without the need to first structure or transform it. Most importantly, data lakes allow controlled access to data from many different types of analytics and machine learning (ML) processes in order to guide better decision-making.
Multiple vendors have created data lake architectures, including AWS Lake Formation. In addition, open-source solutions allow companies to access, load, and share data easily. One of the options for storing data in the AWS Cloud is Delta Lake. The Delta Lake library enables reads and writes in open-source Apache Parquet file format, and provides capabilities like ACID transactions, scalable metadata handling, and unified streaming and batch data processing. Delta Lake offers a storage layer API that you can use to store data on top of an object-layer storage like Amazon Simple Storage Service (Amazon S3).
Data is at the heart of ML—training a traditional supervised model is impossible without access to high-quality historical data, which is commonly stored in a data lake. Amazon SageMaker is a fully managed service that provides a versatile workbench for building ML solutions and provides highly tailored tooling for data ingestion, data processing, model training, and model hosting. Apache Spark is a workhorse of modern data processing with an extensive API for loading and manipulating data. SageMaker has the ability to prepare data at petabyte scale using Spark to enable ML workflows that run in a highly distributed manner. This post highlights how you can take advantage of the capabilities offered by Delta Lake using Amazon SageMaker Studio.
Solution overview
In this post, we describe how to use SageMaker Studio notebooks to easily load and transform data stored in the Delta Lake format. We use a standard Jupyter notebook to run Apache Spark commands that read and write table data in CSV and Parquet format. The open-source library delta-spark allows you to directly access this data in its native format. This library allows you to take advantage of the many API operations to apply data transformations, make schema modifications, and use time-travel or as-of-timestamp queries to pull a particular version of the data.
In our sample notebook, we load raw data into a Spark DataFrame, create a Delta table, query it, display audit history, demonstrate schema evolution, and show various methods for updating the table data. We use the DataFrame API from the PySpark library to ingest and transform the dataset attributes. We use the delta-spark library to read and write data in Delta Lake format and to manipulate the underlying table structure, referred to as the schema.
We use SageMaker Studio, the built-in IDE from SageMaker, to create and run Python code from a Jupyter notebook. We have created a GitHub repository that contains this notebook and other resources to run this sample on your own. The notebook demonstrates exactly how to interact with data stored in Delta Lake format, which permits tables to be accessed in-place without the need to replicate data across disparate datastores.
For this example, we use a publicly available dataset from Lending Club that represents customer loans data. We downloaded the accepted data file (accepted_2007_to_2018Q4.csv.gz), and selected a subset of the original attributes. This dataset is available under the Creative Commons (CCO) License.
Prerequisites
You must install a few prerequisites prior to using the delta-spark functionality. To satisfy required dependencies, we have to install some libraries into our Studio environment, which runs as a Dockerized container and is accessed via a Jupyter Gateway app:
- OpenJDK for access to Java and associated libraries
- PySpark (Spark for Python) library
- Delta Spark open-source library
We can use either conda or pip to install these libraries, which are publicly available in either conda-forge, PyPI servers, or Maven repositories.
This notebook is designed to run within SageMaker Studio. After you launch the notebook within Studio, make sure you choose the Python 3(Data Science) kernel type. Additionally, we suggest using an instance type with at least 16 GB of RAM (like ml.g4dn.xlarge), which allows PySpark commands to run faster. Use the following commands to install the required dependencies, which make up the first several cells of the notebook:
After the installation commands are complete, we’re ready to run the core logic in the notebook.
Implement the solution
To run Apache Spark commands, we need to instantiate a SparkSession object. After we include the necessary import commands, we configure the SparkSession by setting some additional configuration parameters. The parameter with key spark.jars.packages passes the names of additional libraries used by Spark to run delta commands. The following initial lines of code assemble a list of packages, using traditional Maven coordinates (groupId:artifactId:version), to pass these additional packages to the SparkSession.
Additionally, the parameters with key spark.sql.extensions and spark.sql.catalog.spark_catalog enable Spark to properly handle Delta Lake functionality. The final configuration parameter with key fs.s3a.aws.credentials.provider adds the ContainerCredentialsProvider class, which allows Studio to look up the AWS Identity and Access Management (IAM) role permissions made available via the container environment. The code creates a SparkSession object that is properly initialized for the SageMaker Studio environment:
In the next section, we upload a file containing a subset of the Lending Club consumer loans dataset to our default S3 bucket. The original dataset is very large (over 600 MB), so we provide a single representative file (2.6 MB) for use by this notebook. PySpark uses the s3a protocol to enable additional Hadoop library functionality. Therefore, we modify each native S3 URI from the s3 protocol to use s3a in the cells throughout this notebook.
We use Spark to read in the raw data (with options for both CSV or Parquet files) with the following code, which returns a Spark DataFrame named loans_df:
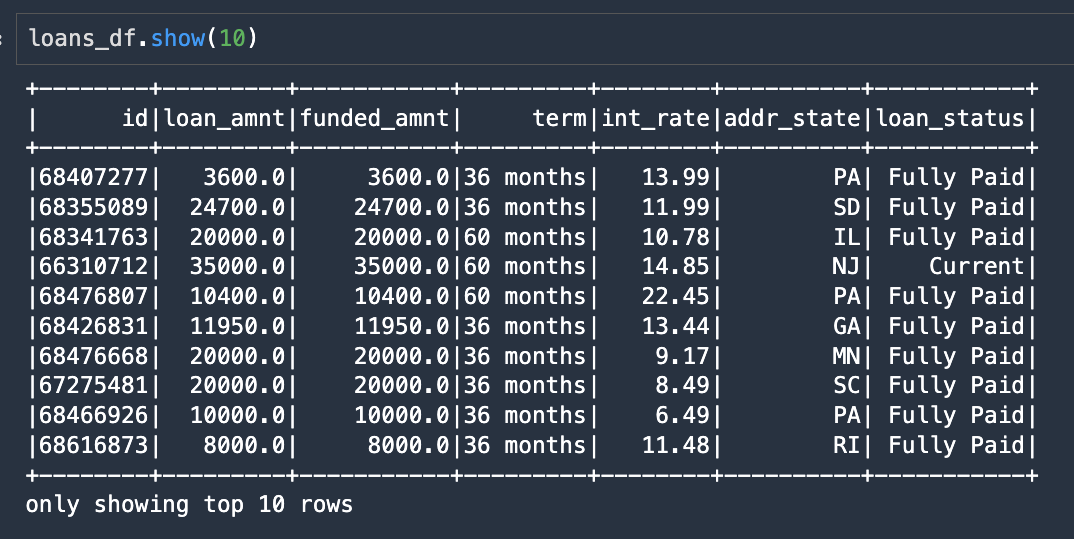
The following screenshot shows the first 10 rows from the resulting DataFrame.
We can now write out this DataFrame as a Delta Lake table with a single line of code by specifying .format("delta") and providing the S3 URI location where we want to write the table data:
The next few notebook cells show an option for querying the Delta Lake table. We can construct a standard SQL query, specify delta format and the table location, and submit this command using Spark SQL syntax:
The following screenshot shows the results of our SQL query as ordered by loan_amnt.

Interact with Delta Lake tables
In this section, we showcase the DeltaTable class from the delta-spark library. DeltaTable is the primary class for programmatically interacting with Delta Lake tables. This class includes several static methods for discovering information about a table. For example, the isDeltaTable method returns a Boolean value indicating whether the table is stored in delta format:
You can create DeltaTable instances using the path of the Delta table, which in our case is the S3 URI location. In the following code, we retrieve the complete history of table modifications:
The output indicates the table has six modifications stored in the history, and shows the latest three versions.

Schema evolution
In this section, we demonstrate how Delta Lake schema evolution works. By default, delta-spark forces table writes to abide by the existing schema by enforcing constraints. However, by specifying certain options, we can safely modify the schema of the table.
First, let’s read data back in from the Delta table. Because this data was written out as delta format, we need to specify .format("delta") when reading the data, then we provide the S3 URI where the Delta table is located. Second, we write the DataFrame back out to a different S3 location where we demonstrate schema evolution. See the following code:
Now we use the Spark DataFrame API to add two new columns to our dataset. The column names are funding_type and excess_int_rate, and the column values are set to constants using the DataFrame withColumn method. See the following code:
A quick look at the data types (dtypes) shows the additional columns are part of the DataFrame.

Now we enable the schema modification, thereby changing the underlying schema of the Delta table, by setting the mergeSchema option to true in the following Spark write command:
Let’s check the modification history of our new table, which shows that the table schema has been modified:
The history listing shows each revision to the metadata.

Conditional table updates
You can use the DeltaTable update method to run a predicate and then apply a transform whenever the condition evaluates to True. In our case, we write the value FullyFunded to the funding_type column whenever the loan_amnt equals the funded_amnt. This is a powerful mechanism for writing conditional updates to your table data.
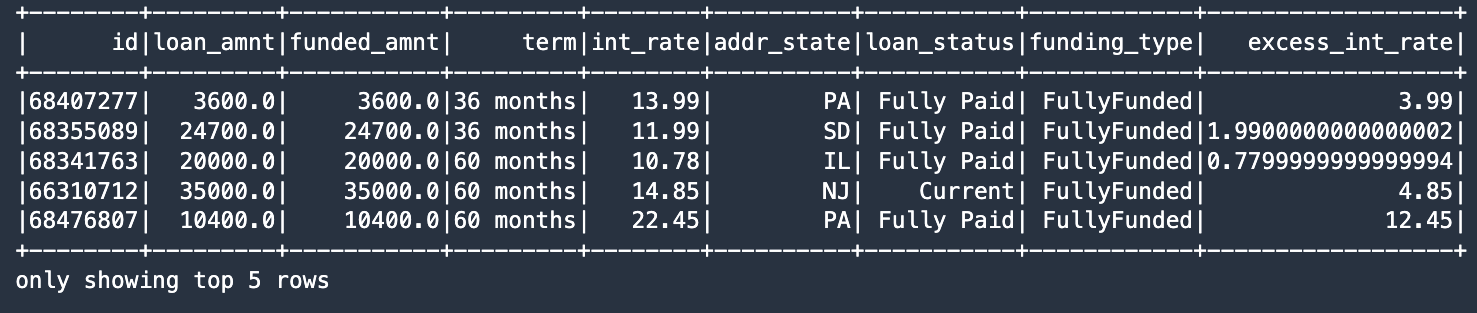
The following screenshot shows our results.

In the final change to the table data, we show the syntax to pass a function to the update method, which in our case calculates the excess interest rate by subtracting 10.0% from the loan’s int_rate attribute. One more SQL command pulls records that meet our condition, using the WHERE clause to locate records with int_rate greater than 10.0%:
The new excess_int_rate column now correctly contains the int_rate minus 10.0%.
Our last notebook cell retrieves the history from the Delta table again, this time showing the modifications after the schema modification has been performed:
The following screenshot shows our results.

Conclusion
You can use SageMaker Studio notebooks to interact directly with data stored in the open-source Delta Lake format. In this post, we provided sample code that reads and writes this data using the open source delta-spark library, which allows you to create, update, and manage the dataset as a Delta table. We also demonstrated the power of combining these critical technologies to extract value from preexisting data lakes, and showed how to use the capabilities of Delta Lake on SageMaker.
Our notebook sample provides an end-to-end recipe for installing prerequisites, instantiating Spark data structures, reading and writing DataFrames in Delta Lake format, and using functionalities like schema evolution. You can integrate these technologies to magnify their power to provide transformative business outcomes.
About the Authors
 Paul Hargis has focused his efforts on Machine Learning at several companies, including AWS, Amazon, and Hortonworks. He enjoys building technology solutions and also teaching people how to make the most of it. Prior to his role at AWS, he was lead architect for Amazon Exports and Expansions helping amazon.com improve experience for international shoppers. Paul likes to help customers expand their machine learning initiatives to solve real-world problems.
Paul Hargis has focused his efforts on Machine Learning at several companies, including AWS, Amazon, and Hortonworks. He enjoys building technology solutions and also teaching people how to make the most of it. Prior to his role at AWS, he was lead architect for Amazon Exports and Expansions helping amazon.com improve experience for international shoppers. Paul likes to help customers expand their machine learning initiatives to solve real-world problems.
 Vedant Jain is a Sr. AI/ML Specialist Solutions Architect, helping customers derive value out of the Machine Learning ecosystem at AWS. Prior to joining AWS, Vedant has held ML/Data Science Specialty positions at various companies such as Databricks, Hortonworks (now Cloudera) & JP Morgan Chase. Outside of his work, Vedant is passionate about making music, using Science to lead a meaningful life & exploring delicious vegetarian cuisine from around the world.
Vedant Jain is a Sr. AI/ML Specialist Solutions Architect, helping customers derive value out of the Machine Learning ecosystem at AWS. Prior to joining AWS, Vedant has held ML/Data Science Specialty positions at various companies such as Databricks, Hortonworks (now Cloudera) & JP Morgan Chase. Outside of his work, Vedant is passionate about making music, using Science to lead a meaningful life & exploring delicious vegetarian cuisine from around the world.