We recently published a new whitepaper, Machine Learning Best Practices in Financial Services, that outlines security and model governance considerations for financial institutions building machine learning (ML) workflows. The whitepaper discusses common security and compliance considerations and aims to accompany a hands-on demo and workshop that walks you through an end-to-end example. Although the whitepaper focuses on financial services considerations, much of the information around authentication and access management, data and model security, and ML operationalization (MLOps) best practices may be applicable to other regulated industries, such as healthcare.
A typical ML workflow, as shown in the following diagram, involves multiple stakeholders. To successfully govern and operationalize this workflow, you should collaborate across multiple teams, including business stakeholders, sysops administrators, data engineers, and software and devops engineers.
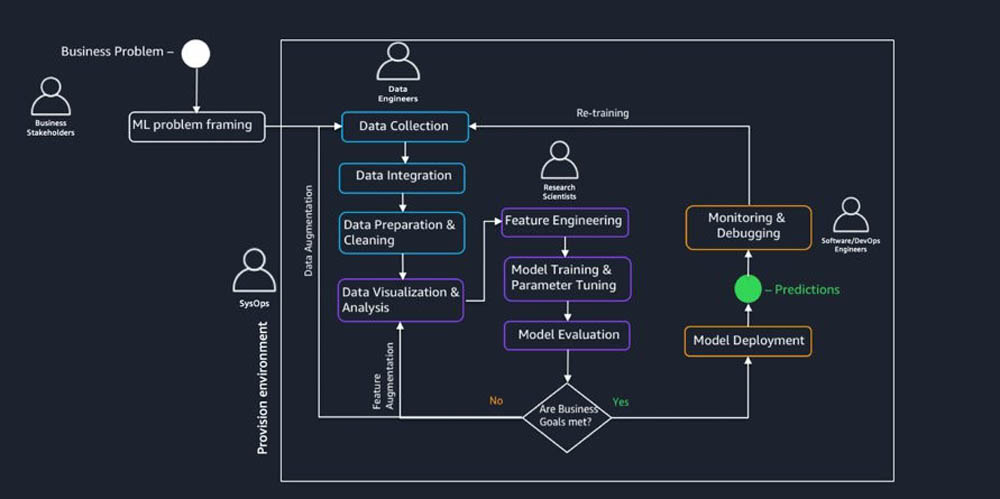
In the whitepaper, we discuss considerations for each team and also provide examples and illustrations of how you can use Amazon SageMaker and other AWS services to build, train, and deploy ML workloads. More specifically, based on feedback from customers running workloads in regulated environments, we cover the following topics:
- Provisioning a secure ML environment – This includes the following:
- Compute and network isolation – How to deploy Amazon SageMaker in a customer’s private network, with no internet connectivity.
- Authentication and authorization – How to authenticate users in a controlled fashion and authorize these users based on their AWS Identity and Access Management (IAM) permissions, with no multi-tenancy.
- Data protection – How to encrypt data in transit and at rest with customer-provided encryption keys.
- Auditability – How to audit, prevent, and detect who did what at any given point in time to help identify and protect against malicious activities.
- Establishing ML governance – This includes the following:
- Traceability – Methods to trace ML model lineage from data preparation, model development, and training iterations, and how to audit who did what at any given point in time.
- Explainability and interpretability –Methods that may help explain and interpret the trained model and obtain feature importance.
- Model monitoring – How to monitor your model in production to protect against data drift, and automatically react to rules that you define.
- Reproducibility – How to reproduce the ML model based on model lineage and the stored artifacts.
- Operationalizing ML workloads – This includes the following:
- Model development workload – How to build automated and manual review processes in the dev environment.
- Preproduction workload – How to build automated CI/CD pipelines using the AWS CodeStar suite and AWS Step Functions.
- Production and continuous monitoring workload – How to combine continuous deployment and automated model monitoring.
- Tracking and alerting – How to track model metrics (operational and statistical) and alert appropriate users if anomalies are detected.
Provisioning a secure ML environment
A well-governed and secure ML workflow begins with establishing a private and isolated compute and network environment. This may be especially important in regulated industries, particularly when dealing with PII data for model building or training. The Amazon Virtual Private Cloud (VPC) that hosts Amazon SageMaker and its associated components, such as Jupyter notebooks, training instances, and hosting instances, should be deployed in a private network with no internet connectivity.
Furthermore, you can associate these Amazon SageMaker resources with your VPC environment, which allows you to apply network-level controls, such as security groups to govern access to Amazon SageMaker resources and control ingress and egress of data into and out of the environment. You can establish connectivity between Amazon SageMaker and other AWS services, such as Amazon Simple Storage Service (Amazon S3), using VPC endpoints or AWS PrivateLink. The following diagram illustrates a suggested reference architecture of a secure Amazon SageMaker deployment.

The next step is to ensure that only authorized users can access the appropriate AWS services. IAM can help you create preventive controls for many aspects of your ML environment, including access to Amazon SageMaker resources, your data in Amazon S3, and API endpoints. You can access AWS services using a RESTful API, and every API call is authorized by IAM. You grant explicit permissions through IAM policy documents, which specify the principal (who), the actions (API calls), and the resources (such as Amazon S3 objects) that are allowed, as well as the conditions under which the access is granted. For a deeper dive into building secure environments for financial services as well as other well-architected pillars, also refer to this whitepaper.
In addition, as ML environments may contain sensitive data and intellectual property, the third consideration for a secure ML environment is data encryption. We recommend that you enable data encryption both at rest and in transit with your own encryption keys. And lastly, another consideration for a well-governed and secure ML environment is a robust and transparent audit trail that logs all access and changes to the data and models, such as a change in the model configuration or the hyperparameters. More details on all those fronts are included in the whitepaper.
To enable self-service provisioning and automation, administrators can use tools such as the AWS Service Catalog to create these secure environments in a repeatable manner for their data scientists. This way, data scientists can simply log in to a secure portal using AWS Single Sign-On, and create a secure Jupyter notebook environment provisioned for their use with appropriate security guardrails in place.
Establishing ML governance
In this section of the whitepaper, we discuss the considerations around ML governance, which includes four key aspects: traceability, explainability, real-time model monitoring, and reproducibility. The financial services industry has various compliance and regulatory obligations that may touch on these aspects of ML governance. You should review and understand those obligations with your legal counsel, compliance personnel, and other stakeholders involved in the ML process.
As an example, if Jane Smith is denied a bank loan, the lender may be required to explain how that decision was made in order to comply with regulatory requirements. If the financial services industry customer is using ML as part of the loan review process, the prediction made by the ML model may need to be interpreted or explained in order to meet these requirements. Generally, an ML model’s interpretability or explainability refers to people’s ability to understand and explain the processes that the model uses to arrive at its predictions. It is also important to note that many ML models make predictions of a likely answer, rather than the answer itself. Therefore, it may be appropriate to have human review of predictions made by ML models before any action is taken. The model may also need to be monitored, so that if the underlying data changes, the model is periodically retrained on new data. Finally, the ML model may need to be reproducible, such that if the steps leading to the model’s output are retraced, the model outputs don’t change.
Operationalizing ML workloads
In the final section, we discuss some best practices around operationalizing ML workloads. We begin with a high-level discussion and then dive deeper into a specific architecture that uses AWS native tools and services. In addition to the process of deploying models, or what in traditional software deployments is referred to as CI/CD (continuous integration/deployment), deploying ML models into production for regulated industries may have additional implications from an implementation perspective.
The following diagram captures some of the high-level requirements that an enterprise ML platform might have to address guidelines around governance, auditing, logging, and reporting:
- A data lake for managing raw data and associated metadata
- A feature store for managing ML features and associated metadata (mapping from raw data to generated features such as one-hot encodings or scaling transformations)
- A model and container registry containing trained model artifacts and associated metadata (such as hyperparameters, training times, and dependencies)
- A code repository (such as Git, AWS CodeCommit, or Artifactory) for maintaining and versioning source code
- A pipeline registry to version and maintain training and deployment pipelines
- Logging tools for maintaining access logs
- Production monitoring and performance logs
- Tools for auditing and reporting

The following diagram illustrates a specific implementation that uses AWS native tools and services. Although several scheduling and orchestration tools are on the market, such as Airflow or Jenkins, for concreteness, we focus predominantly on Step Functions.
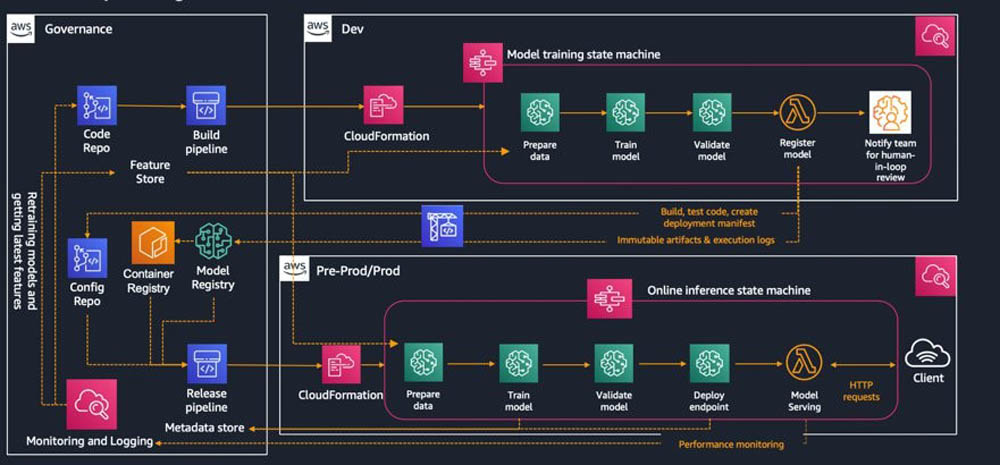
In the whitepaper, we dive deeper into each part of the preceding diagram, and more specifically into the following workloads:
- Model development
- Pre-production
- Production and continuous monitoring
Summary
The Machine Learning Best Practices in Financial Services whitepaper is available here. Start using it today to help illustrate how you can build secure and well-governed ML workflows and feel free to reach out to the authors if you have any questions. As you progress on your journey, also refer to this whitepaper for a lens on the AWS well-architected principles applied to machine learning workloads. You can also use the video demo walkthrough, and the following two workshops:
- Build a secure ML environment with SageMaker
- Provision a secure ML environment with SageMaker and run an end-to-end example
About the authors
 Stefan Natu is a Sr. Machine Learning Specialist at Amazon Web Services. He is focused on helping financial services customers build and operationalize end-to-end machine learning solutions on AWS. His academic background is in theoretical physics, and in the past, he worked on a number of data science problems in retail and energy verticals. In his spare time, he enjoys reading machine learning blogs, traveling, playing the guitar, and exploring the food scene in New York City.
Stefan Natu is a Sr. Machine Learning Specialist at Amazon Web Services. He is focused on helping financial services customers build and operationalize end-to-end machine learning solutions on AWS. His academic background is in theoretical physics, and in the past, he worked on a number of data science problems in retail and energy verticals. In his spare time, he enjoys reading machine learning blogs, traveling, playing the guitar, and exploring the food scene in New York City.
 Kosti Vasilakakis is a Sr. Business Development Manager for Amazon SageMaker, the AWS fully managed service for end-to-end machine learning, and he focuses on helping financial services and technology companies achieve more with ML. He spearheads curated workshops, hands-on guidance sessions, and pre-packaged open-source solutions to ensure that customers build better ML models quicker and safer. Outside of work, he enjoys traveling the world, philosophizing, and playing tennis.
Kosti Vasilakakis is a Sr. Business Development Manager for Amazon SageMaker, the AWS fully managed service for end-to-end machine learning, and he focuses on helping financial services and technology companies achieve more with ML. He spearheads curated workshops, hands-on guidance sessions, and pre-packaged open-source solutions to ensure that customers build better ML models quicker and safer. Outside of work, he enjoys traveling the world, philosophizing, and playing tennis.
 Alvin Huang is a Capital Markets Specialist for Worldwide Financial Services Business Development at Amazon Web Services with a focus on data lakes and analytics, and artificial intelligence and machine learning. Alvin has over 19 years of experience in the financial services industry, and prior to joining AWS, he was an Executive Director at J.P. Morgan Chase & Co, where he managed the North America and Latin America trade surveillance teams and led the development of global trade surveillance. Alvin also teaches a Quantitative Risk Management course at Rutgers University and serves on the Rutgers Mathematical Finance Master’s program (MSMF) Advisory Board.
Alvin Huang is a Capital Markets Specialist for Worldwide Financial Services Business Development at Amazon Web Services with a focus on data lakes and analytics, and artificial intelligence and machine learning. Alvin has over 19 years of experience in the financial services industry, and prior to joining AWS, he was an Executive Director at J.P. Morgan Chase & Co, where he managed the North America and Latin America trade surveillance teams and led the development of global trade surveillance. Alvin also teaches a Quantitative Risk Management course at Rutgers University and serves on the Rutgers Mathematical Finance Master’s program (MSMF) Advisory Board.
 David Ping is a Principal Machine Learning Architect and Sr. Manager of AI/ML Solutions Architecture at Amazon Web Services. He helps enterprise customers build and operate machine learning solutions on AWS. David enjoys hiking and following the latest machine learning advancement.
David Ping is a Principal Machine Learning Architect and Sr. Manager of AI/ML Solutions Architecture at Amazon Web Services. He helps enterprise customers build and operate machine learning solutions on AWS. David enjoys hiking and following the latest machine learning advancement.