Posted by Arjun Gopalan, Software Engineer, Google Research
Edited by Robert Crowe, TensorFlow Developer Advocate, Google Research
Introduction
Neural Structured Learning (NSL) is a framework in TensorFlow that can be used to train neural networks with structured signals. It handles structured input in two ways: (i) as an explicit graph, or (ii) as an implicit graph where neighbors are dynamically generated during model training. NSL with an explicit graph is typically used for Neural Graph Learning while NSL with an implicit graph is typically used for Adversarial Learning. Both of these techniques are implemented as a form of regularization in the NSL framework. As a result, they only affect the training workflow and so, the model serving workflow remains unchanged. In the rest of this post, we will mostly focus on how graph regularization can be implemented using the NSL framework in TFX.
The high-level workflow for building a graph-regularized model using NSL entails the following steps:
- Build a graph, if one is not available.
- Use the graph and the input example features to augment the training data.
- Use the augmented training data to apply graph regularization to a given model.
These steps don’t immediately map onto existing TFX pipeline components. However, TFX supports custom components which allow users to implement custom processing within their TFX pipelines. See this blog post for an introduction to custom components in TFX. So, to create a graph-regularized model in TFX incorporating the above steps, we will make use of additional custom TFX components.
To illustrate an example TFX pipeline with NSL, let’s consider the task of sentiment classification on the IMDB dataset. A colab-based tutorial demonstrating the use of NSL for this task with native TensorFlow is available here, which we will use as the basis for our TFX pipeline example.
Graph Regularization With Custom TFX Components
To build a graph-regularized NSL model in TFX for this task, we will define three custom components using the custom Python functions approach. Here is a TFX pipeline schematic for our example using these custom components. For brevity, we have skipped components that typically come after the Trainer component like the Evaluator, Pusher, etc.
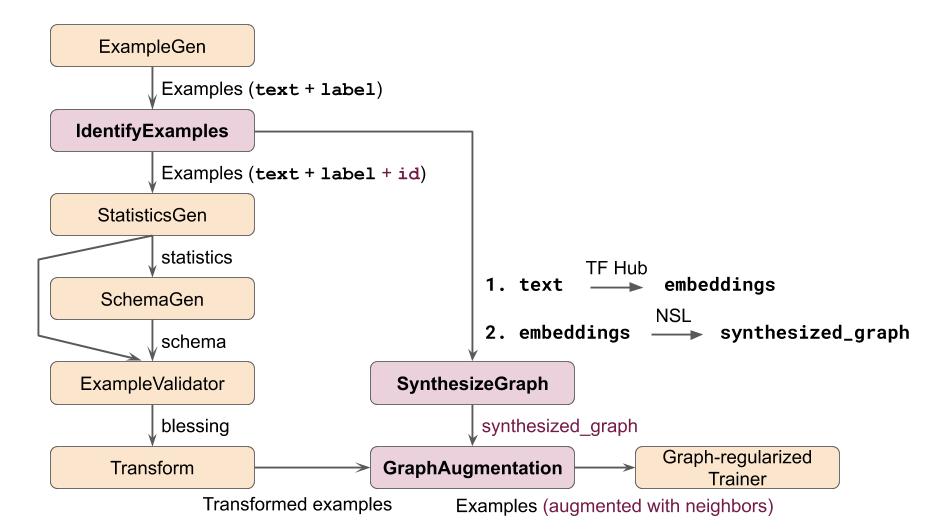
Figure 1: Example TFX pipeline for text classification using graph regularization
In this figure, only the custom components (in pink) and the Graph-regularized Trainer component have NSL-related logic. It’s worth noting that the custom components shown here are only illustrative and it may be possible to build a functionally equivalent pipeline in other ways. We now describe each of the custom components in further detail and show code snippets for them.
IdentifyExamples
This custom component assigns a unique ID to each training example that is used to associate each training example with its corresponding neighbors from the graph.
def IdentifyExamples(
orig_examples: InputArtifact[Examples],
identified_examples: OutputArtifact[Examples],
id_feature_name: Parameter[str],
component_name: Parameter[str]
) -> None:
# Compute the input and output URIs.
...
# For each input split, update the TF.Examples to include a unique ID.
with beam.Pipeline() as pipeline:
(pipeline
| 'ReadExamples' >> beam.io.ReadFromTFRecord(
os.path.join(input_dir, '*'),
coder=beam.coders.coders.ProtoCoder(tf.train.Example))
| 'AddUniqueId' >> beam.Map(make_example_with_unique_id, id_feature_name)
| 'WriteIdentifiedExamples' >> beam.io.WriteToTFRecord(
file_path_prefix=os.path.join(output_dir, 'data_tfrecord'),
coder=beam.coders.coders.ProtoCoder(tf.train.Example),
file_name_suffix='.gz'))
identified_examples.split_names = orig_examples.split_names
return
The
make_example_with_unique_id()function updates a given example to include an additional feature containing a unique ID.SynthesizeGraph
As mentioned above, in the IMDB dataset, no explicit graph is given as an input. So, we will build one before we can demonstrate graph regularization. For this example, we will use a pre-trained text embedding model to convert raw text in the movie reviews to embeddings, and then use the resulting embeddings to build a graph.
The SynthesizeGraph custom component handles graph building for our example and notice that it defines a new
ArtifactcalledSynthesizedGraph, which will be the output of this custom component.
class SynthesizedGraph(tfx.types.artifact.Artifact):
"""Output artifact of the SynthesizeGraph component"""
TYPE_NAME = 'SynthesizedGraphPath'
PROPERTIES = {
'span': standard_artifacts.SPAN_PROPERTY,
'split_names': standard_artifacts.SPLIT_NAMES_PROPERTY,
}
@component
def SynthesizeGraph(
identified_examples: InputArtifact[Examples],
synthesized_graph: OutputArtifact[SynthesizedGraph],
similarity_threshold: Parameter[float],
component_name: Parameter[str]
) -> None:
# Compute the input and output URIs
...
# We build a graph only based on the 'train' split which includes both
# labeled and unlabeled examples.
create_embeddings(train_input_examples_uri, output_graph_uri)
build_graph(output_graph_uri, similarity_threshold)
synthesized_graph.split_names = artifact_utils.encode_split_names(
splits=['train'])
return
The
create_embeddings()function involves converting the text in movie reviews to corresponding embeddings using some pre-trained model on TensorFlow Hub. Thebuild_graph()function involves invoking thebuild_graph()API in NSL.GraphAugmentation
The purpose of this custom component is to combine the example features (text in the movie reviews) with the graph built from embeddings to produce an augmented training dataset. The resulting training examples will include features from their corresponding neighbors as well.
def GraphAugmentation(
identified_examples: InputArtifact[Examples],
synthesized_graph: InputArtifact[SynthesizedGraph],
augmented_examples: OutputArtifact[Examples],
num_neighbors: Parameter[int],
component_name: Parameter[str]
) -> None:
# Compute the input and output URIs
...
# Separate out the labeled and unlabeled examples from the 'train' split.
train_path, unsup_path = split_train_and_unsup(train_input_uri)
# Augment training data with neighbor features.
nsl.tools.pack_nbrs(
train_path, unsup_path, graph_path, output_path, add_undirected_edges=True,
max_nbrs=num_neighbors
)
# Copy the 'test' examples from input to output without modification.
...
augmented_examples.split_names = identified_examples.split_names
return
The
split_train_and_unsup()function involves splitting the input Examples into labeled and unlabeled examples and thepack_nbrs()NSL API creates the augmented training dataset.Graph-regularized Trainer
Now that all of our custom components are implemented, the remaining NSL-specific addition to the TFX pipeline is in the
Trainercomponent. Below is a simplified view of the graph-regularizedTrainercomponent.
estimator = tf.estimator.Estimator(
model_fn=feed_forward_model_fn, config=run_config, params=HPARAMS)
# Create a graph regularization config.
graph_reg_config = nsl.configs.make_graph_reg_config(
max_neighbors=HPARAMS.num_neighbors,
multiplier=HPARAMS.graph_regularization_multiplier,
distance_type=HPARAMS.distance_type,
sum_over_axis=-1)
# Invoke the Graph Regularization Estimator wrapper to incorporate
# graph-based regularization for training.
graph_nsl_estimator = nsl.estimator.add_graph_regularization(
estimator,
embedding_fn,
optimizer_fn=optimizer_fn,
graph_reg_config=graph_reg_config)
...
As you can see, once a base model has been created (in this case a feed-forward neural network), it’s straightforward to convert it to a graph-regularized model by invoking the NSL wrapper API.
And that’s it! We now have all of the missing pieces that are required to build a graph-regularized NSL model in TFX. A colab-based tutorial that demonstrates this example end-to-end in TFX is available here. Feel free to try it and customize it as you want!
Adversarial Learning
As mentioned in the introduction above, another aspect of Neural Structured Learning is adversarial learning where instead of using explicit neighbors from a graph for regularization, implicit neighbors are created dynamically and adversarially to confuse the model. So, regularizing using adversarial examples is an effective way to improve a model’s robustness. Adversarial learning using NSL can be easily integrated into a TFX pipeline. It does not require any custom components and only the trainer component needs to be updated to invoke the adversarial regularization wrapper API in NSL.
Summary
We have demonstrated how to build a graph-regularized model with NSL in TFX using custom components. It’s certainly possible to build graphs in other ways as well as structure the overall pipeline differently. We hope that this example provides a basis for your own NSL workflows.
Additional Links
For more information on NSL, check out the following resources:
Acknowledgements:
We’d like to thank the Neural Structured Learning and TFX teams at Google as well as Aurélien Geron for their support and contributions.