A guest post by Jan Kieseler from CERN, EP/CMG
Introduction
At large colliders such as the CERN LHC (Large Hadron Collider) high energetic particle beams collide and thereby create massive and possibly yet unknown particles from the collision energy following the well known equation E=mc2. Most of these newly created particles are not stable and decay to more stable particles almost immediately. Detecting these decay products and measuring their properties precisely is the key to understanding what happened during the high energy collision, and will possibly shed light on big questions such as the origin of dark matter.
Detecting and measuring particles
For this purpose, the collision interaction points are surrounded by large detectors covering as much as possible in all possible directions and energies of the decay products. These detectors are further split into sub-detectors, each collecting complementary information. The innermost detector, closest to the interaction point, is the tracker consisting of multiple layers. Similar to a camera, each layer can detect the spatial position at which a charged particle passed through it, providing access to its trajectory. Combined with a strong magnetic field, this trajectory gives access to the particle charge and the particle momentum.
While the tracker is aimed at measuring the trajectories, only, while minimising any further interaction with and scattering of the particles, the next sub-detector layer is aimed at stopping them entirely. By stopping the particles completely, these calorimeters can extract the initial particle energy, and can also detect neutral particles. The only particles that pass through these calorimeters are muons, which are identified by additional muon chambers that constitute the outermost detector shell and use the same detection principles as the tracker.
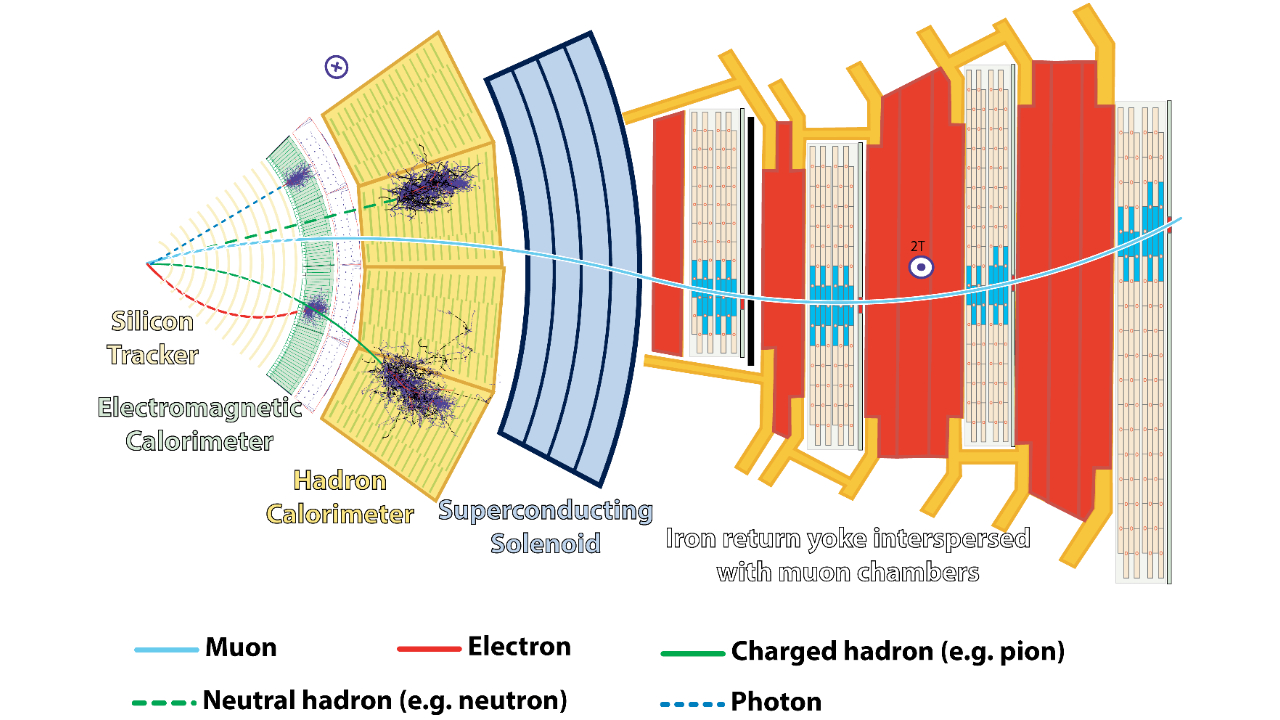
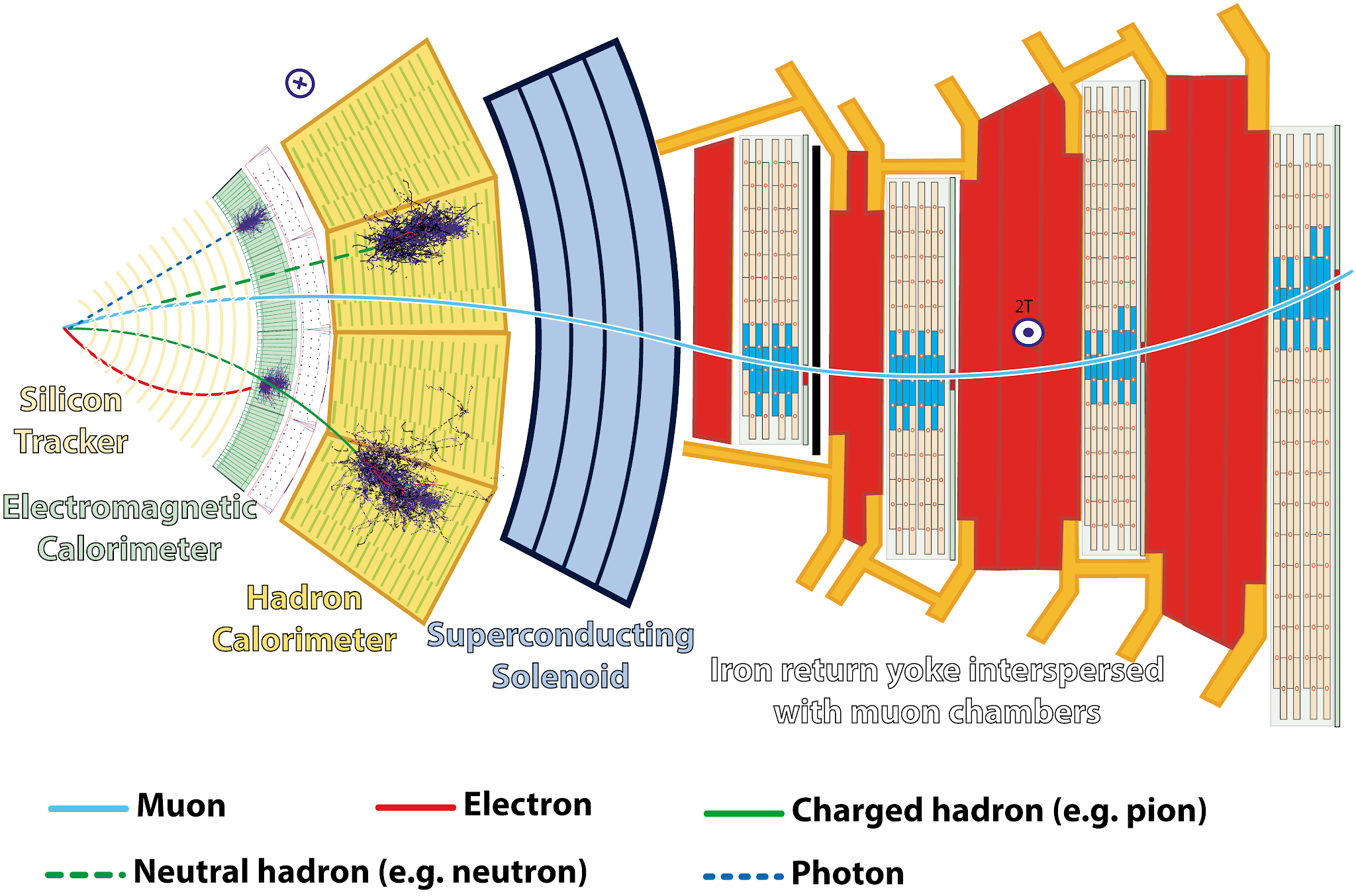 |
| Layout of the CMS detector, showing different particle species interacting with the sub-detectors (Image credit: CERN). |
Combining the information from all these sub-detectors to reconstruct the final particles is a challenging task, not only because we want to achieve the best physics performance, but also in terms of computing resources and person-power available to develop and tune the reconstruction algorithms. In particular for the High-Luminosity LHC, the extension of the CERN LHC, aiming to collect unprecedented amounts of data, these algorithms need to perform well given a collision rate of 40MHz and up to 200 simultaneous interactions in each collision, which result in up to about a million signals from all sub-detectors.
Even with triggers, a fast, step-wise filtering of interesting events, in place, the total data collected to disk still comprises several petabytes, making efficient algorithms a must at all stages.
Classic reconstruction algorithms in high energy physics heavily rely on factorisation of individual steps and a lot of domain (physics) knowledge. While they perform reasonably well, the idealistic assumptions that are needed to develop these algorithms limit the performance, such that machine-learning approaches are often used to refine the classically reconstructed particles, and make their way into more and more reconstruction chains. The machine learning approaches benefit from a very precise simulation of all detector components and physics processes, valid over several orders of magnitude, such that large sets of labelled data can be produced very easily in a short amount of time. This led to a rise of neural network based identification and regression algorithms, and to the inclusion of TensorFlow as the standard inference engine in the software framework of the Compact Muon Solenoid (CMS) experiment.
Machine-learning reconstruction approaches also come with the advantage that by construction they have to be automatically optimizable and need a loss function to train that quantifies the final reconstruction target. In contrast, classic approaches are often optimised without the need to define such an inclusive quantitative metric, and parameters are tuned by hand, involving many experts, and taking a lot of person-power that could be spent on developing new algorithms instead of tuning existing ones. Therefore, moving to differentiable machine-learning algorithms such as deep neural networks in general can also help use the human resources more efficiently.
However, extending machine-learning based algorithms to the first step of reconstructing the particles from hits – instead of just refining already reconstructed particles – comes with two main challenges: the data structure and phrasing reconstruction as a minimisation problem.
The detector data is highly irregular, due to the inclusion of multiple sub-detectors, each with its own geometry. But even within a sub-detector, such as the tracker, the geometry is designed based on physics aspects with a fine resolution close to the interaction point and more coarse further away. Furthermore, the individual tracker layers are not densely packed, but have a considerable amount of space between them, and in each event only a small fraction of sensors are actually active, changing the number of inputs from event to event. Therefore, neural networks that require a regular grid, such as convolutional neural network architectures are – despite their good performance and highly optimised implementations – not applicable.
Graph neural networks can bridge this gap and, in principle, allow abstracting from the detector geometry. Recently, several graph neural network proposals from computer science have been studied in the context of refining already reconstructed particles in high energy physics. However, given the high input dimensionality of the data many of these proposals cannot be employed for reconstructing particles directly from hits, and custom solutions are needed. One example is GravNet that – by construction – reduces the resource requirements significantly while maintaining good physics performance by using sparse dynamic adjacency matrices and performing most operations without memory overhead.
This in particular becomes possible through TensorFlow which makes it easy to implement and load custom kernels into the graph and integrate custom analytic gradients for fused operations. Only the combination of these custom kernels and the network structure allows loading a full physics event into the GPU memory, training the network on it, and performing the inference.
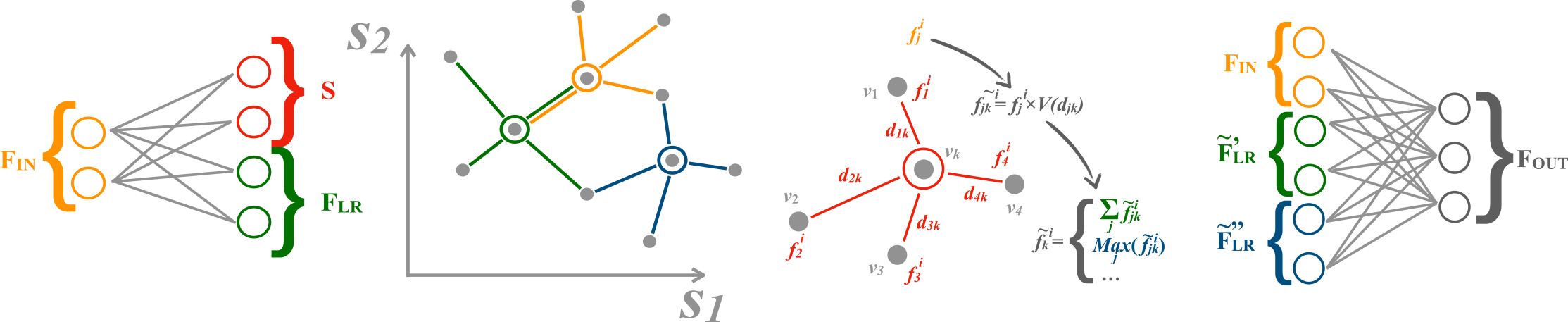 |
| GravNet layer architecture (from left to right): point features are projected into a feature space FLR, and a low dimensional coordinate space S; k nearest neighbours are determined in S; mean and maximum of distance weighted neighbour features are accumulated; accumulated features are combined with original features. |
Since many of the reconstruction tasks, even the refinement of already reconstructed particles, rely on an unknown number of inputs, the recent addition and support of ragged data structures in TensorFlow in principle opens up a lot of new possibilities. While the integration is not sufficient to build full neural network architectures, yet, a future full support of ragged data structures would be a significant step forward for integrating TensorFlow even deeper into the reconstruction algorithms and would make some custom kernels obsolete.
The second challenge when reconstructing particles directly from hits using deep neural networks is to train the network to predict an unknown number of particles from an unknown number of inputs. There is a plethora of algorithms and training methods for detecting dense objects in dense data, such as images, but while the requirement of the dense data can be loosened in some cases, most of these algorithms still rely on the objects being dense or having a clear boundary, making it possible to exploit anchor boxes or central points of the object. Particles in the detector however, often overlap to a large degree, and their sparsity does not allow defining central points nor clear boundaries. A solution to this problem is Object Condensation, where object properties are condensed in at least one representative condensation point per object that can be chosen freely by the network through a high confidence score.
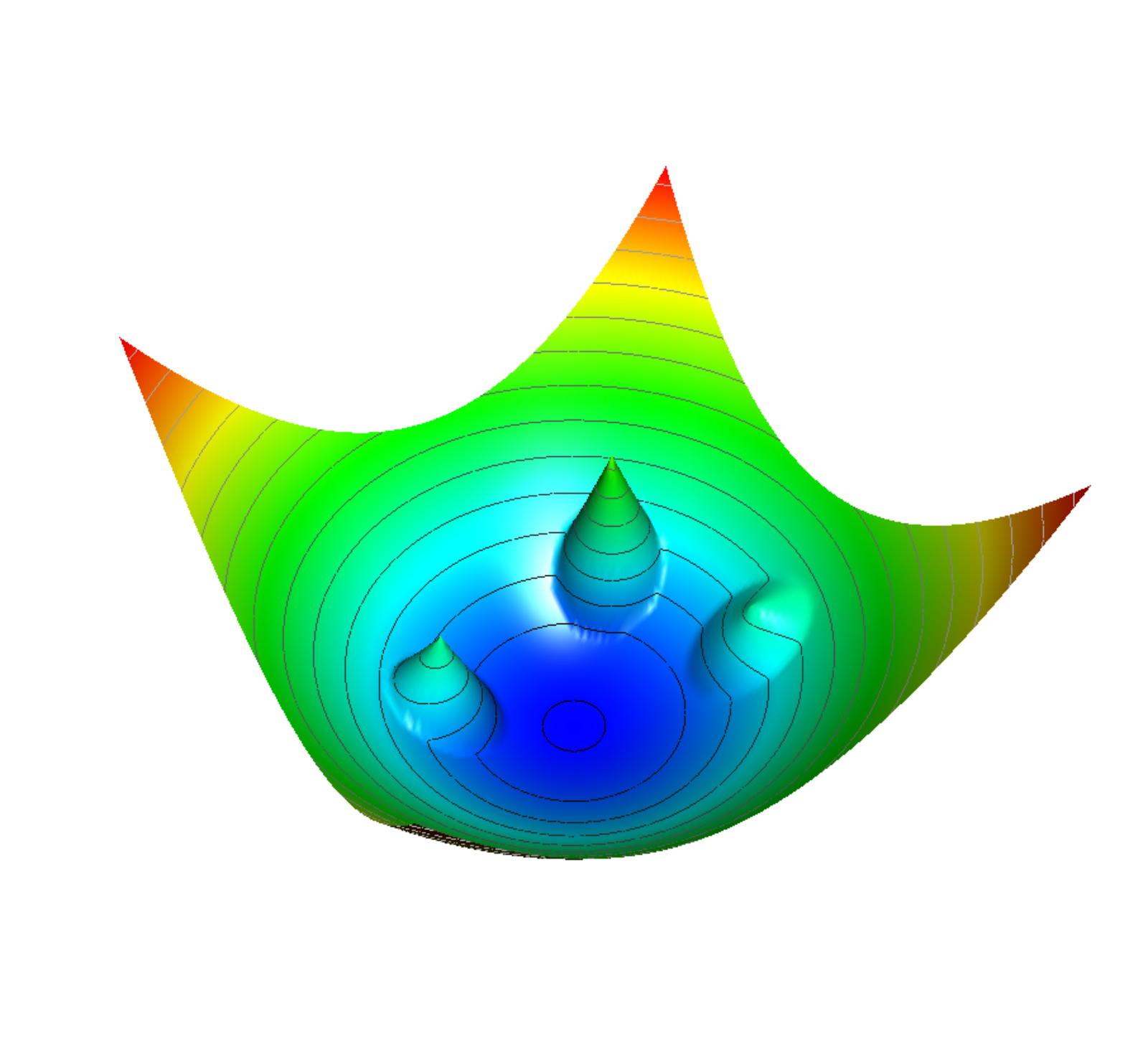
To resolve ambiguities, the other points are clustered around the object they belong to using potential functions (illustrated above). However, these potentials scale with the confidence score in a tunable manner, such that the amount of segmentation the network should perform is adjustable up to the point where all points except the condensation points can be left free floating in case we are only interested in the final object properties.
Some parts of this algorithm are very similar to the method proposed in a previous paper, but the goal is entirely different. While the previous approach constitutes a very powerful segmentation algorithm moving pixels to cluster objects in an image towards a central point, the condensation points here directly carry object properties, and through the choice of the potential functions the clustering space can be completely detached from the input space. The latter has big implications for the applicability to the sparse detector data with overlapping particles, but also does not distinguish conceptually between “stuff” and “things”, providing a new perspective on one-shot panoptic segmentation.
But coming back to particle reconstruction, as shown in the corresponding paper, Object Condensation can outperform classic particle reconstruction algorithms even on simplified problems that are quite close to the idealistic assumptions of the classic algorithm. Therefore, it provides an alternative to classic reconstruction approaches directly from hits.
Based on this promising study, there is work ongoing to extend the approach to simulated events in the High Granularity Calorimeter, a planned new sub-detector of the CMS experiment at CERN, with about 2 million sensors, covering the particularly challenging forward region close to the incident beams, where most particles are produced. Compared to the published proof-of-concept, this realistic environment is much more challenging and requires the optimisation of the network structures and even more custom TensorFlow operations that can be found in the developing repository on github, using DeepJetCore as an interface to data formats commonly used in high-energy physics. Right now, there is a particular focus on implementing fast k-nearest-neighbour algorithms, a crucial building block for GravNet, that can handle the large input dimensionality, but also ragged implementations of other operations as well as implementations of the Object Condensation loss can be found there.
Conclusion
To conclude, the application of deep neural networks to reconstruction tasks is exhibiting a shift from refining classically reconstructed particles to reconstructing the particles and their properties directly, in an optimizable and highly parallelizable way to meet the person-power and computing challenges in the future. This development will give rise to more custom implementations, and will be using more of the bleeding edge features in TensorFlow and tf.keras such as ragged data structures, so that a closer contact between high-energy physics reconstruction developers and TensorFlow developers is foreseeable.
Acknowledgements
I would like to acknowledge the support of Thiru Palanisamy and Josh Gordon at Google for their help with the blog post collaboration and with providing active feedback.