Posted by Reza Rokni, Snr Staff Developer Advocate
In part I of this blog series we discussed best practices and patterns for efficiently deploying a machine learning model for inference with Google Cloud Dataflow. Amongst other techniques, it showed efficient batching of the inputs and the use of shared.py to make efficient use of a model.
In this post, we walk through the use of the RunInference API from tfx-bsl, a utility transform from TensorFlow Extended (TFX), which abstracts us away from manually implementing the patterns described in part I. You can use RunInference to simplify your pipelines and reduce technical debt when building production inference pipelines in batch or stream mode.
The following four patterns are covered:
- Using RunInference to make ML prediction calls.
- Post-processing RunInference results. Making predictions is often the first part of a multistep flow, in the business process. Here we will process the results into a form that can be used downstream.
- Attaching a key. Along with the data that is passed to the model, there is often a need for an identifier — for example, an IOT device ID or a customer identifier — that is used later in the process even if it’s not used by the model itself. We show how this can be accomplished.
- Inference with multiple models in the same pipeline.Often you may need to run multiple models within the same pipeline, be it in parallel or as a sequence of predict – process – predict calls. We walk through a simple example.
Creating a simple model
In order to illustrate these patterns, we’ll use a simple toy model that will let us concentrate on the data engineering needed for the input and output of the pipeline. This model will be trained to approximate multiplication by the number 5.
Please note the following code snippets can be run as cells within a notebook environment.
Step 1 – Set up libraries and imports
%pip install tfx_bsl==0.29.0 --quietimport argparse
import tensorflow as tf
from tensorflow import keras
from tensorflow_serving.apis import prediction_log_pb2
import apache_beam as beam
import tfx_bsl
from tfx_bsl.public.beam import RunInference
from tfx_bsl.public import tfxio
from tfx_bsl.public.proto import model_spec_pb2
import numpy
from typing import Dict, Text, Any, Tuple, List
from apache_beam.options.pipeline_options import PipelineOptions
project = "<your project>"
bucket = "<your bucket>"
save_model_dir_multiply = f'gs://{bucket}/tfx-inference/model/multiply_five/v1/'
save_model_dir_multiply_ten = f'gs://{bucket}/tfx-inference/model/multiply_ten/v1/'Step 2 – Create the example data
In this step we create a small dataset that includes a range of values from 0 to 99 and labels that correspond to each value multiplied by 5.
"""
Create our training data which represents the 5 times multiplication table for 0 to 99. x is the data and y the labels.
x is a range of values from 0 to 99.
y is a list of 5x
value_to_predict includes a values outside of the training data
"""
x = numpy.arange(0, 100)
y = x * 5Step 3 – Create a simple model, compile, and fit it
"""
Build a simple linear regression model.
Note the model has a shape of (1) for its input layer, it will expect a single int64 value.
"""
input_layer = keras.layers.Input(shape=(1), dtype=tf.float32, name='x')
output_layer= keras.layers.Dense(1)(input_layer)
model = keras.Model(input_layer, output_layer)
model.compile(optimizer=tf.optimizers.Adam(), loss='mean_absolute_error')
model.summary()Let’s teach the model about multiplication by 5.
model.fit(x, y, epochs=2000)Next, check how well the model performs using some test data.
value_to_predict = numpy.array([105, 108, 1000, 1013], dtype=numpy.float32)
model.predict(value_to_predict)From the results below it looks like this simple model has learned its 5 times table close enough for our needs!
OUTPUT:
array([[ 524.9939],
[ 539.9937],
[4999.935 ],
[5064.934 ]], dtype=float32)Step 4 – Convert the input to tf.example
In the model we just built, we made use of a simple list to generate the data and pass it to the model. In this next step we make the model more robust by using tf.example objects in the model training.
tf.example is a serializable dictionary (or mapping) from names to tensors, which ensures the model can still function even when new features are added to the base examples. Making use of tf.example also brings with it the benefit of having the data be portable across models in an efficient, serialized format.
To use tf.example for this example, we first need to create a helper class, ExampleProcessor, that is used to serialize the data points.
class ExampleProcessor:
def create_example_with_label(self, feature: numpy.float32,
label: numpy.float32)-> tf.train.Example:
return tf.train.Example(
features=tf.train.Features(
feature={'x': self.create_feature(feature),
'y' : self.create_feature(label)
}))
def create_example(self, feature: numpy.float32):
return tf.train.Example(
features=tf.train.Features(
feature={'x' : self.create_feature(feature)})
)
def create_feature(self, element: numpy.float32):
return tf.train.Feature(float_list=tf.train.FloatList(value=[element]))Using the ExampleProcess class, the in-memory list can now be moved to disk.
# Create our labeled example file for 5 times table
example_five_times_table = 'example_five_times_table.tfrecord'
with tf.io.TFRecordWriter(example_five_times_table) as writer:
for i in zip(x, y):
example = ExampleProcessor().create_example_with_label(
feature=i[0], label=i[1])
writer.write(example.SerializeToString())
# Create a file containing the values to predict
predict_values_five_times_table = 'predict_values_five_times_table.tfrecord'
with tf.io.TFRecordWriter(predict_values_five_times_table) as writer:
for i in value_to_predict:
example = ExampleProcessor().create_example(feature=i)
writer.write(example.SerializeToString())With the new examples stored in TFRecord files on disk, we can use the Dataset API to prepare the data so it is ready for consumption by the model.
RAW_DATA_TRAIN_SPEC = {
'x': tf.io.FixedLenFeature([], tf.float32),
'y': tf.io.FixedLenFeature([], tf.float32)
}
RAW_DATA_PREDICT_SPEC = {
'x': tf.io.FixedLenFeature([], tf.float32),
}With the feature spec in place, we can train the model as before.
dataset = tf.data.TFRecordDataset(example_five_times_table)
dataset = dataset.map(lambda e : tf.io.parse_example(e, RAW_DATA_TRAIN_SPEC))
dataset = dataset.map(lambda t : (t['x'], t['y']))
dataset = dataset.batch(100)
dataset = dataset.repeat()
model.fit(dataset, epochs=500, steps_per_epoch=1)Note that these steps would be done automatically for us if we had built the model using a TFX pipeline, rather than hand-crafting the model as we did here.
Step 5 – Save the model
Now that we have a model, we need to save it for use with the RunInference transform. RunInference accepts TensorFlow saved model pb files as part of its configuration. The saved model file must be stored in a location that can be accessed by the RunInference transform. In a notebook this can be the local file system; however, to run the pipeline on Dataflow, the file will need to be accessible by all the workers, so here we use a GCP bucket.
Note that the gs:// schema is directly supported by the tf.keras.models.save_model api.
tf.keras.models.save_model(model, save_model_dir_multiply)During development it’s useful to be able to inspect the contents of the saved model file. For this, we use the saved_model_cli that comes with TensorFlow. You can run this command from a cell:
!saved_model_cli show --dir {save_model_dir_multiply} --allAbbreviated output from the saved model file is shown below. Note the signature def 'serving_default', which accepts a tensor of float type. We will change this to accept another type in the next section.
OUTPUT:
signature_def['serving_default']:
The given SavedModel SignatureDef contains the following input(s):
inputs['example'] tensor_info:
dtype: DT_FLOAT
shape: (-1, 1)
name: serving_default_example:0
The given SavedModel SignatureDef contains the following output(s):
outputs['dense_1'] tensor_info:
dtype: DT_FLOAT
shape: (-1, 1)
name: StatefulPartitionedCall:0
Method name is: tensorflow/serving/predictRunInference will pass a serialized tf.example to the model rather than a tensor of float type as seen in the current signature. To accomplish this we have one more step to prepare the model: creation of a specific signature.
Signatures are a powerful feature as they enable us to control how calling programs interact with the model. From the TensorFlow documentation:
“The optional signatures argument controls which methods in obj will be available to programs which consume SavedModels, for example, serving APIs. Python functions may be decorated with @tf.function(input_signature=…) and passed as signatures directly, or lazily with a call to get_concrete_function on the method decorated with @tf.function.”
In our case, the following code will create a signature that accepts a tf.string data type with a name of ‘examples’. This signature is then saved with the model, which replaces the previous saved model.
@tf.function(input_signature=[tf.TensorSpec(shape=[None], dtype=tf.string , name='examples')])
def serve_tf_examples_fn(serialized_tf_examples):
"""Returns the output to be used in the serving signature."""
features = tf.io.parse_example(serialized_tf_examples, RAW_DATA_PREDICT_SPEC)
return model(features, training=False)
signature = {'serving_default': serve_tf_examples_fn}
tf.keras.models.save_model(model, save_model_dir_multiply, signatures=signature)If you run the saved_model_cli command again, you will see that the input signature has changed to DT_STRING.
Pattern 1: RunInference for Predictions
Step 1 – Use RunInference within the pipeline
Now that the model is ready, the RunInference transform can be plugged into an Apache Beam pipeline. The pipeline below uses TFXIO TFExampleRecord, which it converts to a transform via RawRecordBeamSource(). The saved model location and signature are passed to the RunInference API as a SavedModelSpec configuration object.
pipeline = beam.Pipeline()
tfexample_beam_record = tfx_bsl.public.tfxio.TFExampleRecord(file_pattern=predict_values_five_times_table)
with pipeline as p:
_ = (p | tfexample_beam_record.RawRecordBeamSource()
| RunInference(
model_spec_pb2.InferenceSpecType(
saved_model_spec=model_spec_pb2.SavedModelSpec(model_path=save_model_dir_multiply)))
| beam.Map(print)
)Note:
You can perform two types of inference using RunInference:
- In-process inference from a SavedModel instance. Used when the
saved_model_specfield is set ininference_spec_type. - Remote inference by using a service endpoint. Used when the
ai_platform_prediction_model_specfield is set ininference_spec_type.
Below is a snippet of the output. The values here are a little difficult to interpret as they are in their raw unprocessed format. In the next section the raw results are post-processed.
OUTPUT:
predict_log {
request {
model_spec { signature_name: "serving_default" }
inputs {
key: "examples"
...
string_val: "n22n20n07example22053203n01i"
...
response {
outputs {
key: "output_0"
value {
...
float_val: 524.993896484375Pattern 2: Post-processing RunInference results
The RunInference API returns a PredictionLog object, which contains the serialized input and the output from the call to the model. Having access to both the input and output enables you to create a simple tuple during post-processing for use downstream in the pipeline. Also worthy of note is that RunInference will consider the amenable-to-batching capability of the model (and does batch inference for performance purposes) transparently for you.
The PredictionProcessor beam.DoFn takes the output of RunInference and produces formatted text with the questions and answers as output. Of course in a production system, the output would more normally be a Tuple[input, output], or simply the output depending on the use case.
class PredictionProcessor(beam.DoFn):
def process(
self,
element: prediction_log_pb2.PredictionLog):
predict_log = element.predict_log
input_value = tf.train.Example.FromString(predict_log.request.inputs['examples'].string_val[0])
output_value = predict_log.response.outputs
yield (f"input is [{input_value.features.feature['x'].float_list.value}] output is {output_value['output_0'].float_val}");
pipeline = beam.Pipeline()
tfexample_beam_record = tfx_bsl.public.tfxio.TFExampleRecord(file_pattern=predict_values_five_times_table)
with pipeline as p:
_ = (p | tfexample_beam_record.RawRecordBeamSource()
| RunInference(
model_spec_pb2.InferenceSpecType(
saved_model_spec=model_spec_pb2.SavedModelSpec(model_path=save_model_dir_multiply)))
| beam.ParDo(PredictionProcessor())
| beam.Map(print)
)Now the output contains both the original input and the model’s output values.
OUTPUT:
input is [[105.]] output is [523.6328735351562]
input is [[108.]] output is [538.5157470703125]
input is [[1000.]] output is [4963.6787109375]
input is [[1013.]] output is [5028.1708984375]Pattern 3: Attaching a key
One useful pattern is the ability to pass information, often a unique identifier, with the input to the model and have access to this identifier from the output. For example, in an IOT use case you could associate a device id with the input data being passed into the model. Often this type of key is not useful for the model itself and thus should not be passed into the first layer.
RunInference takes care of this for us, by accepting a Tuple[key, value] and outputting Tuple[key, PredictLog]
Step 1 – Create a source with attached key
Since we need a key with the data that we are sending in for prediction, in this step we create a table in BigQuery, which has two columns: One holds the key and the second holds the test value.
CREATE OR REPLACE TABLE
maths.maths_problems_1 ( key STRING OPTIONS(description="A unique key for the maths problem"),
value FLOAT64 OPTIONS(description="Our maths problem" ) );
INSERT INTO
maths.maths_problems_1
VALUES
( "first_question", 105.00),
( "second_question", 108.00),
( "third_question", 1000.00),
( "fourth_question", 1013.00)Step 2 – Modify post processor and pipeline
In this step we:
- Modify the pipeline to read from the new BigQuery source table
- Add a map transform, which converts a table row into a Tuple[ bytes, Example]
- Modify the post inference processor to output results along with the key
class PredictionWithKeyProcessor(beam.DoFn):
def __init__(self):
beam.DoFn.__init__(self)
def process(
self,
element: Tuple[bytes, prediction_log_pb2.PredictionLog]):
predict_log = element[1].predict_log
input_value = tf.train.Example.FromString(predict_log.request.inputs['examples'].string_val[0])
output_value = predict_log.response.outputs
yield (f"key is {element[0]} input is {input_value.features.feature['x'].float_list.value} output is { output_value['output_0'].float_val[0]}" )
pipeline_options = PipelineOptions().from_dictionary({'temp_location':f'gs://{bucket}/tmp'})
pipeline = beam.Pipeline(options=pipeline_options)
with pipeline as p:
_ = (p | beam.io.gcp.bigquery.ReadFromBigQuery(table=f'{project}:maths.maths_problems_1')
| beam.Map(lambda x : (bytes(x['key'], 'utf-8'), ExampleProcessor().create_example(numpy.float32(x['value']))))
| RunInference(
model_spec_pb2.InferenceSpecType(
saved_model_spec=model_spec_pb2.SavedModelSpec(model_path=save_model_dir_multiply)))
| beam.ParDo(PredictionWithKeyProcessor())
| beam.Map(print)
)key is b'first_question' input is [105.] output is 524.0875854492188
key is b'second_question' input is [108.] output is 539.0093383789062
key is b'third_question' input is [1000.] output is 4975.75830078125
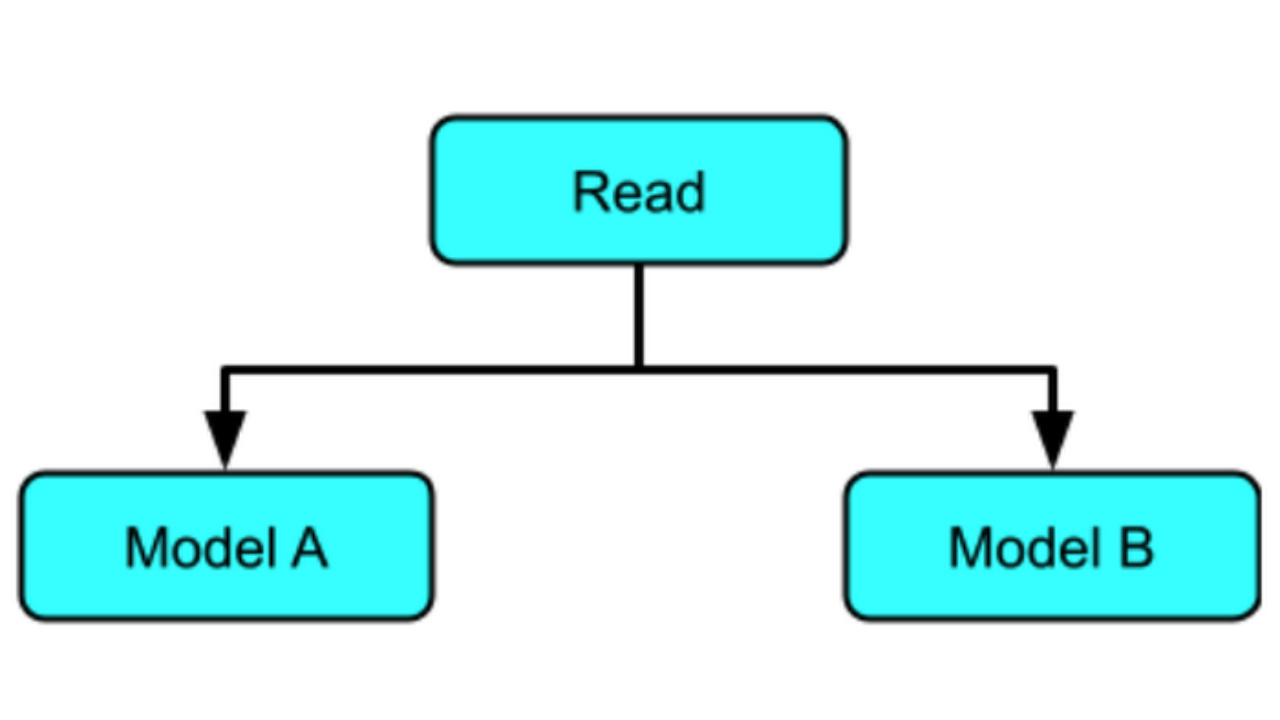
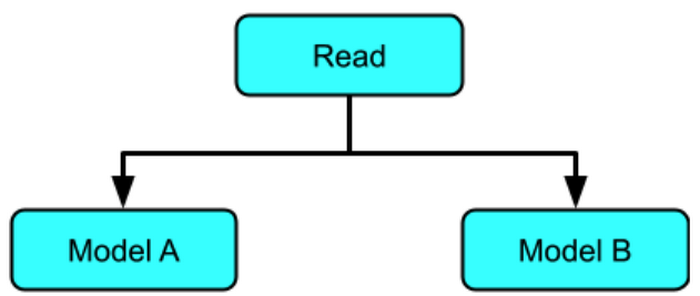
key is b'fourth_question' input is [1013.] output is 5040.41943359375Pattern 4: Inference with multiple models in the same pipeline
In part I of the series, the “join results from multiple models” pattern covered the various branching techniques in Apache Beam that make it possible to run data through multiple models.
Those techniques are applicable to RunInference API, which can easily be used by multiple branches within a pipeline, with the same or different models. This is similar in function to cascade ensembling, although here the data flows through multiple models in a single Apache Beam DAG.
Inference with multiple models in parallel
In this example, the same data is run through two different models: the one that we’ve been using to multiply by 5 and a new model, which will learn to multiply by 10.
"""
Create multiply by 10 table.
x is a range of values from 0 to 100.
y is a list of x * 10
value_to_predict includes a values outside of the training data
"""
x = numpy.arange( 0, 1000)
y = x * 10
# Create our labeled example file for 10 times table
example_ten_times_table = 'example_ten_times_table.tfrecord'
with tf.io.TFRecordWriter( example_ten_times_table ) as writer:
for i in zip(x, y):
example = ExampleProcessor().create_example_with_label(
feature=i[0], label=i[1])
writer.write(example.SerializeToString())
dataset = tf.data.TFRecordDataset(example_ten_times_table)
dataset = dataset.map(lambda e : tf.io.parse_example(e, RAW_DATA_TRAIN_SPEC))
dataset = dataset.map(lambda t : (t['x'], t['y']))
dataset = dataset.batch(100)
dataset = dataset.repeat()
model.fit(dataset, epochs=500, steps_per_epoch=10, verbose=0)
tf.keras.models.save_model(model,
save_model_dir_multiply_ten,
signatures=signature)Now that we have two models, we apply them to our source data.
pipeline_options = PipelineOptions().from_dictionary(
{'temp_location':f'gs://{bucket}/tmp'})
pipeline = beam.Pipeline(options=pipeline_options)
with pipeline as p:
questions = p | beam.io.gcp.bigquery.ReadFromBigQuery(
table=f'{project}:maths.maths_problems_1')
multiply_five = ( questions
| "CreateMultiplyFiveTuple" >>
beam.Map(lambda x : (bytes('{}{}'.format(x['key'],' * 5'),'utf-8'),
ExampleProcessor().create_example(x['value'])))
| "Multiply Five" >> RunInference(
model_spec_pb2.InferenceSpecType(
saved_model_spec=model_spec_pb2.SavedModelSpec(
model_path=save_model_dir_multiply)))
)
multiply_ten = ( questions
| "CreateMultiplyTenTuple" >>
beam.Map(lambda x : (bytes('{}{}'.format(x['key'],'* 10'), 'utf-8'),
ExampleProcessor().create_example(x['value'])))
| "Multiply Ten" >> RunInference(
model_spec_pb2.InferenceSpecType(
saved_model_spec=model_spec_pb2.SavedModelSpec(
model_path=save_model_dir_multiply_ten)))
)
_ = ((multiply_five, multiply_ten) | beam.Flatten()
| beam.ParDo(PredictionWithKeyProcessor())
| beam.Map(print))Output:
key is b'first_question * 5' input is [105.] output is 524.0875854492188
key is b'second_question * 5' input is [108.] output is 539.0093383789062
key is b'third_question * 5' input is [1000.] output is 4975.75830078125
key is b'fourth_question * 5' input is [1013.] output is 5040.41943359375
key is b'first_question* 10' input is [105.] output is 1054.333984375
key is b'second_question* 10' input is [108.] output is 1084.3131103515625
key is b'third_question* 10' input is [1000.] output is 9998.0908203125
key is b'fourth_question* 10' input is [1013.] output is 10128.0009765625Inference with multiple models in sequence
In a sequential pattern, data is sent to one or more models in sequence, with the output from each model chaining to the next model.

Here are the steps:
- Read the data from BigQuery
- Map the data
- RunInference with multiply by 5 model
- Process the results
- RunInference with multiply by 10 model
- Process the results
pipeline_options = PipelineOptions().from_dictionary(
{'temp_location':f'gs://{bucket}/tmp'})
pipeline = beam.Pipeline(options=pipeline_options)
def process_interim_inference(element : Tuple[
bytes, prediction_log_pb2.PredictionLog
])-> Tuple[bytes, tf.train.Example]:
key = '{} original input is {}'.format(
element[0], str(tf.train.Example.FromString(
element[1].predict_log.request.inputs['examples'].string_val[0]
).features.feature['x'].float_list.value[0]))
value = ExampleProcessor().create_example(
element[1].predict_log.response.outputs['output_0'].float_val[0])
return (bytes(key,'utf-8'),value)
with pipeline as p:
questions = p | beam.io.gcp.bigquery.ReadFromBigQuery(
table=f'{project}:maths.maths_problems_1')
multiply = ( questions
| "CreateMultiplyTuple" >>
beam.Map(lambda x : (bytes(x['key'],'utf-8'),
ExampleProcessor().create_example(x['value'])))
| "MultiplyFive" >> RunInference(
model_spec_pb2.InferenceSpecType(
saved_model_spec=model_spec_pb2.SavedModelSpec(
model_path=save_model_dir_multiply)))
)
_ = ( multiply
| "Extract result " >>
beam.Map(lambda x : process_interim_inference(x))
| "MultiplyTen" >> RunInference(
model_spec_pb2.InferenceSpecType(
saved_model_spec=model_spec_pb2.SavedModelSpec(
model_path=save_model_dir_multiply_ten)))
| beam.ParDo(PredictionWithKeyProcessor())
| beam.Map(print)
)Output:
key is b"b'first_question' original input is 105.0" input is [524.9771118164062] output is 5249.7822265625
key is b"b'second_question' original input is 108.0" input is [539.9765014648438] output is 5399.7763671875
key is b"b'third_question' original input is 1000.0" input is [4999.7841796875] output is 49997.9453125
key is b"b'forth_question' original input is 1013.0" input is [5064.78125] output is 50647.91796875Running the pipeline on Dataflow
Until now the pipeline has been run locally, using the direct runner, which is implicitly used when running a pipeline with the default configuration. The same examples can be run using the production Dataflow runner by passing in configuration parameters including --runner. Details and an example can be found here.
Here is an example of the multimodel pipeline graph running on the Dataflow service:

With the Dataflow runner you also get access to pipeline monitoring as well as metrics that have been output from the RunInference transform. The following table shows some of these metrics from a much larger list available from the library.

Conclusion
In this blog, part II of our series, we explored the use of the tfx-bsl RunInference within some common scenarios, from standard inference, to post processing and the use of RunInference API in multiple locations in the pipeline.
To learn more, review the Dataflow and TFX documentation, you can also try out TFX with Google Cloud AI platform pipelines..
Acknowledgements
None of this would be possible without the hard work of many folks across both the Dataflow TFX and TF teams. From the TFX and TF team we would especially like to thank Konstantinos Katsiapis, Zohar Yahav, Vilobh Meshram, Jiayi Zhao, Zhitao Li, and Robert Crowe. From the Dataflow team I would like to thank Ahmet Altay for his support and input throughout.