![]()
The International Conference on Computer Vision (ICCV 2021)
will be hosted virtually next week. We’re excited to share all the work from SAIL that will be presented, and you’ll find links to papers, videos and blogs below. Feel free to reach out to the contact authors directly to learn more about the work that’s happening at Stanford!
List of Accepted Papers
GLoRIA: A Multimodal Global-Local Representation Learning Framework for Label-efficient Medical Image Recognition
Authors: Mars Huang
Contact: mschuang@stanford.edu
Keywords: medical image, self-supervised learning, multimodal fusion
3D Shape Generation and Completion Through Point-Voxel Diffusion
Authors: Linqi Zhou, Yilun Du, Jiajun Wu
Contact: linqizhou@stanford.edu
Links: Paper | Video | Website
Keywords: diffusion, shape generation
CAPTRA: CAtegory-level Pose Tracking for Rigid and Articulated Objects from Point Clouds
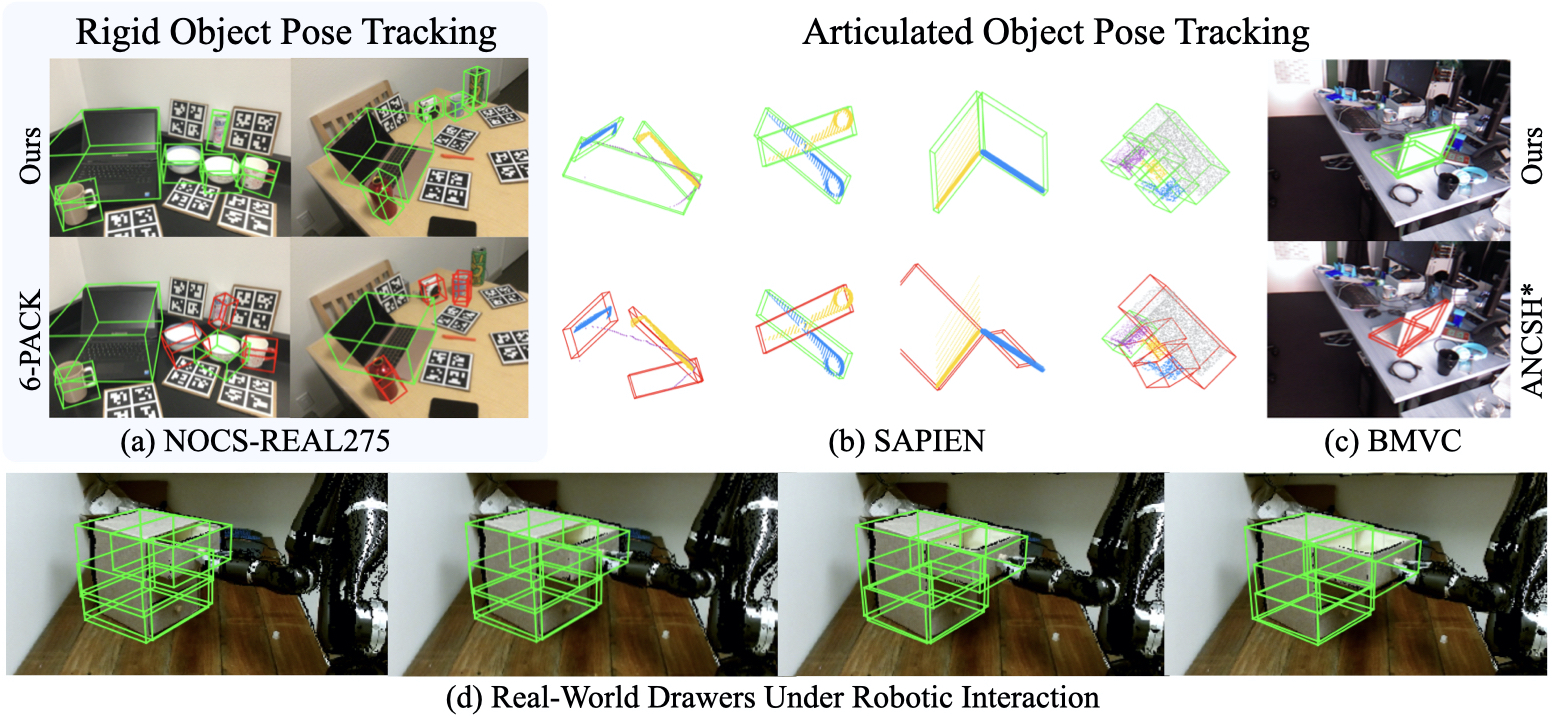
Authors: Yijia Weng*, He Wang*, Qiang Zhou, Yuzhe Qin, Yueqi Duan, Qingnan Fan, Baoquan Chen, Hao Su, Leonidas J. Guibas
Contact: yijiaw@stanford.edu
Award nominations: Oral Presentation
Links: Paper | Video | Website
Keywords: category-level object pose tracking, articulated objects
Detecting Human-Object Relationships in Videos
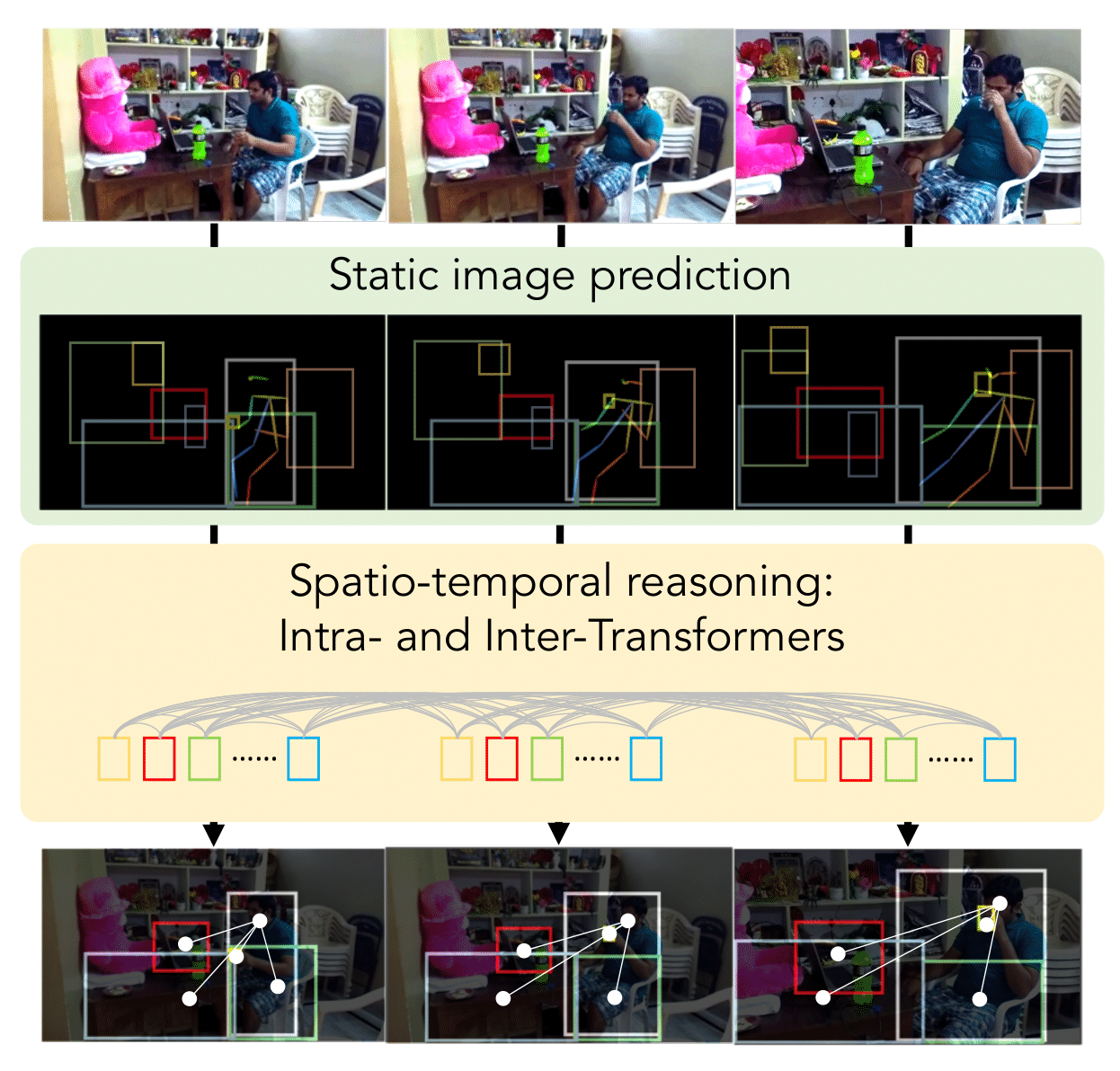
Authors: Jingwei Ji, Rishi Desai, Juan Carlos Niebles
Contact: jingweij@cs.stanford.edu
Links: Paper
Keywords: human-object relationships, video, detection, transformer, spatio-temporal reasoning
Geography-Aware Self-Supervised Learning
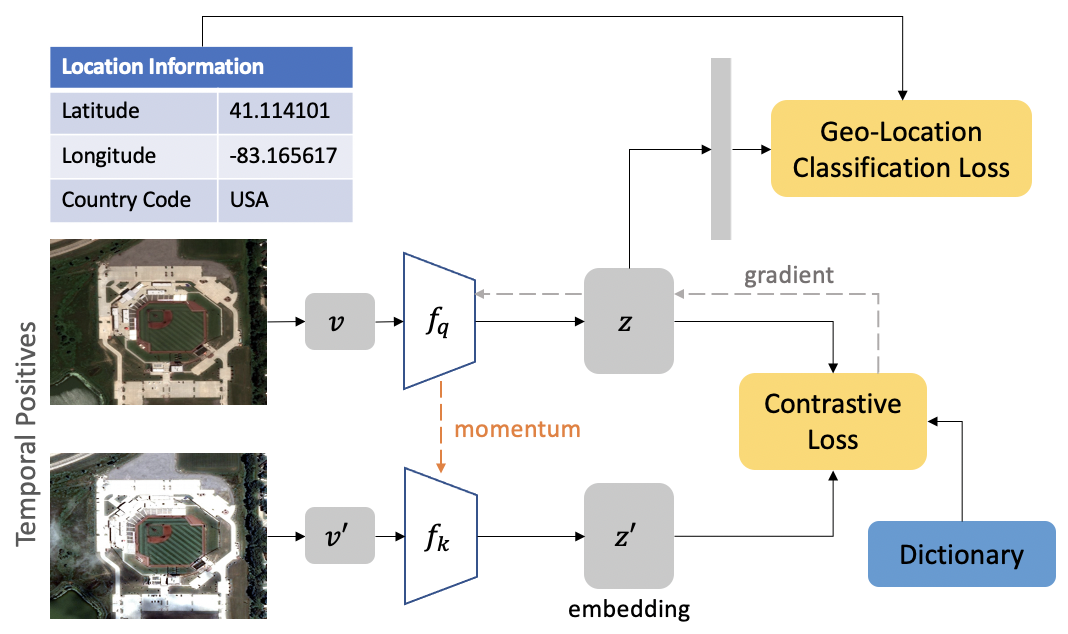
Authors: Kumar Ayush, Burak Uzkent, Chenlin Meng, Kumar Tanmay, Marshall Burke, David Lobell, Stefano Ermon
Contact: kayush@cs.stanford.edu, chenlin@stanford.edu
Links: Paper | Website
Keywords: self-supervised learning, contrastive learning, remote sensing, spatio-temporal, classification, object detection, segmentation
HuMoR: 3D Human Motion Model for Robust Pose Estimation
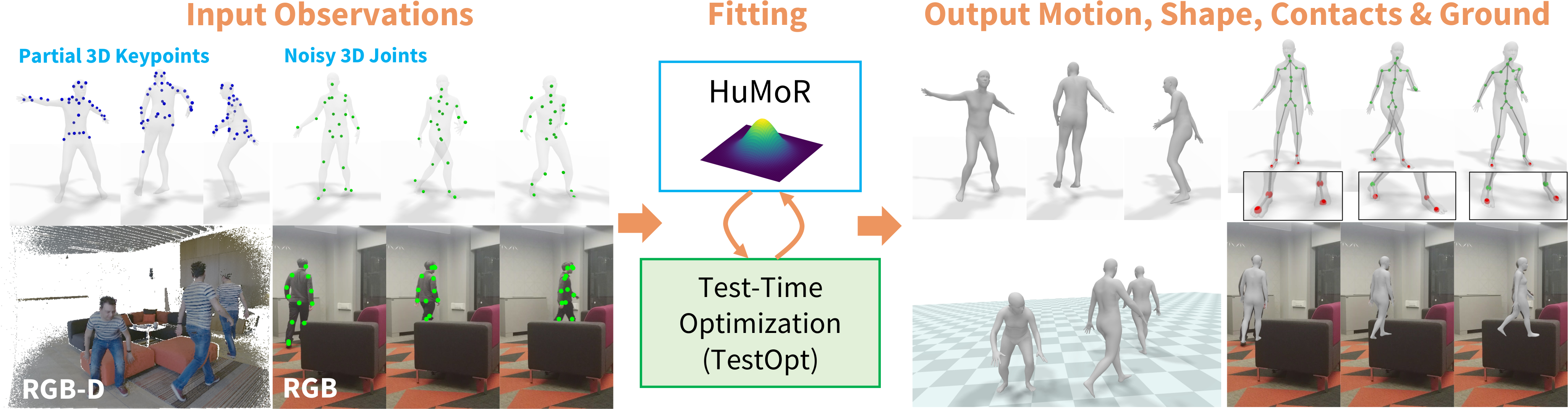
Authors: Davis Rempe, Tolga Birdal, Aaron Hertzmann, Jimei Yang, Srinath Sridhar, Leonidas Guibas
Contact: drempe@stanford.edu
Award nominations: Oral Presentation
Links: Paper | Website
Keywords: 3d human pose estimation; 3d human motion; generative modeling
Learning Privacy-preserving Optics for Human Pose Estimation
Authors: Carlos Hinojosa, Juan Carlos Niebles, Henry Arguello
Contact: carlos.hinojosa@saber.uis.edu.co
Links: Paper | Website
Keywords: computational photography; fairness, accountability, transparency, and ethics in vision; gestures and body pose
Learning Temporal Dynamics from Cycles in Narrated Video
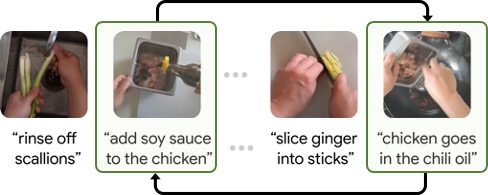
Authors: Dave Epstein, Jiajun Wu, Cordelia Schmid, Chen Sun
Contact: jiajunwu@cs.stanford.edu
Links: Paper | Website
Keywords: multi-modal learning, cycle consistency, video
Vector Neurons: A General Framework for SO(3)-Equivariant Networks
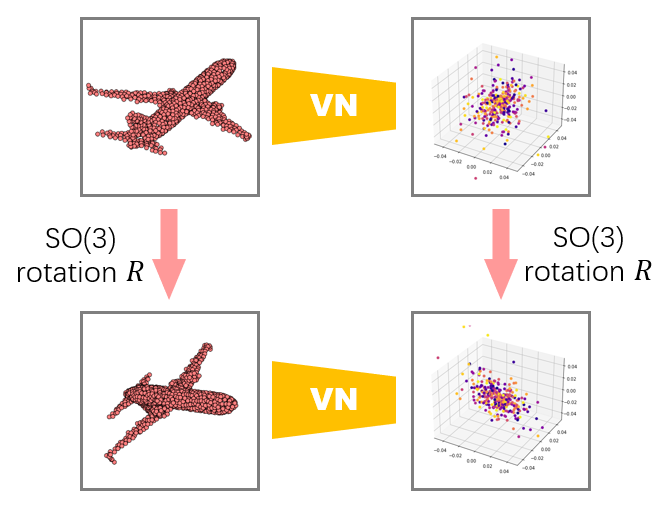
Authors: Congyue Deng, Or Litany, Yueqi Duan, Adrien Poulenard, Andrea Tagliasacchi, Leonidas Guibas
Contact: congyue@stanford.edu
Links: Paper | Video | Website
Keywords: pointcloud network, rotation equivariance, rotation invariance
Neural Radiance for 4D View Synthesis and Video Processing

Authors: Yilun Du, Yinan Zhang, Hong-Xing Yu, Joshua B. Tenenbaum, Jiajun Wu
Contact: jiajunwu@cs.stanford.edu
Links: Paper | Website
Keywords: 4d representation, neural rendering, video processing
Where2Act: From Pixels to Actions for Articulated 3D Objects
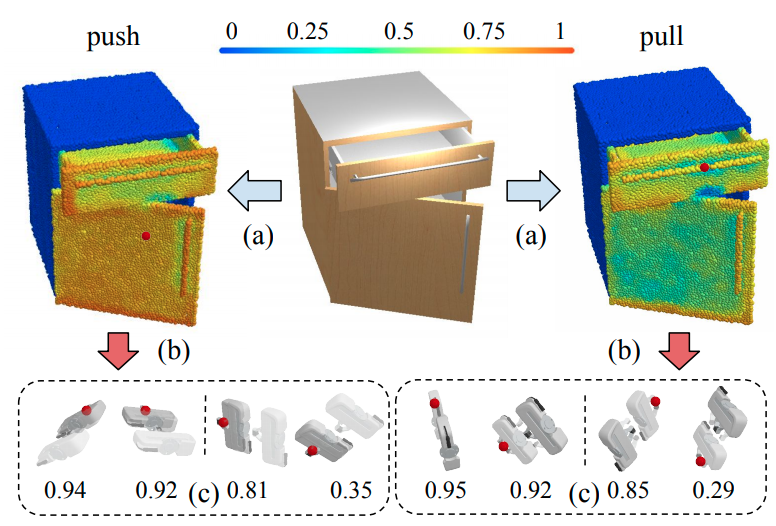
Authors: Kaichun Mo, Leonidas J. Guibas, Mustafa Mukadam, Abhinav Gupta, Shubham Tulsiani
Contact: kaichunm@stanford.edu
Links: Paper | Website
Keywords: 3d computer vision, robotic vision, affordance learning, robot learning
Low-Shot Validation: Active Importance Sampling for Estimating Classifier Performance on Rare Categories
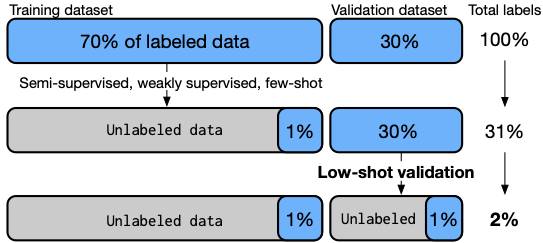
Authors: Fait Poms*, Vishnu Sarukkai*, Ravi Teja Mullapudi, Nimit S. Sohoni, William R. Mark, Deva Ramanan, Kayvon Fatahalian
Contact: sarukkai@stanford.edu
Links: Paper | Blog | Video
Keywords: model evaluation, active learning
We look forward to seeing you at ICCV 2021!