Posted by Zirui Wang, Student Researcher and Yuan Cao, Research Scientist, Google Research, Brain Team
Vision-language modeling grounds language understanding in corresponding visual inputs, which can be useful for the development of important products and tools. For example, an image captioning model generates natural language descriptions based on its understanding of a given image. While there are various challenges to such cross-modal work, significant progress has been made in the past few years on vision-language modeling thanks to the adoption of effective vision-language pre-training (VLP). This approach aims to learn a single feature space from both visual and language inputs, rather than learning two separate feature spaces, one each for visual inputs and another for language inputs. For this purpose, existing VLP often leverages an object detector, like Faster R-CNN, trained on labeled object detection datasets to isolate regions-of-interest (ROI), and relies on task-specific approaches (i.e., task-specific loss functions) to learn representations of images and texts jointly. Such approaches require annotated datasets or time to design task-specific approaches, and so, are less scalable.
To address this challenge, in “SimVLM: Simple Visual Language Model Pre-training with Weak Supervision”, we propose a minimalist and effective VLP, named SimVLM, which stands for “Simple Visual Language Model”. SimVLM is trained end-to-end with a unified objective, similar to language modeling, on a vast amount of weakly aligned image-text pairs (i.e., the text paired with an image is not necessarily a precise description of the image). The simplicity of SimVLM enables efficient training on such a scaled dataset, which helps the model to achieve state-of-the-art performance across six vision-language benchmarks. Moreover, SimVLM learns a unified multimodal representation that enables strong zero-shot cross-modality transfer without fine-tuning or with fine-tuning only on text data, including for tasks such as open-ended visual question answering, image captioning and multimodal translation.
Model and Pre-training Procedure
Unlike existing VLP methods that adopt pre-training procedures similar to masked language modeling (like in BERT), SimVLM adopts the sequence-to-sequence framework and is trained with a one prefix language model (PrefixLM) objective, which receives the leading part of a sequence (the prefix) as inputs, then predicts its continuation. For example, given the sequence “A dog is chasing after a yellow ball”, the sequence is randomly truncated to “A dog is chasing” as the prefix, and the model will predict its continuation. The concept of a prefix similarly applies to images, where an image is divided into a number of “patches”, then a subset of those patches are sequentially fed to the model as inputs—this is called an “image patch sequence”. In SimVLM, for multimodal inputs (e.g., images and their captions), the prefix is a concatenation of both the image patch sequence and prefix text sequence, received by the encoder. The decoder then predicts the continuation of the textual sequence. Compared to prior VLP models combining several pre-training losses, the PrefixLM loss is the only training objective and significantly simplifies the training process. This approach for SimVLM maximizes its flexibility and universality in accommodating different task setups.
Finally, due to its success for both language and vision tasks, like BERT and ViT, we adopt the Transformer architecture as the backbone of our model, which, unlike prior ROI-based VLP approaches, enables the model to directly take in raw images as inputs. Moreover, inspired by CoAtNet, we adopt a convolution stage consisting of the first three blocks of ResNet in order to extract contextualized patches, which we find more advantageous than the naïve linear projection in the original ViT model. The overall model architecture is illustrated below.
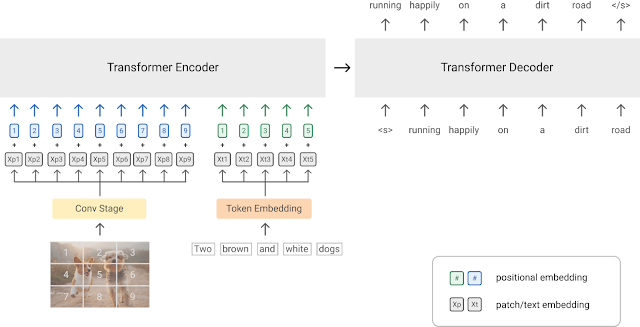 |
| Overview of the SimVLM model architecture. |
The model is pre-trained on large-scale web datasets for both image-text and text-only inputs. For joint vision and language data, we use the training set of ALIGN which contains about 1.8B noisy image-text pairs. For text-only data, we use the Colossal Clean Crawled Corpus (C4) dataset introduced by T5, totaling 800G web-crawled documents.
Benchmark Results
After pre-training, we fine-tune our model on the following multimodal tasks: VQA, NLVR2, SNLI-VE, COCO Caption, NoCaps and Multi30K En-De. For example, for VQA the model takes an image and corresponding questions about the input image, and generates the answer as output. We evaluate SimVLM models of three different sizes (base: 86M parameters, large: 307M and huge: 632M) following the same setup as in ViT. We compare our results with strong existing baselines, including LXMERT, VL-T5, UNITER, OSCAR, Villa, SOHO, UNIMO, VinVL, and find that SimVLM achieves state-of-the-art performance across all these tasks despite being much simpler.
| VQA | NLVR2 | SNLI-VE | CoCo Caption | |||||||||||
| Model | test-dev | test-std | dev | test-P | dev | test | B@4 | M | C | S | ||||
| LXMERT | 72.4 | 72.5 | 74.9 | 74.5 | – | – | – | – | – | – | ||||
| VL-T5 | – | 70.3 | 74.6 | 73.6 | – | – | – | – | 116.5 | – | ||||
| UNITER | 73.8 | 74 | 79.1 | 80 | 79.4 | 79.4 | – | – | – | – | ||||
| OSCAR | 73.6 | 73.8 | 79.1 | 80.4 | – | – | 41.7 | 30.6 | 140 | 24.5 | ||||
| Villa | 74.7 | 74.9 | 79.8 | 81.5 | 80.2 | 80 | – | – | – | – | ||||
| SOHO | 73.3 | 73.5 | 76.4 | 77.3 | 85 | 85 | – | – | – | – | ||||
| UNIMO | 75.1 | 75.3 | – | – | 81.1 | 80.6 | 39.6 | – | 127.7 | – | ||||
| VinVL | 76.6 | 76.6 | 82.7 | 84 | – | – | 41 | 31.1 | 140.9 | 25.2 | ||||
| SimVLM base | 77.9 | 78.1 | 81.7 | 81.8 | 84.2 | 84.2 | 39 | 32.9 | 134.8 | 24 | ||||
| SimVLM large | 79.3 | 79.6 | 84.1 | 84.8 | 85.7 | 85.6 | 40.3 | 33.4 | 142.6 | 24.7 | ||||
| SimVLM huge | 80 | 80.3 | 84.5 | 85.2 | 86.2 | 86.3 | 40.6 | 33.7 | 143.3 | 25.4 | ||||
| Evaluation results on a subset of 6 vision-language benchmarks in comparison with existing baseline models. Metrics used above (higher is better): BLEU-4 (B@4), METEOR (M), CIDEr (C), SPICE (S). Similarly, evaluation on NoCaps and Multi30k En-De also show state-of-the-art performance. |
Zero-Shot Generalization
Since SimVLM has been trained on large amounts of data from both visual and textual modalities, it is interesting to ask whether it is capable of performing zero-shot cross-modality transfer. We examine the model on multiple tasks for this purpose, including image captioning, multilingual captioning, open-ended VQA and visual text completion. We take the pre-trained SimVLM and directly decode it for multimodal inputs with fine-tuning only on text data or without fine-tuning entirely. Some examples are given in the figure below. It can be seen that the model is able to generate not only high-quality image captions, but also German descriptions, achieving cross-lingual and cross-modality transfer at the same time.
 |
| Examples of SimVLM zero-shot generalization. (a) Zero-shot image captioning: Given an image together with text prompts, the pre-trained model predicts the content of the image without fine-tuning. (b) zero-shot cross-modality transfer on German image captioning: The model generates captions in German even though it has never been fine-tuned on image captioning data in German. (c) Generative VQA: The model is capable of generating answers outside the candidates of the original VQA dataset. (d) Zero-shot visual text completion: The pre-trained model completes a textual description grounded on the image contents; (e) Zero-shot open-ended VQA: The model provides factual answers to the questions about images, after continued pre-training on the WIT dataset. Images are from NoCaps, which come from the Open Images dataset under the CC BY 2.0 license. |
To quantify SimVLM’s zero-shot performance, we take the pre-trained, frozen model and decode it on the COCO Caption and NoCaps benchmarks, then compare with supervised baselines. Even without supervised fine-tuning (in the middle-rows), SimVLM can reach zero-shot captioning quality close to the quality of supervised methods.
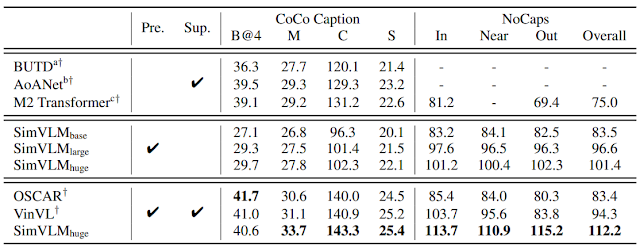 |
| Zero shot image captioning results. Here “Pre.” indicates the model is pre-trained and “Sup.” means the model is finetuned on task-specific supervision. For NoCaps, [In, Near, Out] refer to in-domain, near-domain and out-of-domain respectively. We compare results from BUTD, AoANet, M2 Transformer, OSCAR and VinVL. Metrics used above (higher is better): BLEU-4 (B@4), METEOR (M), CIDEr (C), SPICE (S). For NoCaps, CIDEr numbers are reported. |
Conclusion
We propose a simple yet effective framework for VLP. Unlike prior work using object detection models and task-specific auxiliary losses, our model is trained end-to-end with a single prefix language model objective. On various vision-language benchmarks, this approach not only obtains state-of-the-art performance, but also exhibits intriguing zero-shot behaviors in multimodal understanding tasks.
Acknowledgements
We would like to thank Jiahui Yu, Adams Yu, Zihang Dai, Yulia Tsvetkov for preparation of the SimVLM paper, Hieu Pham, Chao Jia, Andrew Dai, Bowen Zhang, Zhifeng Chen, Ruoming Pang, Douglas Eck, Claire Cui and Yonghui Wu for helpful discussions, Krishna Srinivasan, Samira Daruki, Nan Du and Aashi Jain for help with data preparation, Jonathan Shen, Colin Raffel and Sharan Narang for assistance on experimental settings, and others on the Brain team for support throughout this project.
