NVIDIA researchers are at the forefront of the rapidly advancing field of visual generative AI, developing new techniques to create and interpret images, videos and 3D environments.
More than 50 of these projects will be showcased at the Computer Vision and Pattern Recognition (CVPR) conference, taking place June 17-21 in Seattle. Two of the papers — one on the training dynamics of diffusion models and another on high-definition maps for autonomous vehicles — are finalists for CVPR’s Best Paper Awards.
NVIDIA is also the winner of the CVPR Autonomous Grand Challenge’s End-to-End Driving at Scale track — a significant milestone that demonstrates the company’s use of generative AI for comprehensive self-driving models. The winning submission, which outperformed more than 450 entries worldwide, also received CVPR’s Innovation Award.
NVIDIA’s research at CVPR includes a text-to-image model that can be easily customized to depict a specific object or character, a new model for object pose estimation, a technique to edit neural radiance fields (NeRFs) and a visual language model that can understand memes. Additional papers introduce domain-specific innovations for industries including automotive, healthcare and robotics.
Collectively, the work introduces powerful AI models that could enable creators to more quickly bring their artistic visions to life, accelerate the training of autonomous robots for manufacturing, and support healthcare professionals by helping process radiology reports.
“Artificial intelligence, and generative AI in particular, represents a pivotal technological advancement,” said Jan Kautz, vice president of learning and perception research at NVIDIA. “At CVPR, NVIDIA Research is sharing how we’re pushing the boundaries of what’s possible — from powerful image generation models that could supercharge professional creators to autonomous driving software that could help enable next-generation self-driving cars.”
At CVPR, NVIDIA also announced NVIDIA Omniverse Cloud Sensor RTX, a set of microservices that enable physically accurate sensor simulation to accelerate the development of fully autonomous machines of every kind.
Forget Fine-Tuning: JeDi Simplifies Custom Image Generation
Creators harnessing diffusion models, the most popular method for generating images based on text prompts, often have a specific character or object in mind — they may, for example, be developing a storyboard around an animated mouse or brainstorming an ad campaign for a specific toy.
Prior research has enabled these creators to personalize the output of diffusion models to focus on a specific subject using fine-tuning — where a user trains the model on a custom dataset — but the process can be time-consuming and inaccessible for general users.
JeDi, a paper by researchers from Johns Hopkins University, Toyota Technological Institute at Chicago and NVIDIA, proposes a new technique that allows users to easily personalize the output of a diffusion model within a couple of seconds using reference images. The team found that the model achieves state-of-the-art quality, significantly outperforming existing fine-tuning-based and fine-tuning-free methods.
JeDi can also be combined with retrieval-augmented generation, or RAG, to generate visuals specific to a database, such as a brand’s product catalog.
New Foundation Model Perfects the Pose
NVIDIA researchers at CVPR are also presenting FoundationPose, a foundation model for object pose estimation and tracking that can be instantly applied to new objects during inference, without the need for fine-tuning.
The model, which set a new record on a popular benchmark for object pose estimation, uses either a small set of reference images or a 3D representation of an object to understand its shape. It can then identify and track how that object moves and rotates in 3D across a video, even in poor lighting conditions or complex scenes with visual obstructions.
FoundationPose could be used in industrial applications to help autonomous robots identify and track the objects they interact with. It could also be used in augmented reality applications where an AI model is used to overlay visuals on a live scene.
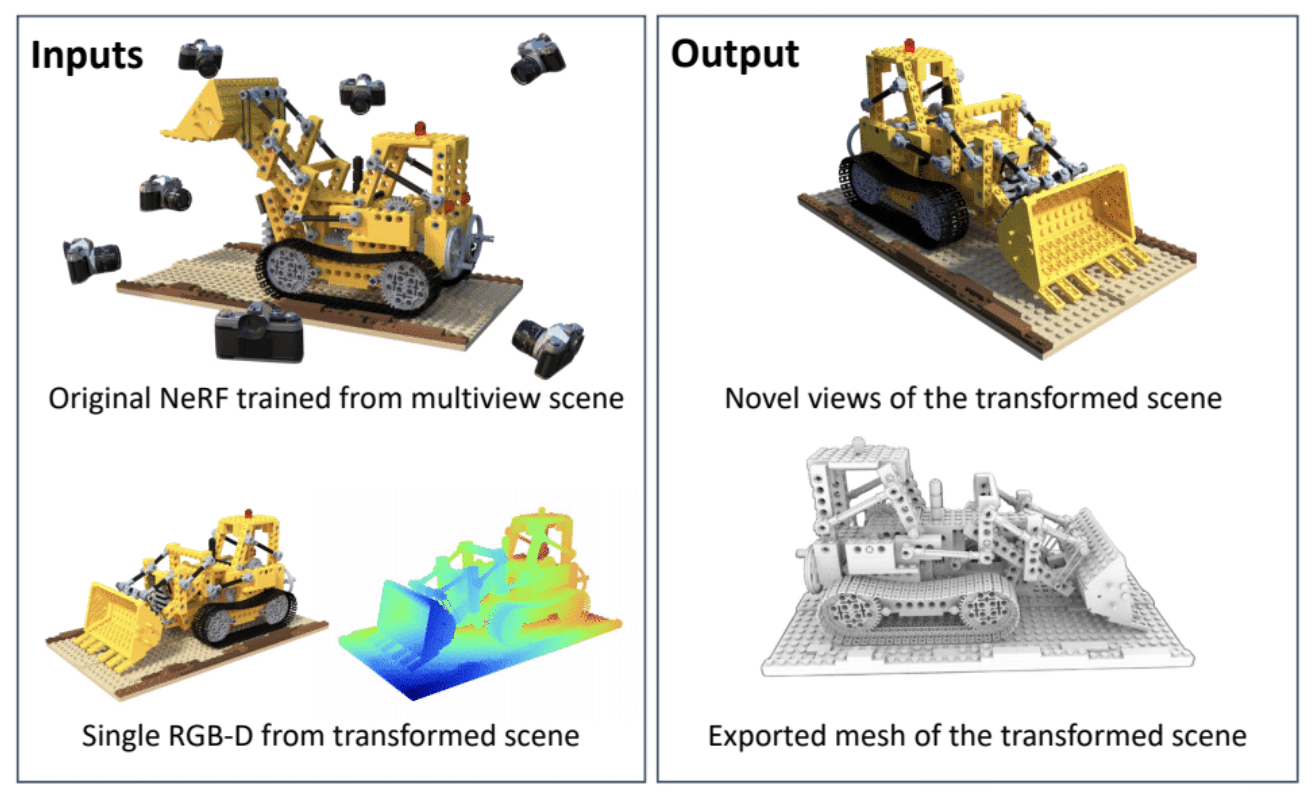
NeRFDeformer Transforms 3D Scenes With a Single Snapshot
A NeRF is an AI model that can render a 3D scene based on a series of 2D images taken from different positions in the environment. In fields like robotics, NeRFs can be used to generate immersive 3D renders of complex real-world scenes, such as a cluttered room or a construction site. However, to make any changes, developers would need to manually define how the scene has transformed — or remake the NeRF entirely.
Researchers from the University of Illinois Urbana-Champaign and NVIDIA have simplified the process with NeRFDeformer. The method, being presented at CVPR, can successfully transform an existing NeRF using a single RGB-D image, which is a combination of a normal photo and a depth map that captures how far each object in a scene is from the camera.
VILA Visual Language Model Gets the Picture
A CVPR research collaboration between NVIDIA and the Massachusetts Institute of Technology is advancing the state of the art for vision language models, which are generative AI models that can process videos, images and text.
The group developed VILA, a family of open-source visual language models that outperforms prior neural networks on key benchmarks that test how well AI models answer questions about images. VILA’s unique pretraining process unlocked new model capabilities, including enhanced world knowledge, stronger in-context learning and the ability to reason across multiple images.

The VILA model family can be optimized for inference using the NVIDIA TensorRT-LLM open-source library and can be deployed on NVIDIA GPUs in data centers, workstations and even edge devices.
Read more about VILA on the NVIDIA Technical Blog and GitHub.
Generative AI Fuels Autonomous Driving, Smart City Research
A dozen of the NVIDIA-authored CVPR papers focus on autonomous vehicle research. Other AV-related highlights include:
- NVIDIA’s AV applied research, which won the CVPR Autonomous Grand Challenge, is featured in this demo.
- Sanja Fidler, vice president of AI research at NVIDIA, will present on vision language models at the Workshop on Autonomous Driving on June 17.
- Producing and Leveraging Online Map Uncertainty in Trajectory Prediction, a paper authored by researchers from the University of Toronto and NVIDIA, has been selected as one of 24 finalists for CVPR’s best paper award.
Also at CVPR, NVIDIA contributed the largest ever indoor synthetic dataset to the AI City Challenge, helping researchers and developers advance the development of solutions for smart cities and industrial automation. The challenge’s datasets were generated using NVIDIA Omniverse, a platform of APIs, SDKs and services that enable developers to build Universal Scene Description (OpenUSD)-based applications and workflows.
NVIDIA Research has hundreds of scientists and engineers worldwide, with teams focused on topics including AI, computer graphics, computer vision, self-driving cars and robotics. Learn more about NVIDIA Research at CVPR.