Near-real-time delivery of data and insights enable businesses to rapidly respond to their customers’ needs. Real-time data can come from a variety of sources, including social media, IoT devices, infrastructure monitoring, call center monitoring, and more. Due to the breadth and depth of data being ingested from multiple sources, businesses look for solutions to protect their customers’ privacy and keep sensitive data from being accessed from end systems. You previously had to rely on personally identifiable information (PII) rules engines that could flag false positives or miss data, or you had to build and maintain custom machine learning (ML) models to identify PII in your streaming data. You also needed to implement and maintain the infrastructure necessary to support these engines or models.
To help streamline this process and reduce costs, you can use Amazon Comprehend, a natural language processing (NLP) service that uses ML to find insights and relationships like people, places, sentiments, and topics in unstructured text. You can now use Amazon Comprehend ML capabilities to detect and redact PII in customer emails, support tickets, product reviews, social media, and more. No ML experience is required. For example, you can analyze support tickets and knowledge articles to detect PII entities and redact the text before you index the documents. After that, documents are free of PII entities and users can consume the data. Redacting PII entities helps you protect your customer’s privacy and comply with local laws and regulations.
In this post, you learn how to implement Amazon Comprehend into your streaming architectures to redact PII entities in near-real time using Amazon Kinesis Data Firehose with AWS Lambda.
This post is focused on redacting data from select fields that are ingested into a streaming architecture using Kinesis Data Firehose, where you want to create, store, and maintain additional derivative copies of the data for consumption by end-users or downstream applications. If you’re using Amazon Kinesis Data Streams or have additional use cases outside of PII redaction, refer to Translate, redact and analyze streaming data using SQL functions with Amazon Kinesis Data Analytics, Amazon Translate, and Amazon Comprehend, where we show how you can use Amazon Kinesis Data Analytics Studio powered by Apache Zeppelin and Apache Flink to interactively analyze, translate, and redact text fields in streaming data.
Solution overview
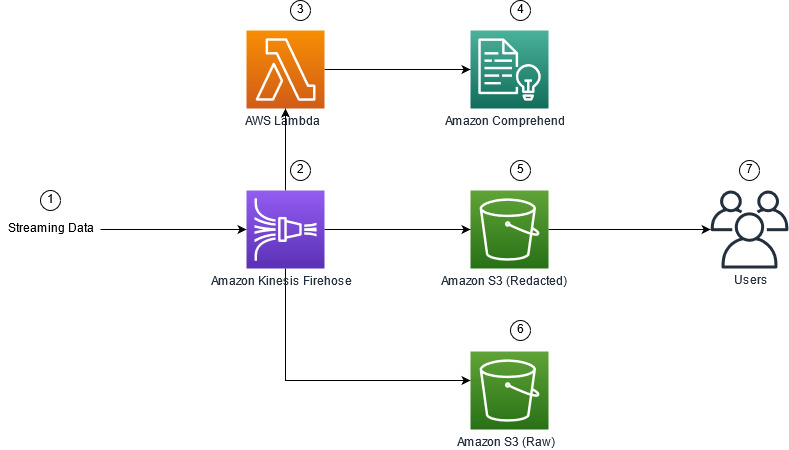
The following figure shows an example architecture for performing PII redaction of streaming data in real time, using Amazon Simple Storage Service (Amazon S3), Kinesis Data Firehose data transformation, Amazon Comprehend, and AWS Lambda. Additionally, we use the AWS SDK for Python (Boto3) for the Lambda functions. As indicated in the diagram, the S3 raw bucket contains non-redacted data, and the S3 redacted bucket contains redacted data after using the Amazon Comprehend DetectPiiEntities API within a Lambda function.
Costs involved
In addition to Kinesis Data Firehose, Amazon S3, and Lambda costs, this solution will incur usage costs from Amazon Comprehend. The amount you pay is a factor of the total number of records that contain PII and the characters that are processed by the Lambda function. For more information, refer to Amazon Kinesis Data Firehose pricing, Amazon Comprehend Pricing, and AWS Lambda Pricing.
As an example, let’s assume you have 10,000 logs records, and the key value you want to redact PII from is 500 characters. Out of the 10,000 log records, 50 are identified as containing PII. The cost details are as follows:
Contains PII Cost:
- Size of each key value = 500 characters (1 unit = 100 characters)
- Number of units (100 characters) per record (minimum is 3 units) = 5
- Total units = 10,000 (records) x 5 (units per record) x 1 (Amazon Comprehend requests per record) = 50,000
- Price per unit = $0.000002
- Total cost for identifying log records with PII using ContainsPiiEntities API = $0.1 [50,000 units x $0.000002]
Redact PII Cost:
- Total units containing PII = 50 (records) x 5 (units per record) x 1 (Amazon Comprehend requests per record) = 250
- Price per unit = $0.0001
- Total cost for identifying location of PII using DetectPiiEntities API = [number of units] x [cost per unit] = 250 x $0.0001 = $0.025
Total Cost for identification and redaction:
- Total cost: $0.1 (validation if field contains PII) + $0.025 (redact fields that contain PII) = $0.125
Deploy the solution with AWS CloudFormation
For this post, we provide an AWS CloudFormation streaming data redaction template, which provides the full details of the implementation to enable repeatable deployments. Upon deployment, this template creates two S3 buckets: one to store the raw sample data ingested from the Amazon Kinesis Data Generator (KDG), and one to store the redacted data. Additionally, it creates a Kinesis Data Firehose delivery stream with DirectPUT as input, and a Lambda function that calls the Amazon Comprehend ContainsPiiEntities and DetectPiiEntities API to identify and redact PII data. The Lambda function relies on user input in the environment variables to determine what key values need to be inspected for PII.
The Lambda function in this solution has limited payload sizes to 100 KB. If a payload is provided where the text is greater than 100 KB, the Lambda function will skip it.
To deploy the solution, complete the following steps:
- Launch the CloudFormation stack in US East (N. Virginia)
us-east-1:

- Enter a stack name, and leave other parameters at their default
- Select I acknowledge that AWS CloudFormation might create IAM resources with custom names.
- Choose Create stack.
Deploy resources manually
If you prefer to build the architecture manually instead of using AWS CloudFormation, complete the steps in this section.
Create the S3 buckets
Create your S3 buckets with the following steps:
- On the Amazon S3 console, choose Buckets in the navigation pane.
- Choose Create bucket.
- Create one bucket for your raw data and one for your redacted data.
- Note the names of the buckets you just created.
Create the Lambda function
To create and deploy the Lambda function, complete the following steps:
- On the Lambda console, choose Create function.
- Choose Author from scratch.
- For Function Name, enter
AmazonComprehendPII-Redact. - For Runtime, choose Python 3.9.
- For Architecture, select x86_64.
- For Execution role, select Create a new role with Lambda permissions.
- After you create the function, enter the following code:
- Choose Deploy.
- In the navigation pane, choose Configuration.
- Navigate to Environment variables.
- Choose Edit.
- For Key, enter
keys. - For Value, enter the key values you want to redact PII from, separated by a comma and space. For example, enter
Tweet1,Tweet2if you’re using the sample test data provided in the next section of this post. - Choose Save.
- Navigate to General configuration.
- Choose Edit.
- Change the value of Timeout to 1 minute.
- Choose Save.
- Navigate to Permissions.
- Choose the role name under Execution Role.
You’re redirected to the AWS Identity and Access Management (IAM) console. - For Add permissions, choose Attach policies.
- Enter
Comprehendinto the search bar and choose the policyComprehendFullAccess. - Choose Attach policies.
Create the Firehose delivery stream
To create your Firehose delivery stream, complete the following steps:
- On the Kinesis Data Firehose console, choose Create delivery stream.
- For Source, select Direct PUT.
- For Destination, select Amazon S3.
- For Delivery stream name, enter
ComprehendRealTimeBlog. - Under Transform source records with AWS Lambda, select Enabled.
- For AWS Lambda function, enter the ARN for the function you created, or browse to the function
AmazonComprehendPII-Redact. - For Buffer Size, set the value to 1 MB.
- For Buffer Interval, leave it as 60 seconds.
- Under Destination Settings, select the S3 bucket you created for the redacted data.
- Under Backup Settings, select the S3 bucket that you created for the raw records.
- Under Permission, either create or update an IAM role, or choose an existing role with the proper permissions.
- Choose Create delivery stream.
Deploy the streaming data solution with the Kinesis Data Generator
You can use the Kinesis Data Generator (KDG) to ingest sample data to Kinesis Data Firehose and test the solution. To simplify this process, we provide a Lambda function and CloudFormation template to create an Amazon Cognito user and assign appropriate permissions to use the KDG.
- On the Amazon Kinesis Data Generator page, choose Create a Cognito User with CloudFormation.You’re redirected to the AWS CloudFormation console to create your stack.
- Provide a user name and password for the user with which you log in to the KDG.
- Leave the other settings at their defaults and create your stack.
- On the Outputs tab, choose the KDG UI link.
- Enter your user name and password to log in.
Send test records and validate redaction in Amazon S3
To test the solution, complete the following steps:
- Log in to the KDG URL you created in the previous step.
- Choose the Region where the AWS CloudFormation stack was deployed.
- For Stream/delivery stream, choose the delivery stream you created (if you used the template, it has the format
accountnumber-awscomprehend-blog). - Leave the other settings at their defaults.
- For the record template, you can create your own tests, or use the following template.If you’re using the provided sample data below for testing, you should have updated environment variables in the
AmazonComprehendPII-RedactLambda function toTweet1,Tweet2. If deployed via CloudFormation, update environment variables toTweet1,Tweet2within the created Lambda function. The sample test data is below: - Choose Send Data, and allow a few seconds for records to be sent to your stream.
- After few seconds, stop the KDG generator and check your S3 buckets for the delivered files.
The following is an example of the raw data in the raw S3 bucket:
The following is an example of the redacted data in the redacted S3 bucket:
The sensitive information has been removed from the redacted messages, providing confidence that you can share this data with end systems.
Cleanup
When you’re finished experimenting with this solution, clean up your resources by using the AWS CloudFormation console to delete all the resources deployed in this example. If you followed the manual steps, you will need to manually delete the two buckets, the AmazonComprehendPII-Redact function, the ComprehendRealTimeBlog stream, the log group for the ComprehendRealTimeBlog stream, and any IAM roles that were created.
Conclusion
This post showed you how to integrate PII redaction into your near-real-time streaming architecture and reduce data processing time by performing redaction in flight. In this scenario, you provide the redacted data to your end-users and a data lake administrator secures the raw bucket for later use. You could also build additional processing with Amazon Comprehend to identify tone or sentiment, identify entities within the data, and classify each message.
We provided individual steps for each service as part of this post, and also included a CloudFormation template that allows you to provision the required resources in your account. This template should be used for proof of concept or testing scenarios only. Refer to the developer guides for Amazon Comprehend, Lambda, and Kinesis Data Firehose for any service limits.
To get started with PII identification and redaction, see Personally identifiable information (PII). With the example architecture in this post, you could integrate any of the Amazon Comprehend APIs with near-real-time data using Kinesis Data Firehose data transformation. To learn more about what you can build with your near-real-time data with Kinesis Data Firehose, refer to the Amazon Kinesis Data Firehose Developer Guide. This solution is available in all AWS Regions where Amazon Comprehend and Kinesis Data Firehose are available.
About the authors
 Joe Morotti is a Solutions Architect at Amazon Web Services (AWS), helping Enterprise customers across the Midwest US. He has held a wide range of technical roles and enjoy showing customer’s art of the possible. In his free time, he enjoys spending quality time with his family exploring new places and overanalyzing his sports team’s performance
Joe Morotti is a Solutions Architect at Amazon Web Services (AWS), helping Enterprise customers across the Midwest US. He has held a wide range of technical roles and enjoy showing customer’s art of the possible. In his free time, he enjoys spending quality time with his family exploring new places and overanalyzing his sports team’s performance
 Sriharsh Adari is a Senior Solutions Architect at Amazon Web Services (AWS), where he helps customers work backwards from business outcomes to develop innovative solutions on AWS. Over the years, he has helped multiple customers on data platform transformations across industry verticals. His core area of expertise include Technology Strategy, Data Analytics, and Data Science. In his spare time, he enjoys playing Tennis, binge-watching TV shows, and playing Tabla.
Sriharsh Adari is a Senior Solutions Architect at Amazon Web Services (AWS), where he helps customers work backwards from business outcomes to develop innovative solutions on AWS. Over the years, he has helped multiple customers on data platform transformations across industry verticals. His core area of expertise include Technology Strategy, Data Analytics, and Data Science. In his spare time, he enjoys playing Tennis, binge-watching TV shows, and playing Tabla.