Last year, IBM Research began collaborating with us to onboard Fully Sharded Data Parallelism (FSDP) for their large foundation models. They became interested as FSDP is a PyTorch native offering for scaling their distributed training efforts on IBM Cloud.
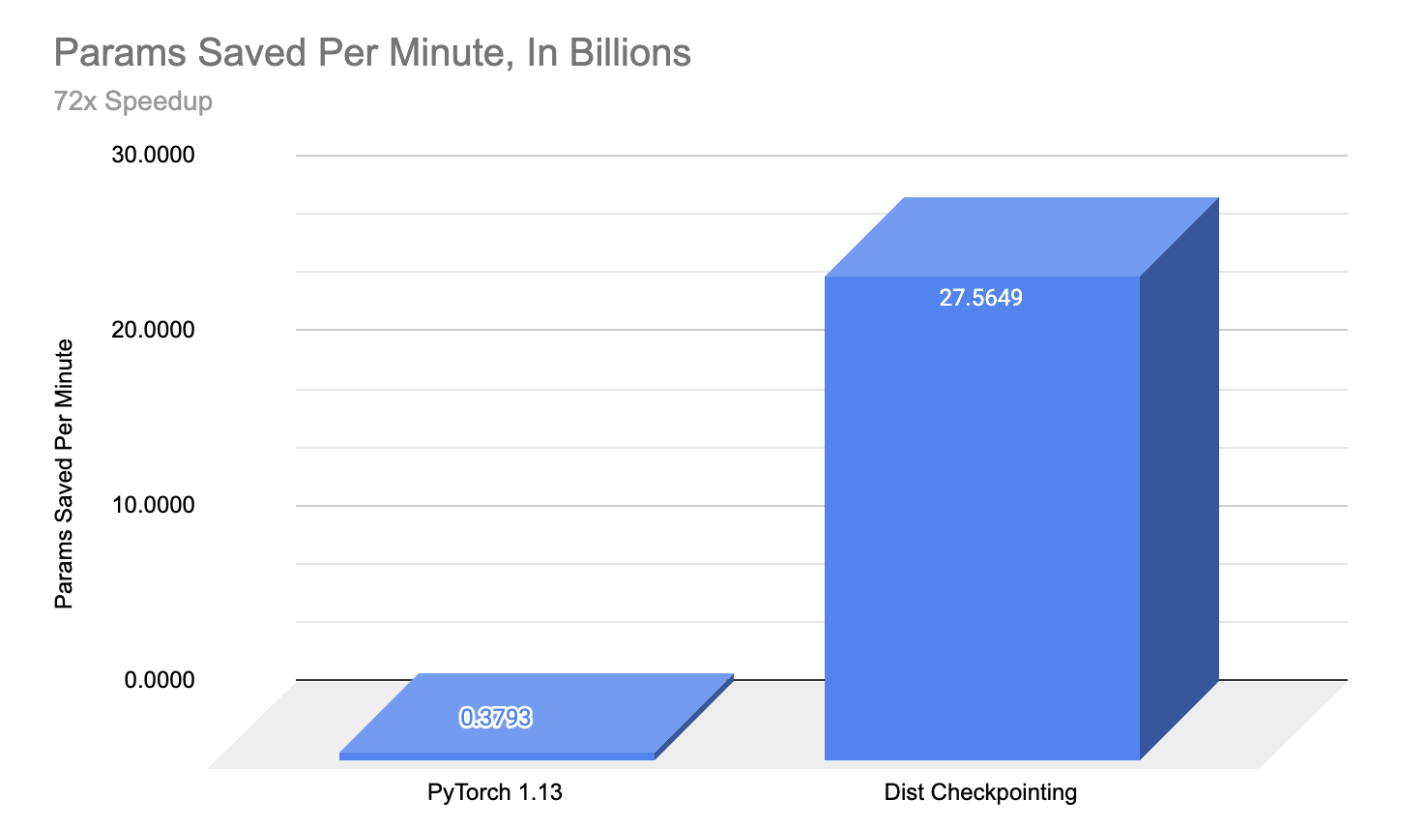
We are pleased to share that, in collaboration with IBM, we have achieved substantial checkpointing speedups for large models (72x vs the original PyTorch 1.13 save speed), proven model and optimizer checkpoint scaling to 30B parameters, and enabled cloud first training using FSDP + Distributed Checkpoint on S3 backends.
What is a Distributed Checkpoint?
Distributed checkpointing is the PyTorch native solution for saving and loading PyTorch models and optimizer states from multiple ranks, as well as supporting dynamically changing world sizes between reloads.
PyTorch Distributed Checkpoint (DCP) APIs were introduced in PyTorch 1.13, and are included as an official prototype feature in PyTorch 2.0.
Distributed checkpoint is different from torch.save() and torch.load() in a few significant ways:
- DCP produces multiples files per checkpoint, with at least one file per rank,
- DCP operates in place, meaning that the model should allocate its data first and the Distributed Checkpoint will then use the storage.
A major improvement from 1.13 to 2.0 includes adding sharded_state_dict support for checkpointing FSDP models. This allows checkpointing for larger sized models, as well as adding support for load-time resharding. Load time resharding enables saving in one cluster topology, and loading into another. This feature was highly requested as it allows training jobs to be run on one cluster, saved, and then continued on a different cluster with different world size.
Another major change is that we decouple the storage layer from the checkpoint planning layer and separate implementation from the interface for both layers. With this change, users can now specify how their state_dict should be chunked or transformed during the checkpoint planning phase. Additionally, the customizable storage layer can easily accommodate different backends.
More information on the Distributed Checkpoint package can be found here.
Performant Distributed checkpointing in Production with IBM
IBM at Think 2023 announced its watsonx.ai platform for development and deployment of foundation models for the enterprise. Built on Hybrid Cloud, the platform enables use cases across multiple modalities such as NLP, timeseries, weather, chemistry, tabular data, and cybersecurity, with model sizes from 100s of millions to 10s of billions of parameters. Model architectures range from vision transformers, to multi-modal RoBERTa-style feature extractors, to large-scale generative language models similar to T5, GPT and Llama.
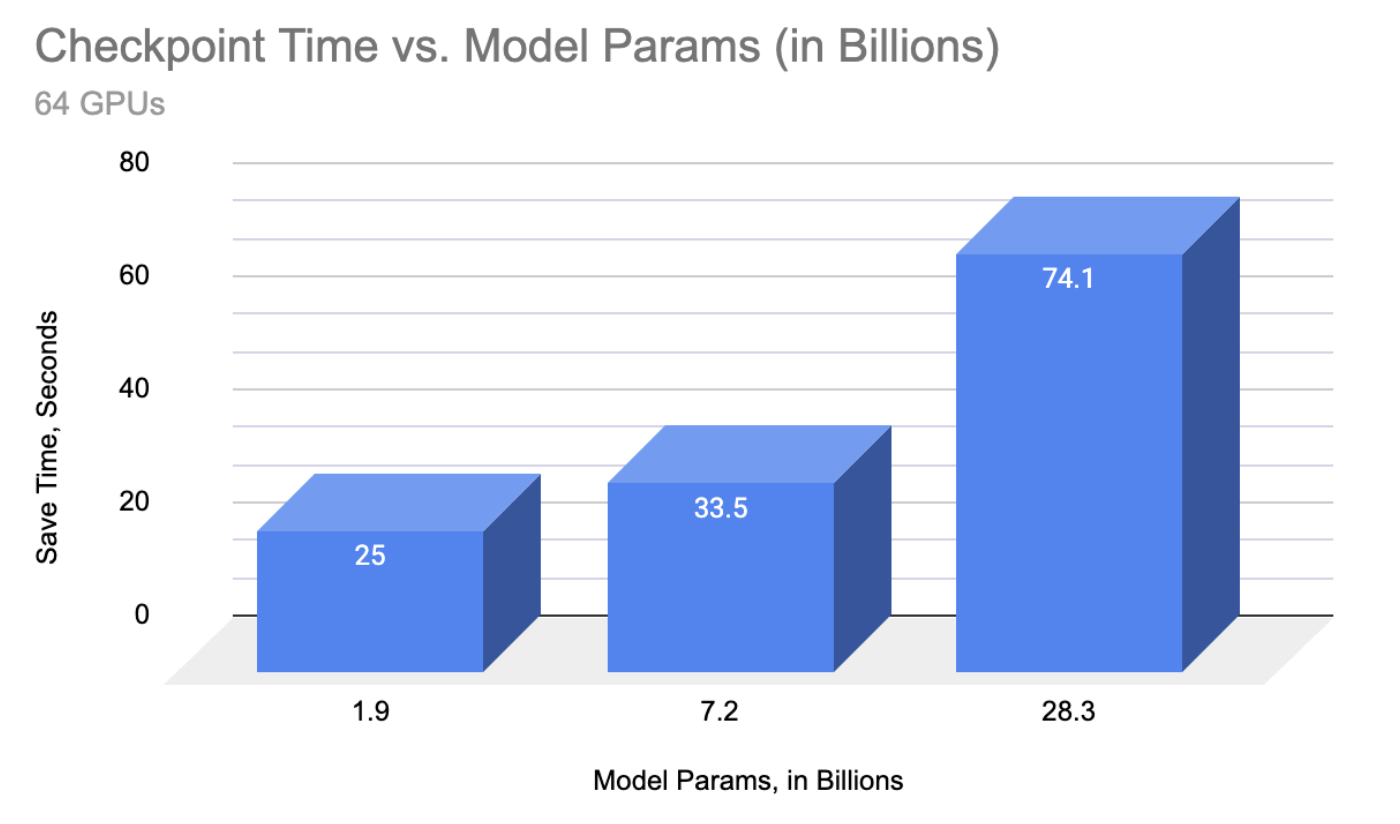
As of today, IBM has now enabled checkpointing for T5-style architectures up to 11B parameters, and decoder architectures (GPT style) up to 30B.
IBM helped us identify that this limits the scaling power of DCP from both memory and performance standpoints. With their suggestion, we enhanced our FileSystemWriter to produce single checkpoint per rank to reduce read write overhead.
With this option as the new default, DCP now creates a single file per rank during checkpoint saving, which would then be sliced when reading parameters at load time.
By combining sharded_state_dict support with single filer per rank writer, distributed checkpoint was able to accelerate checkpoint saving time over 72x vs the original PyTorch 1.13 save speed, and enable rapid checkpointing for models sizes over 15B which would previously simply time out.
“Looking back, it’s really astounding the speedups we’ve seen, handling training for many of these models. We went from taking almost half an hour to write a single 11B checkpoint in PyTorch 1.13, to being able to handle a 30B parameter model, with optimizer and dataloader state – so that’s over eight times the raw data – in just over 3 minutes. That’s done wonders for both the stability and efficiency of our jobs, as we scale up training to hundreds of gpus.” – Davis Wertheimer, IBM Research
IBM’s adoption has also helped us validate and improve our solutions in a real world, large-scale training environment. As an example, IBM discovered that DCP was working well for them on a single node with multiple GPUs, but erred out when used on multiple nodes.
Upon investigating the issue, we realized that we were assuming writing to a NFS-like shared file system, which assumes strong read-after-write consistencies. Object stores with file system APIs such as S3FS provide eventual consistency semantics, thus causing the distributed checkpoint in such a setting to fail. Working together with IBM, we identified this issue and fixed it by making one line code change and enabled object storage backend for DCP! Such storage approaches are typically an order of magnitude cheaper than shared file systems thus enabling finer grained checkpointing.
Looking for Collaboration
If you are interested in trying Distributed Checkpoint, feel free to reach out to us!
If you run into any issue when trying it, you can open an issue at our Github repo.
Acknowledgements
This project would not have been possible without the assistance from many collaborators. We would like to thank Yanli Zhao, Andrew Gu, Rohan Varma for their support of FSDP. Thanks to Pritam Damania, Junjie Zhao, and Wanchao Liang for their support of ShardedTensor.