The Triton open-source programming language and compiler offers a high-level, python-based approach to create efficient GPU code. In this blog, we highlight the underlying details of how a triton program is compiled and the intermediate representations. For an introduction to Triton, we refer readers to this blog.
Triton Language and Compilation
The Triton programming language supports different types of modern GPUs and follows a blocked programming approach. As an example, we will follow the Triton vector add tutorial with minor modifications. The vector addition kernel and helper function is defined as:
import torch
import triton
import triton.language as tl
@triton.jit
def add_kernel(x_ptr, # *Pointer* to first input vector.
y_ptr, # *Pointer* to second input vector.
output_ptr, # *Pointer* to output vector.
n_elements,
BLOCK_SIZE: tl.constexpr,
):
pid = tl.program_id(axis=0)
block_start = pid * BLOCK_SIZE
offsets = block_start + tl.arange(0, BLOCK_SIZE)
mask = offsets < n_elements
x = tl.load(x_ptr + offsets, mask=mask)
y = tl.load(y_ptr + offsets, mask=mask)
output = x + y
tl.store(output_ptr + offsets, output, mask=mask)
def add(x: torch.Tensor, y: torch.Tensor):
output = torch.empty_like(x)
assert x.is_cuda and y.is_cuda and output.is_cuda
n_elements = output.numel()
grid = lambda meta: (triton.cdiv(n_elements, meta['BLOCK_SIZE']), )
triton_kernel=add_kernel[grid](x, y, output, n_elements, BLOCK_SIZE=1024)
torch.cuda.synchronize()
# Save compilation stages - some of the stages identified here are specific to NVIDIA devices:
with open('triton_IR.txt', 'w') as f:
print(triton_kernel.asm['ttir'], file=f)
with open('triton_TTGIR.txt', 'w') as f:
print(triton_kernel.asm['ttgir'], file=f)
with open('triton_LLVMIR.txt', 'w') as f:
print(triton_kernel.asm['llir'], file=f)
with open('triton_PTX.ptx', 'w') as f:
print(triton_kernel.asm['ptx'], file=f)
with open('triton_cubin.txt', 'w') as f:
print(triton_kernel.asm['cubin'], file=f)
return output
torch.manual_seed(0)
size = 98432
x = torch.rand(size, device='cuda')
y = torch.rand(size, device='cuda')
output_torch = x + y
output_triton = add(x, y)
print(output_torch)
print(output_triton)
print(f'The maximum difference between torch and triton is '
f'{torch.max(torch.abs(output_torch - output_triton))}')
The Triton vector add kernel includes the @triton.jit decorator. The Triton compiler will compile functions marked by @triton.jit, which lowers the function through multiple compilation stages. The helper function add allocates the output tensor, computes the appropriate GPU grid size, and additionally saves the intermediate compilation stages.
Focusing on the compilation process, the Triton kernel is lowered to device specific assembly through a series of stages outlined in the following figure.
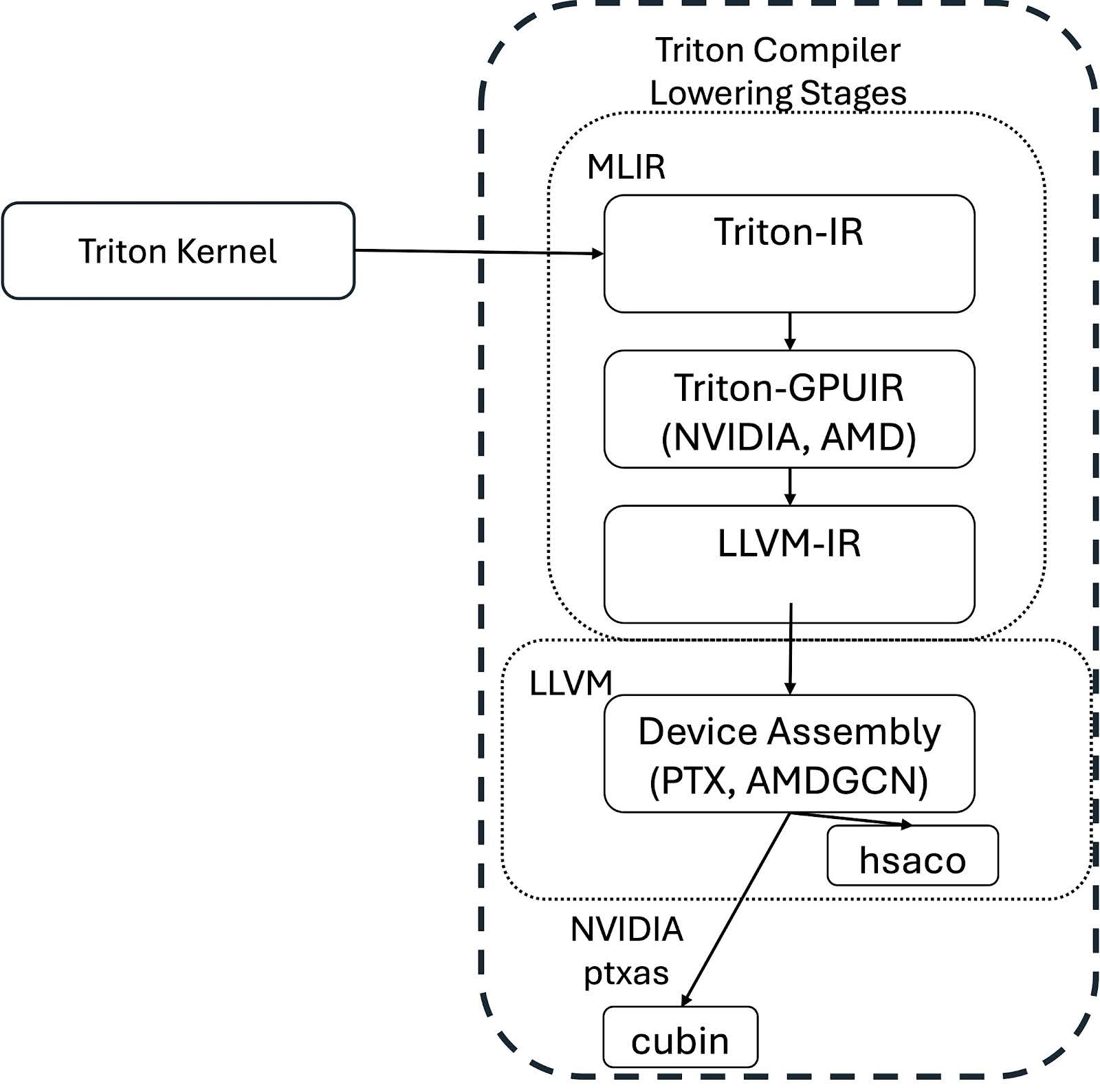
The kernel is compiled by first walking the abstract syntax tree (AST) of the decorated python function to create the Triton Intermediate Representation (Triton-IR). The Triton-IR is an unoptimized, machine independent intermediate representation. It introduces tile-level programming requirements and is based on the open-source LLVM compiler project. Next the Triton compiler optimizes and converts the Triton-IR into the stages Triton-GPU IR (Triton-TTGIR) and then LLVM-IR. Both the Triton-IR and Triton-GPUIR representations are written as MLIR dialects, where MLIR is a subproject of LLVM that aims to improve compilation for heterogeneous hardware.
For the Triton vector add tutorial kernel, the example Triton IR snippet is:
module {
tt.func public @add_kernel(%arg0: !tt.ptr<f32> {tt.divisibility = 16 : i32} loc("/u/saraks/triton_blog/01-vector-add.py":28:0), %arg1: !tt.ptr<f32> {tt.divisibility = 16 : i32} loc("/u/saraks/triton_blog/01-vector-add.py":28:0), %arg2: !tt.ptr<f32> {tt.divisibility = 16 : i32} loc("/u/saraks/triton_blog/01-vector-add.py":28:0), %arg3: i32 {tt.divisibility = 16 : i32} loc("/u/saraks/triton_blog/01-vector-add.py":28:0)) attributes {noinline = false} {
%c1024_i32 = arith.constant 1024 : i32 loc(#loc1)
%0 = tt.get_program_id x : i32 loc(#loc2)
%1 = arith.muli %0, %c1024_i32 : i32 loc(#loc3)
%2 = tt.make_range {end = 1024 : i32, start = 0 : i32} : tensor<1024xi32> loc(#loc4)
%3 = tt.splat %1 : i32 -> tensor<1024xi32> loc(#loc5)
%4 = arith.addi %3, %2 : tensor<1024xi32> loc(#loc5)
%5 = tt.splat %arg3 : i32 -> tensor<1024xi32> loc(#loc6)
%6 = arith.cmpi slt, %4, %5 : tensor<1024xi32> loc(#loc6)
%7 = tt.splat %arg0 : !tt.ptr<f32> -> tensor<1024x!tt.ptr<f32>> loc(#loc7)
%8 = tt.addptr %7, %4 : tensor<1024x!tt.ptr<f32>>, tensor<1024xi32> loc(#loc7)
%9 = tt.load %8, %6 : tensor<1024x!tt.ptr<f32>> loc(#loc8)
%10 = tt.splat %arg1 : !tt.ptr<f32> -> tensor<1024x!tt.ptr<f32>> loc(#loc9)
%11 = tt.addptr %10, %4 : tensor<1024x!tt.ptr<f32>>, tensor<1024xi32> loc(#loc9)
%12 = tt.load %11, %6 : tensor<1024x!tt.ptr<f32>> loc(#loc10)
%13 = arith.addf %9, %12 : tensor<1024xf32> loc(#loc11)
%14 = tt.splat %arg2 : !tt.ptr<f32> -> tensor<1024x!tt.ptr<f32>> loc(#loc12)
%15 = tt.addptr %14, %4 : tensor<1024x!tt.ptr<f32>>, tensor<1024xi32> loc(#loc12)
tt.store %15, %13, %6 : tensor<1024x!tt.ptr<f32>> loc(#loc13)
tt.return loc(#loc14)
} loc(#loc)
} loc(#loc)
Notice that the main functions in the Triton kernel are now represented as:
| Triton kernel | Triton IR |
| x = tl.load(x_ptr + offsets, mask=mask) | %9 = tt.load %8, %6 : tensor<1024x!tt.ptr<f32>> loc(#loc8) |
| y = tl.load(y_ptr + offsets, mask=mask) | %12 = tt.load %11, %6 : tensor<1024x!tt.ptr<f32>> loc(#loc10) |
| output = x + y | %13 = arith.addf %9, %12 : tensor<1024xf32> loc(#loc11) |
| tl.store(output_ptr + offsets, output, mask=mask) | tt.store %15, %13, %6 : tensor<1024x!tt.ptr<f32>> loc(#loc13) |
At the Triton IR stage, the %arg0: !tt.ptr<f32> and the following tensor references show that the intermediate representation is already specialized by the data type.
We ran this example on a Tesla V100-SXM2-32GB GPU with CUDA Version 12.2, Python version 3.11.9, and PyTorch 2.4.1 with the default version of Triton that is installed with PyTorch. On this device, the simple vector addition has the following Triton GPU IR snippet with lines omitted for clarity:
#blocked = #triton_gpu.blocked<{sizePerThread = [4], threadsPerWarp = [32], warpsPerCTA = [4], order = [0]}>
module attributes {"triton_gpu.num-ctas" = 1 : i32, "triton_gpu.num-warps" = 4 : i32, triton_gpu.target = "cuda:70", "triton_gpu.threads-per-warp" = 32 : i32} {
tt.func public @add_kernel(%arg0: !tt.ptr<f32> {tt.divisibility = 16 : i32}
⋮
%9 = tt.load %8, %6 : tensor<1024x!tt.ptr<f32>, #blocked> loc(#loc8)
⋮
%12 = tt.load %11, %6 : tensor<1024x!tt.ptr<f32>, #blocked> loc(#loc10)
%13 = arith.addf %9, %12 : tensor<1024xf32, #blocked> loc(#loc11)
⋮
tt.store %15, %13, %6 : tensor<1024x!tt.ptr<f32>, #blocked> loc(#loc13)
⋮
} loc(#loc)
} loc(#loc)
At this stage, some of the hardware specific information is included. For example, the compute capability is included along with details on how the tensors are distributed to cores and warps or for AMD GPUs on wavefronts. In this example, the tensors are represented as a #blocked layout. In this encoding, each warp owns a contiguous portion of the tensor. Currently, other possible memory optimizations include layouts such as slice (restructures and distributes a tensor along a dimension), dot_op(optimized layout for block matrix product), shared(indicates GPU shared memory), nvidia_mma (produced by NVIDIA tensor cores), amd_mfma (produced by AMD MFMA matrix core), and amd_wmma (produced by AMD WMMA matrix core). As announced at the recent Triton conference, this layout representation will transition to a new linear layout to unify layouts within and across backends. The stage from Triton-GPUIR to LLVM-IR converts the Triton-GPUIR to LLVM’s representation. At this time, Triton has third-party backend support for NVIDIA and AMD devices, but other device support is under active development by the open-source community.
A small subset of the LLVM-IR vector add arguments shown below for illustration:
%19 = extractvalue { i32, i32, i32, i32 } %18, 0, !dbg !16
%39 = extractvalue { i32, i32, i32, i32 } %38, 0, !dbg !18
%23 = bitcast i32 %19 to float, !dbg !16
%43 = bitcast i32 %39 to float, !dbg !18
%56 = fadd float %23, %43, !dbg !19
After some pointer arithmetic and an inline assembly call to retrieve the data from global memory, the vector elements are extracted and cast to the correct type. Finally they are added together and later written to global memory through an inline assembly expression.
The final stages of the Triton compilation process lower the LLVM-IR to a device specific binary. For the example vector add, on an NVIDIA GPU, the next intermediate is PTX (Parallel Thread Execution). The low-level PTX syntax specifies the execution at the thread level of NVIDIA devices, starting with the CUDA 1.0 release. For an in-depth guide on PTX, see NVIDIA’s documentation. In the vector add, the kernel parameters are passed from the host to the kernel, addresses are assigned and mov instructions facilitate the thread-level data access, ultimately representing the element addition calls with add.f32 such as the example below:
add.f32 %f17, %f1, %f9// add type float32, output register, input register for x, input register for y
The Triton compiler orchestrates the final stage with different hardware backends managing how the assembly code is compiled into binary. The Triton kernel is now ready for use.
Summary
Triton provides a high-level abstraction to program and compile kernels for different types of hardware. In this post, we highlight the different stages of the Triton code representations and Triton compiler. For details on including custom Triton kernels or accelerating different workloads with Triton kernels, check out the PyTorch Triton tutorial, the blog posts on Triton GPTQ kernels, Llama3 FP8 Inference with Triton, and CUDA-Free Inference for LLMs, or the PyTorch 2.2 Section on Triton code generation.