Digital publishers are continuously looking for ways to streamline and automate their media workflows in order to generate and publish new content as rapidly as they can.
Publishers can have repositories containing millions of images and in order to save money, they need to be able to reuse these images across articles. Finding the image that best matches an article in repositories of this scale can be a time-consuming, repetitive, manual task that can be automated. It also relies on the images in the repository being tagged correctly, which can also be automated (for a customer success story, refer to Aller Media Finds Success with KeyCore and AWS).
In this post, we demonstrate how to use Amazon Rekognition, Amazon SageMaker JumpStart, and Amazon OpenSearch Service to solve this business problem. Amazon Rekognition makes it easy to add image analysis capability to your applications without any machine learning (ML) expertise and comes with various APIs to fulfil use cases such as object detection, content moderation, face detection and analysis, and text and celebrity recognition, which we use in this example. SageMaker JumpStart is a low-code service that comes with pre-built solutions, example notebooks, and many state-of-the-art, pre-trained models from publicly available sources that are straightforward to deploy with a single click into your AWS account. These models have been packaged to be securely and easily deployable via Amazon SageMaker APIs. The new SageMaker JumpStart Foundation Hub allows you to easily deploy large language models (LLM) and integrate them with your applications. OpenSearch Service is a fully managed service that makes it simple to deploy, scale, and operate OpenSearch. OpenSearch Service allows you to store vectors and other data types in an index, and offers rich functionality that allows you to search for documents using vectors and measuring the semantical relatedness, which we use in this post.
The end goal of this post is to show how we can surface a set of images that are semantically similar to some text, be that an article or tv synopsis.
The following screenshot shows an example of taking a mini article as your search input, rather than using keywords, and being able to surface semantically similar images.
Overview of solution
The solution is divided into two main sections. First, you extract label and celebrity metadata from the images, using Amazon Rekognition. You then generate an embedding of the metadata using a LLM. You store the celebrity names, and the embedding of the metadata in OpenSearch Service. In the second main section, you have an API to query your OpenSearch Service index for images using OpenSearch’s intelligent search capabilities to find images that are semantically similar to your text.
This solution uses our event-driven services Amazon EventBridge, AWS Step Functions, and AWS Lambda to orchestrate the process of extracting metadata from the images using Amazon Rekognition. Amazon Rekognition will perform two API calls to extract labels and known celebrities from the image.
Amazon Rekognition celebrity detection API, returns a number of elements in the response. For this post, you use the following:
- Name, Id, and Urls – The celebrity name, a unique Amazon Rekognition ID, and list of URLs such as the celebrity’s IMDb or Wikipedia link for further information.
- MatchConfidence – A match confidence score that can be used to control API behavior. We recommend applying a suitable threshold to this score in your application to choose your preferred operating point. For example, by setting a threshold of 99%, you can eliminate more false positives but may miss some potential matches.
In your second API call, Amazon Rekognition label detection API, returns a number of elements in the response. You use the following:
- Name – The name of the detected label
- Confidence – The level of confidence in the label assigned to a detected object
A key concept in semantic search is embeddings. A word embedding is a numerical representation of a word or group of words, in the form of a vector. When you have many vectors, you can measure the distance between them, and vectors which are close in distance are semantically similar. Therefore, if you generate an embedding of all of your images’ metadata, and then generate an embedding of your text, be that an article or tv synopsis for example, using the same model, you can then find images which are semantically similar to your given text.
There are many models available within SageMaker JumpStart to generate embeddings. For this solution, you use GPT-J 6B Embedding from Hugging Face. It produces high-quality embeddings and has one of the top performance metrics according to Hugging Face’s evaluation results. Amazon Bedrock is another option, still in preview, where you could choose Amazon Titan Text Embeddings model to generate the embeddings.
You use the GPT-J pre-trained model from SageMaker JumpStart to create an embedding of the image metadata and store this as a k-NN vector in your OpenSearch Service index, along with the celebrity name in another field.
The second part of the solution is to return the top 10 images to the user that are semantically similar to their text, be this an article or tv synopsis, including any celebrities if present. When choosing an image to accompany an article, you want the image to resonate with the pertinent points from the article. SageMaker JumpStart hosts many summarization models which can take a long body of text and reduce it to the main points from the original. For the summarization model, you use the AI21 Labs Summarize model. This model provides high-quality recaps of news articles and the source text can contain roughly 10,000 words, which allows the user to summarize the entire article in one go.
To detect if the text contains any names, potentially known celebrities, you use Amazon Comprehend which can extract key entities from a text string. You then filter by the Person entity, which you use as an input search parameter.
Then you take the summarized article and generate an embedding to use as another input search parameter. It’s important to note that you use the same model deployed on the same infrastructure to generate the embedding of the article as you did for the images. You then use Exact k-NN with scoring script so that you can search by two fields: celebrity names and the vector that captured the semantic information of the article. Refer to this post, Amazon OpenSearch Service’s vector database capabilities explained, on the scalability of Score script and how this approach on large indexes may lead to high latencies.
Walkthrough
The following diagram illustrates the solution architecture.
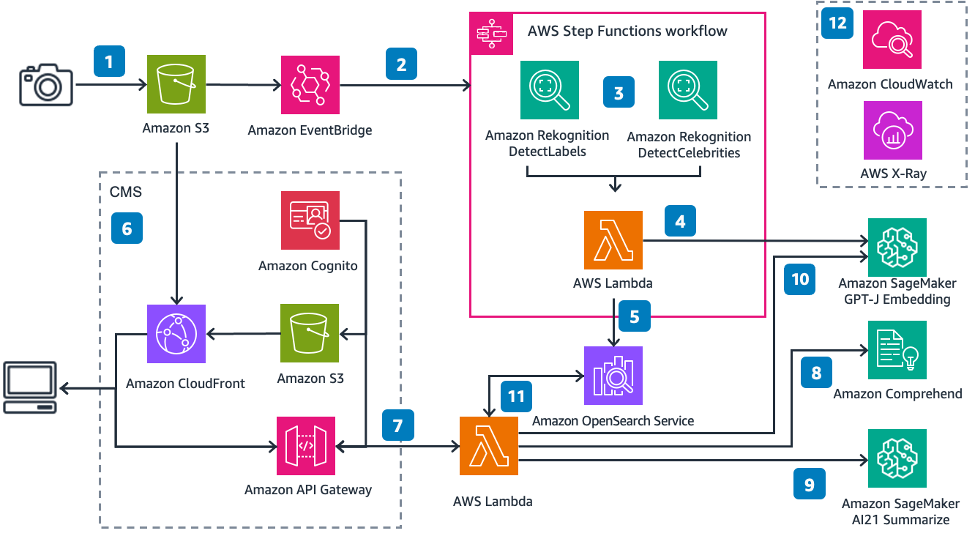
Following the numbered labels:
- You upload an image to an Amazon S3 bucket
- Amazon EventBridge listens to this event, and then triggers an AWS Step function execution
- The Step Function takes the image input, extracts the label and celebrity metadata
- The AWS Lambda function takes the image metadata and generates an embedding
- The Lambda function then inserts the celebrity name (if present) and the embedding as a k-NN vector into an OpenSearch Service index
- Amazon S3 hosts a simple static website, served by an Amazon CloudFront distribution. The front-end user interface (UI) allows you to authenticate with the application using Amazon Cognito to search for images
- You submit an article or some text via the UI
- Another Lambda function calls Amazon Comprehend to detect any names in the text
- The function then summarizes the text to get the pertinent points from the article
- The function generates an embedding of the summarized article
- The function then searches OpenSearch Service image index for any image matching the celebrity name and the k-nearest neighbors for the vector using cosine similarity
- Amazon CloudWatch and AWS X-Ray give you observability into the end to end workflow to alert you of any issues.
Extract and store key image metadata
The Amazon Rekognition DetectLabels and RecognizeCelebrities APIs give you the metadata from your images—text labels you can use to form a sentence to generate an embedding from. The article gives you a text input that you can use to generate an embedding.
Generate and store word embeddings
The following figure demonstrates plotting the vectors of our images in a 2-dimensional space, where for visual aid, we have classified the embeddings by their primary category.

You also generate an embedding of this newly written article, so that you can search OpenSearch Service for the nearest images to the article in this vector space. Using the k-nearest neighbors (k-NN) algorithm, you define how many images to return in your results.
Zoomed in to the preceding figure, the vectors are ranked based on their distance from the article and then return the K-nearest images, where K is 10 in this example.
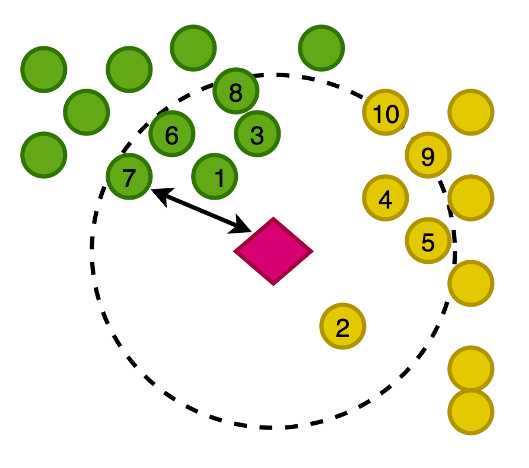
OpenSearch Service offers the capability to store large vectors in an index, and also offers the functionality to run queries against the index using k-NN, such that you can query with a vector to return the k-nearest documents that have vectors in close distance using various measurements. For this example, we use cosine similarity.
Detect names in the article
You use Amazon Comprehend, an AI natural language processing (NLP) service, to extract key entities from the article. In this example, you use Amazon Comprehend to extract entities and filter by the entity Person, which returns any names that Amazon Comprehend can find in the journalist story, with just a few lines of code:
In this example, you upload an image to Amazon Simple Storage Service (Amazon S3), which triggers a workflow where you are extracting metadata from the image including labels and any celebrities. You then transform that extracted metadata into an embedding and store all of this data in OpenSearch Service.
Summarize the article and generate an embedding
Summarizing the article is an important step to make sure that the word embedding is capturing the pertinent points of the article, and therefore returning images that resonate with the theme of the article.
AI21 Labs Summarize model is very simple to use without any prompt and just a few lines of code:
You then use the GPT-J model to generate the embedding
You then search OpenSearch Service for your images
The following is an example snippet of that query:
The architecture contains a simple web app to represent a content management system (CMS).
For an example article, we used the following input:
“Werner Vogels loved travelling around the globe in his Toyota. We see his Toyota come up in many scenes as he drives to go and meet various customers in their home towns.”
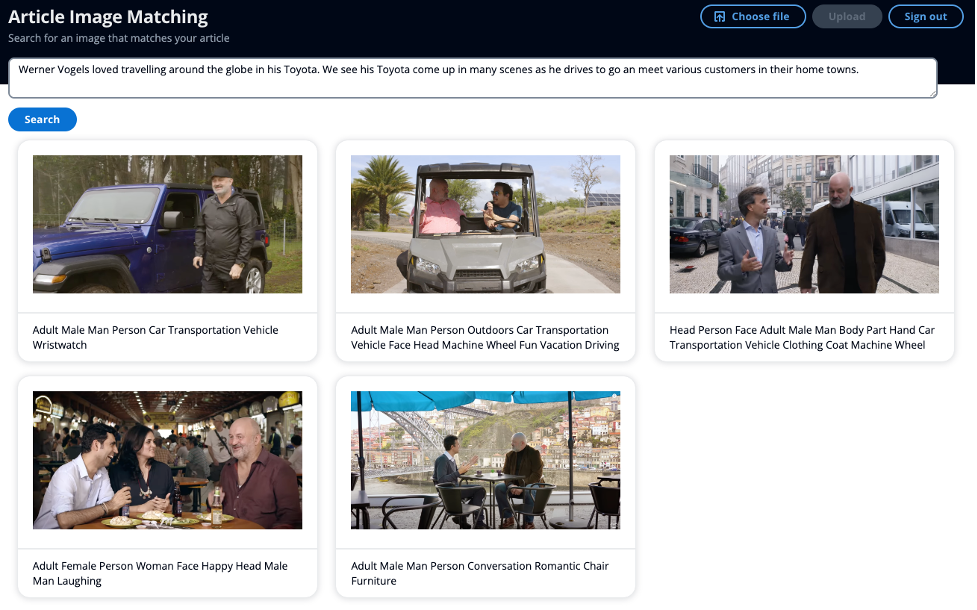
None of the images have any metadata with the word “Toyota,” but the semantics of the word “Toyota” are synonymous with cars and driving. Therefore, with this example, we can demonstrate how we can go beyond keyword search and return images that are semantically similar. In the above screenshot of the UI, the caption under the image shows the metadata Amazon Rekognition extracted.
You could include this solution in a larger workflow where you use the metadata you already extracted from your images to start using vector search along with other key terms, such as celebrity names, to return the best resonating images and documents for your search query.
Conclusion
In this post, we showed how you can use Amazon Rekognition, Amazon Comprehend, SageMaker, and OpenSearch Service to extract metadata from your images and then use ML techniques to discover them automatically using celebrity and semantic search. This is particularly important within the publishing industry, where speed matters in getting fresh content out quickly and to multiple platforms.
For more information about working with media assets, refer to Media intelligence just got smarter with Media2Cloud 3.0.
About the Author
 Mark Watkins is a Solutions Architect within the Media and Entertainment team, supporting his customers solve many data and ML problems. Away from professional life, he loves spending time with his family and watching his two little ones growing up.
Mark Watkins is a Solutions Architect within the Media and Entertainment team, supporting his customers solve many data and ML problems. Away from professional life, he loves spending time with his family and watching his two little ones growing up.