This research paper was presented at the 38th Annual AAAI Conference on Artificial Intelligence (opens in new tab) (AAAI-24), the premier forum for advancing understanding of intelligence and its implementation in machines.

We’re seeing remarkable abilities from visual language models in transforming text descriptions into images. However, creating high-quality visuals requires crafting precise prompts that capture the relationships among the different image elements, a capability that standard prompts lack. In our paper, “Learning Hierarchical Prompt with Structured Linguistic Knowledge for Language Models,” presented at AAAI-24, we introduce a novel approach using large language models (LLMs) to enhance the images created by visual language models. By creating detailed graphs of image descriptions, we leverage LLMs’ linguistic knowledge to produce richer images, expanding their utility in practical applications.

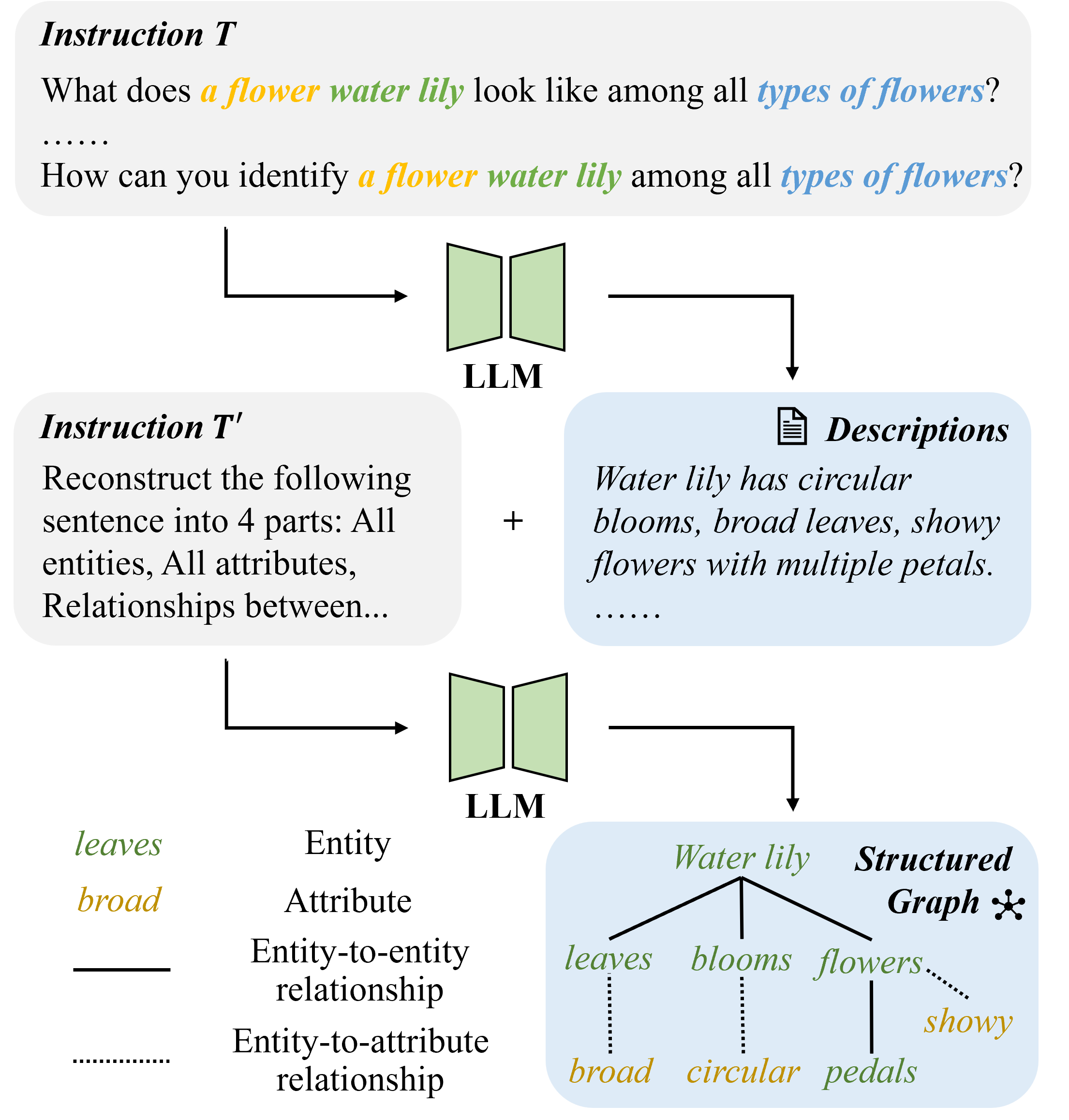
Figure 1 illustrates our method for constructing a structured graph containing key details for each category, or class. These graphs contain structured information, with entities (objects, people, and concepts), attributes (characteristics), and the relationships between them. For example, when defining “water lily,” we include entities like “leaves” or “blooms”, their attributes, “round” and “white”, and then apply LLMs’ reasoning capabilities to identify how these terms relate to each other. This is shown in Figure 2.
Microsoft Research Podcast

Collaborators: Holoportation communication technology with Spencer Fowers and Kwame Darko
communication technology with Spencer Fowers and Kwame Darko
Spencer Fowers and Kwame Darko break down how the technology behind Holoportation and the telecommunication device being built around it brings patients and doctors together when being in the same room isn’t an easy option and discuss the potential impact of the work.
How to model structural knowledge
After identifying and structuring the relationships within the generated prompt descriptions, we implement Hierarchical Prompt Tuning (HTP), a new prompt-tuning framework that organizes content hierarchically. This approach allows the visual language model to discern the different levels of information in a prompt, ranging from specific details to broader categories and overarching themes across multiple knowledge domains, as shown in Figure 3. This facilitates the model’s understanding of the connections among these elements, improving its ability to process complex queries across various topics.
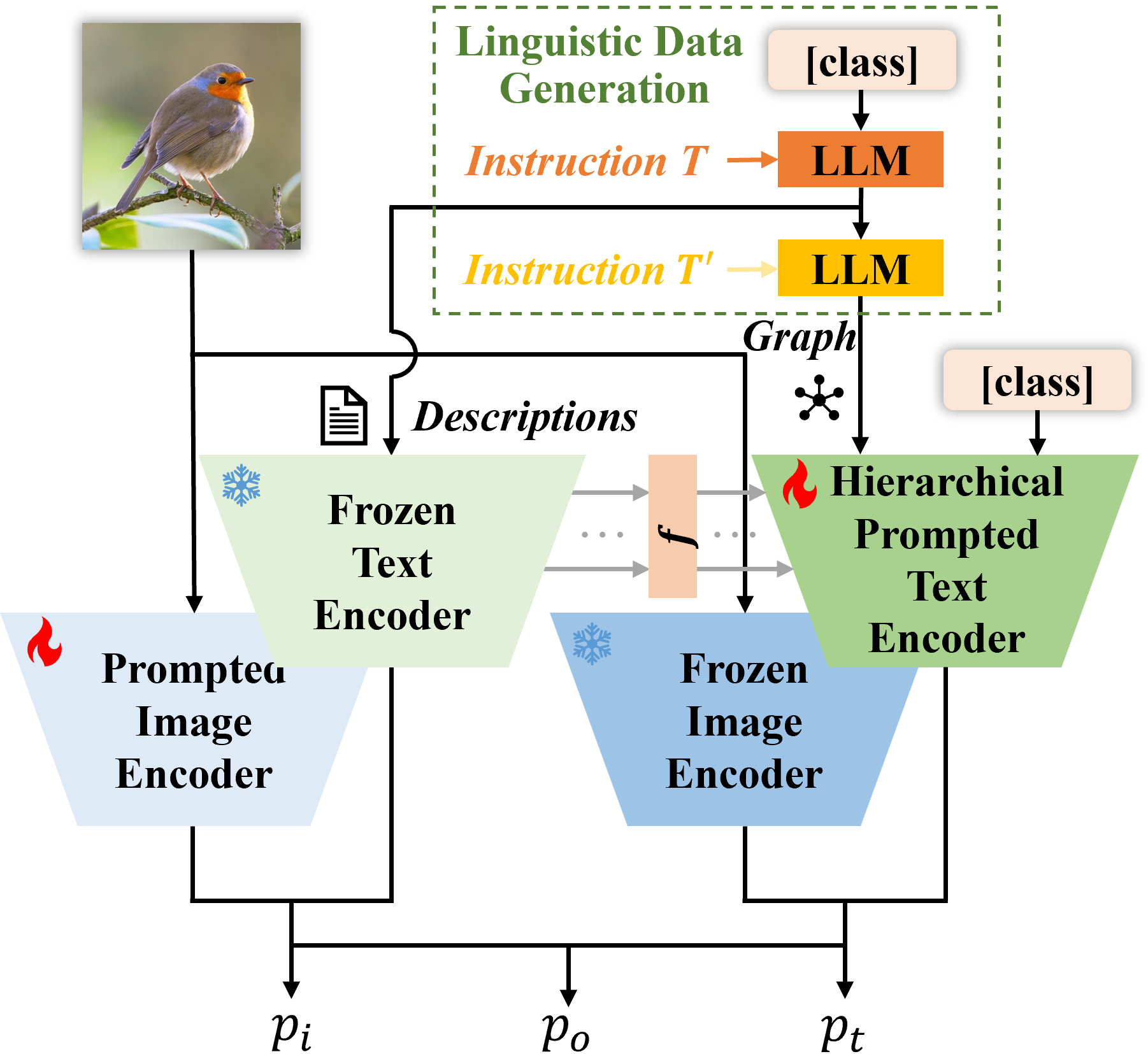
Central to this method is a state-of-the-art relationship-guided attention module, designed to help the model identify and analyze the complex interconnections among elements within a graph. This module also understands the interactions between different entities and attributes through a cross-level self-attention mechanism. Self-attention enables the model to assess and prioritize various parts of the input data—here, the graph—according to their relevance. “Cross-level” self-attention extends this capability across various semantic layers within the graph, allowing the model to examine relationships at multiple levels of abstraction. This feature helps the model to discern the interrelations of prompts (or input commands/questions) across these various levels, helping it gain a deeper understanding of the categories or concepts.
Our findings offer valuable insights into a more effective approach to navigating and understanding complex linguistic data, improving the model’s knowledge discovery and decision-making processes. Building on these advances, we refined the traditional approach to text encoding by introducing a hierarchical, prompted text encoder, shown in Figure 4. Our aim is to improve how textual information is aligned or correlated with visual data, a necessity for vision-language models that must interpret both text and visual inputs.

Looking ahead
By incorporating structured knowledge into our model training frameworks, our research lays the groundwork for more sophisticated applications. One example is enhanced image captioning, where visual language models gain the ability to describe the contents of photographs, illustrations, or any visual media with greater accuracy and depth. This improvement could significantly benefit various applications, such as assisting visually impaired users. Additionally, we envision advances in text-to-image generation, enabling visual language models to produce visual representations that are more precise, detailed, and contextually relevant based on textual descriptions.
Looking forward, we hope our research ignites a broader interest in exploring the role of structured knowledge in improving prompt tuning for both visual and language comprehension. This exploration is expected to extend the use of these models beyond basic classification tasks—where models categorize or label data—towards enabling more nuanced and accurate interactions between people and AI systems. By doing so, we pave the way for AI systems to more effectively interpret the complexities of human language.
Acknowledgements
Thank you to Yubin Wang for his contributions in implementing the algorithm and executing the experiments.
The post Structured knowledge from LLMs improves prompt learning for visual language models appeared first on Microsoft Research.