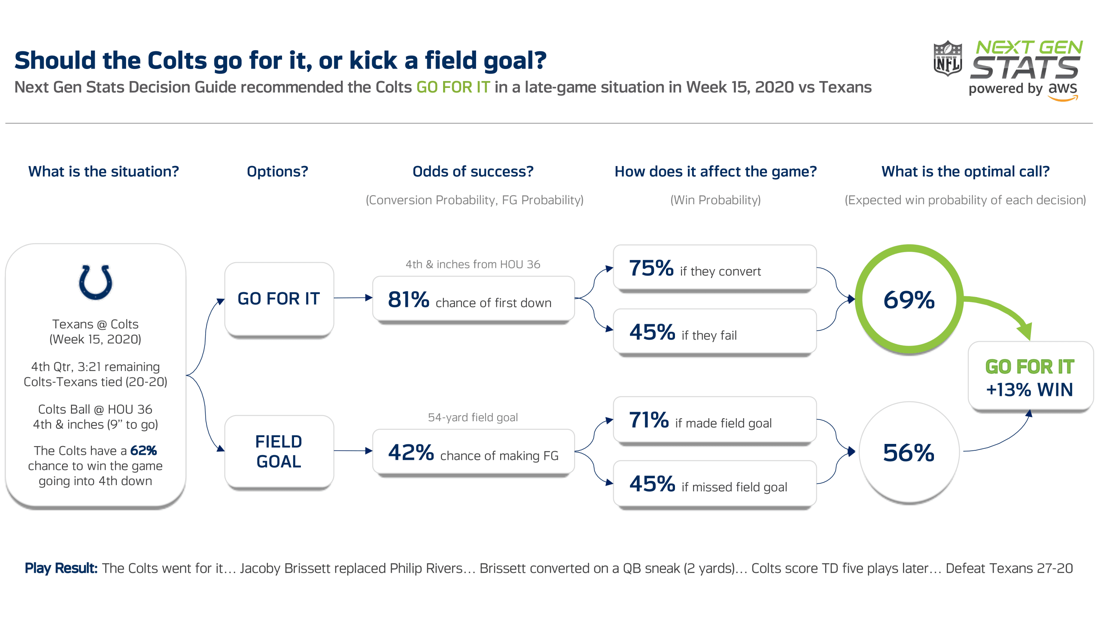
It is fourth-and-one on the Texans’ 36-yard line with 3:21 remaining on the clock in a tie game. Should the Colts’ head coach Frank Reich send out kicker Rodrigo Blankenship to attempt a 54-yard field goal or rely on his offense to convert a first down? Frank chose to go for it, leading to a first-down conversion and an eventual touchdown to seal the win. Was this the optimal call or a gamble that ended up working? Through a collaboration between the NFL’s Next Gen Stats team and AWS, NFL fans can now get an answer to this question.
Like the Colts-Texans example, the decision of what to do on a fourth down late in the game can be the difference between a win and a loss. While it can be tempting to focus on fourth-downs late in the game, even fourth-down decisions that occur early in the game can be important. Fourth-down decisions early in the game can have reverberating effects that compound over the course of a game or season. Head coaches who consistently make the right call on the fourth down put their teams in the best possible position to win, but how does a coach know what the right call is? What factors do they have to weigh, and how can a computer give fans insights into this complicated decision-making process?
The problem can be represented as a tree of choices and their respective potential outcomes. On any fourth down, a team has three main options: punt, kick a field goal, or go for it. If a team punts, their opponent generally gains possession of the ball at some point farther down the field. On a field goal attempt, the two main outcomes are the offensive team either makes the field goal or misses the field goal. If they make the field goal, they gain three points. If they miss the field goal, the defense gains possession of the ball at the location of the attempt. Similarly, if a team chooses to go for it, there are two main outcomes. Either the team gains enough yards for a first-down (or potentially a touchdown), or the defense gains possession of the ball at the end of the play.
When coaches decide what to do on a fourth-down, they must weigh all the potential outcomes and the impact of these outcomes on the odds of winning the game. To help fans understand a coach’s decision, the NFL and AWS partnered to create the Next Gen Stats Decision Guide. The Next Gen Stats Decision Guide is a suite of machine learning (ML) models designed to determine the optimal fourth-down call. The decision guide does this by predicting the odds of each potential fourth-down outcome and the resulting odds of winning the game. By comparing the odds of winning the game for each fourth-down choice, the Next Gen Stats Decision Guide provides a data-driven answer to that optimal fourth-down call.
Going back to Frank Reich’s decision, the Colts needed 0.25 yards to gain a first down. What is the probability that they convert? As shown in the following figure, our fourth-down conversion probability model predicts an 81% chance. When paired with the updated win probability of 75% if they convert, we get an expected win probability of 69%. However, if they choose to kick a field goal, the chance of making the field goal is around 42%. Paired with the win probability of 71% if successful, we get an expected win probability of 56%. Based on these expected probabilities, the Next Gen Stats Decision Guide recommends going for it with a 13% difference.
In addition to fourth-down decisions, coaches must decide what to do after scoring a touchdown. The team can kick an extra point (+1 point) or elect to attempt a two-point conversion (+2 points). The application of the Next Gen Stats Decision Guide to fourth-down plays and after-touchdown plays has been presented before, and is a good primer for this discussion. In this post, we focus on the models that determine the probability of converting a fourth-down conversion. We share how we feature engineered and developed the ML model and metrics that were used to evaluate the quality of predictions.
Go-for-it model
If a team chooses to go for it on a fourth-down, the team must gain enough yards to make a first-down on that single play. This means that not all fourth-downs are equal. Some require the offense to gain less than a yard, while others may occasionally require the offense to gain more than 10 yards. The location on the field, time left on the clock, and relative strengths of the teams are among the important parameters in understanding the odds of success. In building the Go-for-it model, we examine these and other factors to determine which features are most important in constructing a performant model.
Problem formulation
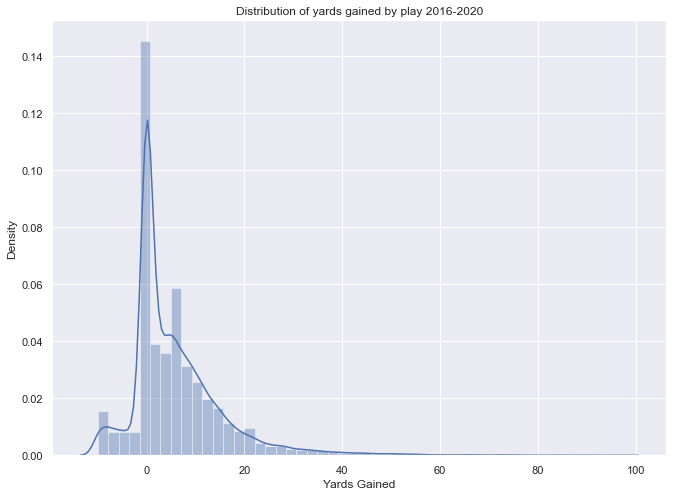
The odds of converting on a fourth-down can be formulated as a multi-class classifier. In this formulation, each class represents the offense gaining some number of yards on the play. The probability of each class is used as the odds that the team will gain that number of yards on the play. The following histogram shows the yards gained on third- and fourth-down plays from 2016–2020. An initial approach might be to make each class in the model represent an integer number of yards gained, but the histogram shows that this approach will be difficult. Classes in the long tail of the graph (roughly 40–100 yards) occur infrequently, and this sort of class imbalance can be difficult account for in model training.
To combat the potential class imbalance, we used an unequal distribution of yards to classes. Instead of each yard gained being an individual class, we used 17 different classes to encompass all the potential outcomes shown in in the graph.
As shown in the following table, we use one class for all negative or zero-yards-gained results. Between 1–15 yards gained, we use one class for each potential outcome. The reason for this breakdown is that 88% of fourth-down plays have somewhere between 1–15 yards to go. This enables the model to capture a large majority of fourth-down situations with high fidelity. To address plays with more than 15 yards to go, we employ a decay factor to represent the decreasing probability of getting more yards on a single play.
| Yards | Model Classes (17) |
| Less than or equal to 0 | 0 |
| 1–15 yards | 1–15 (15 classes) |
| 16+ yards | 16 |
The following equation shows the decay factor used where the probability of converting ( Pconversion ) is the probability of getting 16 or more yards () divided by the actual distance needed for a first down (d ) minus 15 yards.
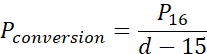
Features
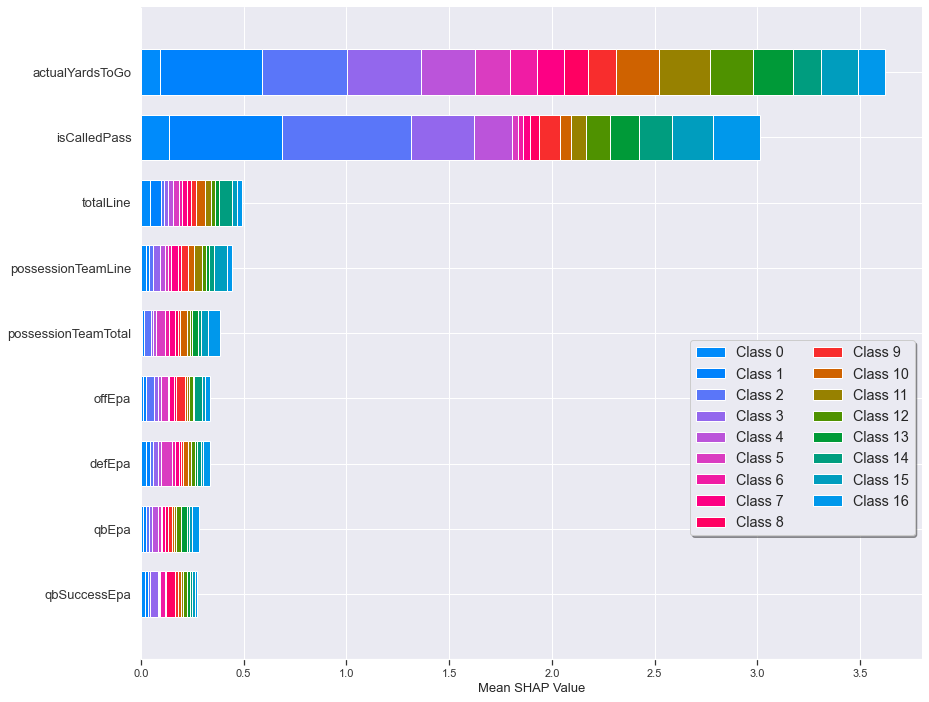
Just as a coach needs to consider many factors when deciding what to do in a game, the conversion probability models also have many potential features to use. Part of the modeling process involved determining which features to incorporate into the model. We used feature importance measures like correlation to help us identify several high-value features (see the following table). These features include the actual yards-to-go, the Vegas spread, and the historical aggregations of expected points added (EPA) by team and quarterback.
The actual yards-to-go is arguably the most important feature for this model, aligning with general football knowledge. The more yards a team needs to gain, the less likely the team is to achieve that outcome. What makes the actual yards-to-go metric even more valuable in this model is that it is derived from the NGS tracking data. Traditional NFL datasets often represent the yards-to-go as an integer, which obscures the variable nature of the game. With the NGS tracking data, we can get a measurement of the football’s location with sub-foot accuracy. This allows our model to understand the difference between fourth and inches versus fourth and 1 yard.
Although the actual yards-to-go is a clear metric to provide the model, some information is harder to quantify immediately and provide to the model. For example, a coach understands the unique skillsets of their team and the opposition, both on that day and historically. To assess coaching decisions, the model needs a way to use similar information. The Vegas lines are a useful condensation of vast amounts of situational and historical knowledge about the teams into a small set of numbers. Specifically, the point spread and the total points lines capture information about prevailing beliefs regarding the relative strengths of the teams, and the model found these values useful.
| Input Features | Description |
| actualYardsToGo | The yards to go as measured using NGS tracking data between the ball at snap and the yards-to-go marker |
| isCalledPass | Is the play predicted to be a pass or a rush? |
| totalLine | The closing spread line for the game |
| possessionTeamLine | The number of points the possession team is favored by according to Vegas |
| possessionTeamTotal | The number of total points the possession team is expected to score as indicated by the Vegas total and spread lines |
| offEpa | A team offense’s average expected points added per play over the last X number of plays in similar situations |
| defEpa | A team defense’s average expected points added allowed per play over the last X number of plays in similar situations |
| qbEpa | A team offense’s average expected points added per play over the last X number of plays when the quarterback on the field attempted a pass, run, or was sacked |
| qbSuccessEpa | Quarterback success EPA for the last N similar plays |
Similar to how the Vegas lines provide game-level insight into relative team strengths, we can use EPA values to provide insight into relative team strengths at a more granular level. These EPA values, calculated using other NGS models, provide insight into how the team has performed in similar situations in the past. The EPA models can be broken down by the offense, defense, and quarterback. This provides the model with information about how successful the respective teams have been in the past in addition to how successful the current quarterback has been. The following figure shows the relative importance of the features after HPO. As discussed earlier, this feature importance makes intuitive sense.
Model training
To train the model, we used all the data from third- and fourth-down plays from 2016–2019 regular seasons as the training set. We held out the data from 2020 for the testing set.
For model architecture, a handful of different models were compared, including XGBoost, PyTorch Tabular, and AutoML-based models. Of these options, the XGBoost model provided the best results. It is also explained by using the Shapely Additive Explanations (SHAP) feature importance measures. Because our goal is to optimize for conversion probabilities, we used the Brier score (probabilistic loss function) to measure the performance of our models. The Brier score measures the mean squared difference between predicted probability assigned to the possible outcomes and actual outcomes. A lower Brier score is considered better.
To optimize our models, we used Amazon SageMaker hyperparameter optimization (HPO) to fine-tune XGBoost parameters like learning rate, max depth, subsamples, alpha, and gamma. The SageMaker-managed HPO service helped us run multiple experiments in parallel to identify optimal hyperparameter configurations. Each experiment took only a few minutes because tuning jobs are distributed across 10 instances. In addition, we used SageMaker features, including automatic early stopping and warm starting from previous tuning jobs. This combined with custom metrics improved the performance of the model within minutes. Examples of various SageMaker-based HPO tuning jobs are available on GitHub.
Go-for-it model results
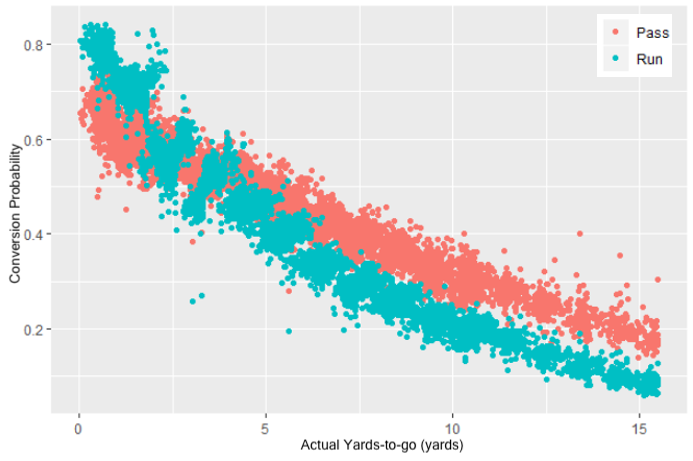
After training and HPO, the XGBoost model achieved a Brier score of 0.21. In addition to the Brier score, we examined the model predictions to ensure they were recreating known aspects of the game. For example, the odds of converting on a fourth-down play decrease as the number of yards needed for a first-down increase. The following figure shows the model’s predicted conversion probabilities as a function of the yards-to-go. We can observe two key trends. First, as expected, the conversion probability decreases as the yards-to-go increases. Second, a team is generally better off running the ball on short yards-to-go situations and passing the ball on long yards-to-go situations.
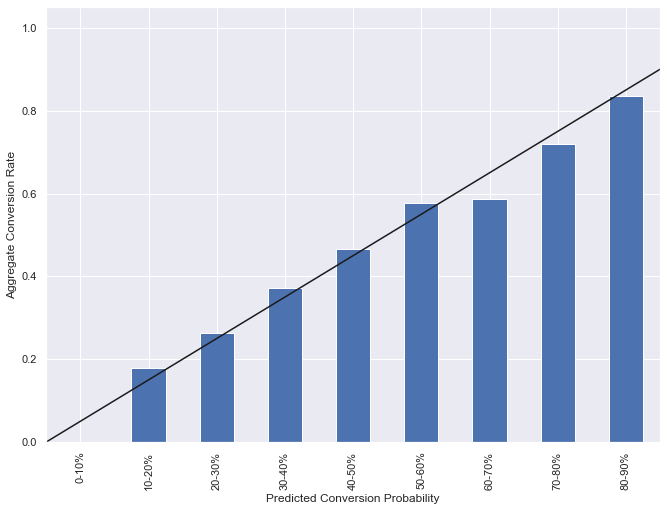
For the Next Gen Stats Decision Guide, it’s not sufficient for the model to make correct predictions. It must also assign valid probabilities to those predictions. To examine the validity of the model probabilities, we compare the probabilities against the aggregate play outcomes, as shown in the following graph. The model predictions were binned into 10%-wide categories from 0–90%. For each bin, the fraction of plays that were converted was calculated (bar height). For an ideal model, the bin heights should be roughly the midpoint of each bin (solid line). The following graph shows that when the model provides a conversion probability between 0–60%, the actual aggregate outcomes of these plays closely match the model’s predictions. For model predictions between 60–90%, the model slightly appears to underestimate the offense’s probabilities of converting (most notably between 60–70%). In situations where the agreement is poor, we can use postprocessing techniques to increase the agreement between play outcomes and the model probabilities. For an example for deep learning models, see Quantifying uncertainty in deep learning systems.
ML production pipeline
For the model in production, we used SageMaker for preprocessing, training, and postprocessing. The model is hosted using a highly scalable, available, and secured Amazon Elastic Kubernetes Service (Amazon EKS) for production usage. The following figure shows a high-level diagram of the production pipeline. All steps are automated and require minimal maintenance.

Summary
AWS and the NFL NGS team jointly developed the Next Gen Stats Decision Guide, which helps fans understand the choices coaches make at pivotal moments in the game. The odds of converting on a fourth-down play are a key component of the Next Gen Stats Decision Guide. In this post, we provided insight into how AWS helped the NFL create the model powering fourth-down conversions and discussed methods to assess model performance.
The NGS team will be hosting these models as part of the 2021 NFL season. Keep an eye out for the Next Gen Stats Decision Guide during the next NFL game.
You can find full examples of creating custom training jobs, implementing HPO, and deploying models on SageMaker at the AWS Labs GitHub repo. If you would like us to help and accelerate your use of ML, contact the Amazon ML Solutions Lab program.
About the Authors
 Selvan Senthivel is a Senior ML Engineer with Amazon ML Solutions Lab team at AWS, focusing on helping customers on Machine Learning, Deep Learning problems and end-to-end ML solutions. He was the founding engineering lead of Amazon Comprehend Medical service and contributed to the design/architecture of multiple AWS AI services.
Selvan Senthivel is a Senior ML Engineer with Amazon ML Solutions Lab team at AWS, focusing on helping customers on Machine Learning, Deep Learning problems and end-to-end ML solutions. He was the founding engineering lead of Amazon Comprehend Medical service and contributed to the design/architecture of multiple AWS AI services.
 Lin Lee Cheong is a Senior Scientist and Manager with the Amazon ML Solutions Lab team at Amazon Web Services. She works with strategic AWS customers to explore and apply artificial intelligence and machine learning to discover new insights and solve complex problems.
Lin Lee Cheong is a Senior Scientist and Manager with the Amazon ML Solutions Lab team at Amazon Web Services. She works with strategic AWS customers to explore and apply artificial intelligence and machine learning to discover new insights and solve complex problems.
 Tyler Mullenbach is a Principal Data Science Manager with AWS Professional Services. He leads a global team of data science consultants focusing on helping customers turn their data into insights and bring ML models to production.
Tyler Mullenbach is a Principal Data Science Manager with AWS Professional Services. He leads a global team of data science consultants focusing on helping customers turn their data into insights and bring ML models to production.
 Ankit Tyagi is a Senior Software Engineer with the NFL’s Next Gen Stats team. He focuses on backend data pipelines and machine learning for delivering stats to fans. Outside of work, you can find him playing tennis, experimenting with brewing beer, or playing guitar.
Ankit Tyagi is a Senior Software Engineer with the NFL’s Next Gen Stats team. He focuses on backend data pipelines and machine learning for delivering stats to fans. Outside of work, you can find him playing tennis, experimenting with brewing beer, or playing guitar.
 Mike Band is the Lead Analyst for NFL’s Next Gen Stats. He contributes to the ideation, development, and communication of advanced football performance metrics for the NFL Media Group, NFL Broadcast Partners, and fans.
Mike Band is the Lead Analyst for NFL’s Next Gen Stats. He contributes to the ideation, development, and communication of advanced football performance metrics for the NFL Media Group, NFL Broadcast Partners, and fans.
 Juyoung Lee is a Senior Software Engineer with the NFL’s Next Gen Stats. Her work focuses on designing and developing machine learning models to create stats for fans. On her spare time, she enjoys being active by playing Ultimate Frisbee and doing CrossFit.
Juyoung Lee is a Senior Software Engineer with the NFL’s Next Gen Stats. Her work focuses on designing and developing machine learning models to create stats for fans. On her spare time, she enjoys being active by playing Ultimate Frisbee and doing CrossFit.
 Michael Schaefer was the Director of Product and Analytics for NFL’s Next Gen Stats. His work focuses on the design and execution of statistics, applications, and content delivered to NFL Media, NFL Broadcaster Partners, and fans.
Michael Schaefer was the Director of Product and Analytics for NFL’s Next Gen Stats. His work focuses on the design and execution of statistics, applications, and content delivered to NFL Media, NFL Broadcaster Partners, and fans.
 Michael Chi is the Director of Technology for NFL’s Next Gen Stats. He is responsible for all technical aspects of the platform which is used by all 32 clubs, NFL Media and Broadcast Partners. In his free time, he enjoys being outdoors and spending time with his family.
Michael Chi is the Director of Technology for NFL’s Next Gen Stats. He is responsible for all technical aspects of the platform which is used by all 32 clubs, NFL Media and Broadcast Partners. In his free time, he enjoys being outdoors and spending time with his family.