Amazon SageMaker multi-model endpoint (MME) enables you to cost-effectively deploy and host multiple models in a single endpoint and then horizontally scale the endpoint to achieve scale. As illustrated in the following figure, this is an effective technique to implement multi-tenancy of models within your machine learning (ML) infrastructure. We have seen software as a service (SaaS) businesses use this feature to apply hyper-personalization in their ML models while achieving lower costs.
For a high-level overview of how MME work, check out the AWS Summit video Scaling ML to the next level: Hosting thousands of models on SageMaker. To learn more about the hyper-personalized, multi-tenant use cases that MME enables, refer to How to scale machine learning inference for multi-tenant SaaS use cases.
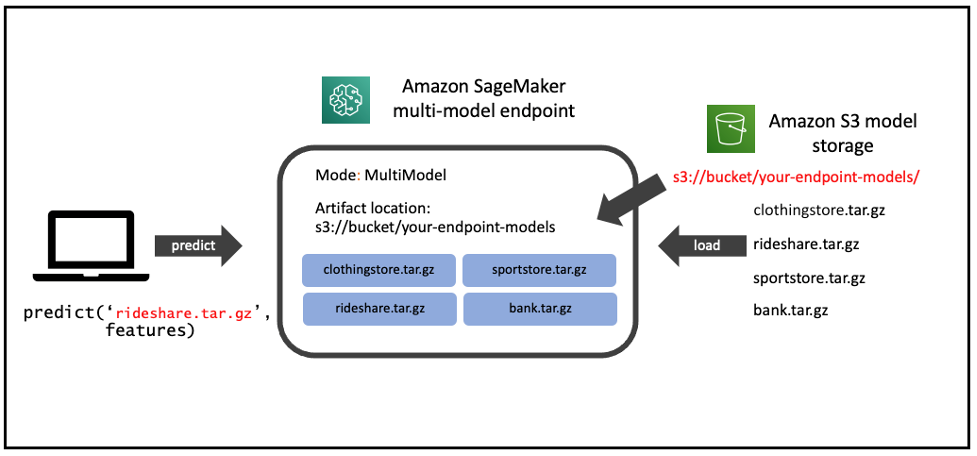
In the rest of this post, we dive deeper into the technical architecture of SageMaker MME and share best practices for optimizing your multi-model endpoints.
Use cases best suited for MME
SageMaker multi-model endpoints are well suited for hosting a large number of models that you can serve through a shared serving container and you don’t need to access all the models at the same time. Depending on the size of the endpoint instance memory, a model may occasionally be unloaded from memory in favor of loading a new model to maximize efficient use of memory, therefore your application needs to be tolerant of occasional latency spikes on unloaded models.
MME is also designed for co-hosting models that use the same ML framework because they use the shared container to load multiple models. Therefore, if you have a mix of ML frameworks in your model fleet (such as PyTorch and TensorFlow), SageMaker dedicated endpoints or multi-container hosting is a better choice.
Finally, MME is suited for applications that can tolerate an occasional cold start latency penalty, because models are loaded on first invocation and infrequently used models can be offloaded from memory in favor of loading new models. Therefore, if you have a mix of frequently and infrequently accessed models, a multi-model endpoint can efficiently serve this traffic with fewer resources and higher cost savings.
We have also seen some scenarios where customers deploy an MME cluster with enough aggregate memory capacity to fit all their models, thereby avoiding model offloads altogether yet still achieving cost savings because of the shared inference infrastructure.
Model serving containers
When you use the SageMaker Inference Toolkit or a pre-built SageMaker model serving container compatible with MME, your container has the Multi Model Server (JVM process) running. The easiest way to have Multi Model Server (MMS) incorporated into your model serving container is to use SageMaker model serving containers compatible with MME (look for those with Job Type=inference and CPU/GPU=CPU). MMS is an open source, easy-to-use tool for serving deep learning models. It provides a REST API with a web server to serve and manage multiple models on a single host. However, it’s not mandatory to use MMS; you could implement your own model server as long as it implements the APIs required by MME.
When used as part of the MME platform, all predict, load, and unload API calls to MMS or your own model server are channeled through the MME data plane controller. API calls from the data plane controller are made over local host only to prevent unauthorized access from outside of the instance. One of the key benefits of MMS is that it enables a standardized interface for loading, unloading, and invoking models with compatibility across a wide range of deep learning frameworks.
Advanced configuration of MMS
If you choose to use MMS for model serving, consider the following advanced configurations to optimize the scalability and throughput of your MME instances.
Increase inference parallelism per model
MMS creates one or more Python worker processes per model based on the value of the default_workers_per_model configuration parameter. These Python workers handle each individual inference request by running any preprocessing, prediction, and post processing functions you provide. For more information, see the custom service handler GitHub repo.
Having more than one model worker increases the parallelism of predictions that can be served by a given model. However, when a large number of models are being hosted on an instance with a large number of CPUs, you should perform a load test of your MME to find the optimum value for default_workers_per_model to prevent any memory or CPU resource exhaustion.
Design for traffic spikes
Each MMS process within an endpoint instance has a request queue that can be configured with the job_queue_size parameter (default is 100). This determines the number of requests MMS will queue when all worker processes are busy. Use this parameter to fine-tune the responsiveness of your endpoint instances after you’ve decided on the optimal number of workers per model.
In an optimal worker per model ratio, the default of 100 should suffice for most cases. However, for those cases where request traffic to the endpoint spikes unusually, you can reduce the size of the queue if you want the endpoint to fail fast to pass control to the application or increase the queue size if you want the endpoint to absorb the spike.
Maximize memory resources per instance
When using multiple worker processes per model, by default each worker process loads its own copy of the model. This can reduce the available instance memory for other models. You can optimize memory utilization by sharing a single model between worker processes by setting the configuration parameter preload_model=true. Here you’re trading off reduced inference parallelism (due to a single model instance) with more memory efficiency. This setting along with multiple worker processes can be a good choice for use cases where model latency is low but you have heavier preprocessing and postprocessing (done by the worker processes) per inference request.
Set values for MMS advanced configurations
MMS uses a config.properties file to store configurations. MMS uses the following order to locate this config.properties file:
- If the
MMS_CONFIG_FILEenvironment variable is set, MMS loads the configuration from the environment variable. - If the
--mms-configparameter is passed to MMS, it loads the configuration from the parameter. - If there is a
config.propertiesin current folder where the user starts MMS, it loads theconfig.propertiesfile from the current working directory.
If none of the above are specified, MMS loads the built-in configuration with default values.
The following is a command line example of starting MMS with an explicit configuration file:
Key metrics to monitor your endpoint performance
The key metrics that can help you optimize your MME are typically related to CPU and memory utilization and inference latency. The instance-level metrics are emitted by MMS, whereas the latency metrics come from the MME. In this section, we discuss the typical metrics that you can use to understand and optimize your MME.
Endpoint instance-level metrics (MMS metrics)
From the list of MMS metrics, CPUUtilization and MemoryUtilization can help you evaluate whether or not your instance or the MME cluster is right-sized. If both metrics have percentages between 50–80%, then your MME is right-sized.
Typically, low CPUUtilization and high MemoryUtilization is an indication of an over-provisioned MME cluster because it indicates that infrequently invoked models aren’t being unloaded. This could be because of a higher-than-optimal number of endpoint instances provisioned for the MME and therefore higher-than-optimal aggregate memory is available for infrequently accessed models to remain in memory. Conversely, close to 100% utilization of these metrics means that your cluster is under-provisioned, so you need to adjust your cluster auto scaling policy.
Platform-level metrics (MME metrics)
From the full list of MME metrics, a key metric that can help you understand the latency of your inference request is ModelCacheHit. This metric shows the average ratio of invoke requests for which the model was already loaded in memory. If this ratio is low, it indicates your MME cluster is under-provisioned because there’s likely not enough aggregate memory capacity in the MME cluster for the number of unique model invocations, therefore causing models to be frequently unloaded from memory.
Lessons from the field and strategies for optimizing MME
We have seen the following recommendations from some of the high-scale uses of MME across a number of customers.
Horizontal scaling with smaller instances is better than vertical scaling with larger instances
You may experience throttling on model invocations when running high requests per second (RPS) on fewer endpoint instances. There are internal limits to the number of invocations per second (loads and unloads that can happen concurrently on an instance), and therefore it’s always better to have a higher number of smaller instances. Running a higher number of smaller instances means a higher total aggregate capacity of these limits for the endpoint.
Another benefit of horizontally scaling with smaller instances is that you reduce the risk of exhausting instance CPU and memory resources when running MMS with higher levels of parallelism, along with a higher number of models in memory (as described earlier in this post).
Avoiding thrashing is a shared responsibility
Thrashing in MME is when models are frequently unloaded from memory and reloaded due to insufficient memory, either in an individual instance or on aggregate in the cluster.
From a usage perspective, you should right-size individual endpoint instances and right-size the overall size of the MME cluster to ensure enough memory capacity is available per instance and also on aggregate for the cluster for your use case. The MME platform’s router fleet will also maximize the cache hit.
Don’t be aggressive with bin packing too many models on fewer, larger memory instances
Memory isn’t the only resource on the instance to be aware of. Other resources like CPU can be a constraining factor, as seen in the following load test results. In some other cases, we have also observed other kernel resources like process IDs being exhausted on an instance, due to a combination of too many models being loaded and the underlying ML framework (such as TensorFlow) spawning threads per model that were multiples of available vCPUs.
The following performance test demonstrates an example of CPU constraint impacting model latency. In this test, a single instance endpoint with a large instance, while having more than enough memory to keep all four models in memory, produced comparatively worse model latencies under load when compared to an endpoint with four smaller instances.

single instance endpoint model latency

single instance endpoint CPU & memory utilization

four instance endpoint model latency

four instance endpoint CPU & memory utilization
To achieve both performance and cost-efficiency, right-size your MME cluster with higher number of smaller instances that on aggregate give you the optimum memory and CPU capacity while being relatively at par for cost with fewer but larger memory instances.
Mental model for optimizing MME
There are four key metrics that you should always consider when right-sizing your MME:
- The number and size of the models
- The number of unique models invoked at a given time
- The instance type and size
- The instance count behind the endpoint
Start with the first two points, because they inform the third and fourth. For example, if not enough instances are behind the endpoint for the number or size of unique models you have, the aggregate memory for the endpoint will be low and you’ll see a lower cache hit ratio and thrashing at the endpoint level because the MME will load and unload models in and out of memory frequently.
Similarly, if the invocations for unique models are higher than the aggregate memory of all instances behind the endpoint, you’ll see a lower cache hit. This can also happen if the size of instances (especially memory capacity) is too small.
Vertically scaling with really large memory instances could also lead to issues because although the models may fit into memory, other resources like CPU and kernel processes and thread limits could be exhausted. Load test horizontal scaling in pre-production to get the optimum number and size of instances for your MME.
Summary
In this post, you got a deeper understanding of the MME platform. You learned which technical use cases MME is suited for and reviewed the architecture of the MME platform. You gained a deeper understanding of the role of each component within the MME architecture and which components you can directly influence the performance of. Finally, you had a deeper look at the configuration parameters that you can adjust to optimize MME for your use case and the metrics you should monitor to maintain optimum performance.
To get started with MME, review Amazon SageMaker Multi-Model Endpoints using XGBoost and Host multiple models in one container behind one endpoint.
About the Author
 Syed Jaffry is a Principal Solutions Architect with AWS. He works with a range of companies from mid-sized organizations, large enterprises, financial services and ISVs to help them build and operate cost efficient and scalable AI/ML applications in the cloud.
Syed Jaffry is a Principal Solutions Architect with AWS. He works with a range of companies from mid-sized organizations, large enterprises, financial services and ISVs to help them build and operate cost efficient and scalable AI/ML applications in the cloud.
 Saurabh Trikande is a Senior Product Manager for Amazon SageMaker Inference. He is passionate about working with customers and is motivated by the goal of democratizing machine learning. He focuses on core challenges related to deploying complex ML applications, multi-tenant ML models, cost optimizations, and making deployment of deep learning models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch and spending time with his family.
Saurabh Trikande is a Senior Product Manager for Amazon SageMaker Inference. He is passionate about working with customers and is motivated by the goal of democratizing machine learning. He focuses on core challenges related to deploying complex ML applications, multi-tenant ML models, cost optimizations, and making deployment of deep learning models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch and spending time with his family.