Globally, there has been an accelerated shift toward frictionless digital user experiences. Whether it’s registering at a website, transacting online, or simply logging in to your bank account, organizations are actively trying to reduce the friction their customers experience while at the same time enhance their security, compliance, and fraud prevention measures. The shift toward frictionless user experiences has given rise to face-based biometric identity verification solutions aimed at answering the question “How do you verify a person in the digital world?”
There are two key advantages of facial biometrics when it comes to questions of identification and authentication. First, it’s a convenient technology for users: there is no need to remember a password, deal with multi-factor challenges, click verification links, or solve CAPTCHA puzzles. Secondly, a high level of security is achieved: identification and authentication on the basis of facial-biometrics is secure and less susceptible to fraud and attacks.
In this post, we dive into the two primary use cases of identity verification: onboarding and authentication. Then we dive into the two key metrics used to evaluate a biometric system’s accuracy: the false match rate (also known as false acceptance rate) and false non-match rate (also known as false rejection rate). These two measures are widely used by organizations to evaluate accuracy and error rate of biometric systems. Finally, we discuss a framework and best practices for performing an evaluation of an identity verification service.
Refer to the accompanying Jupyter notebook that walks through all the steps mentioned in this post.
Use cases: Onboarding and Authentication
There are two primary use cases for biometric solutions: user onboarding (often referred to as verification) and authentication (often referred to as identification). Onboarding entails one-to-one matching of faces between two images, for example comparing a selfie to a trusted identification document like a driver’s license or passport. Authentication, on the other hand, entails one-to-many search of a face against a stored collection of faces, for example searching a collection of employee faces to see if an employee is authorized access to a particular floor in a building.
Accuracy performance of onboarding and authentication use cases is measured by the false positive and false negative errors that the biometric solution can make. A similarity score (ranging from 0% meaning no match to 100% meaning a perfect match) is used to make the determination of a match or a non-match decision. A false positive occurs when the solution considers images of two different individuals to be the same person. A false negative, on the other hand, means that the solution considered two images of the same person to be different.
Onboarding: One-to-one verification
Biometric-based onboarding processes both simplify and secure the process. Most importantly, it sets the organization and customer up for a near-frictionless onboarding experience. To do this, users are simply required to present an image of some form of trusted identification document containing the user’s face (such as driver’s license or passport) as well as take a selfie image during the onboarding process. After the system has these two images, it simply compares the faces within the two images. When the similarity is greater than a specified threshold, then you have a match; otherwise, you have a non-match. The following diagram outlines the process.
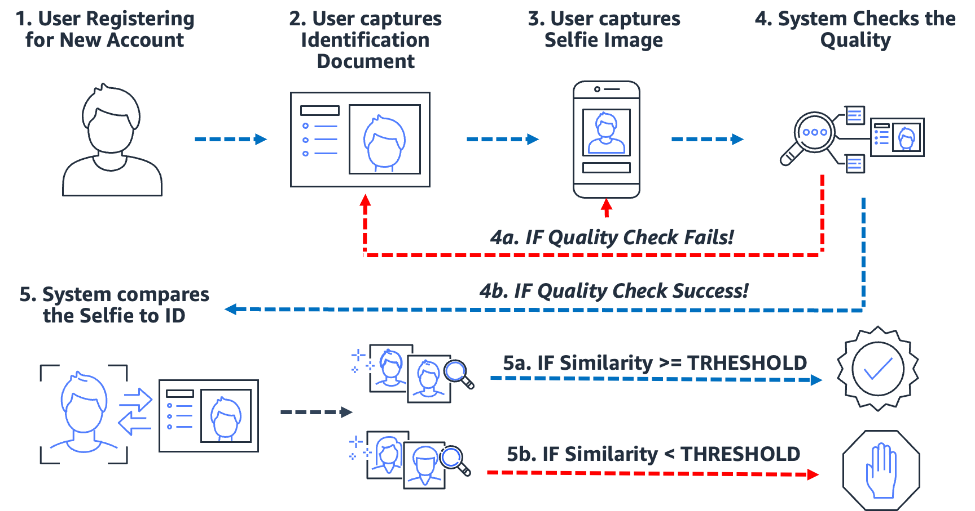
Consider the example of Julie, a new user opening a digital bank account. The solution prompts her to snap a picture of her driver’s license (step 2) and snap a selfie (step 3). After the system checks the quality of the images (step 4), it compares the face in the selfie to the face on the driver’s license (one-to-one matching) and a similarity score (step 5) is produced. If the similarity score is less than the required similarity threshold, then the onboarding attempt by Julie is rejected. This is what we call a false non-match or false rejection: the solution considered two images of the same person to be different. On the other hand, if the similarity score was greater than the required similarity, then the solution considers the two images to be the same person or a match.
Authentication: One-to-many identification
From entering a building, to checking in at a kiosk, to prompting a user for a selfie to verify their identity, this type of zero-to-low-friction authentication via facial recognition has become commonplace for many organizations. Instead of performing image-to-image matching, this authentication use case takes a single image and compares it to a searchable collection of images for a potential match. In a typical authentication use case, the user is prompted to snap a selfie, which is then compared against the faces stored in the collection. The result of the search yields zero, one, or more potential matches with corresponding similarity scores and external identifiers. If no match is returned, then the user is not authenticated; however, assuming the search returns one or more matches, the system makes the authentication decision based on the similarity scores and external identifiers. If the similarity score exceeds the required similarity threshold and the external identifier matches the expected identifier, then the user is authenticated (matched). The following diagram outlines an example face-based biometric authentication process.
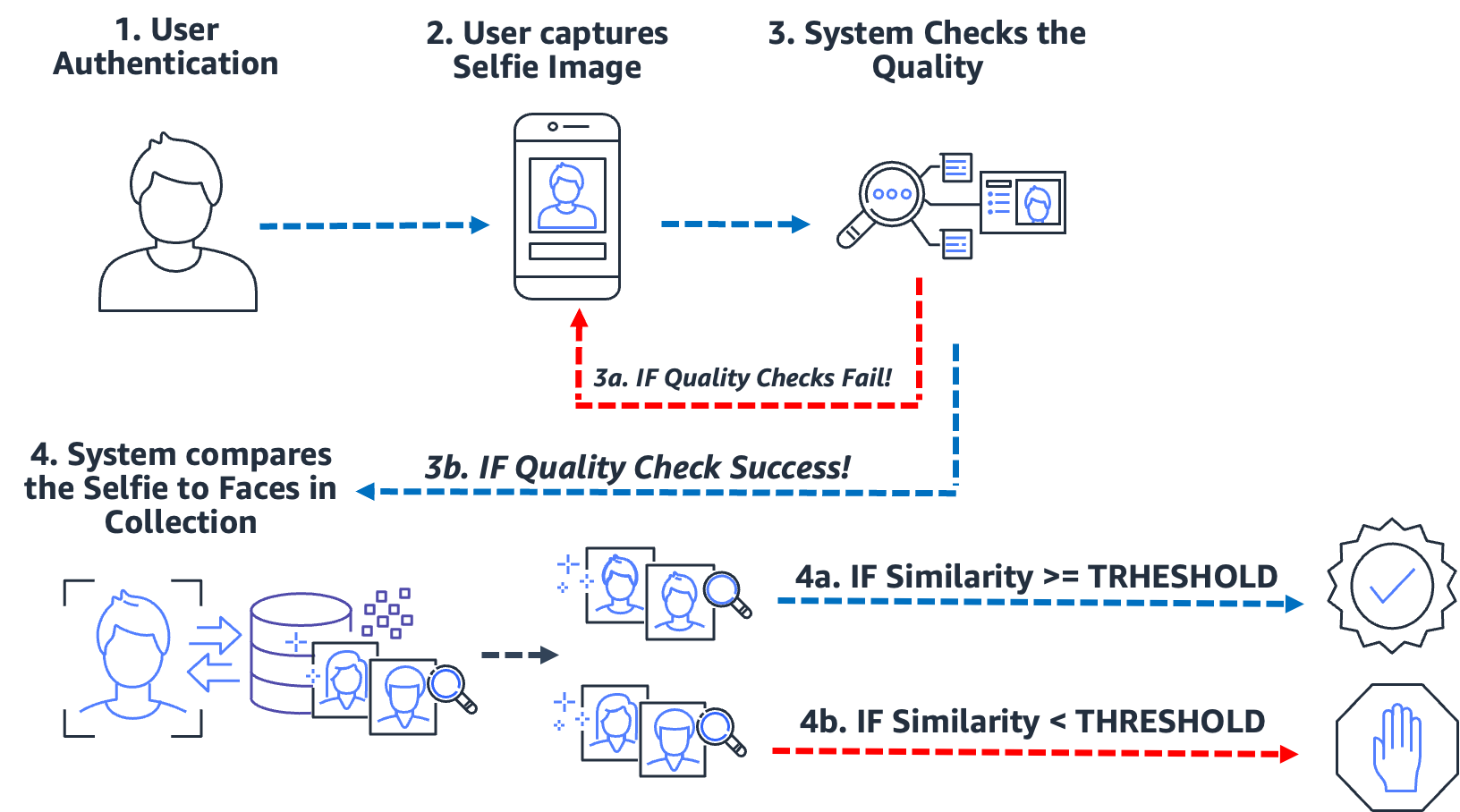
Consider the example of Jose, a gig-economy delivery driver. The delivery service authenticates delivery drivers by prompting the driver to snap a selfie before starting a delivery using the company’s mobile application. One problem gig-economy service providers face is job-sharing; essentially two or more users share the same account in order to game the system. To combat this, many delivery services use an in-car camera to snap images (step 2) of the driver at random times during a delivery (to ensure that the delivery driver is the authorized driver). In this case, Jose not only snaps a selfie at the start of his delivery, but an in-car camera snaps images of him during the delivery. The system performs quality checks (step 3) and searches (step 4) the collection of registered drivers to verify the identity of the driver. If a different driver is detected, then the gig-economy delivery service can investigate further.
A false match (false positive) occurs when the solution considered two or more images of different people to be the same person. In our use case, suppose that instead of the authorized driver, Jose he lets his brother Miguel take one of his deliveries for him. If the solution incorrectly matches Miguel’s selfie to the images of Jose, then a false match (false positive) occurs.
To combat the potential of a false matches, we recommend that collections contain several images of each subject. It’s common practice to index trusted identification documents containing a face, a selfie at time of onboarding, and selfies from the last several identification checks. Indexing several images of a subject provides the ability to aggregate the similarity scores across faces returned, thereby improving the accuracy of the identification. Additionally, external identifiers are used to limit the risk of a false acceptance. An example business rule might look something like this:
IF aggregate similarity score >= required similarity threshold AND external identifier == expected identifier THEN authenticate
Key biometric accuracy measures
In a biometric system, we’re interested in the false match rate (FMR) and false non-match rate (FNMR) based on the similarity scores from face comparisons and searches. Whether it’s an onboarding or authentication use case, biometric systems decide to accept or reject matches of a user’s face based on the similarity score of two or more images. Like any decision system, there will be errors where the system incorrectly accepts or rejects an attempt at onboarding or authentication. As part of evaluating your identity verification solution, you need to evaluate the system at various similarity thresholds to minimize false match and false non-match rates, as well as contrast those errors against the cost of making incorrect rejections and acceptances. We use FMR and FNMR as our two key metrics to evaluate facial biometric systems.
False non-match rate
When the identity verification system fails to correctly identify or authorize a genuine user, a false non-match occurs, also known as a false negative. The false non-match rate (FNMR) is a measure of how prone the system is to incorrectly identifying or authorizing a genuine user.
The FNMR is expressed as a percentage of instances where an onboarding or authentication attempt is made, where the user’s face is incorrectly rejected (a false negative) because the similarity score is below the prescribed threshold.
A true positive (TP) is when the solution considers two or more images of the same person to be the same. That is, the similarity of the comparison or search is above the required similarity threshold.
A false negative (FN) is when the solution considers two or more images of the same person to be different. That is, the similarity of the comparison or search is below the required similarity threshold.
The formula for the FNMR is:
FNMR = False Negative Count / (True Positive Count + False Negative Count)
For example, suppose we have 10,000 genuine authentication attempts but 100 are denied because their similarity to the reference image or collection falls below the specified similarity threshold. Here we have 9,900 true positives and 100 false negatives, therefore our FNMR is 1.0%
FNMR = 100 / (9900 + 100) or 1.0%
False match rate
When an identity verification system incorrectly identifies or authorizes an unauthorized user as genuine, a false match occurs, also known as a false positive. The false match rate (FMR) is a measure of how prone the system is to incorrectly identifying or authorizing an unauthorized user. It’s measured by the number of false positive recognitions or authentications divided by the total number of identification attempts.
A false positive occurs when the solution considers two or more images of different people to be the same person. That is, the similarity score of the comparison or search is above the required similarity threshold. Essentially, the system incorrectly identifies or authorizes a user when it should have rejected their identification or authentication attempt.
The formula for the FMR is:
FMR = False Positive Count / (Total Attempts)
For example, suppose we have 100,000 authentication attempts but 100 bogus users are incorrectly authorized because their similarity to the reference image or collection falls above the specified similarity threshold. Here we have 100 false positives, therefore our FMR is 0.01%
FMR = 100 / (100,000) or 0.01%
False match rate vs. false non-match rate
False match rate and false non-match rate are at odds with each other. As the similarity threshold increases, the potential for a false match decreases, while the potential for a false non-match increases. Another way to think about this trade-off is that as the similarity threshold increases, the solution becomes more restrictive, making fewer low similarity matches. For example, it’s common for use cases involving public safety and security to set a match similarity threshold quite high (99 and above). Alternatively, an organization may choose a less restrictive similarity threshold (90 and above), where the impact of friction to the user is more important. The following diagram illustrates these trade-offs. The challenge for organizations is to find a threshold that minimizes both FMR and FNMR based on your organizational and application requirements.
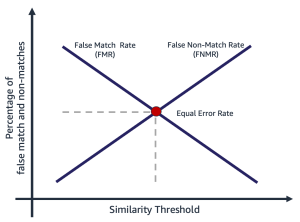
Selecting a similarity threshold depends on the business application. For example, suppose you want to limit customer friction during onboarding (a less restrictive similarity threshold, as shown in the following figure on the left). Here you might have a lower required similarity threshold, and are willing to accept the risk of onboarding users where the confidence in the match between their selfie and driver’s license is lower. By contrast, suppose you want to ensure only authorized users get into an application. Here you might operate at a quite restrictive similarity threshold (as shown in the figure on the right).
 |
 |
Steps for calculating false match and non-match rates
There are several of ways to calculate these two metrics. The following is a relatively simple approach of dividing the steps into gathering genuine image pairs, creating an imposter pairing (images that shouldn’t match), and finally using a probe to loop over the expected match and non-match image pairs, capturing the resulting similarity. The steps are as follows:
- Gather a genuine sample image set. We recommend starting with a set of image pairs and assigning an external identifier, which is used to make an official match determination. The pair consists of the following images:
- Source image – Your trusted source image, for example a driver’s license.
- Target image – Your selfie or image you are going to compare with.
- Gather an image set of imposter matches. These are pairs of images where the source and target don’t match. This is used to assess the FMR (the probability that the system will incorrectly match the faces of two different users). You can create an imposter image set using the image pairs by creating a Cartesian product of the images then filtering and sampling the result.
- Probe the genuine and imposter match sets by looping over the image pairs, comparing the source and imposter target and capturing the resulting similarity.
- Calculate FMR and FNMR by calculating the false positives and false negatives at different minimum similarity thresholds.
You can assess the cost of FMR and FNMR at different similarity thresholds relative to your application’s need.
Step 1: Gather genuine image pair samples
Choosing a representative sample of image pairs to evaluate is critical when evaluating an identity verification service. The first step is to identify a genuine set of image pairs. These are known source and target images of a user. The genuine image pairing is used to assess the FNMR, essentially the probability that the system won’t match two faces of the same person. One of the first questions often asked is “How many image pairs are necessary?” The answer is that it depends on your use case, but the general guidance is the following:
- Between 100–1,000 image pairs provides a measure of feasibility
- Up to 10,000 images pairs is large enough to measure variability between images
- More than 10,000 image pairs provides a measure of operational quality and generalizability
More data is always better; however, as a starting point, use at least 1,000 image pairs. However, it’s not uncommon to use more than 10,000 image pairs to zero in on an acceptable FNMR or FMR for a given business problem.
The following is a sample image pair mapping file. We use the image pair mapping file to drive the rest of the evaluation process.
| EXTERNAL_ID | SOURCE | TARGET | TEST |
| 9055 | 9055_M0.jpeg | 9055_M1.jpeg | Genuine |
| 19066 | 19066_M0.jpeg | 19066_M1.jpeg | Genuine |
| 11396 | 11396_M0.jpeg | 11396_M1.jpeg | Genuine |
| 12657 | 12657_M0.jpeg | 12657_M1.jpeg | Genuine |
| … | . | . | . |
Step 2: Generate an imposter image pair set
Now that you have a file of genuine image pairs, you can create a Cartesian product of target and source images where the external identifiers don’t mach. This produces source-to-target pairs that shouldn’t match. This pairing is used to assess the FMR, essentially the probability the system will match the face of one user to a face of a different user.
| external_id | SOURCE | TARGET | TEST |
| 114192 | 114192_4M49.jpeg | 307107_00M17.jpeg | Imposter |
| 105300 | 105300_04F42.jpeg | 035557_00M53.jpeg | Imposter |
| 110771 | 110771_3M44.jpeg | 120381_1M33.jpeg | Imposter |
| 281333 | 281333_04F35.jpeg | 314769_01M17.jpeg | Imposter |
| 40081 | 040081_2F52.jpeg | 326169_00F32.jpeg | Imposter |
| … | . | . | . |
Step 3: Probe the genuine and imposter image pair sets
Using a driver program, we apply the Amazon Rekognition CompareFaces API over the image pairs and capture the similarity. You can also capture additional information like pose, quality, and other results of the comparison. The similarity scores are used to calculate the false match and non-match rates in the following step.
In the following code snippet, we apply the CompareFaces API to all the image pairs and populate all the similarity scores in a table:
The code snippet gives the following output.
| EXTERNAL_ID | SOURCE | TARGET | TEST | SIMILARITY |
| 9055 | 9055_M0.jpeg | 9055_M1.jpeg | Genuine | 98.3 |
| 19066 | 19066_M0.jpeg | 19066_M1.jpeg | Genuine | 94.3 |
| 11396 | 11396_M0.jpeg | 11396_M1.jpeg | Genuine | 96.1 |
| … | . | . | . | . |
| 114192 | 114192_4M49.jpeg | 307107_00M17.jpeg | Imposter | 0.0 |
| 105300 | 105300_04F42.jpeg | 035557_00M53.jpeg | Imposter | 0.0 |
| 110771 | 110771_3M44.jpeg | 120381_1M33.jpeg | Imposter | 0.0 |
Distribution analysis of similarity scores by tests are a starting point to understand the similarity score by image pairs. The following code snippet and output chart shows a simple example of the distribution of similarity score by test set as well as resulting descriptive statistics:
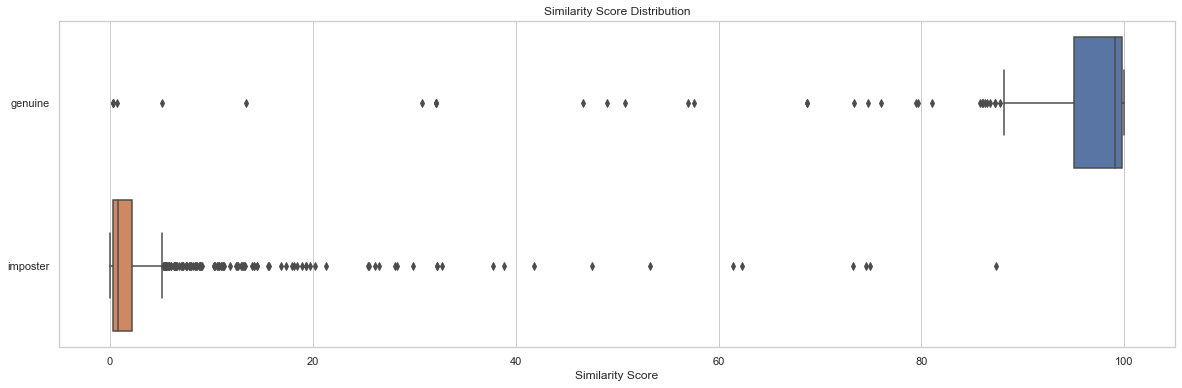
| test | count | min | max | mean | median | std |
| genuine | 204 | 0.2778 | 99.9957 | 91.7357 | 99.0961 | 19.9097 |
| imposter | 1020 | 0.0075 | 87.3893 | 2.8111 | 0.8330 | 7.3496 |
In this example, we can see that the mean and median similarity for genuine face pairs was 91.7 and 99.1, whereas for the imposter pairs was 2.8 and 0.8, respectively. As expected, this shows the high similarity scores for genuine image pairs and low similarity scores for imposter image pairs.
Step 4: Calculate FMR and FNMR at different similarity threshold levels
In this step, we calculate the false match and non-match rates at different thresholds of similarity. To do this, we simply loop through similarity thresholds (for example, 90–100). At each selected similarity threshold, we calculate our confusion matrix containing true positive, true negative, false positive, and false negative counts, which are used to calculate the FMR and FNMR at each selected similarity.
| Actual | |||
| Predicted | |||
| . | Match | No-Match | |
| >= selected similarity | TP | FP | |
| < selected similarity | FN | TN | |
To do this, we create a function that returns the false positive and negative counts, and loop through a range of similarity scores (90–100):
The following table shows the results of the counts at each similarity threshold.
| Similarity Threshold | TN | FN | TP | FP | FNMR | FMR |
| 80 | 1019 | 22 | 182 | 1 | 0.1% | 0.1% |
| 85 | 1019 | 23 | 181 | 1 | 0.11% | 0.1% |
| 90 | 1020 | 35 | 169 | 0 | 0.12% | 0.0% |
| 95 | 1020 | 51 | 153 | 0 | 0.2% | 0.0% |
| 96 | 1020 | 53 | 151 | 0 | 0.25% | 0.0% |
| 97 | 1020 | 60 | 144 | 0 | 0.3% | 0.0% |
| 98 | 1020 | 75 | 129 | 0 | 0.4% | 0.0% |
| 99 | 1020 | 99 | 105 | 0 | 0.5% | 0.0% |
How does the similarity threshold impact false non-match rate?
Suppose we have 1,000 genuine user onboarding attempts, and we reject 10 of these attempts based on a required minimum similarity of 95% to be considered a match. Here we reject 10 genuine onboarding attempts (false negatives) because their similarity falls below the specified minimum required similarity threshold. In this case, our FNMR is 1.0%.
| Actual | |||
| Predicted | |||
| . | Match | No-Match | |
| >= 95% similarity | 990 | 0 | |
| < 95% similarity | 10 | 0 | |
| . | total | 1,000 | . |
FNMR = False Negative Count / (True Positive Count + False Negative Count)
FNMR = 10 / (990 + 10) or 1.0%
By contrast, suppose instead of having 1,000 genuine users to onboard, we have 990 genuine users and 10 imposter users (false positive). At a 95% minimum similarity, suppose we accept all 1,000 users as genuine. Here we would have a 1% FMR.
| Actual | ||||
| Predicted | ||||
| . | Match | No-Match | total | |
| >= 95% similarity | 990 | 10 | 1,000 | |
| < 95% similarity | 0 | 0 | . | |
FMR = False Positive Count / (Total Attempts)
FMR = 10 / (1,000) or 1.0%
Assessing costs of FMR and FNMR at onboarding
In an onboarding use case, the cost of a false non-match (a rejection) is generally associated with additional user friction or loss of a registration. For example, in our banking use case, suppose Julie presents two images of herself but is incorrectly rejected at time of onboarding because the similarity between the two images falls below the selected similarity (a false non-match). The financial institution may risk losing Julie as a potential customer, or it may cause Julie additional friction by requiring her to perform steps to prove her identity.
Conversely, suppose the two images of Julie are of different people and Julie’s onboarding should have been rejected. In the case where Julie is incorrectly accepted (a false match), the cost and risk to the financial institution is quite different. There could be regulatory issues, risk of fraud, and other risks associated with financial transactions.
Responsible use
Artificial intelligence (AI) applied through machine learning (ML) will be one of the most transformational technologies of our generation, tackling some of humanity’s most challenging problems, augmenting human performance, and maximizing productivity. Responsible use of these technologies is key to fostering continued innovation. AWS is committed to developing fair and accurate AI and ML services and providing you with the tools and guidance needed to build AI and ML applications responsibly.
As you adopt and increase your use of AI and ML, AWS offers several resources based on our experience to assist you in the responsible development and use of AI and ML:
- Use cases that involve public safety
- AWS Service Terms
- Resources and tools provided by AWS on responsible use of AI and ML
Best practices and common mistakes to avoid
In this section, we discuss the following best practices:
- Use a large enough sample of images
- Avoid open-source and synthetic face datasets
- Avoid manual and synthetic image manipulation
- Check image quality at time of evaluation and over time
- Monitor FMR and FNMR over time
- Use a human in the loop review
- Stay up to date with Amazon Rekognition
Use a large enough sample of images
Use a large enough but reasonable sample of images. What is a reasonable sample size? It depends on the business problem. If you’re an employer and have 10,000 employees that you want to authenticate, then using all 10,000 images is probably reasonable. However, suppose you’re an organization with millions of customers that you want to onboard. In this case, taking a representative sample of customers such as 5,000–20,000 is probably sufficient. Here is some guidance on the sample size:
- A sample size of 100 – 1,000 image pairs proves feasibility
- A sample size of 1,000 – 10,000 image pairs is useful to measure variability between images
- A sample size of 10,000 – 1 million image pairs provides a measure of operational quality and generalizability
The key with sampling image pairs is to ensure that the sample provides enough variability across the population of faces in your application. You can further extend your sampling and testing to include demographic information like skin tone, gender, and age.
Avoid open-source and synthetic face datasets
There are dozens of curated open-source facial image datasets as well as astonishingly realistic synthetic face sets that are often used in research and to study feasibility. The challenge is that these datasets are generally not useful for 99% of real-world use cases simply because they aren’t representative of the cameras, faces, and quality of the images your application is likely to encounter in the wild. Although they’re useful for application development, the accuracy measures of these image sets don’t generalize to what you’ll encounter in your own application. Instead, we recommend starting with a representative sample of real images from your solution, even if the sample image pairs are small (under 1,000).
Avoid manual and synthetic image manipulation
There are often edge cases that people are interested in understanding. Things like image capture quality or obfuscations of specific facial features are always of interest. For example, we often get asked about the impact of age and image quality on facial recognition. You could simply synthetically age a face or manipulate the image to make the subject appear older, or manipulate the image quality, but this doesn’t translate well to real-world aging of images. Instead, our recommendation is to gather a representative sample of real-world edge cases you’re interested in testing.
Check image quality at time of evaluation and over time
Camera and application technology changes quite rapidly over time. As a best practice, we recommend monitoring image quality over time. From the size of faces captured (using bounding boxes), to the brightness and sharpness of an image, to the pose of a face, as well as potential obfuscations (hats, sunglasses, beards, and so on), all of these image and facial features change over time.
Monitor FNMR and FMR over time
Changes occur, whether it’s the images, the application, or the similarity thresholds used in the application. It’s important to periodically monitor false match and non-match rates over time. Changes in the rates (even subtle changes) can often point to upstream challenges with the application or how the application is being used. Changes to similarity thresholds and business rules used to make accept or reject decisions can have major impact on onboarding and authentication user experiences.
Use a human in the loop review
Identity verification systems make automated decisions to match and non-match based on similarity thresholds and business rules. Besides regulatory and internal compliance requirements, an important process in any automated decision system is to utilize human reviewers as part of the ongoing monitoring of the decision process. Human oversight of these automated decisioning systems provides validation and continuous improvement as well as transparency into the automated decision-making process.
Stay up to date with Amazon Rekognition
The Amazon Recognition faces model is updated periodically (usually annually), and is currently on version 6. This updated version made important improvements to accuracy and indexing. It’s important to stay up to date with new model versions and understand how to use these new versions in your identity verification application. When new versions of the Amazon Rekognition face model are launched, it’s good practice to rerun your identity verification evaluation process and determine any potential impacts (positive and negative) to your false match and non-match rates.
Conclusion
This post discusses the key elements needed to evaluate the performance aspect of your identity verification solution in terms of various accuracy metrics. However, accuracy is only one of the many dimensions that you need to evaluate when choosing a particular content moderation service. It’s critical that you include other parameters, such as the service’s total feature set, ease of use, existing integrations, privacy and security, customization options, scalability implications, customer service, and pricing.
To learn more about identity verification in Amazon Rekognition, visit Identity Verification using Amazon Rekognition.
About the Authors
 Mike Ames is a data scientist turned identity verification solution specialist, with extensive experience developing machine learning and AI solutions to protect organizations from fraud, waste, and abuse. In his spare time, you can find him hiking, mountain biking, or playing freebee with his dog Max.
Mike Ames is a data scientist turned identity verification solution specialist, with extensive experience developing machine learning and AI solutions to protect organizations from fraud, waste, and abuse. In his spare time, you can find him hiking, mountain biking, or playing freebee with his dog Max.
 Amit Gupta is a Senior AI Services Solutions Architect at AWS. He is passionate about enabling customers with well-architected machine learning solutions at scale.
Amit Gupta is a Senior AI Services Solutions Architect at AWS. He is passionate about enabling customers with well-architected machine learning solutions at scale.
 Zuhayr Raghib is an AI Services Solutions Architect at AWS. Specializing in applied AI/ML, he is passionate about enabling customers to use the cloud to innovate faster and transform their businesses.
Zuhayr Raghib is an AI Services Solutions Architect at AWS. Specializing in applied AI/ML, he is passionate about enabling customers to use the cloud to innovate faster and transform their businesses.
 Marcel Pividal is a Sr. AI Services Solutions Architect in the World-Wide Specialist Organization. Marcel has more than 20 years of experience solving business problems through technology for fintechs, payment providers, pharma, and government agencies. His current areas of focus are risk management, fraud prevention, and identity verification.
Marcel Pividal is a Sr. AI Services Solutions Architect in the World-Wide Specialist Organization. Marcel has more than 20 years of experience solving business problems through technology for fintechs, payment providers, pharma, and government agencies. His current areas of focus are risk management, fraud prevention, and identity verification.