Benchmark challenges have been a driving force in the advancement of machine learning (ML). In particular, difficult benchmark environments for reinforcement learning (RL) have been crucial for the rapid progress of the field by challenging researchers to overcome increasingly difficult tasks. The Arcade Learning Environment, Mujoco, and others have been used to push the envelope in RL algorithms, representation learning, exploration, and more.
In “Autonomous Navigation of Stratospheric Balloons Using Reinforcement Learning”, published in Nature, we demonstrated how deep RL can be used to create a high-performing flight agent that can control stratospheric balloons in the real world. This research confirmed that deep RL can be successfully applied outside of simulated environments, and contributed practical knowledge for integrating RL algorithms with complex dynamical systems. Today we are excited to announce the open-source release of the Balloon Learning Environment (BLE), a new benchmark emulating the real-world problem of controlling stratospheric balloons. The BLE is a high-fidelity simulator, which we hope will provide researchers with a valuable resource for deep RL research.
Station-Keeping Stratospheric Balloons
Stratospheric balloons are filled with a buoyant gas that allows them to float for weeks or months at a time in the stratosphere, about twice as high as a passenger plane’s cruising altitude. Though there are many potential variations of stratospheric balloons, the kind emulated in the BLE are equipped with solar panels and batteries, which allow them to adjust their altitude by controlling the weight of air in their ballast using an electric pump. However, they have no means to propel themselves laterally, which means that they are subject to wind patterns in the air around them.
 |
| By changing its altitude, a stratospheric balloon can surf winds moving in different directions. |
The goal of an agent in the BLE is to station-keep — i.e., to control a balloon to stay within 50km of a fixed ground station — by changing its altitude to catch winds that it finds favorable. We measure how successful an agent is at station-keeping by measuring the fraction of time the balloon is within the specified radius, denoted TWR50 (i.e., the time within a radius of 50km).
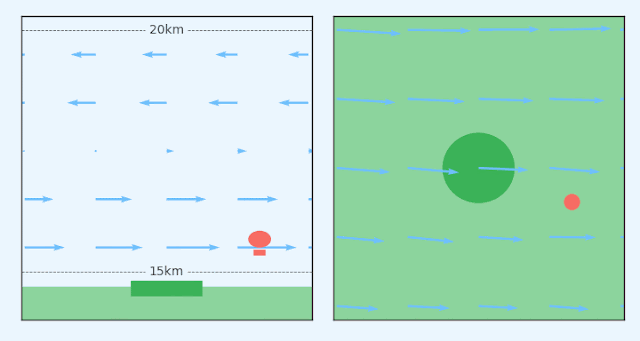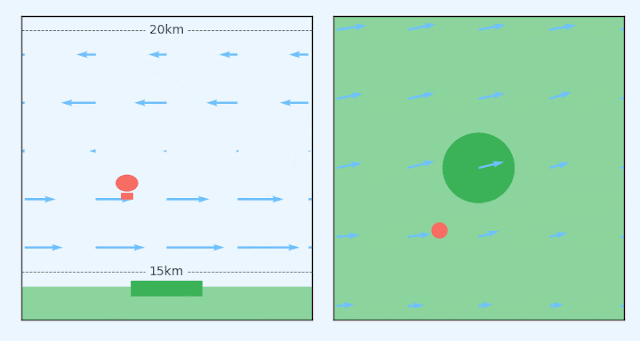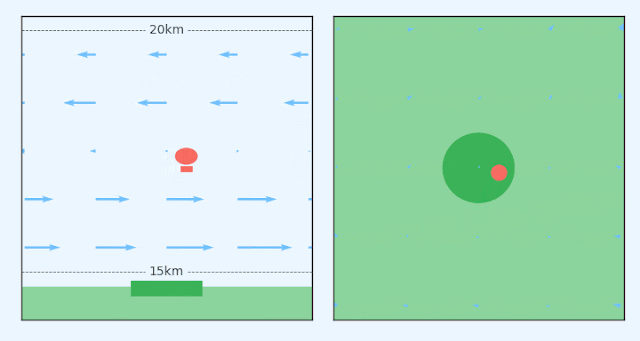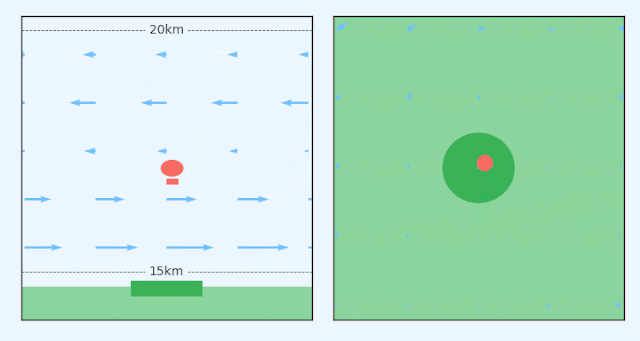 |
| A station-seeking balloon must navigate a changing wind field to stay above a ground station. Left: Side elevation of a station-keeping balloon. Right: Birds-eye-view of the same balloon. |
The Challenges of Station-Keeping
To create a realistic simulator (without including copious amounts of historical wind data), the BLE uses a variational autoencoder (VAE) trained on historical data to generate wind forecasts that match the characteristics of real winds. A wind noise model is then used to make the windfields more realistic to match what a balloon would encounter in real-world conditions.
Navigating a stratospheric balloon through a wind field can be quite challenging. The winds at any given altitude rarely remain ideal for long, and a good balloon controller will need to move up and down through its wind column to discover more suitable winds. In RL parlance, the problem of station-keeping is partially observable because the agent only has access to forecasted wind data to make those decisions. An agent has access to wind forecasts at every altitude and the true wind at its current altitude. The BLE returns an observation which includes a notion of wind uncertainty.
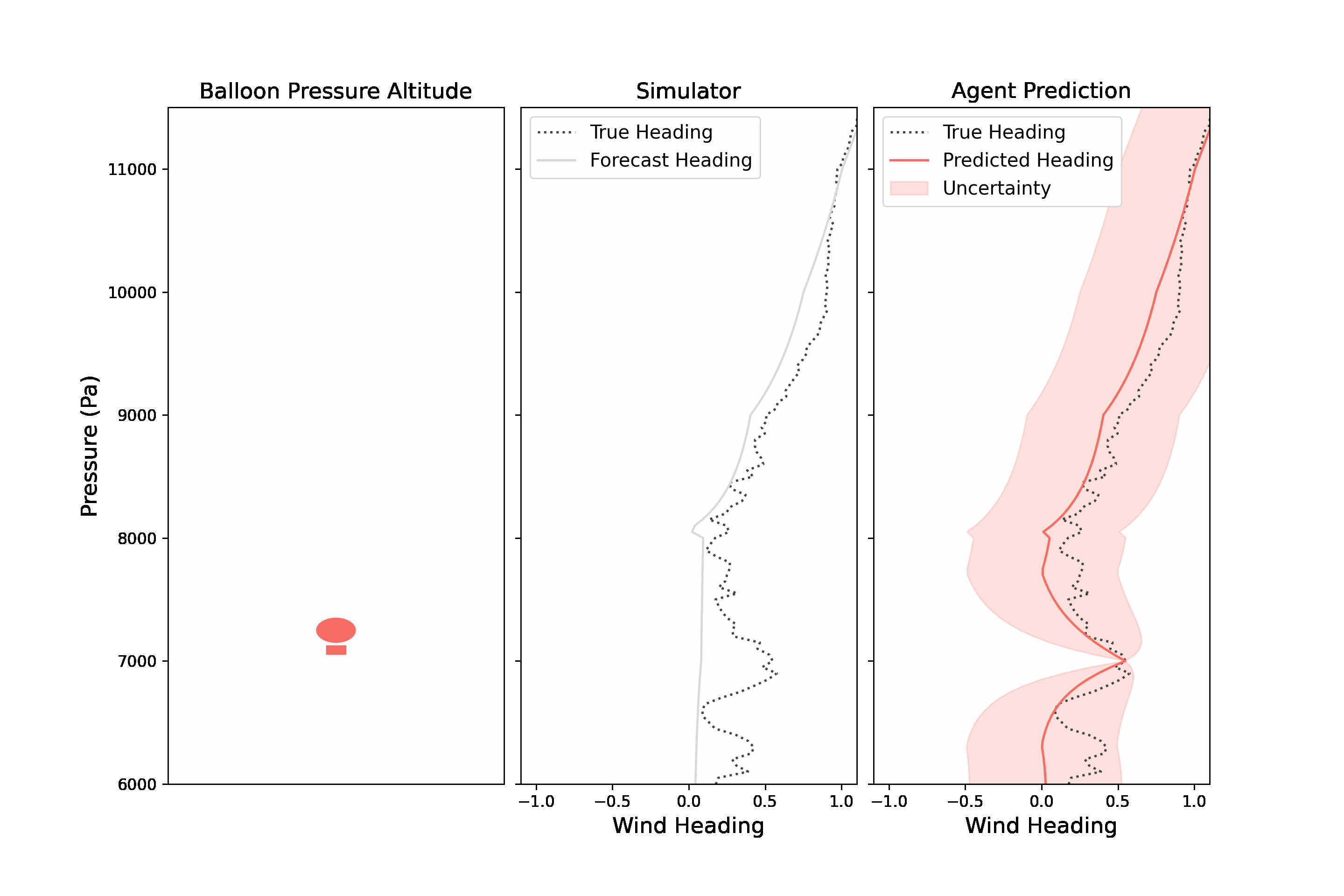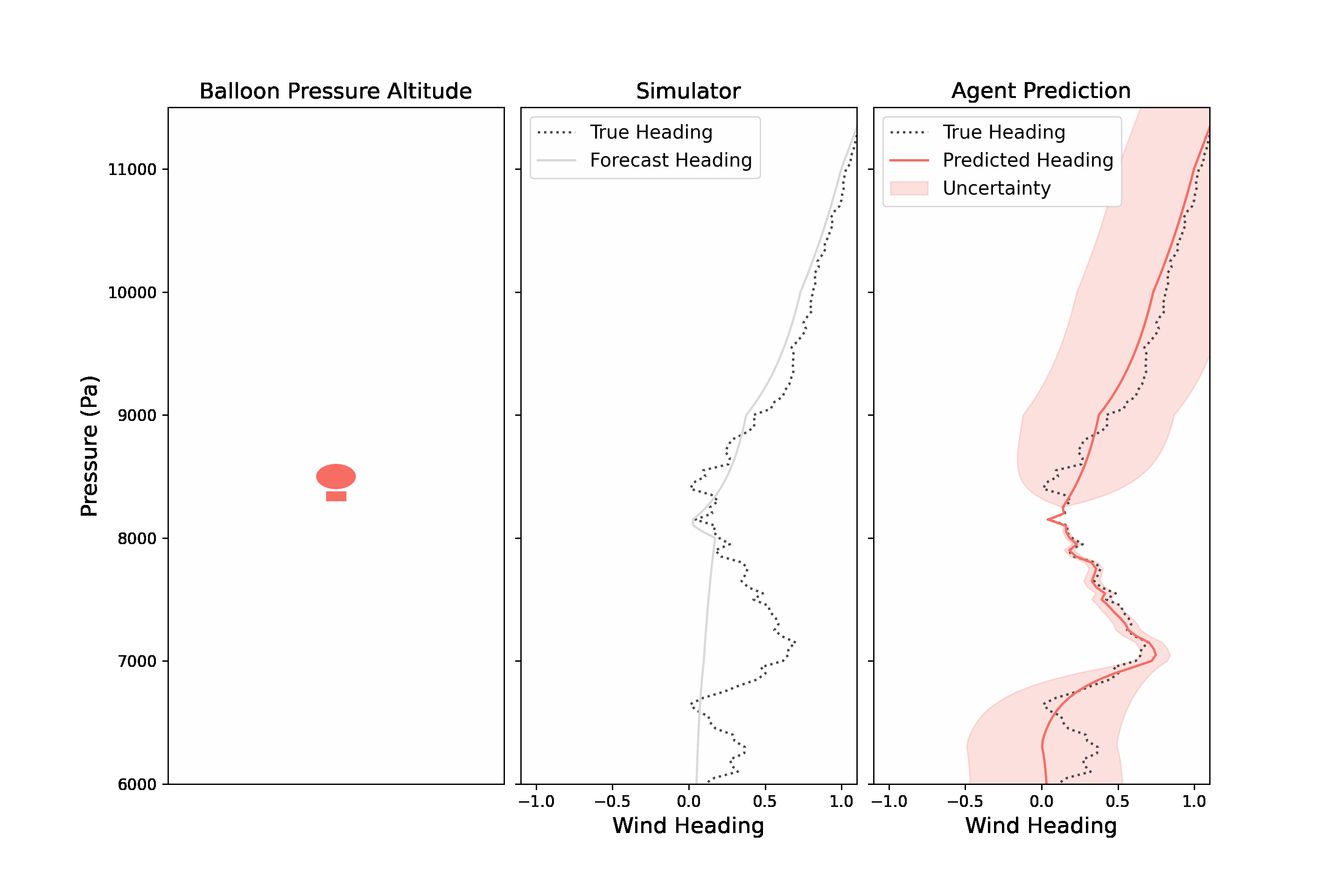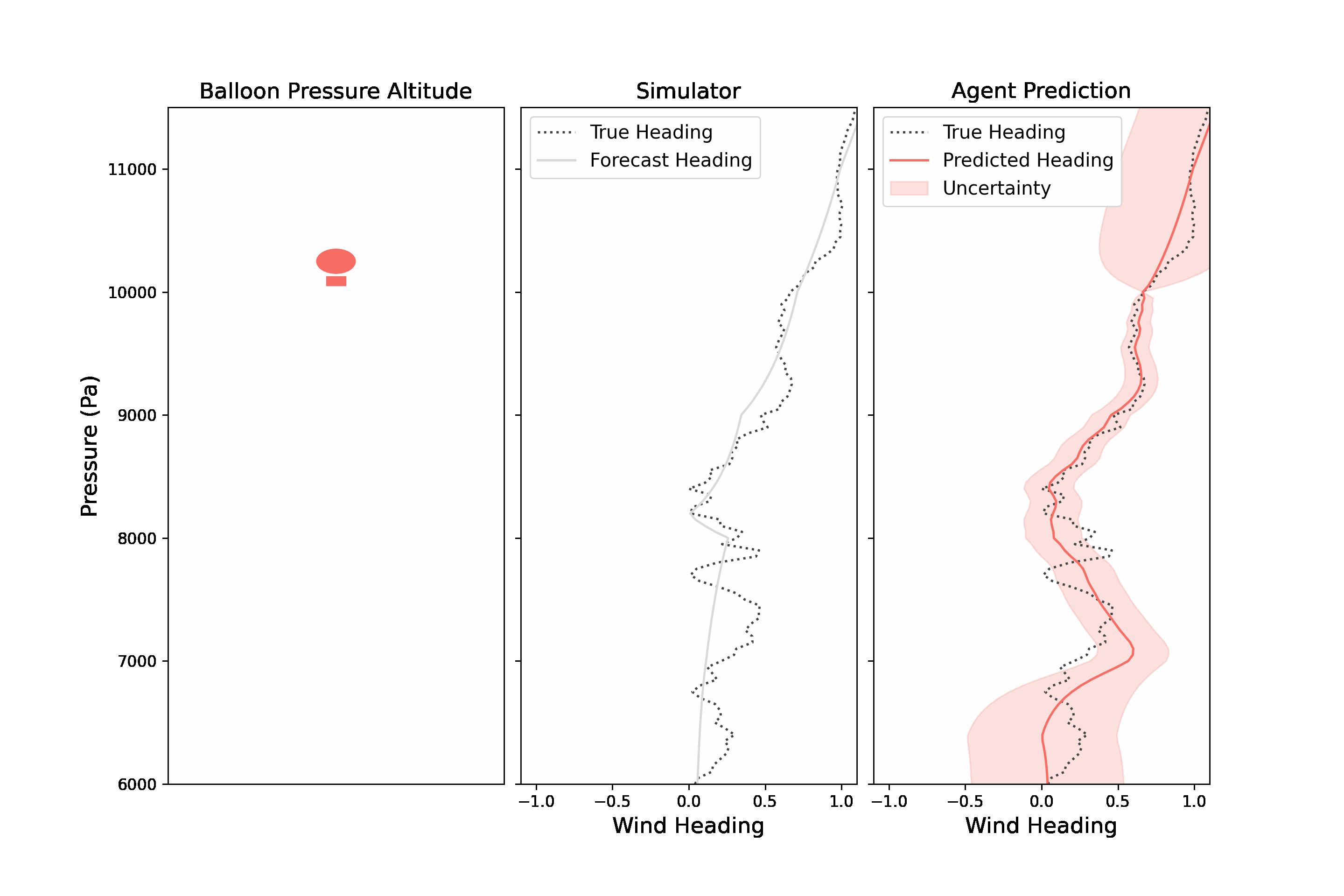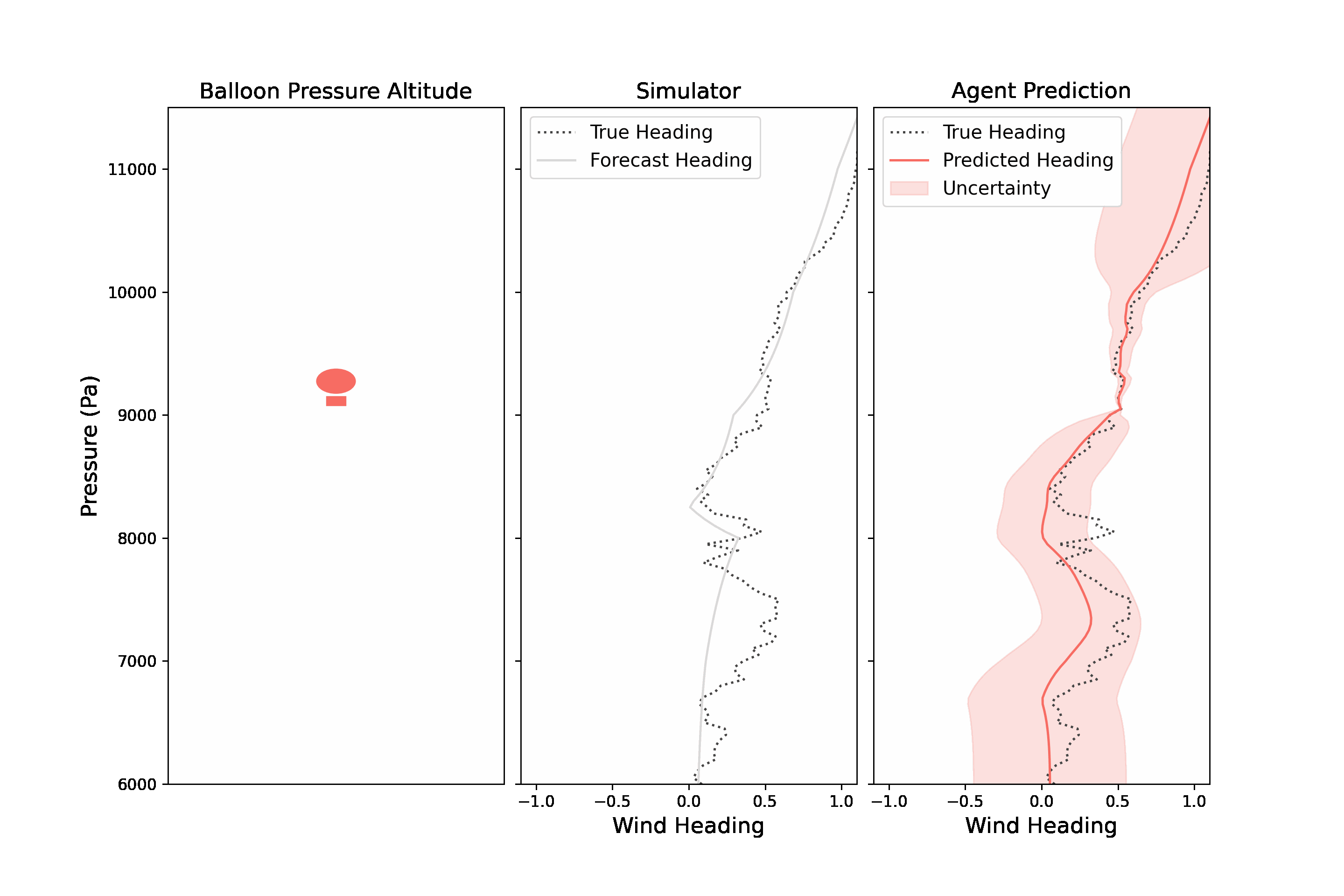 |
| A stratospheric balloon must explore winds at different altitudes in order to find favorable winds. The observation returned by the BLE includes wind predictions and a measure of uncertainty, made by mixing a wind forecast and winds measured at the balloon’s altitude. |
In some situations, there may not be suitable winds anywhere in the balloon’s wind column. In this case, an expert agent is still able to fly towards the station by taking a more circuitous route through the wind field (a common example is when the balloon moves in a zig-zag fashion, akin to tacking on a sailboat). Below we demonstrate that even just remaining in range of the station usually requires significant acrobatics.
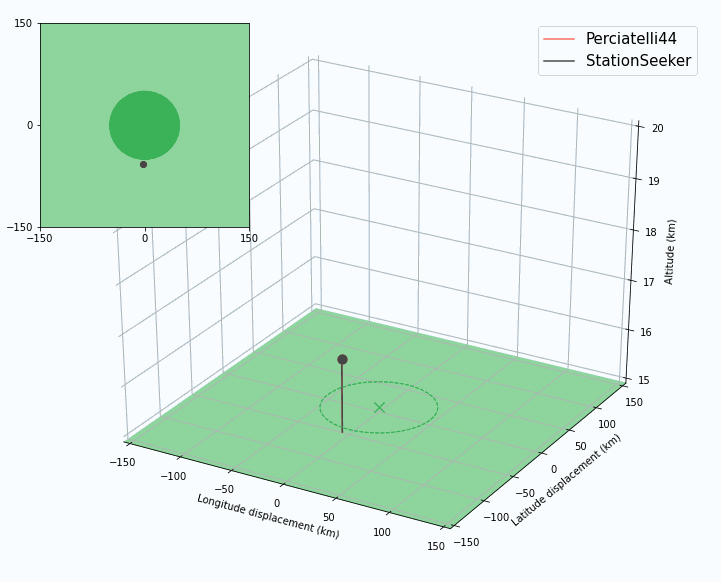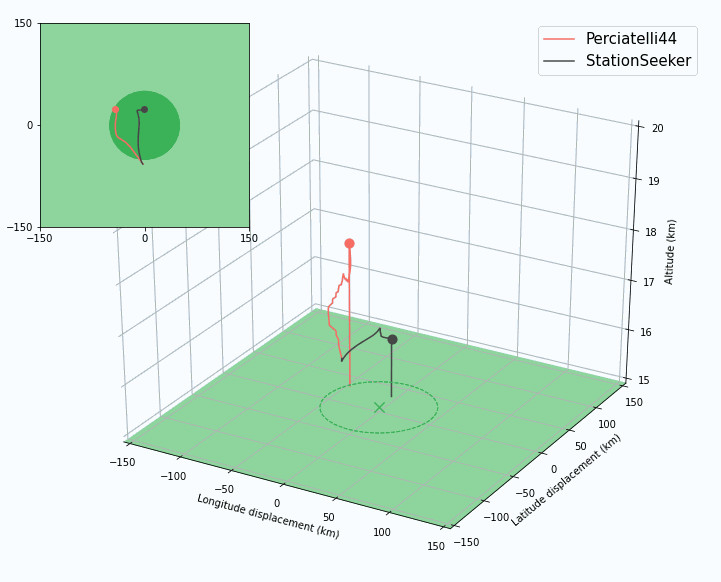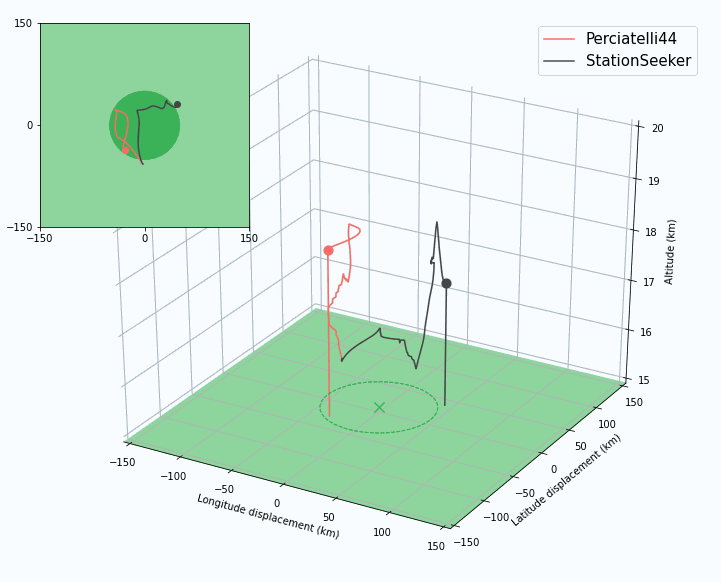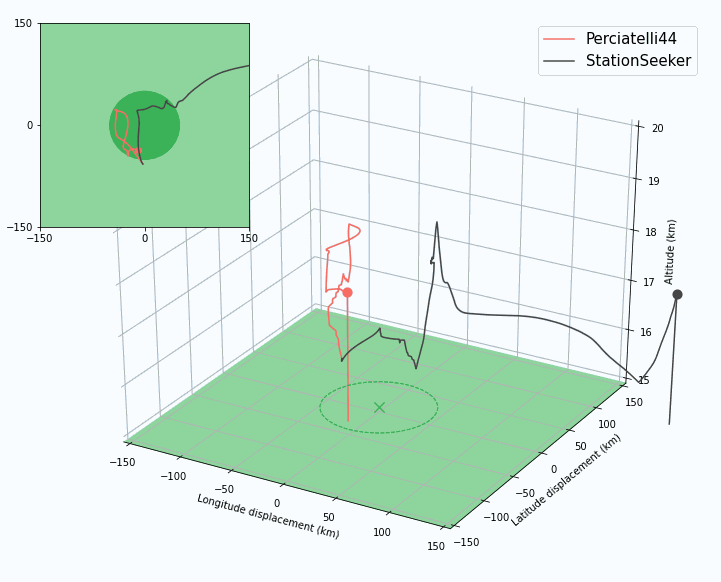 |
| An agent must handle long planning horizons to succeed in station-keeping. In this case, StationSeeker (an expert-designed controller) heads directly to the center of the station-keeping area and is pushed out, while Perciatelli44 (an RL agent) is able to plan ahead and stay in range longer by hugging the edge of the area. |
Night-time adds a fresh element of difficulty to station-keeping in the BLE, which reflects the reality of night-time changes in physical conditions and power availability. While during the day the air pump is powered by solar panels, at night the balloon relies on its on-board batteries for energy. Using too much power early in the night typically results in limited maneuverability in the hours preceding dawn. This is where RL agents can discover quite creative solutions — such as reducing altitude in the afternoon in order to store potential energy.
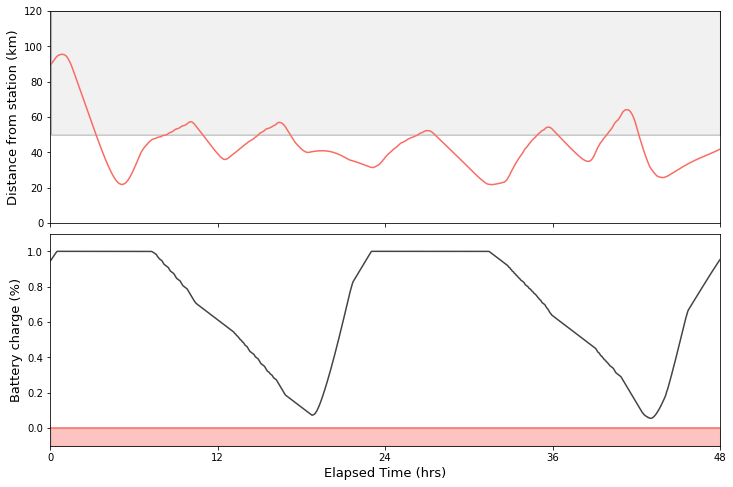 |
| An agent needs to balance the station-keeping objective with a finite energy allowance at night. |
Despite all these challenges, our research demonstrates that agents trained with reinforcement learning can learn to perform better than expert-designed controllers at station-keeping. Along with the BLE, we are releasing the main agents from our research: Perciatelli44 (an RL agent) and StationSeeker (an expert-designed controller). The BLE can be used with any reinforcement learning library, and to showcase this we include Dopamine’s DQN and QR-DQN agents, as well as Acme’s QR-DQN agent (supporting both standalone and distributed training with Launchpad).
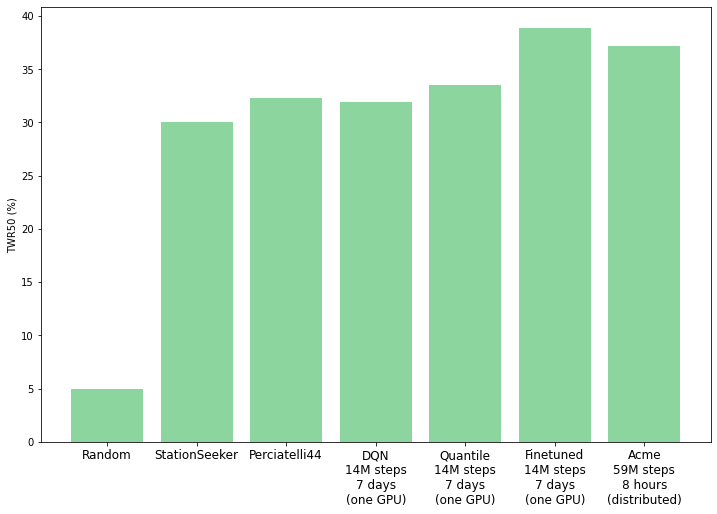 |
| Evaluation performance by the included benchmark agents on the BLE. “Finetuned” is a fine-tuned Perciatelli44 agent, and Acme is a QR-DQN agent trained with the Acme library. |
The BLE source code contains information on how to get started with the BLE, including training and evaluating agents, documentation on the various components of the simulator, and example code. It also includes the historical windfield data (as a TensorFlow DataSet) used to train the VAE to allow researchers to experiment with their own models for windfield generation. We are excited to see the progress that the community will make on this benchmark.
Acknowledgements
We would like to thank the Balloon Learning Environment team: Sal Candido, Marc G. Bellemare, Vincent Dumoulin, Ross Goroshin, and Sam Ponda. We’d also like to thank Tom Small for his excellent animation in this blog post and graphic design help, along with our colleagues, Bradley Rhodes, Daniel Eisenberg, Piotr Staczyk, Anton Raichuk, Nikola Momchev, Geoff Hinton, Hugo Larochelle, and the rest of the Google Brain team in Montreal.
