LinkedIn: Shivam Sahni, Byron Hsu, Yanning Chen
Meta: Ankith Gunapal, Evan Smothers
This blog explores the integration of a custom triton kernel, Liger Kernel with torch.compile to enhance the performance of fine-tuning large language models (LLMs) using torchtune. torchtune, a PyTorch-native library, offers modular building blocks and customizable finetuning recipes which include torch.compile support for various LLMs, while Liger Kernel provides optimized Triton kernels to improve training efficiency and reduce memory usage. The integration involves modifying the TransformerDecoder module in torchtune to bypass the linear layer computation, allowing the Liger Fused Linear Cross Entropy Loss to handle the forward projection weights. Experiments conducted on an NVIDIA A100 instance demonstrate that torch.compile outperforms PyTorch Eager in throughput and memory efficiency, with Liger Kernel further reducing peak memory allocation and enabling larger batch sizes. The results show a 47% reduction in peak memory at batch size 256 and a marginal increase in throughput with meta-llama/Llama-3.2-1B , confirming the effectiveness of the integration without affecting the loss curves.
Introduction to torchtune
torchtune is a PyTorch-native library which has been designed for finetuning LLMs. torchtune provides composable and modular building blocks along with finetuning recipes that can be easily customized for your use case, as will be shown in this blog.
torchtune provides:
- PyTorch implementations of popular LLM model architectures from Llama, Gemma, Mistral, Phi, and Qwen model families
- Hackable training recipes for full finetuning, LoRA, QLoRA, DPO, PPO, QAT, knowledge distillation, and more
- Out-of-the-box memory efficiency, performance improvements, and scaling with the latest PyTorch APIs, including
torch.compile - YAML configs for easily configuring training, evaluation, quantization or inference recipes
- Built-in support for many popular dataset formats and prompt templates
Introduction to Liger Kernel
Liger Kernel is an open source library of optimized Triton kernels designed to enhance the efficiency and scalability of training Large Language Models (LLMs). It focuses on kernel-level optimizations such as operation fusing and input chunking, achieving significant improvements in training throughput and GPU memory usage compared to existing implementations like those from HuggingFace. By using a single line of code, Liger Kernel can improve training throughput by 20% and reduce memory usage by 60%.
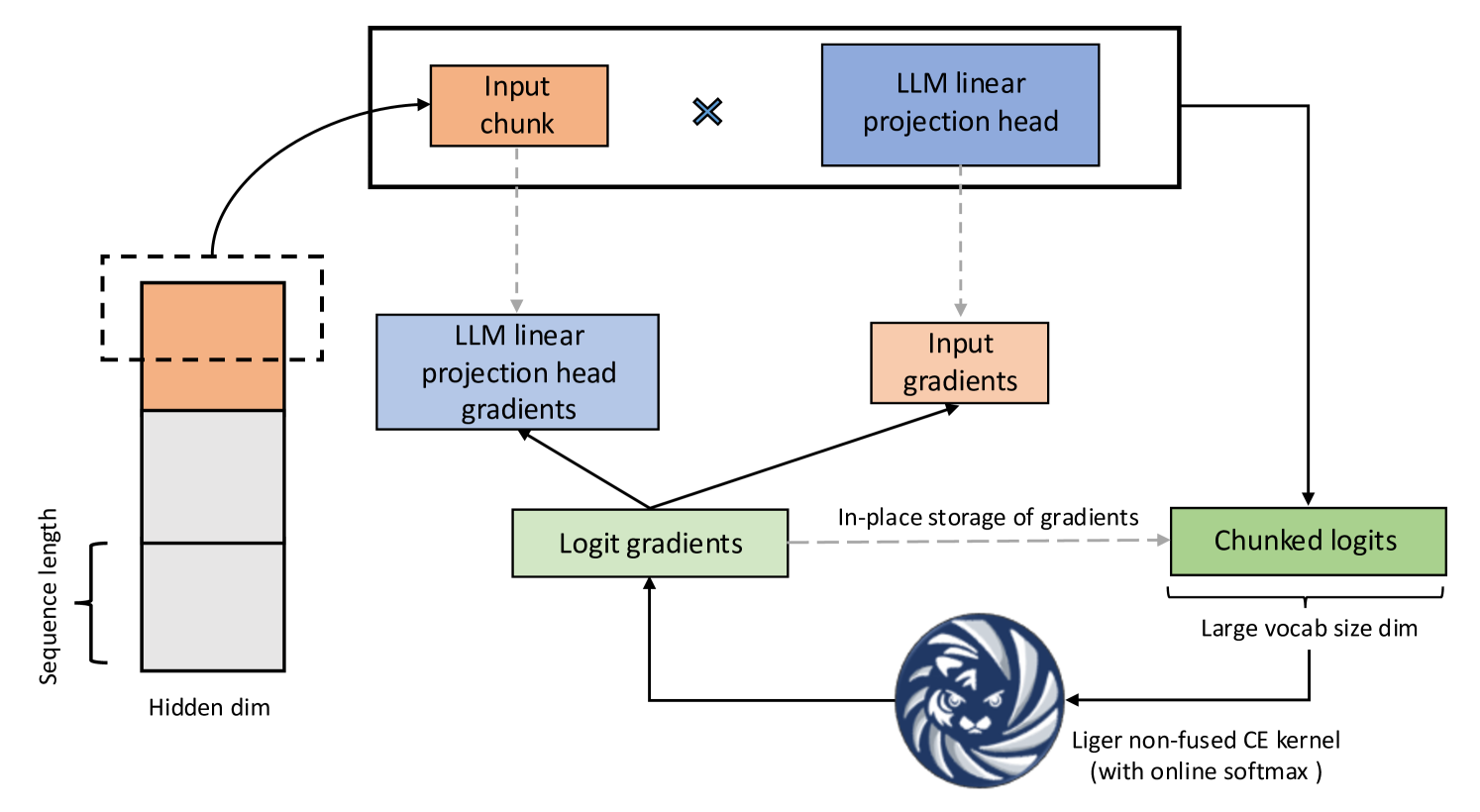
Figure 1: Fused Linear Cross Entropy
The bulk of LIger Kernel’s performance improvement comes from the Fused Linear Cross Entropy (FLCE) Loss, whose core idea is as follows:
In LLMs, the vocabulary size has increased significantly, leading to a large logit tensor during cross-entropy (CE) loss computation. This logit tensor consumes excessive memory, causing a bottleneck in training. For example, when training with a batch size of 8 and sequence length of 4096, the 256k vocabulary size results in a 16.8 GB logit tensor. The FLCE kernel breaks down the computation into smaller chunks, reducing memory consumption.
Here’s how it works:
- Flattens the 3D hidden states into a 2D matrix by collapsing the batch size and sequence length dimensions.
- Applies the linear projection head sequentially on the chunked hidden states.
- Computes the partial loss and returns the chunked logits gradient using the Liger CE kernel.
- Derives the chunked hidden states gradients and accumulates the projection head gradients.
Torchtune’s recipes provide torch.compile support out of the box. It has been shown that utilizing torch.compile with FLCE makes FLCE 2x faster.
Integrating Liger Kernel with torch.compile & torchtune
We demonstrate integration of Liger Kernel with torch.compile & torchtune by running a full fine-tuning recipe with meta-llama/Llama-3.2-1B. To make this integration happen, we have defined a custom full finetuning recipe, the details of the changes are mentioned below.
CUDA_VISIBLE_DEVICES=0,1,2,3 tune run --nproc_per_node 4 recipes/full_finetune_distributed.py --config llama3_2/1B_full optimizer=torch.optim.AdamW optimizer.fused=True optimizer_in_bwd=False gradient_accumulation_steps=1 dataset.packed=True compile=True enable_activation_checkpointing=True tokenizer.max_seq_len=512 batch_size=128
One of the inputs to the LCE Kernel is the forward projection weights. torchtune is designed as a modular library with composable blocks. There is a TransformerDecoder block where at the end of the block, we pass the final hidden state through a linear layer to get the final output. Since the linear layer is combined with the CE loss in LCE Kernel, we write a custom forward function for TransformerDecoder where we skip the computation through the linear layer.
In the full finetuning recipe, we override the model’s forward method with this custom method
import types
from liger_kernel.torchtune.modules.transformers import decoder_forward
self._model.forward = types.MethodType(decoder_forward, self._model)
We then pass the model’s forward projection weights to calculate the loss with LCE Kernel
from liger_kernel.transformers.fused_linear_cross_entropy import (
LigerFusedLinearCrossEntropyLoss,
)
# Use LCE loss instead of CE loss
self._loss_fn = LigerFusedLinearCrossEntropyLoss()
# call torch.compile on the loss function
if self._compile:
training.compile_loss(self._loss_fn, verbose=self._is_rank_zero)
# pass the model's forward projection weights for loss computation
current_loss = (
self._loss_fn(
self._model.output.tied_module.weight,
logits,
labels,
)
* current_num_tokens
)
The complete code and instructions can be found in the GitHub repo.
Experiments & Benchmarking Results
We conduct 3 types of experiments to demonstrate how Liger Kernel integration with torch.compile enhances the performance of torchtune. We set up our experiments on an instance running NVIDIA A100. We fine-tune a small LLM meta-llama/Llama-3.2-1B with differing batch sizes. We record the throughput in terms of tokens/second and measure the peak memory allocated during finetuning. Since it’s a small model, we only use 4 A100 GPUs for the benchmarking. The following are the experiments we conducted:
- Increase batch_size in powers of 2 with PyTorch eager
- Increase batch_size in powers of 2 with torch.compile
- Increase batch_size in powers of 2 with torch.compile & Liger integration
We notice that with PyTorch Eager, throughput increases with increasing batch_size till we hit OOM at batch_size 256. With torch.compile, the throughput is higher than PyTorch Eager for each batch_size. We see that the peak memory allocation reduces drastically with increasing batch_size and more than 50% reduction in peak memory at batch_size 128. This results in torch.compile being able to support batch_size 256 and hence, the overall throughput with torch.compile being 36% greater than PyTorch Eager. Integrating Liger Kernel with torch.compile doesn’t drop the throughput at lower batch_size but with increasing batch_size, we notice that torchtune is consuming less memory compared to torch.compile. At batch_size 256, we see a 47% reduction in peak memory allocation with the Liger kernel. This allows us to use batch_size 512 with torch.compile & Liger. We notice that there is a marginal 1-2% increase in throughput compared to torch.compile without custom triton kernels.
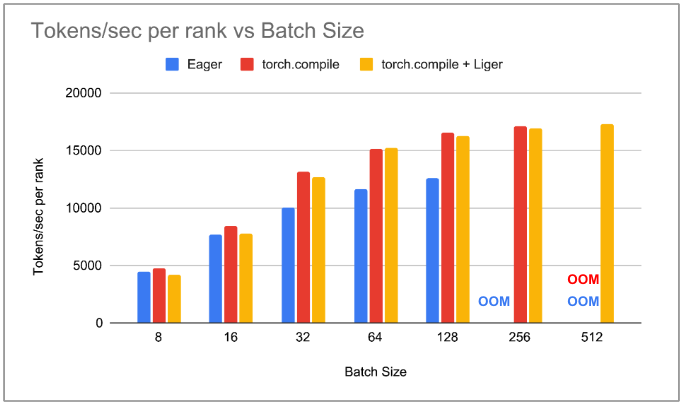
Figure 2: Plot of tokens/sec per rank vs batch_size
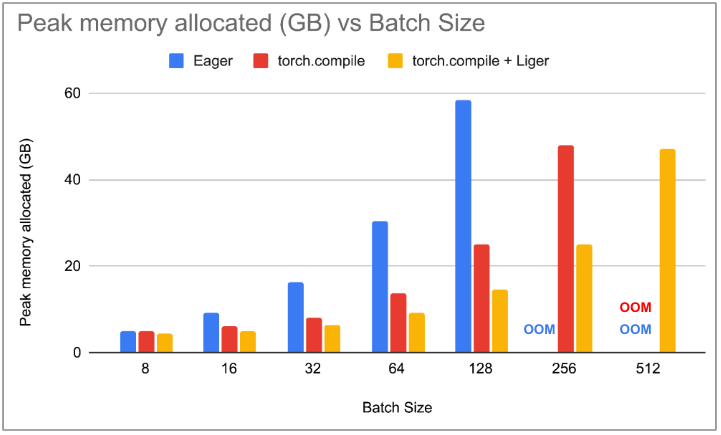
Figure 3: Peak memory allocated vs batch_size
To rule out any potential functional issues with our integration of Liger Kernel with torchtune, we plot the loss curve against training steps with & without Liger. We see that there is no visible difference in the loss curves.
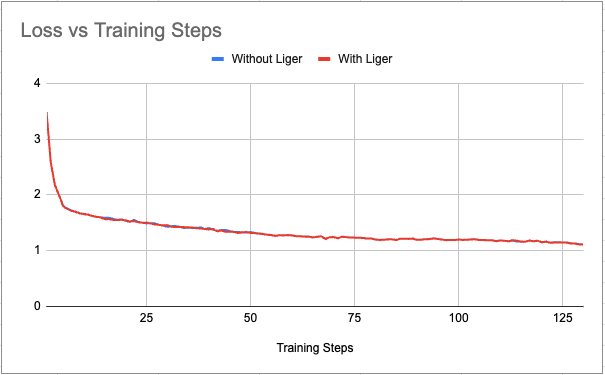
Figure 4: Plot of loss vs training steps for batch_size=128
Next Steps
- Enable Liger kernels for DPO loss and distillation loss in torchtune’s recipes for DPO and knowledge distillation, respectively.
- Support Liger integration in torchtune with tensor parallel training.
Acknowledgments
We thank Hamid Shojanazeri (Meta), Less Wright (Meta), Horace He (Meta) & Gregory Chanan (Meta) for their feedback and support in making this blog post happen.