Posted by Alisa Chang, Software Engineer, Google Cloud and Pritish Kamath, Research Scientist, Google Research
Over the last several years, progress has been made on privacy-safe approaches for handling sensitive data, for example, while discovering insights into human mobility and through use of federated analytics such as RAPPOR. In 2019, we released an open source library to enable developers and organizations to use techniques that provide differential privacy, a strong and widely accepted mathematical notion of privacy. Differentially-private data analysis is a principled approach that enables organizations to learn and release insights from the bulk of their data while simultaneously providing a mathematical guarantee that those results do not allow any individual user’s data to be distinguished or re-identified.
In this post, we consider the following basic problem: Given a database containing several attributes about users, how can one create meaningful user groups and understand their characteristics? Importantly, if the database at hand contains sensitive user attributes, how can one reveal these group characteristics without compromising the privacy of individual users?
Such a task falls under the broad umbrella of clustering, a fundamental building block in unsupervised machine learning. A clustering method partitions the data points into groups and provides a way to assign any new data point to a group with which it is most similar. The k-means clustering algorithm has been one such influential clustering method. However, when working with sensitive datasets, it can potentially reveal significant information about individual data points, putting the privacy of the corresponding user at risk.
Today, we announce the addition of a new differentially private clustering algorithm to our differential privacy library, which is based on privately generating new representative data points. We evaluate its performance on multiple datasets and compare to existing baselines, finding competitive or better performance.
K-means Clustering
Given a set of data points, the goal of k-means clustering is to identify (at most) k points, called cluster centers, so as to minimize the loss given by the sum of squared distances of the data points from their closest cluster center. This partitions the set of data points into k groups. Moreover, any new data point can be assigned to a group based on its closest cluster center. However, releasing the set of cluster centers has the potential to leak information about particular users — for example, consider a scenario where a particular data point is significantly far from the rest of the points, so the standard k-means clustering algorithm returns a cluster center at this single point, thereby revealing sensitive information about this single point. To address this, we design a new algorithm for clustering with the k-means objective within the framework of differential privacy.
A Differentially Private Algorithm
In “Locally Private k-Means in One Round”, published at ICML 2021, we presented a differentially private algorithm for clustering data points. That algorithm had the advantage of being private in the local model, where the user’s privacy is protected even from the central server performing the clustering. However, any such approach necessarily incurs a significantly larger loss than approaches using models of privacy that require trusting a central server.1
Here, we present a similarly inspired clustering algorithm that works in the central model of differential privacy, where the central server is trusted to have complete access to the raw data, and the goal is to compute differentially private cluster centers, which do not leak information about individual data points. The central model is the standard model for differential privacy, and algorithms in the central model can be more easily substituted in place of their non-private counterparts since they do not require changes to the data collection process. The algorithm proceeds by first generating, in a differentially private manner, a core-set that consists of weighted points that “represent” the data points well. This is followed by executing any (non-private) clustering algorithm (e.g., k-means++) on this privately generated core-set.
At a high level, the algorithm generates the private core-set by first using random-projection–based locality-sensitive hashing (LSH) in a recursive manner2 to partition the points into “buckets” of similar points, and then replacing each bucket by a single weighted point that is the average of the points in the bucket, with a weight equal to the number of points in the same bucket. As described so far, though, this algorithm is not private. We make it private by performing each operation in a private manner by adding noise to both the counts and averages of points within a bucket.
This algorithm satisfies differential privacy because each point’s contributions to the bucket counts and the bucket averages are masked by the added noise, so the behavior of the algorithm does not reveal information about any individual point. There is a tradeoff with this approach: if the number of points in the buckets is too large, then individual points will not be well-represented by points in the core-set, whereas if the number of points in a bucket is too small, then the added noise (to the counts and averages) will become significant in comparison to the actual values, leading to poor quality of the core-set. This trade-off is realized with user-provided parameters in the algorithm that control the number of points that can be in a bucket.
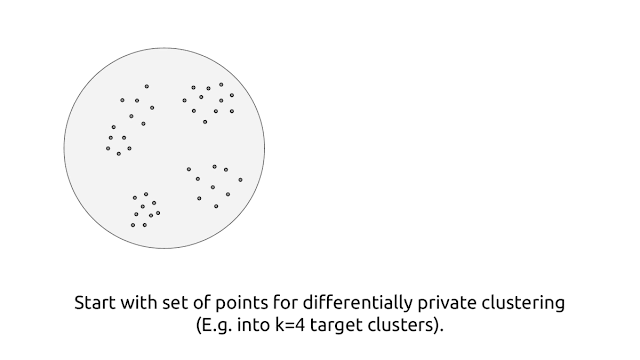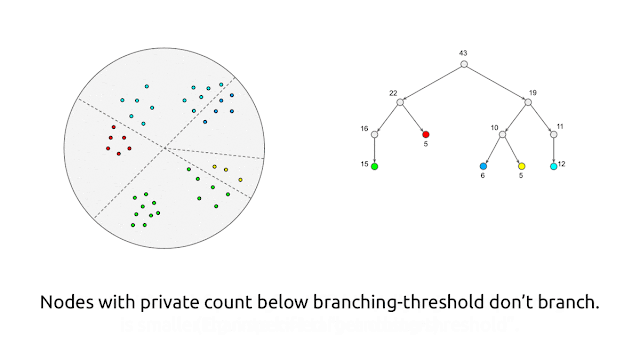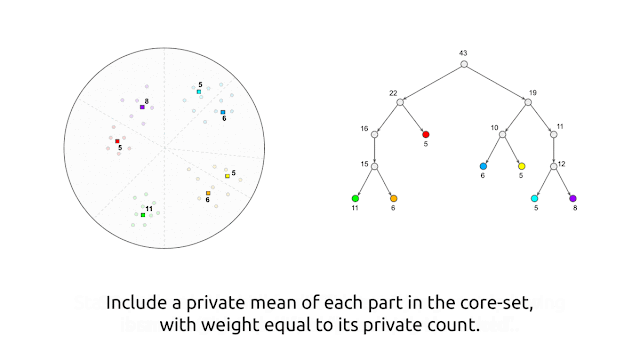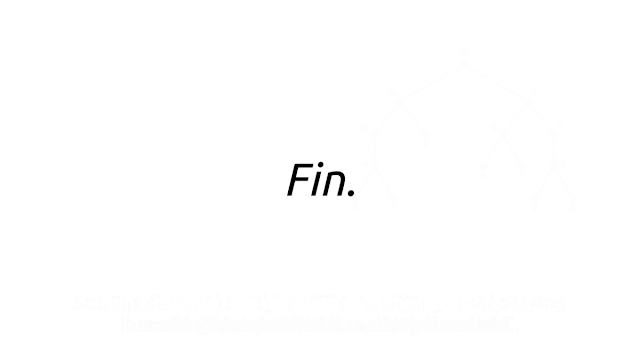 |
| Visual illustration of the algorithm. |
Experimental Evaluation
We evaluated the algorithm on a few benchmark datasets, comparing its performance to that of the (non-private) k-means++ algorithm, as well as a few other algorithms with available implementations, namely diffprivlib and dp-clustering-icml17. We use the following benchmark datasets: (i) a synthetic dataset consisting of 100,000 data points in 100 dimensions sampled from a mixture of 64 Gaussians; (ii) neural representations for the MNIST dataset on handwritten digits obtained by training a LeNet model; (iii) the UC Irvine dataset on Letter Recognition; and (iv) the UC Irvine dataset on Gas Turbine CO and NOx Emissions.3
We analyze the normalized k-means loss (mean squared distance from data points to the nearest center) while varying the number of target centers (k) for these benchmark datasets.4 The described algorithm achieves a lower loss than the other private algorithms in three out of the four datasets we consider.
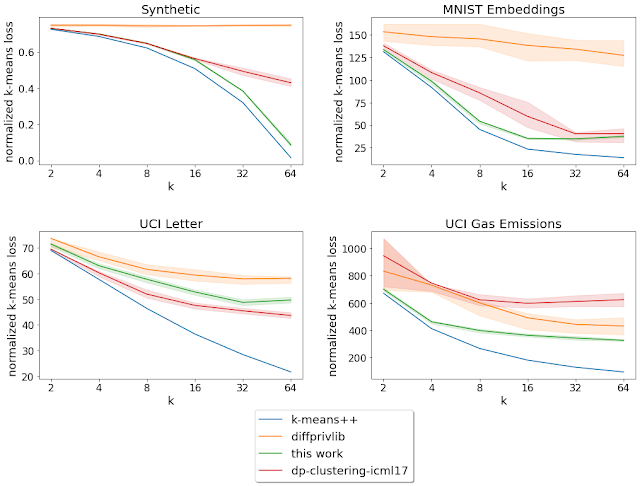 |
| Normalized loss for varying k = number of target clusters (lower is better). The solid curves denote the mean over the 20 runs, and the shaded region denotes the 25-75th percentile range. |
Moreover, for datasets with specified ground-truth labels (i.e., known groupings), we analyze the cluster label accuracy, which is the accuracy of the labeling obtained by assigning the most frequent ground-truth label in each cluster found by the clustering algorithm to all points in that cluster. Here, the described algorithm performs better than other private algorithms for all the datasets with pre-specified ground-truth labels that we consider.
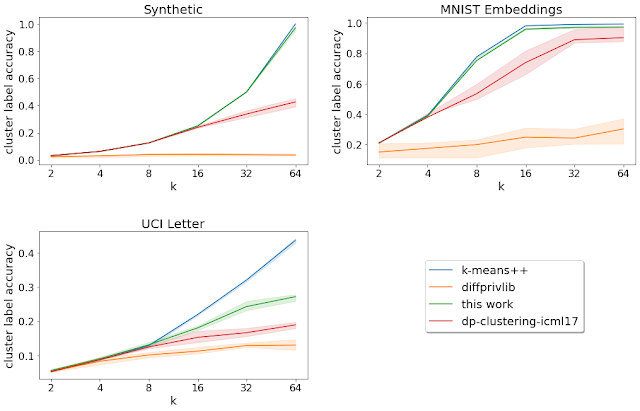 |
| Cluster label accuracy for varying k = number of target clusters (higher is better). The solid curves denote the mean over the 20 runs, and the shaded region denotes the 25-75th percentile range. |
Limitations and Future Directions
There are a couple of limitations to consider when using this or any other library for private clustering.
- It is important to separately account for the privacy loss in any preprocessing (e.g., centering the data points or rescaling the different coordinates) done before using the private clustering algorithm. So, we hope to provide support for differentially private versions of commonly used preprocessing methods in the future and investigate changes so that the algorithm performs better with data that isn’t necessarily preprocessed.
- The algorithm described requires a user-provided radius, such that all data points lie within a sphere of that radius. This is used to determine the amount of noise that is added to the bucket averages. Note that this differs from diffprivlib and dp-clustering-icml17 which take in different notions of bounds of the dataset (e.g., a minimum and maximum of each coordinate). For the sake of our experimental evaluation, we calculated the relevant bounds non-privately for each dataset. However, when running the algorithms in practice, these bounds should generally be privately computed or provided without knowledge of the dataset (e.g., using the underlying range of the data). Although, note that in case of the algorithm described, the provided radius need not be exactly correct; any data points outside of the provided radius are replaced with the closest points that are within the sphere of that radius.
Conclusion
This work proposes a new algorithm for computing representative points (cluster centers) within the framework of differential privacy. With the rise in the amount of datasets collected around the world, we hope that our open source tool will help organizations obtain and share meaningful insights about their datasets, with the mathematical assurance of differential privacy.
Acknowledgements
We thank Christoph Dibak, Badih Ghazi, Miguel Guevara, Sasha Kulankhina, Ravi Kumar, Pasin Manurangsi, Jane Shapiro, Daniel Simmons-Marengo, Yurii Sushko, and Mirac Vuslat Basaran for their help.
1As shown by Uri Stemmer in Locally private k-means clustering (SODA 2020). ↩
2This is similar to work on LSH Forest, used in the context of similarity-search queries. ↩
3Datasets (iii) and (iv) were centered to have mean zero before evaluating the algorithms. ↩
4Evaluation done for fixed privacy parameters ε = 1.0 and δ = 1e-6. Note that dp-clustering-icml17 works in the pure differential privacy model (namely, with δ = 0); k-means++, of course, has no privacy parameters. ↩
