Ambarella builds computer vision SoCs (system on chips) based on a very efficient AI chip architecture and CVflow that provides the Deep Neural Network (DNN) processing required for edge inferencing use cases like intelligent home monitoring and smart surveillance cameras. Developers convert models trained with frameworks (such as TensorFlow or MXNET) to Ambarella CVflow format to be able to run these models on edge devices. Amazon SageMaker Edge has integrated the Ambarella toolchain into its workflow, allowing you to easily convert and optimize your models for the platform.
In this post, we show how to set up model optimization and conversion with SageMaker Edge, add the model to your edge application, and deploy and test your new model in an Ambarella CV25 device to build a smart surveillance camera application running on the edge.
Smart camera use case
Smart security cameras have use case-specific machine learning (ML) enabled features like detecting vehicles and animals, or identifying possible suspicious behavior, parking, or zone violations. These scenarios require ML models run on the edge computing unit in the camera with the highest possible performance.
Ambarella’s CVx processors, based on the company’s proprietary CVflow architecture, provide high DNN inference performance at very low power. This combination of high performance and low power makes them ideal for devices that require intelligence at the edge. ML models need to be optimized and compiled for the target platform to run on the edge. SageMaker Edge plays a key role in optimizing and converting ML models to the most popular frameworks to be able to run on the edge device.
Solution overview
Our smart security camera solution implements ML model optimization and compilation configuration, runtime operation, inference testing, and evaluation on the edge device. SageMaker Edge provides model optimization and conversion for edge devices to run faster with no loss in accuracy. The ML model can be in any framework that SageMaker Edge supports. For more information, see Supported Frameworks, Devices, Systems, and Architectures.
The SageMaker Edge integration of Ambarella CVflow tools provides additional advantages to developers using Ambarella SoCs:
- Developers don’t need to deal with updates and maintenance of the compiler toolchain, because the toolchain is integrated and opaque to the user
- Layers that CVflow doesn’t support are automatically compiled to run on the ARM by the SageMaker Edge compiler
The following diagram illustrates the solution architecture:
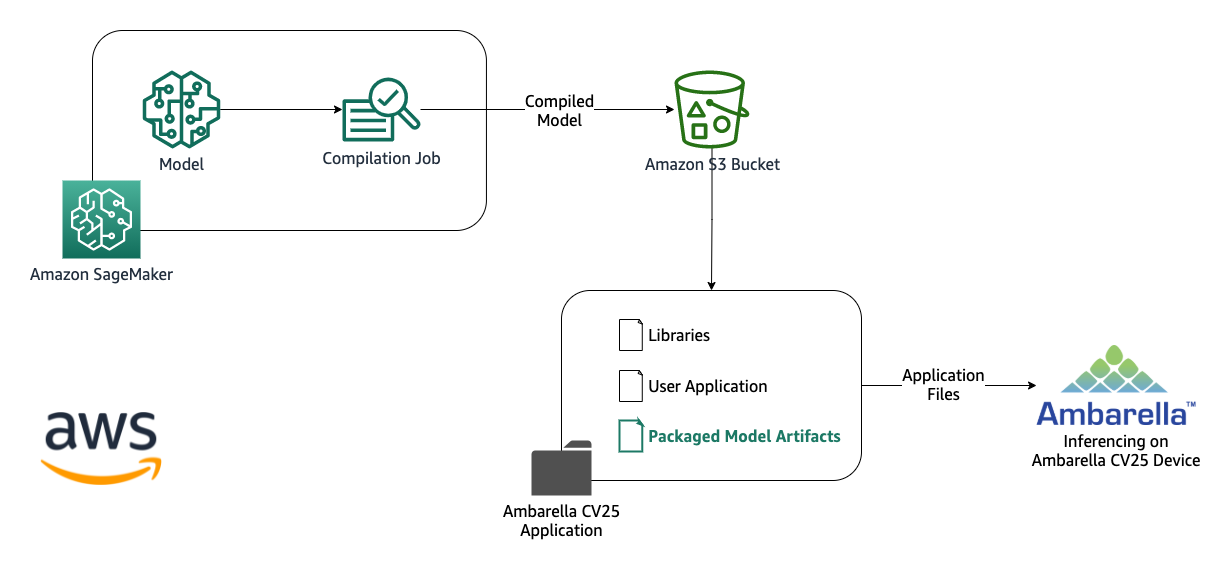
The steps to implement the solution are as follows:
- Prepare the model package.
- Configure and start the model’s compilation job for Ambarella CV25.
- Place the packaged model artifacts on the device.
- Test the inference on the device.
Prepare the model package
For Ambarella targets, SageMaker Edge requires a model package that contains a model configuration file called amba_config.json, calibration images, and a trained ML model file. This model package file is a compressed TAR file (*.tar.gz). You can use an Amazon Sagemaker notebook instance to train and test ML models and to prepare the model package file. To create a notebook instance, complete the following steps:
- On the SageMaker console, under Notebook in the navigation pane, choose Notebook instances.

- Choose Create notebook instance.
- Enter a name for your instance and choose ml.t2.medium as the instance type.
This instance is enough for testing and model preparation purposes.
- For IAM role, create a new AWS Identity and Access Management (IAM) role to allow access to Amazon Simple Storage Service (Amazon S3) buckets, or choose an existing role.
- Keep other configurations as default and choose Create notebook instance.
When the status is InService, you can start using your new Sagemaker notebook instance.
- Choose Open JupyterLab to access your workspace.
For this post, we use a pre-trained TFLite model to compile and deploy to the edge device. The chosen model is a pre-trained SSD object detection model from the TensorFlow model zoo on the COCO dataset.
- Download the converted TFLite model.
Now you’re ready to download, test, and prepare the model package.
- Create a new notebook with kernel
conda_tensorflow2_p36on the launcher view. - Import the required libraries as follows:
- Save the following example image as
street-frame.jpg, create a folder called calib_img in the workspace folder, and upload the image to the current folder. - Upload the downloaded model package contents to the current folder.

- Run the following command to load your pre-trained TFLite model and print its parameters, which we need to configure our model for compilation:
- Use following code to load the test image and run inference:
- Use the following code to visualize the detected bounding boxes on the image and save the result image as
street-frame_results.jpg: - Use following command to show the result image:
You get an inference result like the following image.

Our pre-trained TFLite model detects the car object from a security camera frame.
We’re done with testing the model; now let’s package the model and configuration files that Amazon Sagemaker Neo requires for Ambarella targets.
- Create an empty text file called
amba_config.jsonand use the following content for it:
This file is the compilation configuration file for Ambarella CV25. The filepath value inside amba_config.json should match the calib_img folder name; a mismatch may cause a failure.
The model package contents are now ready.
- Use the following commands to compress the package as a .tar.gz file:
- Upload the file to the SageMaker auto-created S3 bucket to use in the compilation job (or your designated S3 bucket):
The model package file contains calibration images, the compilation config file, and model files. After you upload the file to Amazon S3, you’re ready to start the compilation job.
Compile the model for Ambarella CV25
To start the compilation job, complete the following steps:
- On the SageMaker console, under Inference in the navigation pane, choose Compilation jobs.

- Choose Create compilation job.
- For Job name, enter a name.
- For IAM role, create a role or choose an existing role to give Amazon S3 read and write permission for the model files.

- In the Input configuration section, for Location of model artifacts, enter the S3 path of your uploaded model package file.
- For Data input configuration, enter
{"normalized_input_image_tensor":[1, 300, 300, 3]}, which is the model’s input data shape obtained in previous steps. - For Machine learning framework, choose TFLite.

- In the Output configuration section, for Target device, choose your device (
amba_cv25). - For S3 Output location, enter a folder in your S3 bucket for the compiled model to be saved in.
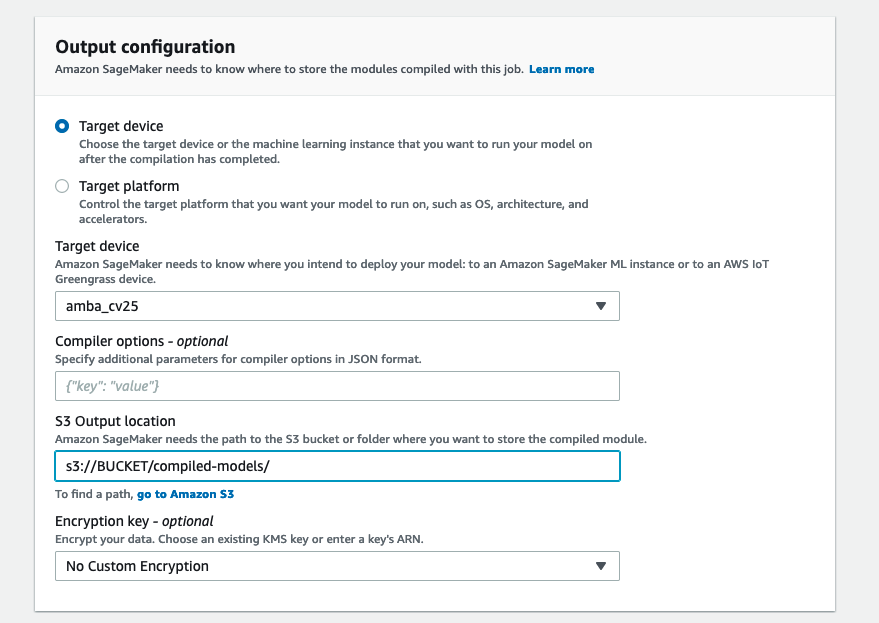
- Choose Submit to start the compilation process.
The compilation time depends on your model size and architecture. When your compiled model is ready in Amazon S3, the Status column shows as COMPLETED.
If the compilation status shows FAILED, refer to Troubleshoot Ambarella Errors to debug compilation errors.
Place the model artifacts on the device
When the compilation job is complete, Neo saves the compiled package to the provided output location in the S3 bucket. The compiled model package file contains the converted and optimized model files, their configuration, and runtime files.
On the Amazon S3 console, download the compiled model package, then extract and transfer the model artifacts to your device to start using it with your edge ML inferencing app.
Test the ML inference on the device
Navigate to your Ambarella device’s terminal and run the inferencing application binary on the device. The compiled and optimized ML model runs for the specified video source. You can observe detected bounding boxes on the output stream, as shown in the following screenshot.

Conclusion
In this post, we accomplished ML model preparation and conversion to Ambarella targets with SageMaker Edge, which has integrated the Ambarella toolchain. Optimizing and deploying high-performance ML models to Ambarella’s low-power edge devices unlocks intelligent edge solutions like smart security cameras.
As a next step, you can get started with SageMaker Edge and Ambarella CV25 to enable ML for edge devices. You can extend this use case with Sagemaker ML development features to build an end-to-end pipeline that includes edge processing and deployment.
About the Authors
 Emir Ayar is an Edge Prototyping Lead Architect on the AWS Prototyping team. He specializes in helping customers build IoT, Edge AI, and Industry 4.0 solutions and implement architectural best practices. He lives in Luxembourg and enjoys playing synthesizers.
Emir Ayar is an Edge Prototyping Lead Architect on the AWS Prototyping team. He specializes in helping customers build IoT, Edge AI, and Industry 4.0 solutions and implement architectural best practices. He lives in Luxembourg and enjoys playing synthesizers.
 Dinesh Balasubramaniam is responsible for marketing and customer support for Ambarella’s family of security SoCs, with expertise in systems engineering, software development, video compression, and product design. Dinesh He earned an MS EE degree from the University of Texas at Dallas with a focus on signal processing.
Dinesh Balasubramaniam is responsible for marketing and customer support for Ambarella’s family of security SoCs, with expertise in systems engineering, software development, video compression, and product design. Dinesh He earned an MS EE degree from the University of Texas at Dallas with a focus on signal processing.