Efficient training of modern neural networks often relies on using lower precision data types. Peak float16 matrix multiplication and convolution performance is 16x faster than peak float32 performance on A100 GPUs. And since the float16 and bfloat16 data types are only half the size of float32 they can double the performance of bandwidth-bound kernels and reduce the memory required to train a network, allowing for larger models, larger batches, or larger inputs. Using a module like torch.amp (short for “Automated Mixed Precision”) makes it easy to get the speed and memory usage benefits of lower precision data types while preserving convergence behavior.
Going faster and using less memory is always advantageous – deep learning practitioners can test more model architectures and hyperparameters, and larger, more powerful models can be trained. Training very large models like those described in Narayanan et al. and Brown et al. (which take thousands of GPUs months to train even with expert handwritten optimizations) is infeasible without using mixed precision.
We’ve talked about mixed precision techniques before (here, here, and here), and this blog post is a summary of those techniques and an introduction if you’re new to mixed precision.
Mixed Precision Training in Practice
Mixed precision training techniques – the use of the lower precision float16 or bfloat16 data types alongside the float32 data type – are broadly applicable and effective. See Figure 1 for a sampling of models successfully trained with mixed precision, and Figures 2 and 3 for example speedups using torch.amp.
Figure 1: Sampling of DL Workloads Successfully Trained with float16 (Source).
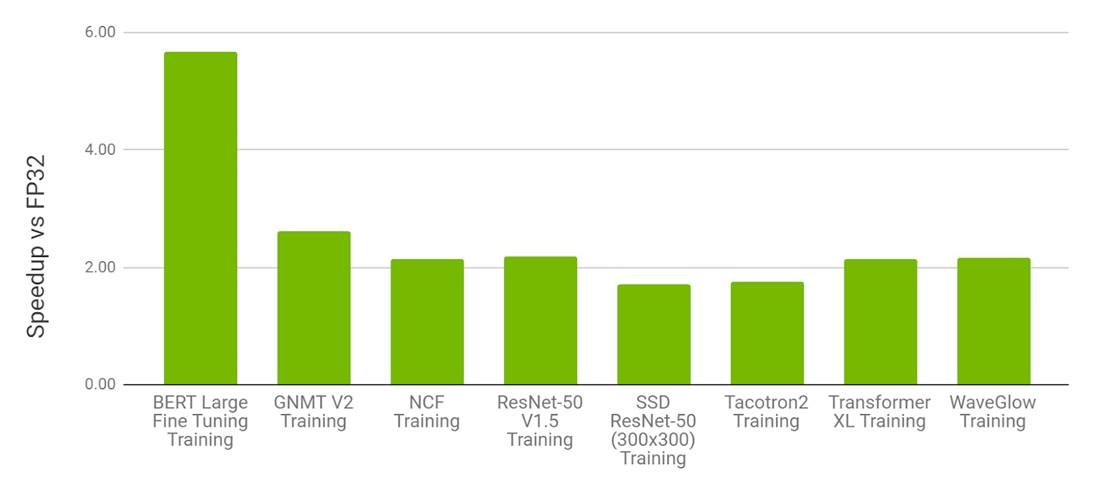
Figure 2: Performance of mixed precision training using torch.amp on NVIDIA 8xV100 vs. float32 training on 8xV100 GPU. Bars represent the speedup factor of torch.amp over float32.
(Higher is better.) (Source).
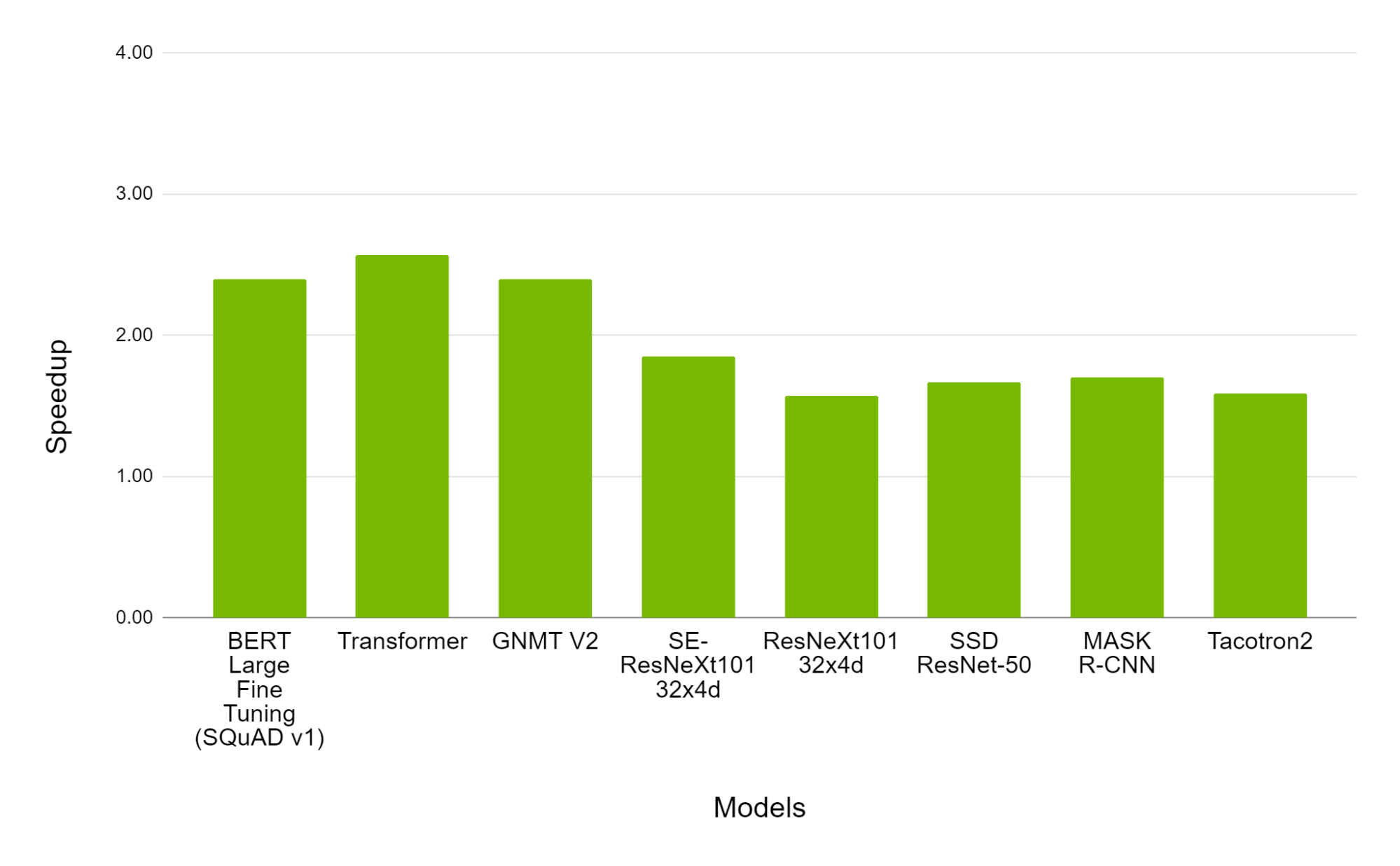
Figure 3. Performance of mixed precision training using torch.amp on NVIDIA 8xA100 vs. 8xV100 GPU. Bars represent the speedup factor of A100 over V100.
(Higher is Better.) (Source).
See the NVIDIA Deep Learning Examples repository for more sample mixed precision workloads.
Similar performance charts can be seen in 3D medical image analysis, gaze estimation, video synthesis, conditional GANs, and convolutional LSTMs. Huang et al. showed that mixed precision training is 1.5x to 5.5x faster over float32 on V100 GPUs, and an additional 1.3x to 2.5x faster on A100 GPUs on a variety of networks. On very large networks the need for mixed precision is even more evident. Narayanan et al. reports that it would take 34 days to train GPT-3 175B on 1024 A100 GPUs (with a batch size of 1536), but it’s estimated it would take over a year using float32!
Getting Started With Mixed Precision Using torch.amp
torch.amp, introduced in PyTorch 1.6, makes it easy to leverage mixed precision training using the float16 or bfloat16 dtypes. See this blog post, tutorial, and documentation for more details. Figure 4 shows an example of applying AMP with grad scaling to a network.
import torch
# Creates once at the beginning of training
scaler = torch.cuda.amp.GradScaler()
for data, label in data_iter:
optimizer.zero_grad()
# Casts operations to mixed precision
with torch.amp.autocast(device_type=“cuda”, dtype=torch.float16):
loss = model(data)
# Scales the loss, and calls backward()
# to create scaled gradients
scaler.scale(loss).backward()
# Unscales gradients and calls
# or skips optimizer.step()
scaler.step(optimizer)
# Updates the scale for next iteration
scaler.update()
Figure 4: AMP recipe
Picking The Right Approach
Out-of-the-box mixed precision training with either float16 or bfloat16 is effective at speeding up the convergence of many deep learning models, but some models may require more careful numerical accuracy management. Here are some options:
- Full float32 precision. Floating point tensors and modules are created in float32 precision by default in PyTorch, but this is a historic artifact not representative of training most modern deep learning networks. It’s rare that networks need this much numerical accuracy.
- Enabling TensorFloat32 (TF32) mode. On Ampere and later CUDA devices matrix multiplications and convolutions can use the TensorFloat32 (TF32) mode for faster but slightly less accurate computations. See the Accelerating AI Training with NVIDIA TF32 Tensor Cores blog post for more details. By default PyTorch enables TF32 mode for convolutions but not matrix multiplications, and unless a network requires full float32 precision we recommend enabling this setting for matrix multiplications, too (see the documentation here for how to do so). It can significantly speed up computations with typically negligible loss of numerical accuracy.
- Using torch.amp with bfloat16 or float16. Both these low precision floating point data types are usually comparably fast, but some networks may only converge with one vs the other. If a network requires more precision it may need to use float16, and if a network requires more dynamic range it may need to use bfloat16, whose dynamic range is equal to that of float32. If overflows are observed, for example, then we suggest trying bfloat16.
There are even more advanced options than those presented here, like using torch.amp’s autocasting for only parts of a model, or managing mixed precision directly. These topics are largely beyond the scope of this blog post, but see the “Best Practices” section below.
Best Practices
We strongly recommend using mixed precision with torch.amp or the TF32 mode (on Ampere and later CUDA devices) whenever possible when training a network. If one of those approaches doesn’t work, however, we recommend the following:
- High Performance Computing (HPC) applications, regression tasks, and generative networks may simply require full float32 IEEE precision to converge as expected.
- Try selectively applying torch.amp. In particular we recommend first disabling it on regions performing operations from the torch.linalg module or when doing pre- or post-processing. These operations are often especially sensitive. Note that TF32 mode is a global switch and can’t be used selectively on regions of a network. Enable TF32 first to check if a network’s operators are sensitive to the mode, otherwise disable it.
- If you encounter type mismatches while using torch.amp we don’t suggest inserting manual casts to start. This error is indicative of something being off with the network, and it’s usually worth investigating first.
- Figure out by experimentation if your network is sensitive to range and/or precision of a format. For example fine-tuning bfloat16-pretrained models in float16 can easily run into range issues in float16 because of the potentially large range from training in bfloat16, so users should stick with bfloat16 fine-tuning if the model was trained in bfloat16.
- The performance gain of mixed precision training can depend on multiple factors (e.g. compute-bound vs memory-bound problems) and users should use the tuning guide to remove other bottlenecks in their training scripts. Although having similar theoretical performance benefits, BF16 and FP16 can have different speeds in practice. It’s recommended to try the mentioned formats and use the one with best speed while maintaining the desired numeric behavior.
For more details, refer to the AMP Tutorial, Training Neural Networks with Tensor Cores, and see the post “More In-Depth Details of Floating Point Precision” on PyTorch Dev Discussion.
Conclusion
Mixed precision training is an essential tool for training deep learning models on modern hardware, and it will become even more important in the future as the performance gap between lower precision operations and float32 continues to grow on newer hardware, as reflected in Figure 5.
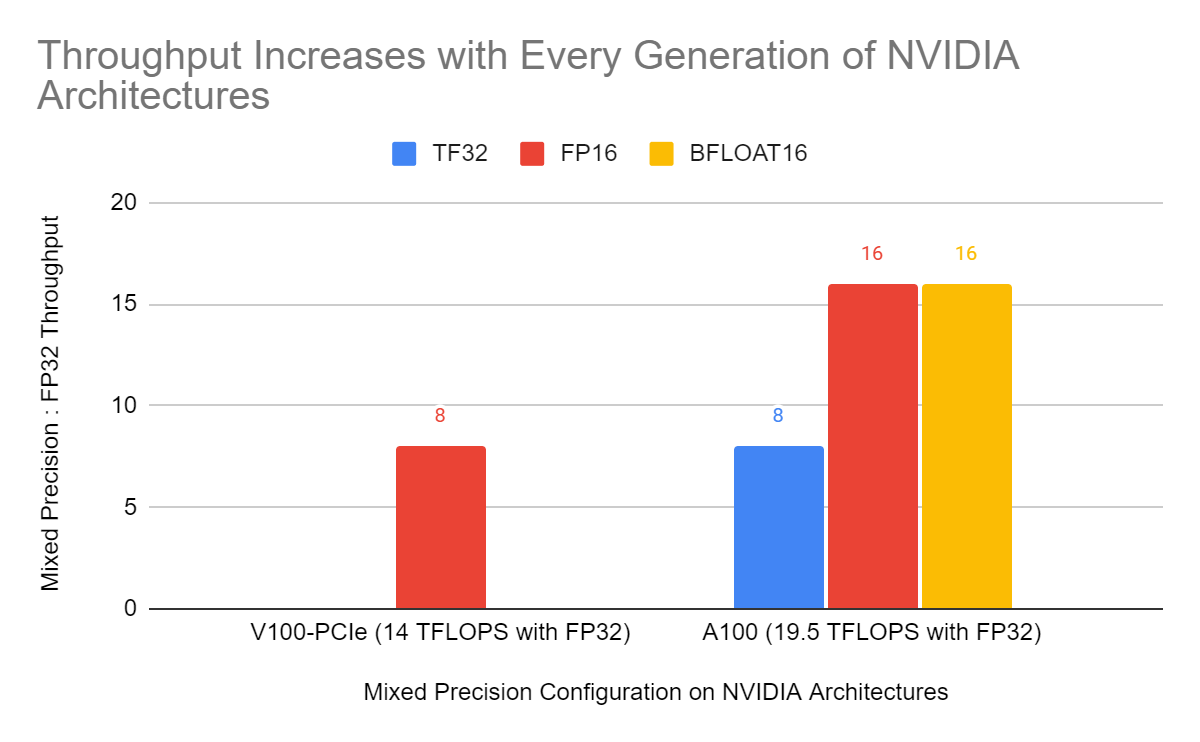
Figure 5: Relative peak throughput of float16 (FP16) vs float32 matrix multiplications on Volta and Ampere GPUs. On Ampere relative peak throughput for the TensorFloat32 (TF32) mode and bfloat16 matrix multiplications are shown, too. The relative peak throughput of low precision data types like float16 and bfloat16 vs. float32 matrix multiplications is expected to grow as new hardware is released.
PyTorch’s torch.amp module makes it easy to get started with mixed precision, and we highly recommend using it to train faster and reduce memory usage. torch.amp supports both float16 and bfloat16 mixed precision.
There are still some networks that are tricky to train with mixed precision, and for these networks we recommend trying TF32 accelerated matrix multiplications on Ampere and later CUDA hardware. Networks are rarely so precision sensitive that they require full float32 precision for every operation.
If you have questions or suggestions for torch.amp or mixed precision support in PyTorch then let us know by posting to the mixed precision category on the PyTorch Forums or filing an issue on the PyTorch GitHub page.