The rapid adoption of smart phones and other mobile platforms has generated an enormous amount of image data. According to Gartner, unstructured data now represents 80–90% of all new enterprise data, but just 18% of organizations are taking advantage of this data. This is mainly due to a lack of expertise and the large amount of time and effort that’s required to sift through all that information to identify quality data and useful insights.
Before you can use image data for labeling, training, or inference, it first needs to be cleaned (deduplicate, drop corrupted images or outliers, and so on), analyzed (such as group images based on certain attributes), standardized (resize, change orientation, standardize lighting and color, and so on), and augmented for better labeling, training, or inference results (enhance contrast, blur some irrelevant objects, upscale, and so on).
Today, we are happy to announce that with Amazon SageMaker Data Wrangler, you can perform image data preparation for machine learning (ML) using little to no code.
Data Wrangler reduces the time it takes to aggregate and prepare data for ML from weeks to minutes. With Data Wrangler, you can simplify the process of data preparation and feature engineering, and complete each step of the data preparation workflow (including data selection, cleansing, exploration, visualization, and processing at scale) from a single visual interface.
Data Wrangler’s image data preparation feature addresses your needs via a visual UI for image preview, import, transformation, and export. You can browse, import, and transform image data just like how you use Data Wrangler for tabular data. In this post, we show an example of how to use this feature.
Solution overview
For this post, we focus on the Data Wrangler component of image processing, which we use to help an image classification model detect crashes with better quality images. We use the following services:
- Amazon SageMaker Data Wrangler to perform image processing
- Amazon SageMaker Jumpstart to train a image recognition model using the prepared dataset
- Amazon SageMaker Studio notebooks to test the model
The following diagram illustrates the solution architecture.

Data Wrangler is a SageMaker feature available within Studio. You can follow the Studio onboarding process to spin up the Studio environment and notebooks. Although you can choose from a few authentication methods, the simplest way to create a Studio domain is to follow the Quick start instructions. The Quick start uses the same default settings as the standard Studio setup. You can also choose to onboard using AWS IAM Identity Center (successor to AWS Single Sign-On) for authentication (see Onboard to Amazon SageMaker Domain Using IAM Identity Center).
For this use case, we use CCTV footage data of accidents and non-accidents available from Kaggle. The dataset contains frames captured from YouTube videos of accidents and non-accidents. The images are split into train, test, and validation folders.
Prerequisites
As a prerequisite, download the sample dataset and upload it to an Amazon Simple Storage Service (Amazon S3) bucket. We use this dataset for image processing and subsequently for training a custom model.
Process images using Data Wrangler
Start your Studio environment and create a new Data Wrangler flow called car_crash_detection_data.flow. Now let’s import the dataset to Data Wrangler from the S3 bucket where the dataset was uploaded. Data Wrangler allows you to import datasets from different data sources, including images.
Data Wrangler supports a variety of built-in transformations for image processing, including the following:
- Blur image – Data Wrangler supports different techniques from an open-source image library (Gaussian, Average, Median, Motion, and more) for blurring images. For details of each technique, refer to augmenters.blur.
- Corrupt image – Data Wrangler also supports different corruption techniques (Gaussian noise, Impulse noise, Speckle noise, and more). For details of each technique, refer to augmenters.imgcorruptlike.
- Enhance image contrast – You can deploy different contrast enhancement techniques (Gamma contrast, Sigmoid contrast, Log contrast, Linear contrast, Histogram equalization, and more). For more details, refer to augmenters.contrast.
- Resize image – Data Wrangler supports different resizing techniques (cropping, padding, thumbnail, and more). For more details, refer to augmenters.size.
In this post, we highlight a subset of these functionalities through the following steps:
- Upload images from the source S3 bucket and preview the image.
- Create quick image transformations using the built-in transformers.
- Write custom code like finding outliers or using the Search Example Snippets function.
- Export the final cleansed data to another S3 bucket.
- Combine images from different Amazon S3 sources into one Data Wrangler flow.
- Create a job to trigger the Data Wrangler flow.
Let’s look at each step in detail.
Upload images from the source bucket S3 and preview the image
To upload all the images under one folder, complete the following steps:
- Select the S3 folder containing the images.
- For File type, choose Image.
- Select Import nested directories.
- Choose Import.

You can preview the images that you’re uploading by turning the Preview option on. Note that Date Wrangler only imports 100 random images for the interactive data preparation.
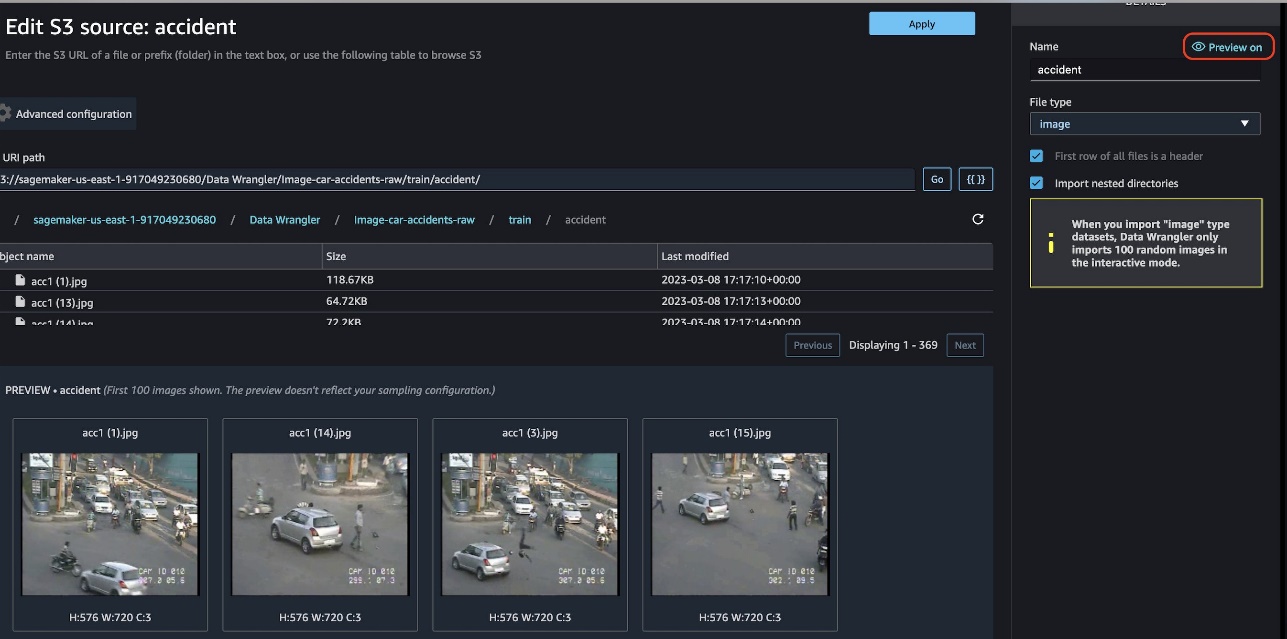
The preview function allows you to view images and preview the quality of images imported.

For this post, we load the images from both the accident and non-accident folders. We create a set of transformations for each: one flow to corrupt images, resize, and remove outliers, and another flow to enhance image contrast, resize, and remove outliers.
Transform images using built-in transformations
Image data transformation is very important to regularize your model network and increase the size of your training set. These transformations can change the images’ pixel values but still keep almost all the information of the image, so that a human could hardly tell whether it was augmented or not. This forces the model to be more flexible with the wide variety of objects in the image, regarding position, orientation, size, color, and so on. Models trained with data augmentation usually generalize better.
Data Wrangler offers you built-in and custom transformations to improve the quality of images for labeling, training, or inference. We use some of these transformations to improve the image dataset fed to the model for machine learning.
Corrupt images
The first built-in transformation we use is Corrupt images.
We add a step with Corruption set to Impulse noise and set our severity.
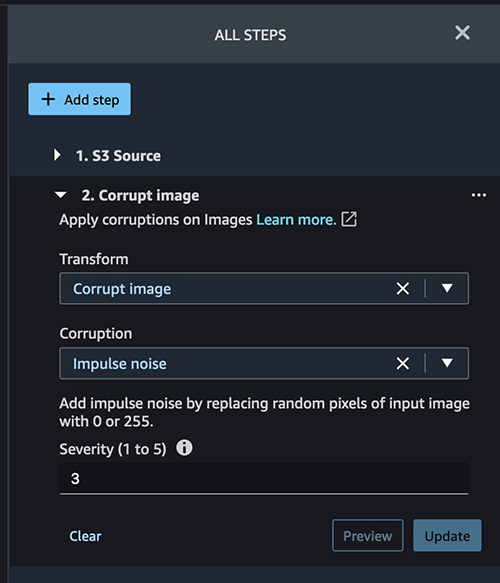
Corrupting an image or creating any kind of noise helps make a model more robust. The model can predict with more accuracy even if it receives a corrupted image because it was trained with corrupt and non-corrupt images.
Enhance contrast
We also add a transform to enhance the Gamma contrast.

Resize images
We can use a built-in transformation to resize all the images to add symmetry. Data Wrangler offers several resize options, as shown in the following screenshot.
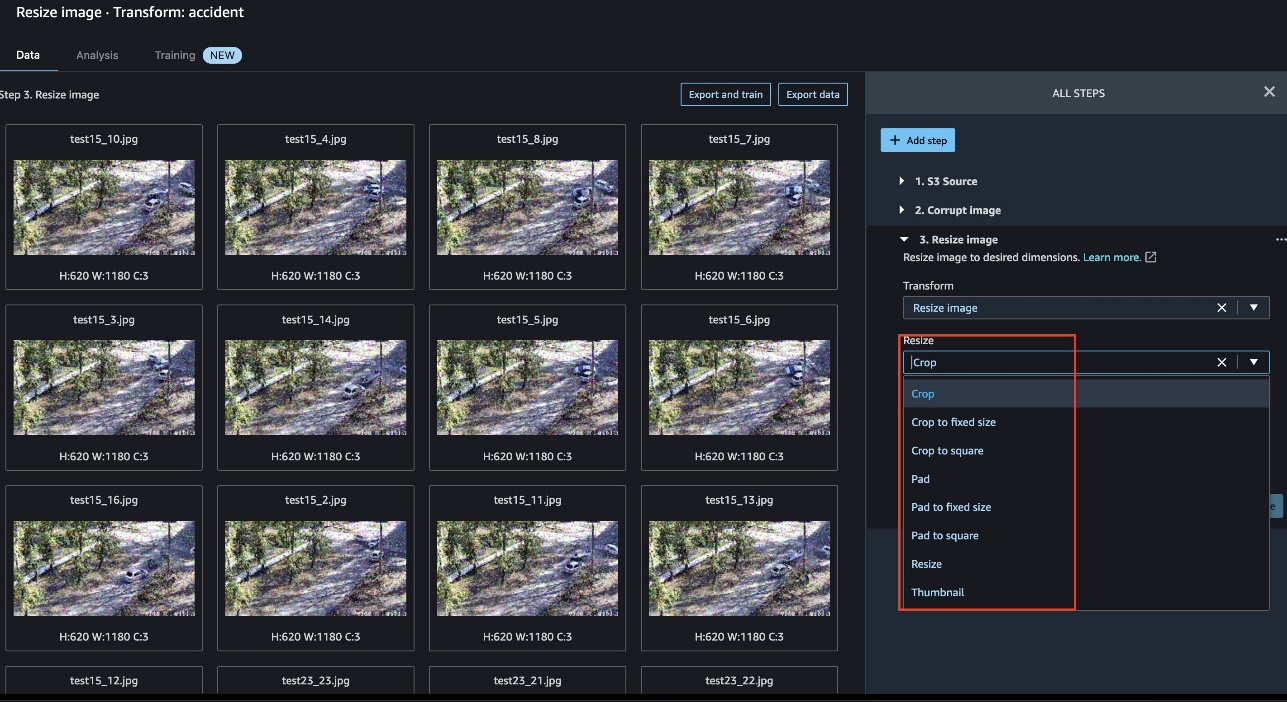
The following example shows images prior to resize: 720 x 1280.

The following images have been resized to 620 x 1180.

Add a custom transformation to detect and remove image outliers
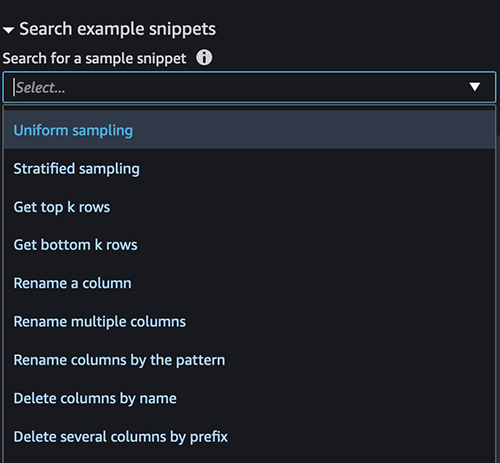
With image preparation in Data Wrangler, we can also invoke another endpoint for another model. You can find some sample scripts with boilerplate code in the Search example snippets section.
For our example, we create a new transformation to remove outliers. Please note that this code is just for demonstration purpose. You may need to modify code to suit any production workload needs.
This is a custom snippet written in PySpark. Before running this step, we need to have an image embedding model mobile-net (for example, jumpstart-dft-mobilenet-v2-100-224-featurevector-4). After the endpoint is deployed, we can call a JumpStart model endpoint.
JumpStart models solve common ML tasks such as image classification, object detection, text classification, sentence pair classification, and question answering, and are available for quick model creation and deployment.
To learn how to create an image embedding model in JumpStart, refer to the GitHub repo. The steps to follow are similar to creating an image classification model with Jumpstart. See the following code:
The following screenshots show an example of our custom transform.
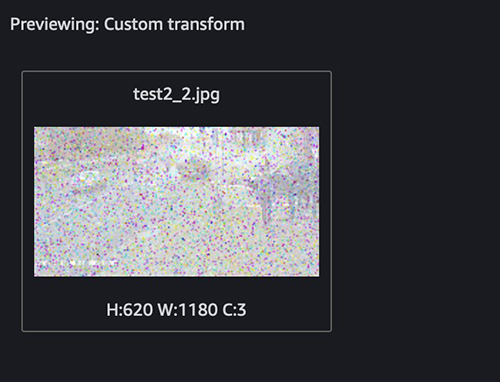
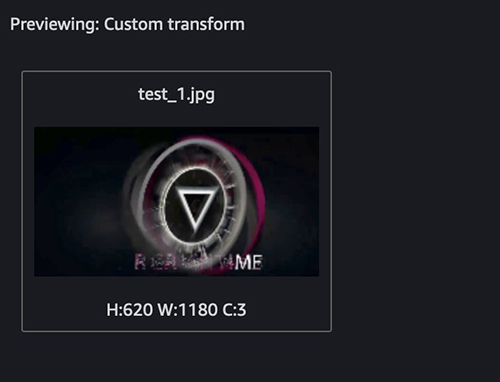
This identifies the outlier. Next, let’s filter out the outlier. You can use the following snippet in the end of the custom transform:
Choose Preview and Add to save the changes.
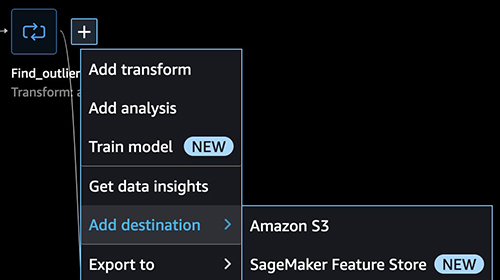
Export the final cleansed data to another S3 bucket
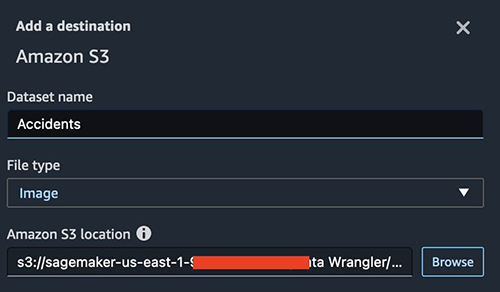
After adding all the transformations, let’s define the destination in Amazon S3.
Provide the location of your S3 bucket.
Combine images from different Amazon S3 sources into one Data Wrangler flow
In the previous sections, we processed images of accidents. We can implement a similar flow for any other images (in our case, non-accident images). Choose Import and follow the same steps to create a second flow.
Now we can view the flows for each dataset.

Create a job to run the automated flow
When we create a job, we scale the recipe to the entire dataset, which could be thousands or millions of images. You can also schedule the flow to run periodically, and you can parameterize the input data source to scale the processing. For details on job scheduling and input parameterization, refer to Create a Schedule to Automatically Process New Data.
Choose Create job to run a job for the end-to-end flow.

Provide the details of the job and select both datasets.
Congratulations! You have successfully created a job to process images using Data Wrangler.
Model training and deployment
JumpStart provides one-click, end-to-end solutions for many common ML use cases. We can use the images prepared with Data Wrangler when creating a quick image classification model in JumpStart. For instructions, refer to Run image classification with Amazon SageMaker JumpStart.
Clean up
When you’re not using Data Wrangler, it’s important to shut down the instance on which it runs to avoid incurring additional fees.
Data Wrangler automatically saves your data flow every 60 seconds. To avoid losing work, save your data flow before shutting Data Wrangler down.
- To save your data flow in Studio, choose File, then choose Save Data Wrangler Flow.
- To shut down the Data Wrangler instance, in Studio, choose Running Instances and Kernels.
- Under RUNNING APPS, choose the shutdown icon next to the
sagemaker-data-wrangler-1.0app. - Choose Shut down all to confirm.
Data Wrangler runs on an ml.m5.4xlarge instance. This instance disappears from RUNNING INSTANCES when you shut down the Data Wrangler app.
- Shut down the JumpStart endpoint that you created for the outlier transformation image embedding.
After you shut down the Data Wrangler app, it has to restart the next time you open a Data Wrangler flow file. This can take a few minutes.
Conclusion
In this post, we demonstrated using image data preparation for ML on Data Wrangler. To get started with Data Wrangler, see Prepare ML Data with Amazon SageMaker Data Wrangler, and check out the latest information on the Data Wrangler product page.
About the Authors
 Deepmala Agarwal works as an AWS Data Specialist Solutions Architect. She is passionate about helping customers build out scalable, distributed, and data-driven solutions on AWS. When not at work, Deepmala likes spending time with family, walking, listening to music, watching movies, and cooking!
Deepmala Agarwal works as an AWS Data Specialist Solutions Architect. She is passionate about helping customers build out scalable, distributed, and data-driven solutions on AWS. When not at work, Deepmala likes spending time with family, walking, listening to music, watching movies, and cooking!
 Meenakshisundaram Thandavarayan works for AWS as an AI/ ML Specialist. He has a passion to design, create, and promote human-centered data and analytics experiences. Meena focusses on developing sustainable systems that deliver measurable, competitive advantages for strategic customers of AWS. Meena is a connector, design thinker, and strives to drive business to new ways of working through innovation, incubation and democratization.
Meenakshisundaram Thandavarayan works for AWS as an AI/ ML Specialist. He has a passion to design, create, and promote human-centered data and analytics experiences. Meena focusses on developing sustainable systems that deliver measurable, competitive advantages for strategic customers of AWS. Meena is a connector, design thinker, and strives to drive business to new ways of working through innovation, incubation and democratization.
 Lu Huang is a Senior Product Manager on Data Wrangler. She’s passionate about AI, machine learning, and big data.
Lu Huang is a Senior Product Manager on Data Wrangler. She’s passionate about AI, machine learning, and big data.
 Nikita Ivkin is a Senior Applied Scientist at Amazon SageMaker Data Wrangler with interests in machine learning and data cleaning algorithms.
Nikita Ivkin is a Senior Applied Scientist at Amazon SageMaker Data Wrangler with interests in machine learning and data cleaning algorithms.