After you build, train, and evaluate your machine learning (ML) model to ensure it’s solving the intended business problem proposed, you want to deploy that model to enable decision-making in business operations. Models that support business-critical functions are deployed to a production environment where a model release strategy is put in place. Given the nature of ML models, where the data is continuously changing, you also want to ensure that a deployed model is still relevant to new data and that the model is updated when this is not the case. This includes choosing a deployment strategy that minimizes risks and downtime. This optimal deployment strategy should maintain high availability of the model, consider the business cost of deploying an inferior model to what is already in production, and contain functionality to easily roll back to a previous model version. Many of these recommended considerations and deployment patterns are also covered within the AWS Well Architected Framework – Machine Learning Lens.
In addition to choosing the right deployment strategy, that strategy should be implemented using a reliable mechanism that includes MLOps practices. MLOps includes practices that integrate ML workloads into release management, CI/CD, and operations, accounting for the unique aspects of ML projects, including considerations for deploying and monitoring models. Amazon SageMaker for MLOps provides purpose-built tools to automate and standardize steps across the ML lifecycle, including capabilities to deploy and manage new models using advanced deployment patterns.
In this post, we discuss how to deploy ML models with Amazon SageMaker in a repeatable and automated way, integrating the production variants and deployment guardrails capabilities of SageMaker with MLOps solutions. We give you an introduction of how to integrate the MLOps tools of SageMaker with SageMaker model deployment patterns, focusing on real-time single-model endpoints.
Solution overview
We explore the following model testing and guardrail patterns and their integration with SageMaker MLOps tools:
- Model testing – We compare different model versions in production before replacing the current model version. This post compares the following model testing capabilities:
- A/B testing – With A/B testing, you compare different versions of your model in production by distributing the endpoint traffic between your model variants. A/B testing is used in scenarios where closed loop feedback can directly tie model outputs to downstream business metrics. This feedback is then used to determine the statistical significance of changing from one model to another, helping you select the best model through live production testing.
- Shadow tests – With shadow tests, you test a new version of your model in production by sending requests to the production model and the new model in parallel. The prediction response data from the production model is served to the application, while the new model version predictions are stored for testing but not served to the production application. Shadow testing is used in situations where there is no closed loop feedback mapping a business metric back to a model’s predictions. In this scenario, you use model quality and operational metrics to compare multiple models instead of any impact on downstream business metrics.
- Shifting traffic – After you have tested the new version of the model and are satisfied with its performance, the next step is to shift traffic from the current model to the new one. The blue/green deployment guardrails in SageMaker allow you to easily switch from the current model in production (blue fleet) to a new one (green fleet) in a controlled way. Blue/green deployments avoid downtime during the updates of your model, like what you would have in an in-place deployment scenario. To maximize model availability, as of this writing, blue/green deployments are the default option for model updates in SageMaker. We discuss the following traffic shifting methods in this post:
- All at once traffic shifting – 100% of your endpoint traffic is shifted from your blue fleet to your green fleet after the green fleet becomes available. We use alarms in Amazon CloudWatch that monitor your green fleet for a set amount of time (the baking period) and if no alarm is triggered, the blue fleet is then deleted by SageMaker after the baking period.
- Canary traffic shifting – Your green fleet is first exposed to a smaller proportion of your traffic (a canary) and validated for any issues using CloudWatch alarms for a baking period while the blue fleet keeps receiving most of the endpoint traffic. After the green fleet is validated, all traffic is shifted to the new fleet and the blue fleet is then deleted by SageMaker.
- Blue/green linear traffic shifting guardrail – You gradually shift traffic from your blue fleet to your green fleet in a step approach. Your model is then monitored with CloudWatch alarms for a baking period in each step before the Blue fleet is completely replaced.
This post focuses on describing architectures that utilize SageMaker MLOps features to perform controlled deployments of models via the deployment guardrails and modeling testing strategies we’ve listed. For general information on these patterns, refer to Take advantage of advanced deployment strategies using Amazon SageMaker deployment guardrails and Deployment guardrails.
Deploy a model with SageMaker
SageMaker offers a broad range of deployment options that vary from low latency and high throughput to long-running inference jobs. These options include considerations for batch, real-time, or near real-time inference. Each option offers different advanced features, such as the ability to run multiple models on a single endpoint. However, as previously mentioned, for this post, we only cover MLOps deployment patterns using single-model endpoints. To dive further into more advanced SageMaker deployment features for real-time inference, refer to Model hosting patterns in Amazon SageMaker, Part 2: Getting started with deploying real time models on SageMaker.
To understand the implementation of advanced deployment patterns using continuous delivery (CD) pipelines, let’s first discuss a key concept within SageMaker called model variants.
SageMaker model variants
Model variants allow you to deploy multiple versions of your model to the same endpoint to test your model. Model variants are deployed to separate instances, so there is no impact on other variants when one is updated. In SageMaker, model variants are implemented as production and shadow variants.
Production variants allow you to A/B test multiple versions of your model to compare their performance. In this scenario, all versions of your model return responses to the model requests. Your endpoint traffic is distributed between the existent variants either by traffic distribution, where you assign a weight for each variant, or by target variant, where a certain parameter (for instance Region or market) decides which model should be invoked.
Shadow variants allow you to shadow test a new version of your model. In this scenario, your model has a production variant and a shadow variant deployed in parallel to the same endpoint. The shadow variant receives the full (or sampled) data traffic from your endpoint. However, only the predictions of the production variants are sent back to the users of your application, and the predictions from the shadow variants are logged for analysis. Because shadow variants are launched on separate instances from the production variant, there is no performance impact to your production variant in this test. With this option, you are testing the new model and minimizing the risks of a low-performing model, and you can compare both models’ performance with the same data.
SageMaker deployment guardrails
Guardrails are an essential part of software development. They protect your application and minimize the risk of deployment of a new version of your application. Similarly, SageMaker deployment guardrails allow you to switch from one model version to another in a controlled way. As of December 2022, SageMaker guardrails provide implementation for blue/green, canary, and linear traffic shifting deployment options. When combined with model variants, deployment guardrails can be applied both to production and shadow variants of your model, ensuring no downtime during the update of a new variant, with the traffic shifting being controlled according to the option selected.
MLOps foundations for model deployment
In the broader context of an ML model building and deploying workflow, we want to employ CI/CD practices purpose built for the ML workflow. Similar to traditional CI/CD systems, we want to automate software tests, integration testing, and production deployments. However, we also need to include specific operations around the ML lifecycle that aren’t present in the traditional software development lifecycle such as model training, model experimentation, model testing, and model monitoring.
To achieve those ML-specific capabilities, MLOps foundations such as automated model testing, deployment guardrails, multi-account deployments, and automated model rollback are added to the model deployment process. This ensures that the already described capabilities allow for model testing and avoid downtime during the process of a model update. It also provides the reliability and traceability necessary for the continuous improvement of a production-ready model. Additionally, capabilities like the ability to package existing solutions into reusable templates and deploy models in a multi-account setup ensure the scalability of the model deployment patterns discussed in the post to several models across an organization.
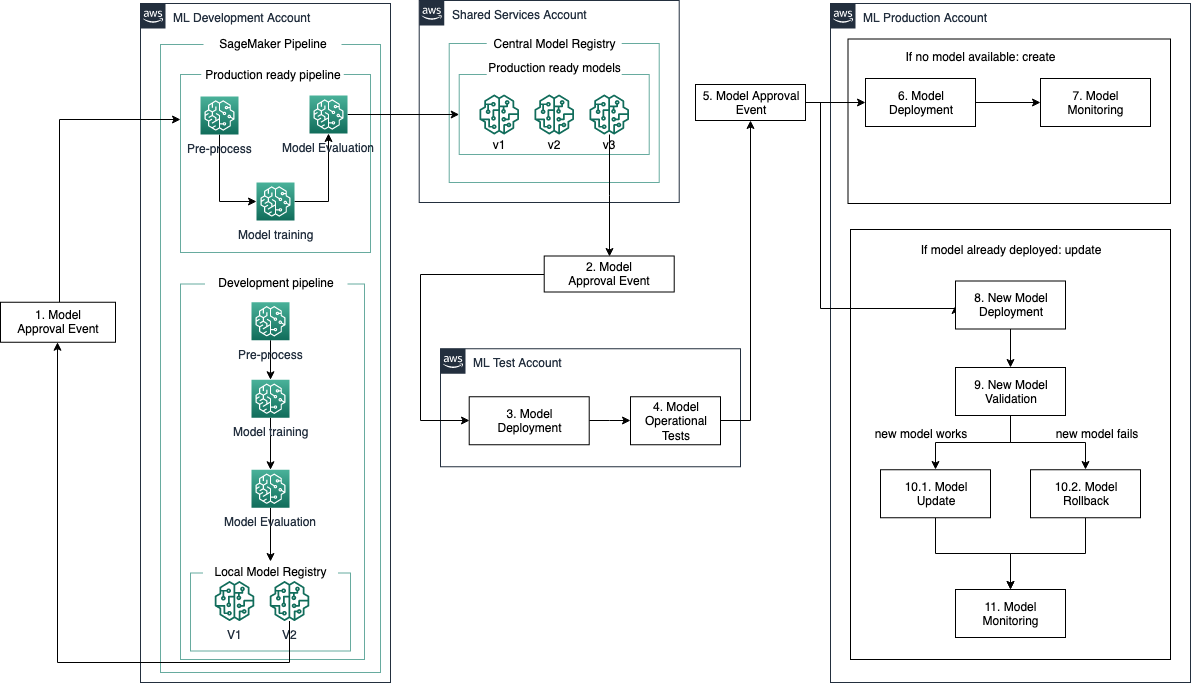
The following figure demonstrates a common pattern for the connection of SageMaker capabilities to create an end-to-end model building and deployment pipeline. In this example, a model is developed in SageMaker using SageMaker Processing jobs to run data processing code that is used to prepare data for an ML algorithm. SageMaker Training jobs are then used to train an ML model on the data produced by the processing job. The model artifacts and associated metadata are stored in the SageMaker Model Registry as the last step of the training process. This is orchestrated by SageMaker Pipelines, which is a purpose-built CI/CD service for ML that helps automate and manage ML workflows at scale.
After the model is approved, it is tested in production with either an A/B testing or a shadow deployment. After the model is validated in production, we use the model registry to approve the model for production rollout to a SageMaker endpoint using one of the deployment guardrails options.
When the model update process is complete, SageMaker Model Monitor continually monitors the model performance for drifts into the model and data quality. This process is automated to multiple use cases using SageMaker Project templates mapping the infrastructure deployment to a multi-account setup in order to ensure complete resource isolation and easier cost control.

Single-model endpoint deployment patterns
When deploying models to a production environment for the first time, you don’t have a model running to compare with, and the deployed model will be the one used by your business application. After the model is deployed and monitored in a production environment, you might want to update the model, either on a regular basis or on demand, when new data is available or when your model has a performance gap detected. When updating an existing model, you want to ensure that the new model performs better than the current one and can handle the prediction request traffic from your business applications. During this validation period, you want the current model to still be available for a possible rollback to minimize the risk of downtime to your applications.
In a broader model development picture, models are typically trained in a data science development account. This includes experimentation workflows often used in the development of models as well as retraining workflows used in production-ready pipelines. All of the metadata for these experiments can be tracked using Amazon SageMaker Experiments during development. After the workflow is incorporated into a pipeline for production use, the metadata is automatically tracked through SageMaker Pipelines. To keep track of viable production models in one place, after experimentation has brought a model’s performance metrics (precision, recall, and so on) to an acceptable level for production, a condition step in the SageMaker pipeline allows the model to be registered into the model registry.
The model registry allows you to trigger the deployment of this model with a manual or automated approval process. This deployment takes place in an ML test account where operational tests such as integration tests, unit tests, model latency, and any additional model validation can be performed against the new model version. Note that A/B testing and shadow testing are not performed in the ML test account, but rather in the ML production account.
After the model passes all validations in the test account, it’s ready to be deployed to a production environment. A new approval process triggers this deployment, and SageMaker deployment guardrails allow for a controlled release and transparent model update process according to the traffic shifting mode selected.
The following diagram illustrates this solution architecture.
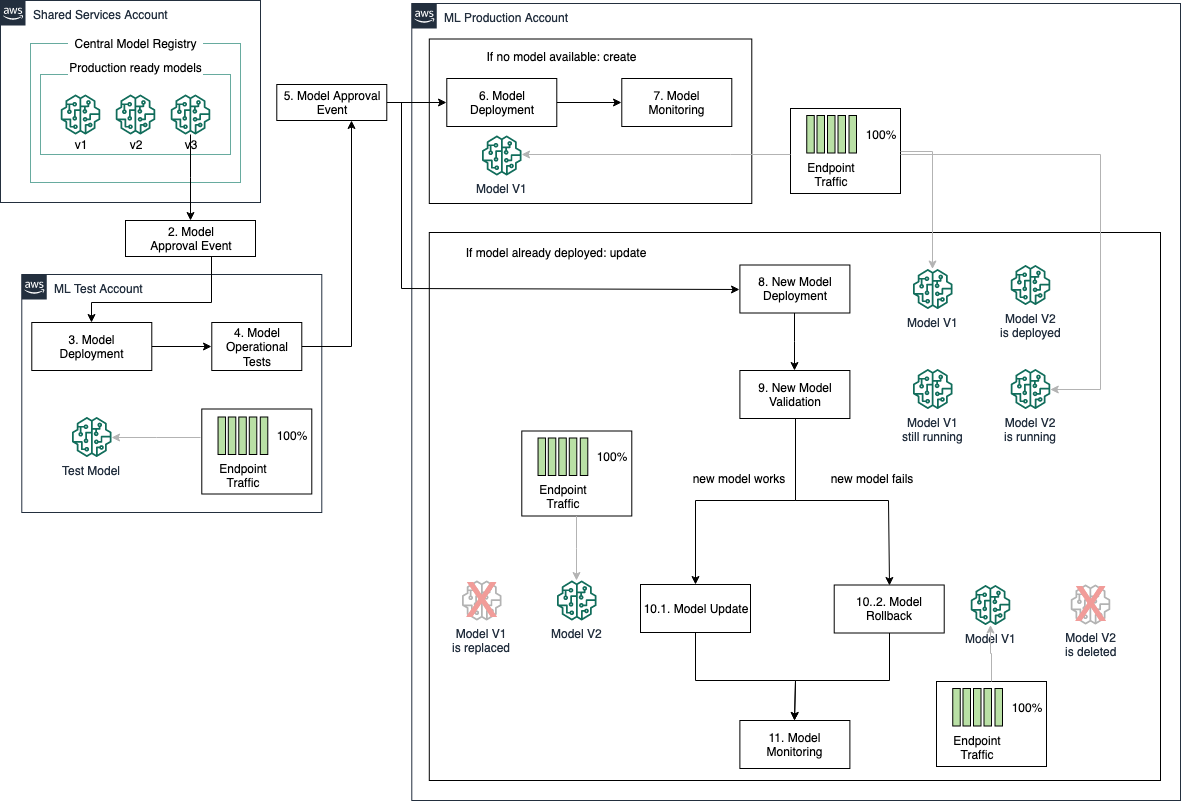
All at once traffic shifting
The all at once traffic shifting mode allows you to update a new model version (green fleet) by completely shifting 100% of the traffic from your current model (blue fleet) to your new model. With this option, you can configure a baking period during which both versions of your model are still running, and you can quickly and automatically roll back to the current version if your new model doesn’t perform as expected. The downside of this option is that all your data traffic is affected at once, so if there is an issue with your model deployment, all users using the application during the deployment process are affected. The following architecture shows how the all at once traffic shifting option handles model updates.
All at once traffic shifting can be incorporated into your MLOps tooling by defining an endpoint deployment configuration with BlueGreenUpdatePolicy set to ALL_AT_ONCE. In your MLOps pipeline, after a new model is approved for deployment to the ML production account, SageMaker checks if your model endpoint already exists. If so, the ALL_AT_ONCE configuration triggers an endpoint update that follows the architecture. Your endpoint rollback is controlled based on CloudWatch alarms defined by your endpoint AutoRollbackConfiguration, which when triggered automatically starts the model rollback to your current model version.
Canary traffic shifting
The canary traffic shifting mode allows you to test your new model (green fleet) with a small portion of the data traffic before either updating the running model (blue fleet) to the new version or rolling back the new version, depending on the outcome of the canary testing. The portion of the traffic used to test the new model is called the canary, and in this option your risk of a problematic new model is minimized to the canary traffic while the update time is still minimized.
Canary deployments allow you to minimize the risk of implementing a new model version by exposing the new model version to a smaller group of users to monitor effectiveness over a period of time. The downside is managing multiple versions for a period of time that allows for gathering performance metrics that are meaningful enough to determine performance impact. The benefit is the ability to isolate risk to a smaller group of users.
Canary traffic shifting can be incorporated into your MLOps tooling by defining an endpoint deployment configuration with a BlueGreenUpdatePolicy set to CANARY and defining the CanarySize to determine how much of your endpoint traffic should be redirected to a new model version. Similarly to all at once option, in your MLOps pipeline, after a new model is approved for deployment to the ML production account, SageMaker checks if your model endpoint already exists. If so, the CANARY configuration triggers an endpoint update that follows the architecture outlined in the following diagram. Your endpoint rollback is controlled based on CloudWatch alarms defined by your endpoint AutoRollbackConfiguration that when triggered automatically starts the model rollback to your current model version. Useful alarm types to deploy here are 500 status codes and model latency; however, these alarm settings should be customized to your specific business use case and ML technology.

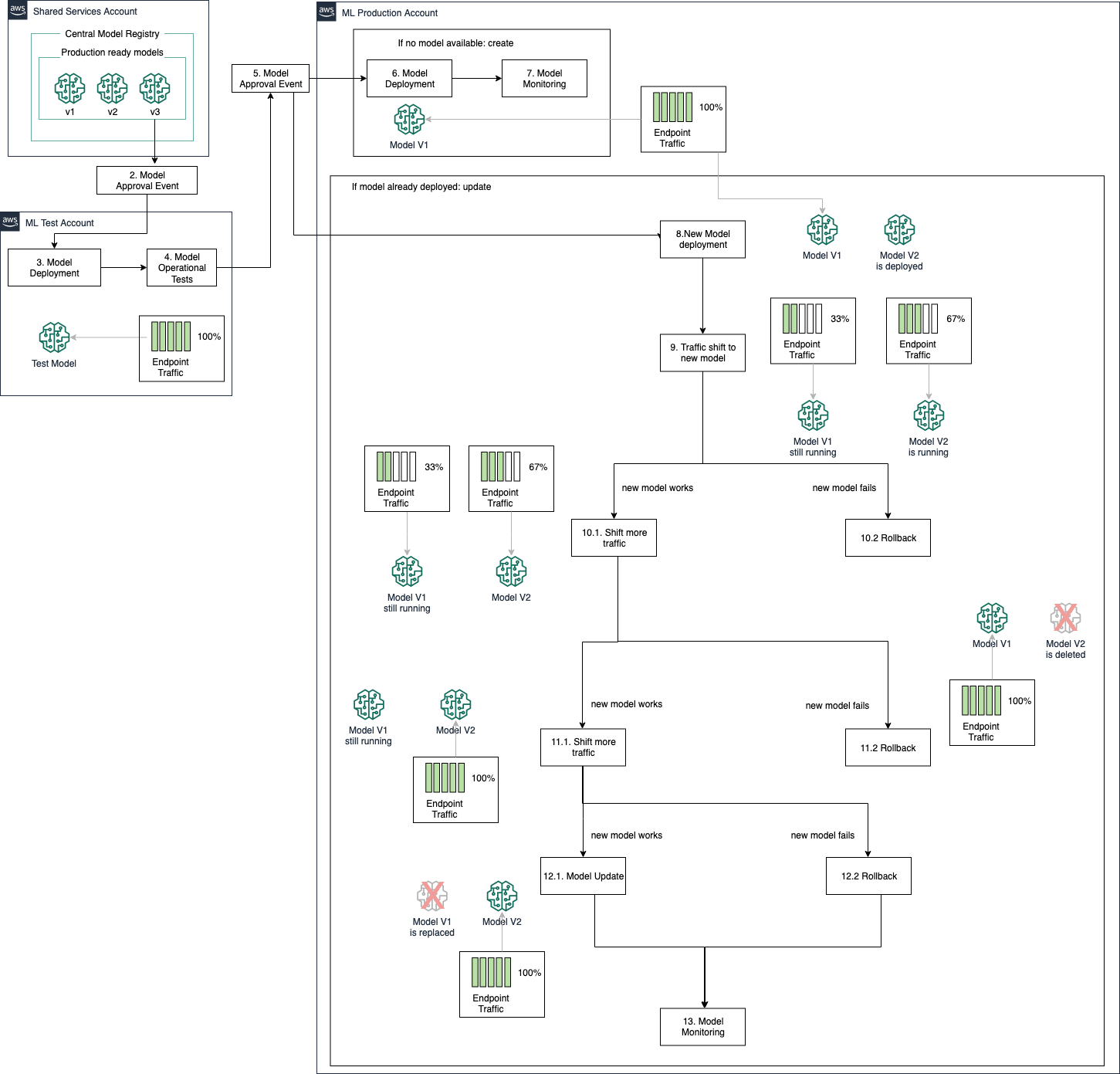
Linear traffic shifting
In the linear traffic shifting model, you gradually change the traffic from your current model (blue fleet) to your new model version (green fleet) by increasing the data traffic sent to the new model in steps. This way, the proportion of traffic used to test your new model version gradually increases with each step, and a baking time for each step ensures that your model is still operational with the new traffic. With this option, you minimize the risk of deploying a low-performing model and gradually expose the new model to more data traffic. The downside of this approach is that your update time is longer and the costs of the running both models in parallel are increased.
Linear traffic shifting can be incorporated into your MLOps tooling by defining an endpoint deployment configuration with BlueGreenUpdatePolicy set to LINEAR and defining the LinearStepSize to determine how much of your traffic should be redirected to a new model in each step. Similarly to all at once option, in your MLOps pipeline, after a new model is approved for deployment to the ML production account, SageMaker checks if your model endpoint already exists. If so, the LINEAR configuration triggers an endpoint update that follows the architecture indicated in the following diagram. Your endpoint rollback is controlled based on CloudWatch alarms defined by your endpoint AutoRollbackConfiguration that when triggered automatically starts the model rollback to your current model version.
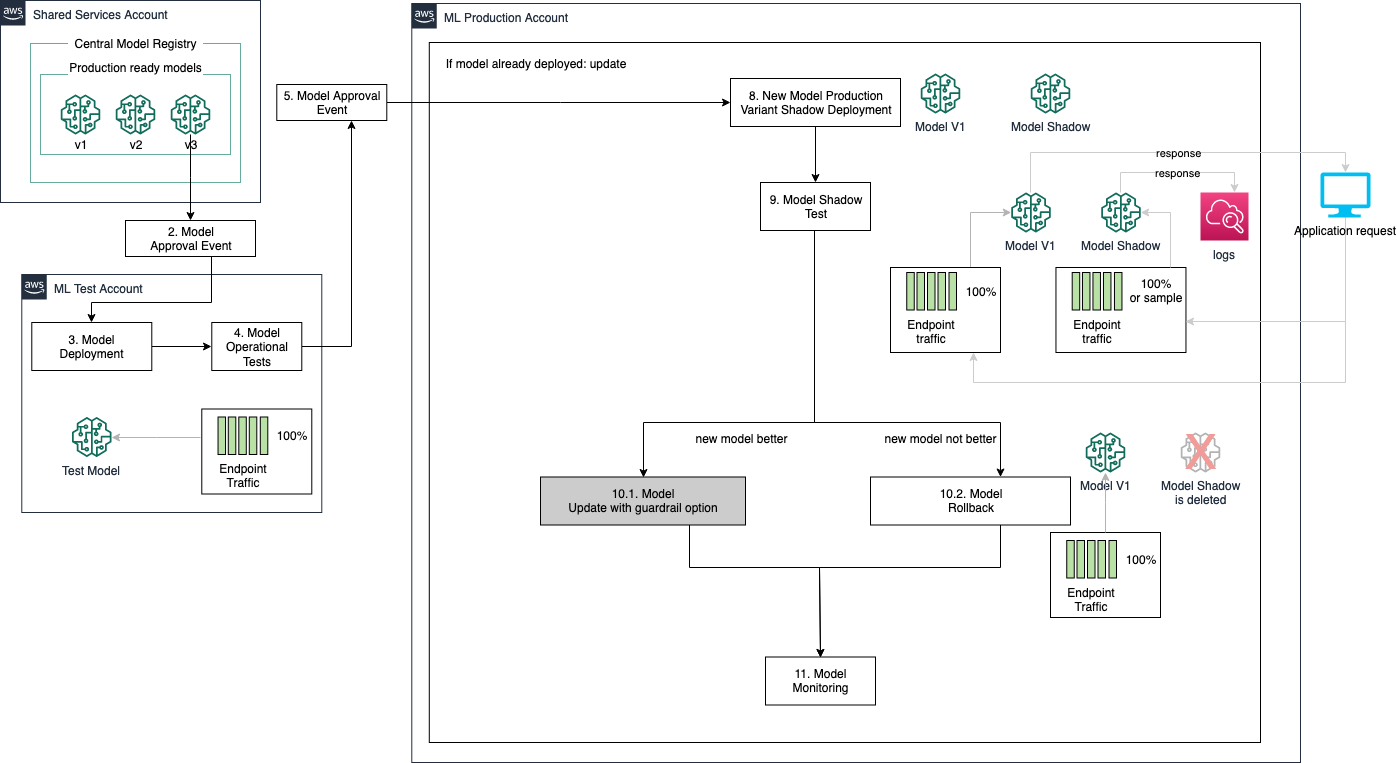
Deployment patterns with model production variants
Independently from the deployment pattern that you chose for your application, you can also utilize production variants to validate your model performance before updating your endpoint or implement additional deployment patterns such as shadow deployments. In this case, you want to add a manual or automated process to select the best model to be deployed before updating your endpoint. The following architecture shows how your endpoint traffic and response behave in a shadow deployment scenario. In this scenario, each prediction request is submitted to both the new and deployed models; however, only the currently deployed model serves the prediction response to the business application, while the prediction served from the new model is maintained only for analysis in performance against the currently deployed model. After model performance is evaluated, the new model version can be deployed to service prediction response traffic to business applications.
Rollback
Independently from the deployment strategy that you chose for your model deployment, you want to be able roll back to the previous model version if your new model performance is lower than your current model performance. To do so while minimizing the downtime of your application, you need to keep your current model running in parallel to the new one until you are confident that your new model performs better than the current one.
SageMaker deployment guardrails allow you to set alarms and automatically roll back to previous model versions during the model validation period. After the validation period is over, you might still need to roll back to a previous model version to solve a new problem that is discovered after the model update is complete. To do so, you can take advantage of the SageMaker model registry to reject and approved models and trigger a rollback process.
Conclusion
In this post, you learned how to combine SageMaker endpoint model variants and deployment guardrails with MLOps capabilities in order to create end-to-end patterns for model development. We provided an example implementation for canary and linear shifting deployment guardrails connected with SageMaker pipelines and the model registry via a SageMaker custom project. As a next step, try adapting the following template to implement the deployment strategy of your organization.
References
- Getting started with deploying real-time models on Amazon SageMaker
- Model Hosting Patterns in SageMaker: Best practices in testing and updating models on SageMaker
- Dynamic A/B testing for machine learning models with Amazon SageMaker MLOps projects
- Take advantage of advanced deployment strategies using Amazon SageMaker deployment guardrails
- Minimize the production impact of ML model updates with Amazon SageMaker shadow testing
About the authors
 Maira Ladeira Tanke is an ML Specialist Solutions Architect at AWS. With a background in data science, she has 9 years of experience architecting and building ML applications with customers across industries. As a technical lead, she helps customers accelerate their achievement of business value through emerging technologies and innovative solutions. In her free time, Maira enjoys traveling and spending time with her family someplace warm.
Maira Ladeira Tanke is an ML Specialist Solutions Architect at AWS. With a background in data science, she has 9 years of experience architecting and building ML applications with customers across industries. As a technical lead, she helps customers accelerate their achievement of business value through emerging technologies and innovative solutions. In her free time, Maira enjoys traveling and spending time with her family someplace warm.
 Clay Elmore is an AI/ML Specialist Solutions Architect at AWS. After spending many hours in a materials research lab, his background in chemical engineering was quickly left behind to pursue his interest in machine learning. He has worked on ML applications in many different industries ranging from energy trading to hospitality marketing. Clay has a special interest in bringing software development practices to ML and guiding customers towards repeatable, scalable solutions by using these principles. In his spare time, Clay enjoys skiing, solving Rubik’s cubes, reading, and cooking.
Clay Elmore is an AI/ML Specialist Solutions Architect at AWS. After spending many hours in a materials research lab, his background in chemical engineering was quickly left behind to pursue his interest in machine learning. He has worked on ML applications in many different industries ranging from energy trading to hospitality marketing. Clay has a special interest in bringing software development practices to ML and guiding customers towards repeatable, scalable solutions by using these principles. In his spare time, Clay enjoys skiing, solving Rubik’s cubes, reading, and cooking.
 Shelbee Eigenbrode is a Principal AI and Machine Learning Specialist Solutions Architect at AWS. She has been in technology for 24 years spanning multiple industries, technologies, and roles. She is currently focusing on combining her DevOps and ML background into the domain of MLOps to help customers deliver and manage ML workloads at scale. With over 35 patents granted across various technology domains, she has a passion for continuous innovation and using data to drive business outcomes. Shelbee is a co-creator and instructor of the Practical Data Science specialization on Coursera. She is also the Co-Director of Women In Big Data (WiBD), Denver chapter. In her spare time, she likes to spend time with her family, friends, and overactive dogs.
Shelbee Eigenbrode is a Principal AI and Machine Learning Specialist Solutions Architect at AWS. She has been in technology for 24 years spanning multiple industries, technologies, and roles. She is currently focusing on combining her DevOps and ML background into the domain of MLOps to help customers deliver and manage ML workloads at scale. With over 35 patents granted across various technology domains, she has a passion for continuous innovation and using data to drive business outcomes. Shelbee is a co-creator and instructor of the Practical Data Science specialization on Coursera. She is also the Co-Director of Women In Big Data (WiBD), Denver chapter. In her spare time, she likes to spend time with her family, friends, and overactive dogs.
 Qiyun Zhao is a Senior Software Development Engineer with the Amazon SageMaker Inference Platform team. He is the lead developer of the deployment guardrails and shadow deployments, and he focuses on helping customers to manage ML workloads and deployments at scale with high availability. He also works on platform architecture evolutions for fast and secure ML jobs deployment and running ML online experiments at ease. In his spare time, he enjoys reading, gaming, and traveling.
Qiyun Zhao is a Senior Software Development Engineer with the Amazon SageMaker Inference Platform team. He is the lead developer of the deployment guardrails and shadow deployments, and he focuses on helping customers to manage ML workloads and deployments at scale with high availability. He also works on platform architecture evolutions for fast and secure ML jobs deployment and running ML online experiments at ease. In his spare time, he enjoys reading, gaming, and traveling.