Organizations in the lending and mortgage industry process thousands of documents on a daily basis. From a new mortgage application to mortgage refinance, these business processes involve hundreds of documents per application. There is limited automation available today to process and extract information from all the documents, especially due to varying formats and layouts. Due to high volume of applications, capturing strategic insights and getting key information from the contents is a time-consuming, highly manual, error prone and expensive process. Legacy optical character recognition (OCR) tools are cost-prohibitive, error-prone, involve a lot of configuring, and are difficult to scale. Intelligent document processing (IDP) with AWS artificial intelligence (AI) services helps automate and accelerate the mortgage application processing with goals of faster and quality decisions, while reducing overall costs.
In this post, we demonstrate how you can utilize machine learning (ML) capabilities with Amazon Textract, and Amazon Comprehend to process documents in a new mortgage application, without the need for ML skills. We explore the various phases of IDP as shown in the following figure, and how they connect to the steps involved in a mortgage application process, such as application submission, underwriting, verification, and closing.
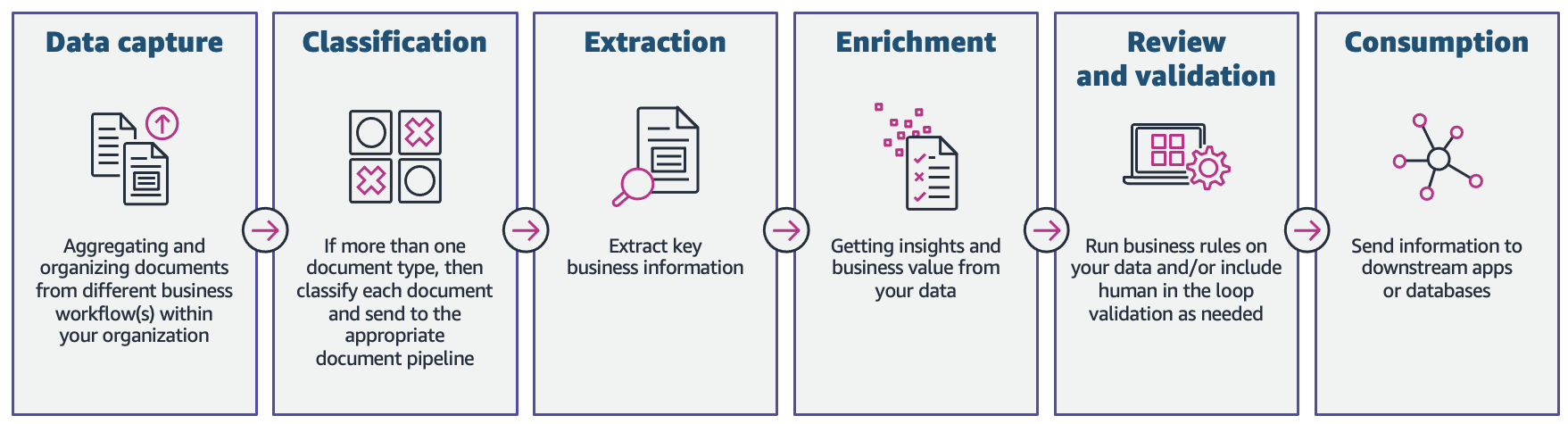
Although each mortgage application may be unique, we took into account some of the most common documents that are included in a mortgage application, such as the Unified Residential Loan Application (URLA-1003) form, 1099 forms, and mortgage note.
Solution overview
Amazon Textract is an ML service that automatically extracts text, handwriting, and data from scanned documents using pre-trained ML models. Amazon Comprehend is a natural-language processing (NLP) service that uses ML to uncover valuable insights and connections in text and can perform document classification, name entity recognition (NER), topic modeling, and more.
The following figure shows the phases of IDP as it relates to the phases of a mortgage application process.
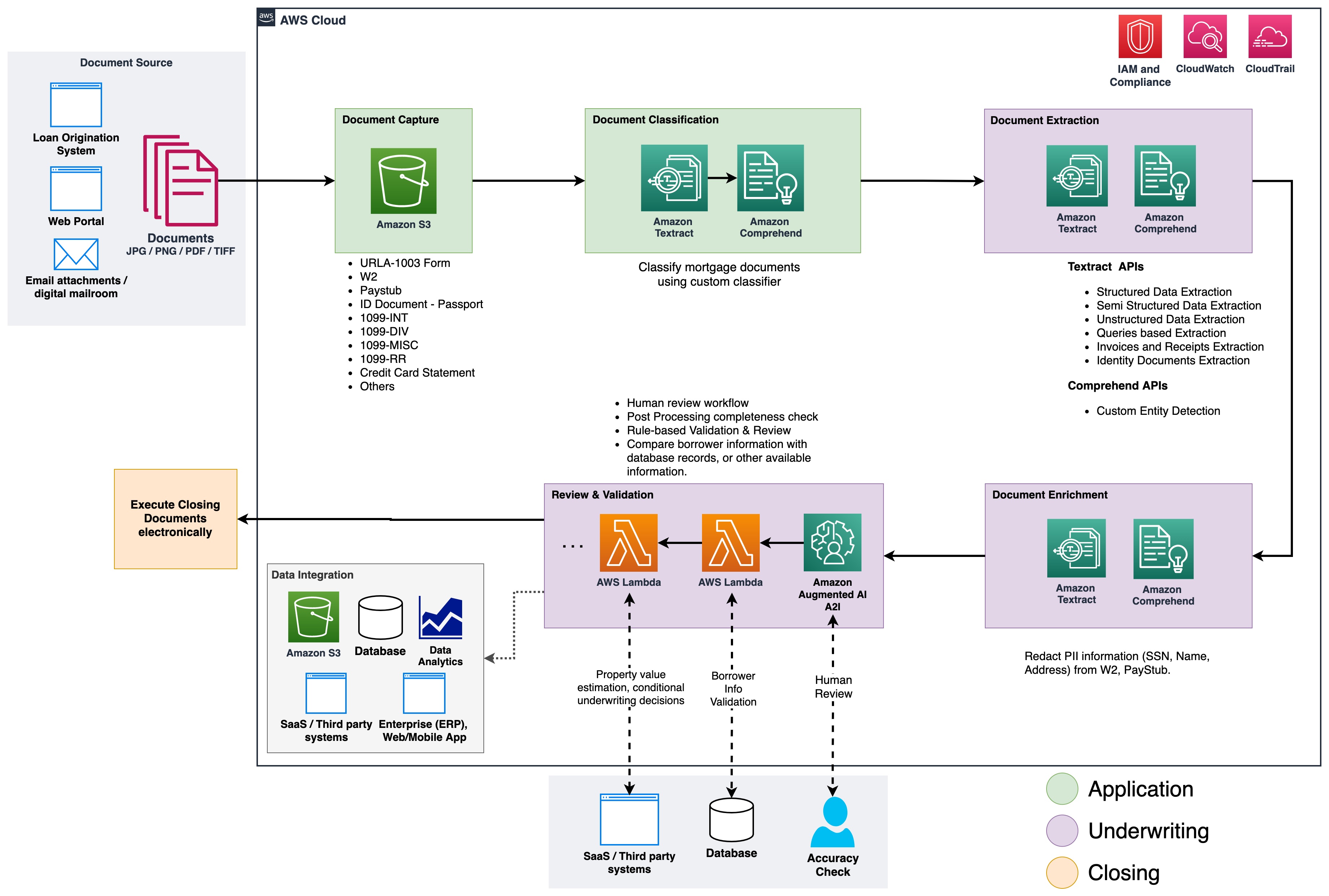
At the start of the process, documents are uploaded to an Amazon Simple Storage Service (Amazon S3) bucket. This initiates a document classification process to categorize the documents into known categories. After the documents are categorized, the next step is to extract key information from them. We then perform enrichment for select documents, which can be things like personally identifiable information (PII) redaction, document tagging, metadata updates, and more. The next step involves validating the data extracted in previous phases to ensure completeness of a mortgage application. Validation can be done via business validation rules and cross document validation rules. The confidence scores of the extracted information can also be compared to a set threshold, and automatically routed to a human reviewer through Amazon Augmented AI (Amazon A2I) if the threshold isn’t met. In the final phase of the process, the extracted and validated data is sent to downstream systems for further storage, processing, or data analytics.
In the following sections, we discuss the phases of IDP as it relates to the phases of a mortgage application in detail. We walk through the phases of IDP and discuss the types of documents; how we store, classify, and extract information, and how we enrich the documents using machine learning.
Document storage
Amazon S3 is an object storage service that offers industry-leading scalability, data availability, security, and performance. We use Amazon S3 to securely store the mortgage documents during and after the mortgage application process. A mortgage application packet may contain several types of forms and documents, such as URLA-1003, 1099-INT/DIV/RR/MISC, W2, paystubs, bank statements, credit card statements, and more. These documents are submitted by the applicant in the mortgage application phase. Without manually looking through them, it might not be immediately clear which documents are included in the packet. This manual process can be time-consuming and expensive. In the next phase, we automate this process using Amazon Comprehend to classify the documents into their respective categories with high accuracy.
Document classification
Document classification is a method by means of which a large number of unidentified documents can be categorized and labeled. We perform this document classification using an Amazon Comprehend custom classifier. A custom classifier is an ML model that can be trained with a set of labeled documents to recognize the classes that are of interest to you. After the model is trained and deployed behind a hosted endpoint, we can utilize the classifier to determine the category (or class) a particular document belongs to. In this case, we train a custom classifier in multi-class mode, which can be done either with a CSV file or an augmented manifest file. For the purposes of this demonstration, we use a CSV file to train the classifier. Refer to our GitHub repository for the full code sample. The following is a high-level overview of the steps involved:
- Extract UTF-8 encoded plain text from image or PDF files using the Amazon Textract DetectDocumentText API.
- Prepare training data to train a custom classifier in CSV format.
- Train a custom classifier using the CSV file.
- Deploy the trained model with an endpoint for real-time document classification or use multi-class mode, which supports both real-time and asynchronous operations.
The following diagram illustrates this process.
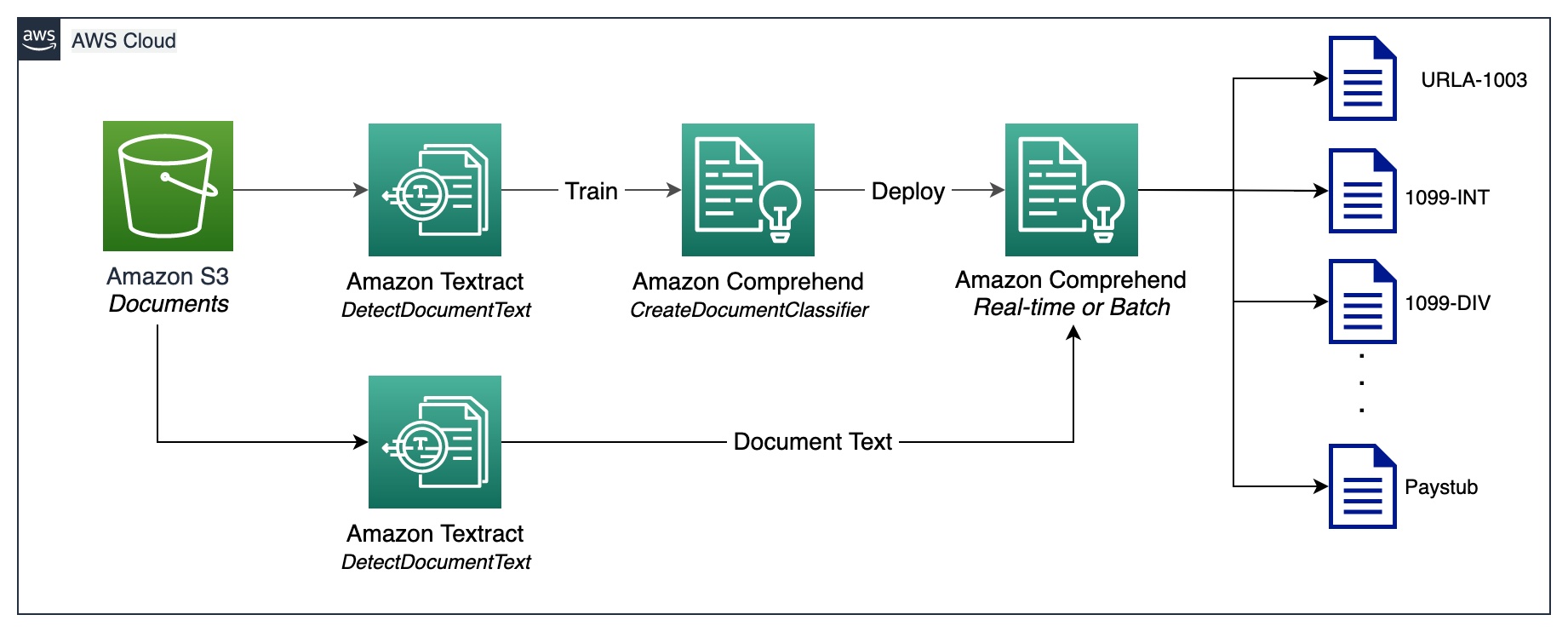
You can automate document classification using the deployed endpoint to identify and categorize documents. This automation is useful to verify whether all the required documents are present in a mortgage packet. A missing document can be quickly identified, without manual intervention, and notified to the applicant much earlier in the process.
Document extraction
In this phase, we extract data from the document using Amazon Textract and Amazon Comprehend. For structured and semi-structured documents containing forms and tables, we use the Amazon Textract AnalyzeDocument API. For specialized documents such as ID documents, Amazon Textract provides the AnalyzeID API. Some documents may also contain dense text, and you may need to extract business-specific key terms from them, also known as entities. We use the custom entity recognition capability of Amazon Comprehend to train a custom entity recognizer, which can identify such entities from the dense text.
In the following sections, we walk through the sample documents that are present in a mortgage application packet, and discuss the methods used to extract information from them. For each of these examples, a code snippet and a short sample output is included.
Extract data from Unified Residential Loan Application URLA-1003
A Unified Residential Loan Application (URLA-1003) is an industry standard mortgage loan application form. It’s a fairly complex document that contains information about the mortgage applicant, type of property being purchased, amount being financed, and other details about the nature of the property purchase. The following is a sample URLA-1003, and our intention is to extract information from this structured document. Because this is a form, we use the AnalyzeDocument API with a feature type of FORM.

The FORM feature type extracts form information from the document, which is then returned in key-value pair format. The following code snippet uses the amazon-textract-textractor Python library to extract form information with just a few lines of code. The convenience method call_textract() calls the AnalyzeDocument API internally, and the parameters passed to the method abstract some of the configurations that the API needs to run the extraction task. Document is a convenience method used to help parse the JSON response from the API. It provides a high-level abstraction and makes the API output iterable and easy to get information out of. For more information, refer to Textract Response Parser and Textractor.
Note that the output contains values for check boxes or radio buttons that exist in the form. For example, in the sample URLA-1003 document, the Purchase option was selected. The corresponding output for the radio button is extracted as “Purchase” (key) and “SELECTED” (value), indicating that radio button was selected.
Extract data from 1099 forms
A mortgage application packet may also contain a number of IRS documents, such as 1099-DIV, 1099-INT, 1099-MISC, and 1099-R. These documents show the applicant’s earnings via interests, dividends, and other miscellaneous income components that are useful during underwriting to make decisions. The following image shows a collection of these documents, which are similar in structure. However, in some instances, the documents contain form information (marked using the red and green bounding boxes) as well as tabular information (marked by the yellow bounding boxes).

To extract form information, we use similar code as explained earlier with the AnalyzeDocument API. We pass an additional feature of TABLE to the API to indicate that we need both form and table data extracted from the document. The following code snippet uses the AnalyzeDocument API with FORMS and TABLES features on the 1099-INT document:
Because the document contains a single table, the output of the code is as follows:
The table information contains the cell position (row 0, column 0, and so on) and the corresponding text within each cell. We use a convenience method that can transform this table data into easy-to-read grid view:
We get the following output:
To get the output in an easy-to-consume CSV format, the format type of Pretty_Print_Table_Format.csv can be passed into the table_format parameter. Other formats such as TSV (tab separated values), HTML, and Latex are also supported. For more information, refer to Textract-PrettyPrinter.
Extract data from a mortgage note
A mortgage application packet may contain unstructured documents with dense text. Some examples of dense text documents are contracts and agreements. A mortgage note is an agreement between a mortgage applicant and the lender or mortgage company, and contains information in dense text paragraphs. In such cases, the lack of structure makes it difficult to find key business information that is important in the mortgage application process. There are two approaches to solving this problem:
- Use the Amazon Textract
AnalyzeDocumentAPI with the Queries feature - Use an Amazon Comprehend custom entity recognizer
In the following sample mortgage note, we’re specifically interested in finding out the monthly payment amount and principal amount.
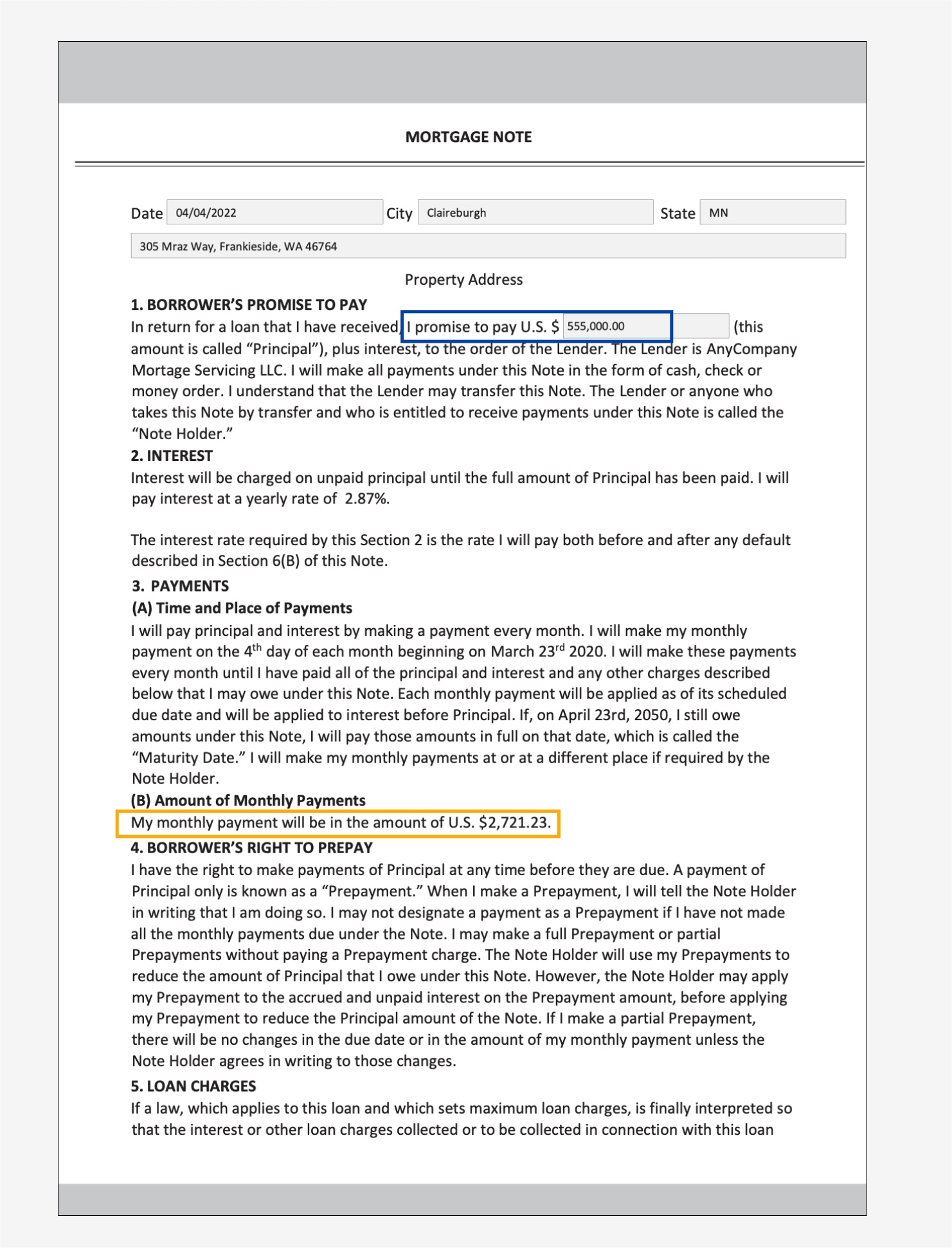
For the first approach, we use the Query and QueriesConfig convenience methods to configure a set of questions that is passed to the Amazon Textract AnalyzeDocument API call. In case the document is multi-page (PDF or TIFF), we can also specify the page numbers where Amazon Textract should look for answers to the question. The following code snippet demonstrates how to create the query configuration, make an API call, and subsequently parse the response to get the answers from the response:
We get the following output:
For the second approach, we use the Amazon Comprehend DetectEntities API with the mortgage note, which returns the entities it detects within the text from a predefined set of entities. These are entities that the Amazon Comprehend entity recognizer is pre-trained with. However, because our requirement is to detect specific entities, an Amazon Comprehend custom entity recognizer is trained with a set of sample mortgage note documents, and a list of entities. We define the entity names as PRINCIPAL_AMOUNT and MONTHLY_AMOUNT. Training data is prepared following the Amazon Comprehend training data preparation guidelines for custom entity recognition. The entity recognizer can be trained with document annotations or with entity lists. For the purposes of this example, we use entity lists to train the model. After we train the model, we can deploy it with a real-time endpoint or in batch mode to detect the two entities from the document contents. The following are the steps involved to train a custom entity recognizer and deploy it. For a full code walkthrough, refer to our GitHub repository.
- Prepare the training data (the entity list and the documents with (UTF-8 encoded) plain text format).
- Start the entity recognizer training using the CreateEntityRecognizer API using the training data.
- Deploy the trained model with a real-time endpoint using the CreateEndpoint API.
Extract data from a US passport
The Amazon Textract analyze identity documents capability can detect and extract information from US-based ID documents such as a driver’s license and passport. The AnalyzeID API is capable of detecting and interpreting implied fields in ID documents, which makes it easy to extract specific information from the document. Identity documents are almost always part of a mortgage application packet, because it’s used to verify the identity of the borrower during the underwriting process, and to validate the correctness of the borrower’s biographical data.

We use a convenience method named call_textract_analyzeid, which calls the AnalyzeID API internally. We then iterate over the response to obtain the detected key-value pairs from the ID document. See the following code:
AnalyzeID returns information in a structure called IdentityDocumentFields, which contains the normalized keys and their corresponding value. For example, in the following output, FIRST_NAME is a normalized key and the value is ALEJANDRO. In the example passport image, the field for the first name is labeled as “Given Names / Prénoms / Nombre,” however AnalyzeID was able to normalize that into the key name FIRST_NAME. For a list of supported normalized fields, refer to Identity Documentation Response Objects.
A mortgage packet may contain several other documents, such as a paystub, W2 form, bank statement, credit card statement, and employment verification letter. We have samples for each of these documents along with the code required to extract data from them. For the complete code base, check out the notebooks in our GitHub repository.
Document enrichment
One of the most common forms of document enrichment is sensitive or confidential information redaction on documents, which may be mandated due to privacy laws or regulations. For example, a mortgage applicant’s paystub may contain sensitive PII data, such as name, address, and SSN, that may need redaction for extended storage.
In the preceding sample paystub document, we perform redaction of PII data such as SSN, name, bank account number, and dates. To identify PII data in a document, we use the Amazon Comprehend PII detection capability via the DetectPIIEntities API. This API inspects the content of the document to identify the presence of PII information. Because this API requires input in UTF-8 encoded plain text format, we first extract the text from the document using the Amazon Textract DetectDocumentText API, which returns the text from the document and also returns geometry information such as bounding box dimensions and coordinates. A combination of both outputs is then used to draw redactions on the document as part of the enrichment process.
Review, validate, and integrate data
Extracted data from the document extraction phase may need validation against specific business rules. Specific information may also be validated across several documents, also known as cross-doc validation. An example of cross-doc validation could be comparing the applicant’s name in the ID document to the name in the mortgage application document. You can also do other validations such as property value estimations and conditional underwriting decisions in this phase.
A third type of validation is related to the confidence score of the extracted data in the document extraction phase. Amazon Textract and Amazon Comprehend return a confidence score for forms, tables, text data, and entities detected. You can configure a confidence score threshold to ensure that only correct values are being sent downstream. This is achieved via Amazon A2I, which compares the confidence scores of detected data with a predefined confidence threshold. If the threshold isn’t met, the document and the extracted output is routed to a human for review through an intuitive UI. The reviewer takes corrective action on the data and saves it for further processing. For more information, refer to Core Concepts of Amazon A2I.
Conclusion
In this post, we discussed the phases of intelligent document processing as it relates to phases of a mortgage application. We looked at a few common examples of documents that can be found in a mortgage application packet. We also discussed ways of extracting and processing structured, semi-structured, and unstructured content from these documents. IDP provides a way to automate end-to-end mortgage document processing that can be scaled to millions of documents, enhancing the quality of application decisions, reducing costs, and serving customers faster.
As a next step, you can try out the code samples and notebooks in our GitHub repository. To learn more about how IDP can help your document processing workloads, visit Automate data processing from documents.
About the authors
 Anjan Biswas is a Senior AI Services Solutions Architect with focus on AI/ML and Data Analytics. Anjan is part of the world-wide AI services team and works with customers to help them understand, and develop solutions to business problems with AI and ML. Anjan has over 14 years of experience working with global supply chain, manufacturing, and retail organizations and is actively helping customers get started and scale on AWS AI services.
Anjan Biswas is a Senior AI Services Solutions Architect with focus on AI/ML and Data Analytics. Anjan is part of the world-wide AI services team and works with customers to help them understand, and develop solutions to business problems with AI and ML. Anjan has over 14 years of experience working with global supply chain, manufacturing, and retail organizations and is actively helping customers get started and scale on AWS AI services.
 Dwiti Pathak is a Senior Technical Account Manager based out of San Diego. She is focused on helping Semiconductor industry engage in AWS. In her spare time, she likes reading about new technologies and playing board games.
Dwiti Pathak is a Senior Technical Account Manager based out of San Diego. She is focused on helping Semiconductor industry engage in AWS. In her spare time, she likes reading about new technologies and playing board games.
 Balaji Puli is a Solutions Architect based in Bay Area, CA. Currently helping select Northwest U.S healthcare life sciences customers accelerate their AWS cloud adoption. Balaji enjoys traveling and loves to explore different cuisines.
Balaji Puli is a Solutions Architect based in Bay Area, CA. Currently helping select Northwest U.S healthcare life sciences customers accelerate their AWS cloud adoption. Balaji enjoys traveling and loves to explore different cuisines.